
Warum Nosql-Datenbanken perfekt für maschinelles Lernen sind
Veröffentlicht: 2023-01-16Nosql-Datenbanken werden aus mehreren Gründen immer beliebter für maschinelles Lernen. Erstens können sie mit dem großen Datenumfang umgehen, der häufig zum Trainieren von Modellen für maschinelles Lernen erforderlich ist. Zweitens bieten sie ein höheres Maß an Flexibilität als herkömmliche relationale Datenbanken, was bei der Arbeit mit komplexen Daten wichtig sein kann. Schließlich können nosql-Datenbanken einfacher horizontal skaliert werden, was für maschinelle Lernanwendungen wichtig sein kann, die in der Lage sein müssen, große Datenmengen zu verarbeiten.
Herkömmliche relationale Datenbanken konnten die Anforderungen von NoSQL-Datenbanken aufgrund ihrer Einschränkungen nicht erfüllen. NoSQL-Datenbanken sind im Vergleich zu relationalen Datenbanken häufig skalierbarer und bieten eine überlegene Leistung. Die Flexibilität und Benutzerfreundlichkeit ihrer Datenmodelle machen sie zu einer idealen Ergänzung zu relationalen Modellen, insbesondere in Cloud-Computing-Umgebungen. Bei gespeicherten oder abgerufenen Daten sind weniger Transformationen erforderlich. Durch die Verwendung einer Vielzahl von Datenspeichertechnologien können mehr Daten bequemer gespeichert und abgerufen werden. NoSQL-Datenbanken haben typischerweise Schemas, die flexibel sind und von den Entwicklern kontrolliert werden. Da neue Formen von Daten leichter in die Datenbank konvertiert werden können, erleichtert dies die Änderung.
Da NoSQL-Datenbanken Daten in nativen Formaten speichern, müssen Entwickler Daten nicht in Speicherformate konvertieren. Die überwiegende Mehrheit der NoSQL-Datenbanken hat eine große Entwickler-Community um sich herum. Die Datenbank wird automatisch erweitert und zusammengezogen, wenn ein Cluster von Computern in einer Datenbank verwendet wird.
NoSQL -Datenbanksysteme werden nicht nur für die Speicherung und Verwaltung von Geschäftsanwendungsdaten immer beliebter, sondern bieten auch integrierte Datenanalysen, mit denen Benutzer komplexe Datensätze sofort verstehen und fundiertere Entscheidungen treffen können.
Eine NoSQL-Datenbank ist eher die beste Wahl, wenn sie darauf ausgelegt ist, strukturierte, halbstrukturierte und unstrukturierte Daten an einem einzigen Ort zu speichern und zu modellieren.
Die Skalierbarkeit, Einfachheit, geringen Codeanforderungen und Wartungsfreundlichkeit von NoSQL machen es zu einem idealen Tool für kleine Organisationen. Weniger ausgereifte, weniger flexible Abfragen in NoSQL schmälern dessen Vorteile. Die Struktur der Abfragen ist weniger flexibel. Die NoSQL-Architektur soll nicht eigenständig skaliert werden.
MongoDB bietet wie andere NoSQL-Datenbanken aufgrund seiner flexiblen Schemaanforderungen Vorteile gegenüber SQL im Umgang mit großen Datensätzen . Zur Datenanalyse werden traditionell SQL-Datenbanken von den meisten Datenmanagern verwendet. Denn die meisten BI-Tools (z. B. Looker) unterstützen keine Abfrage von NoSQL-Datenbanken.
Eignet sich Nosql für maschinelles Lernen?
NoSQL-Datenbanken können Daten von verschiedenen Maschinen auf alternative Weise speichern. Aus diesem Grund werden NoSQL-Datenbanken auch als horizontal skalierbare Datenbanken bezeichnet und dazu verwendet, Datensätze auf mehreren Computern gleichzeitig hinzuzufügen.
Erwerben Sie Kenntnisse über NoSQL-Datenbanken, um Data Scientist zu werden. Eine NoSQL-Datenbank ist eine Datenbank, die Daten in einer Vielzahl von Formaten und Größen speichern kann. Ihm Form und Struktur nehmen. Noql-Datenbanken können für bestimmte Datensätze und mit einem bestimmten Fokus verwendet werden. Es gibt viele unstrukturierte Daten. Datenbankorientierte Datenbanken erleichtern Index und Rückgabe von Spalten. Dokumentendatenbanken werden in textbasierten Online-Umgebungen sowie zur Aufbewahrung von Archivalien verwendet.
Die Daten werden in Diagrammdatenbanken gespeichert und auch verwendet, um die Beziehungen zwischen Entitäten grafisch darzustellen. Der Einsatz von NoSQL-Datenbanken für Data-Science-Projekte ist in vielerlei Hinsicht vorteilhaft. Um diese Probleme zu lösen, bieten wir Kompatibilität mit mehreren Datentypen und horizontale Skalierbarkeit. Aufgrund ihrer Kompatibilität mit verschiedenen Arten von NoSQL-Datenbanken sind MongoDB, Cassandra, Redis und ApacheCouchDB dafür bekannt, dass sie gut funktionieren. MongoDB kann zum Speichern von Schlüsselwertdaten in Schlüsselwertspeichern wie Cassandra und Dokumentdatenbanken verwendet werden. Eine NoSQL-Datenbank ist ein Datenbanktyp, der häufig bei der Entwicklung von Web- und Mobilanwendungen verwendet wird. Studenten und Fachleute der Datenwissenschaft erhalten ein tieferes Verständnis dafür, wie wichtige Plattformen und Programmiersprachen mit Datenbanken interagieren, um Datenbanken zu erstellen, zu verwalten und zu analysieren. Faithe Day ist Autorin, Forscherin und Pädagogin mit einem Bachelor-Abschluss in Anglistik und Digital Humanities sowie einem Doktortitel in Kommunikationswissenschaften.

Nosql-Datenbanken: Die beste Wahl für Data Scientists
Beim Arbeiten mit unstrukturierten Daten ist eine NoSQL-Datenbank von entscheidender Bedeutung. Sie können keine dynamischen Vorgänge ausführen, sind aber ACID-konformer und flexibler als SQL-Datenbanken. Sie sollten SQL auswählen, wenn Sie klare Datenanforderungen haben und ein vordefiniertes Schema verwenden möchten. Wenn Ihre Daten jedoch unstrukturiert sind oder dynamische Vorgänge erfordern, ist NoSQL die bessere Wahl.
Ist Mongodb für maschinelles Lernen nützlich?
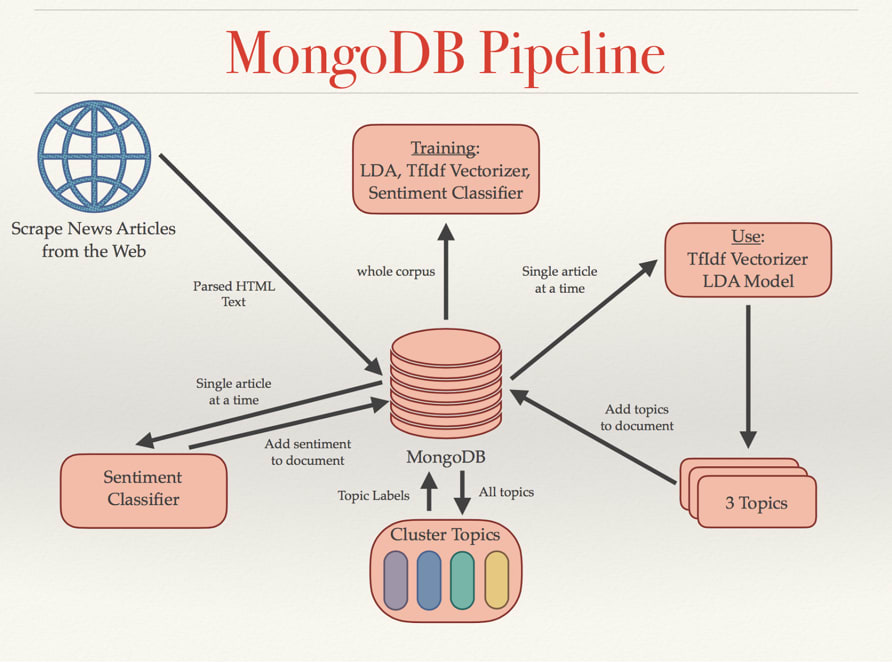
Mongodb ist nützlich für maschinelles Lernen, da es dabei helfen kann, Daten so zu speichern und zu organisieren, dass sie leicht zugänglich sind und für Trainingsmodelle verwendet werden können. Darüber hinaus kann mongodb verwendet werden, um Modelle für maschinelles Lernen bereitzustellen, damit sie von anderen verwendet werden können.
Eine NoSQL-Datenbank wie MongoDB kann große Datenmengen basierend auf Dokumentstrukturen speichern. MongoDB verwendet eher Sammlungen und Dokumente als Tabellen und Zeilen, wie es in traditionellen relationalen Datenbanken der Fall ist. In diesem Blog gehen wir darauf ein, warum MongoDB für maschinelles Lernen wichtig ist und wofür wir es in Python verwenden können. MongoDB ist eine ideale Plattform zum Speichern, Freigeben und Abrufen von trainierten Modellen. Unsere Modelle können nicht nur in der Datenbank gespeichert, sondern auch in einer Historie aufbewahrt werden. Infolgedessen könnten wir, wenn wir uns dafür entscheiden, ein trainiertes Modell aus einer früheren Version wiederherstellen.
Weitere Informationen finden Sie unter https://www.mongodb.com/product/query-api.
Nosql für maschinelles Lernen
Die Verwendung von NoSQL-Datenbanken für maschinelle Lernanwendungen bietet viele Vorteile. NoSQL-Datenbanken sind hochgradig skalierbar, was für Anwendungen wichtig ist, die große Datenmengen verarbeiten müssen. Sie sind auch so konzipiert, dass sie leicht verteilt werden können, was dazu beitragen kann, die Schulungszeiten zu verkürzen. Darüber hinaus sind NoSQL-Datenbanken oft kostengünstiger zu warten als herkömmliche relationale Datenbanken.
Eine nicht relationale Datenbank, die keine Beziehung zwischen Daten hat, diese Kategorie wird als NoSQL bezeichnet. Sie sind äußerst anpassungsfähig und für den Einsatz in einer verteilten Umgebung konzipiert, in der sie skalierbar und zuverlässig sind. Bei NoSQL-Datenbanken müssen Sie sich keine Gedanken über Leistungsprobleme machen; Fragen Sie es stattdessen ab, ohne teure Joins auszuführen. Lassen Sie uns in diesem Abschnitt die verschiedenen Arten von NoSQL-Datenbanken durchgehen, nachdem wir wissen, was sie sind. Dokumentbasierte NoSQL-Datenbanken speichern Daten in JSON-Objekten. Eine Schlüssel- Wert-Datenbank ist ein Beispiel für ein Schlüssel-Wert-Paar. Eine breitspaltenbasierte Datenbank kann eine große Anzahl dynamischer Spalten enthalten.
Die folgenden Artikel helfen Ihnen bei den ersten Schritten mit MongoDB. Facebook hat Anfang der 2000er Jahre das Open -Source-Datenbanksystem Cassandra entwickelt . ElasticSearch ist das schnellste und leistungsstärkste Tool zum Analysieren, Speichern und Durchsuchen großer Datenmengen. Amazon DynamoDB hat die Kapazität, 10 Billionen Anfragen pro Tag zu verarbeiten, was beeindruckend ist.