
Warum Nosql-Datenbanken Data Warehouses ersetzen
Veröffentlicht: 2022-11-23Data Warehouses sind seit langem die wichtigste Methode für Unternehmen, um Daten zu speichern und zu analysieren. Aber Nosql-Datenbanken werden zunehmend als Ergänzung oder sogar als Ersatz für Data Warehouses eingesetzt. Für diese Verschiebung gibt es eine Reihe von Gründen. Nosql-Datenbanken sind im Allgemeinen skalierbarer und einfacher zu handhaben als herkömmliche Data Warehouses. Sie können auch kostengünstiger sein, da sie nicht das gleiche Maß an Hardware- und Softwareinvestitionen erfordern. Nosql-Datenbanken können auch flexibler sein als Data Warehouses, was die Integration neuer Datenquellen und die Anpassung an sich ändernde Geschäftsanforderungen erleichtert. Trotz dieser Vorteile sind Nosql-Datenbanken kein Allheilmittel. Sie können komplexer zu verwalten sein als Data Warehouses und unterstützen möglicherweise nicht alle Features und Funktionen, die Unternehmen benötigen. Dennoch werden Nosql-Datenbanken in vielen Organisationen zunehmend als Ergänzung oder sogar als Ersatz für Data Warehouses eingesetzt. Da Unternehmen mit diesen Technologien vertrauter werden, erwarten wir in den kommenden Jahren eine noch breitere Akzeptanz.
Sowohl NoSQL als auch Data-Warehouse können SQL-Abfragen durchführen. Data Warehouses und NoSQL sind nicht dasselbe. Sie teilen das Konzept, mit großen Datenmengen umgehen zu können, weil sie dazu in der Lage sind. Ein Data Warehouse hat im Vergleich zu einem dimensionalen Modell normalerweise viele Fakten und Dimensionen (oder viele Entitäten in einem 3NF-Modell).
Wie speichert die Nosql-Datenbank Daten?
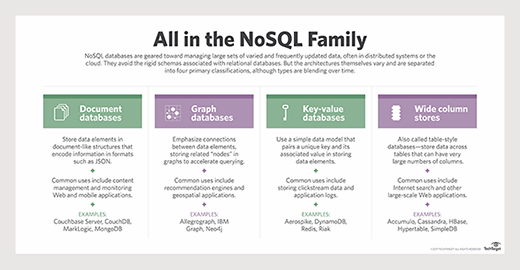
Statt relationaler Datenbanken speichern NoSQL-Datenbanken Daten in Dokumenten. In diesem Sinne werden sie als „nicht nur SQL“ klassifiziert und in eine Vielzahl von flexiblen Datenmodellen unterteilt. Eine NoSQL-Datenbank kann aus einer reinen Dokumentendatenbank, einem Key-Value-Store, einer Wide-Column-Datenbank oder einer Graph-Datenbank bestehen.
Die Verwendung von NoSQL-Datenbanken ermöglicht die schnelle Speicherung großer Mengen unabhängiger Daten. NoSQL ist kein NoSQL-Typ, da es keine relationalen Datenstrukturen enthält. In den 1970er Jahren waren relationale Datenbanken der Standard der Datenspeicherung. In einem Gespräch mit Ben Finkel, einem CBT-Trainer, hält NoSQL Geschwindigkeit und Flexibilität für wichtiger als Konsistenz und Effizienz. Trotz ihrer Geschwindigkeit und Effizienz erfordern relationale Datenbanken viel Aufwand für den Aufbau und die Wartung. NoSQL-Datenbanken müssen vor ihrer Implementierung nicht entworfen oder geplant werden. Infolgedessen können Entwickler Anwendungen viel schneller erstellen, prototypisieren und bereitstellen.
Sie können auch im traditionelleren agilen Entwicklungsprozess verwendet werden. Im Gegensatz zu herkömmlichen Datenbanken können NoSQL-Datenbanken eine Vielzahl von Datentypen verarbeiten und erfordern keine Regularisierung. Datenbank-NoSQLs benötigen mehr Rechenleistung als relationale Datenbanken. Eine NoSQL-Datenbank kann problemlos auf einem Raspberry Pi laufen, aber es wird schwieriger, die Last eines Webservers zu bewältigen. Graphen sind im Gegensatz zu Schlüssel:Wert-Paaren oder Dokumenten eher abstrakt. Knoten und Kanten werden in zwei Teile eines Graphen unterteilt. Knoten enthalten Informationen über ein Objekt (Person, Ort, Sache, Idee usw.)
die in einem Speicherblock gespeichert ist. Zwischen den Kanten eines Knotens wird eine logische Verbindung hergestellt. Ein Datenmodell mit breiten Spalten ähnelt einer relationalen Datenbank darin, dass es aus Zeilen und Spalten besteht.
Scale-out ist die Fähigkeit einer NoSQL-Datenbank, in der Größe zu wachsen, ohne die Leistung zu beeinträchtigen. Die Fähigkeit einer NoSQL-Datenbank, Daten selbst zu replizieren, wird als Replikation bezeichnet. Daten können mit der Flexibilität einer Datenstruktur einfach über verschiedene Formate hinweg abgebildet werden. Eine NoSQL-Datenbank eignet sich im Allgemeinen besser zum Speichern und Modellieren strukturierter, halbstrukturierter und unstrukturierter Daten als eine herkömmliche Datenbank . Bei den drei Hauptfunktionen von NoSQL-Datenbanken sind Scale-out, Replikation und Flexibilität wichtige Faktoren für die Speicherung von Daten, die nicht sauber in Tabellen und Spalten organisiert sind. Die Möglichkeit, eine NoSQL-Datenbank horizontal zu skalieren, stellt sicher, dass sie funktionsfähig bleibt und gleichzeitig Leistung bietet. Da es sich nicht um eine Zeile oder Spalte handelt, ist es besonders nützlich, wenn es sich um große Datensätze handelt, die nicht in eine einzelne Zeile oder Spalte einer Standardtabelle passen. Bei der Replikation werden die Daten einer NoSQL-Datenbank in eine separate Datenbank repliziert, sodass bei einem Ausfall die Daten von der anderen wiederhergestellt werden können, ohne von vorne anfangen zu müssen. Dies ist besonders wichtig, wenn Sie vertrauliche Daten aufbewahren, die bei einer Katastrophe verloren gehen könnten. Diese Technik ist ideal zum Speichern von Daten, die nicht ordentlich in Tabellen und Spalten organisiert sind, wie z. B. Text und Bilder.
Die Vorteile von Nosql-Datenbanken
NoSQL-Datenbanken werden verwendet, um große Datenmengen in Echtzeit zu speichern. Sie eignen sich besonders gut für Kunden-360-Anwendungen wie Online-Shopping, Online-Gaming, Internet der Dinge, soziale Netzwerke und Online-Werbung.
Kann Nosql als Data Warehouse verwendet werden?

Data Warehouses werden am häufigsten im Finanzsektor verwendet und sind äußerst kompatibel mit SQL-Systemen, da Schemata, die zum Formatieren von Daten verwendet werden, für strukturierte Datensätze formatiert sind. Data Warehouses machen das Beste aus SQL-Datenbanken, während einige NoSQL-Datenbanken weggelassen werden.
Wann sollte Nosql nicht verwendet werden?
Wenn Ihre Anwendung Laufzeitflexibilität erfordert, vermeiden Sie NoSQL. Aus Konsistenzgründen und wenn sich hinsichtlich des Datenvolumens keine wesentlichen Änderungen ergeben, sind SQL-Datenbanken die bessere Option.
Die Vor- und Nachteile von Nosql-Datenbanken
Mit der NoSQL-Datenbank können Sie Daten speichern und modellieren, die Sie mit einer standardmäßigen relationalen Datenbank nicht machen könnten. Neben halbstrukturierten und unstrukturierten Daten gelten große und komplexe Daten als große und komplexe Daten. Einer der Vorteile der Verwendung von NoSQL-Datenbanken besteht darin, dass sie agiler sein und auf Änderungen der Anforderungen reagieren können. Dies liegt daran, dass es keine vordefinierten Schemata und ein flexibleres Datenmodell gibt. Es stimmt jedoch, dass NoSQL-Datenbanken einige Einschränkungen aufweisen können. Einer der größten Nachteile von NoSQL-Datenbanken ist, dass sie keine ACID-Transaktionen unterstützen. Infolgedessen kann es schwieriger werden, Daten sicher aufzubewahren. NoSQL-Datenbanken sind nicht nur teurer in der Wartung, sondern können auch schwieriger zu verwenden sein. Außerdem sind sie möglicherweise nicht die beste Wahl für Anwendungen, die einen hohen Durchsatz erfordern.
Kann ein Data Warehouse nicht relational sein?
Data Warehouses sind eine traditionelle Domäne relationaler Datenbanken, und dafür gibt es zwei Gründe: (1) Sie werden hauptsächlich von großen Unternehmen mit großen Datensätzen verwendet, die in Legacy-Systemen mit relationalen Datenspeichern erstellt wurden, und (2) sie befinden sich noch in der Entwicklung. trotz der Tatsache, dass nicht-relationale Datenbanken schnell sind
Data Warehouses sind die Zukunft der Datenspeicherung
Die traditionelle Methode des Data Warehousing wird als relationales Computing bezeichnet. Anstatt sich mit Transaktionen zu befassen, besteht das Hauptziel einer relationalen Datenbank darin, Abfrageanforderungen zu verarbeiten und Daten zu analysieren. Es enthält normalerweise historische Transaktionsdaten, kann aber auch Daten aus anderen Quellen enthalten. Auf der anderen Seite hat dieses Modell Schwächen. Der erste Nachteil relationaler Datenbanken besteht darin, dass sie ein hohes Maß an Wartung und Skalierung erfordern. Darüber hinaus müssen keine großen Datenmengen, die nichts mit früheren Transaktionen zu tun haben, in einem Hadoop-Cluster gespeichert werden. Data Lakes können in dieser Situation helfen. Es ist eine Datenbank, die darauf ausgelegt ist, enorme Datenmengen zu speichern und zu verarbeiten. Es ist ein Gerät, das Daten aus einer Vielzahl von Quellen speichern kann, einschließlich Transaktionen. Es ist jedoch wichtig zu beachten, dass Data Lakes nicht fehlerfrei sind. Daher eignen sie sich nicht besonders gut für Abfragen oder Analysen. Dies liegt daran, dass sie speziell für die Abwicklung von Transaktionen entwickelt wurden. Data Warehouses sind in dieser Situation erforderlich. Dies ist eine Datenbank, die eher für Abfragen und Analysen als für die Transaktionsverarbeitung entwickelt wurde. Ein Data Warehouse kann als Alternative zu einem Data Lake verwendet werden, um eine Vielzahl von Vorteilen zu bieten. Die Kosten für die Wartung und Skalierung eines Data Warehouse sind in der Regel geringer als die Kosten für den Aufbau eines physischen Warehouse. Sie eignen sich auch gut zum Speichern vieler Daten. Kurz gesagt, es ist sehr wahrscheinlich, dass Data Warehouses das dominierende Speicher- und Verarbeitungsmodell der Zukunft werden. Sie sind in Bezug auf Abfragen und Analysen leistungsfähiger als Data Lakes, kostengünstiger und einfacher zu warten als herkömmliche Datenbanken.

Nosql-Datawarehouse
Ein NoSQL Data Warehouse ist ein System, das das Speichern und Abrufen von Daten ermöglicht, die nicht in einer herkömmlichen relationalen Datenbank organisiert sind. NoSQL Data Warehouses werden häufig für Anwendungen verwendet, die eine Datenanalyse in Echtzeit oder die Verarbeitung großer Datenmengen erfordern.
Ziel dieser Arbeit ist es, einen Überblick über die in diesem Zusammenhang geleistete Arbeit zu geben. Eine NoSQL-Datenbank speichert Daten aus sozialen Medien, GPS, Sensordaten, Überwachung und anderen Quellen. Dieses neue Paradigma, das das Design und die Implementierung von Data Warehouses (DW) und Big Data Processing (Big ETL) beeinflusst, sollte untersucht werden. Das spaltenorientierte NoSQL-Modell wird verwendet, um ein Big Data Warehouse zu erstellen. D. Mallek, H. Ghozzi, Teste, O. Gargouri, F.: BigDimETL: Eine NoSQL-Datenbank. Der norwegische Physiker NT Petter. Der erste Schritt zur Erklärung des analytischen Frameworks von NoSQL-Daten Dieser Artikel beschreibt die Entwicklung eines NoSQL-Datenbank-Frameworks basierend auf dem Extraktions- und Transformationsprozess.
Senda Bouaziz, Ahlem Nabli und Faiez Gargouri gehören zu den genannten. Die Al-Baha-Universität befindet sich in der saudi-arabischen Provinz Riad. Vincenzo Piuri, CEO von MIR Labs, einem Machine Intelligence Research Laboratory in Auburn, Washington, ist für das Design und den Betrieb des Labors verantwortlich. Die Abteilung für Baumanagement und Immobilien an der Technischen Universität Vilnius Gediminas, Litauen. Die Dr. Arturas Kaklauskas School of Engineering an der Superior de Engineerharia do Porto ist eine angesehene Institution. Die Rechte treten 2021 in Kraft. Die Autoren und Springer Nature Switzerland AG haben die exklusiven Rechte zur Veröffentlichung des Buches.
Mongodb: Eine großartige Wahl für schnelle und einfache Datenspeicherung
MongoDB ist eher eine Datenwissenschaft als ein traditionelles Data Warehouse . Trotz seiner Fähigkeit, Daten zu speichern, ist MongoDB nicht als zentrales Repository zum Speichern aller Daten Ihres Unternehmens gedacht. MongoDB hingegen eignet sich am besten zum Speichern von Daten aus einer Vielzahl von Geschäftsfunktionen, die auf mehrere Plattformen verteilt werden müssen. NoSQL-Datenbanken erfreuen sich wachsender Beliebtheit, weil sie einfach zu verwenden, effizient zu verwenden und gut verteilt sind. Trotz der Tatsache, dass MongoDB kein traditionelles Data Warehouse ist, ist es eine ausgezeichnete Wahl für Unternehmen, die ein schnelles, benutzerfreundliches System zum Speichern von Daten aus verschiedenen Geschäftsbereichen benötigen.
Datenbank vs. Data Warehouse
Eine Datenbank ist eine Sammlung von Daten, die auf eine bestimmte Weise organisiert sind, typischerweise in Tabellen und Feldern. Ein Data Warehouse ist eine Datenbank, die speziell zur Unterstützung von Datenanalyse und Berichterstellung entwickelt wurde. Data Warehouses haben in der Regel eine denormalisiertere Datenstruktur als Datenbanken und enthalten häufig Funktionen wie einen Data Mart, bei dem es sich um eine Teilmenge des Data Warehouse handelt, die für eine bestimmte Gruppe von Benutzern entwickelt wurde.
Die Definition eines Data Warehouse ist weit gefasst. Entdecken Sie, wie einzigartig sie in ihren analytischen Fähigkeiten sind. Eine Datenbank wird häufig von Online-Transaktionsverarbeitungsanwendungen verwendet. Im Laufe der Zeit kann es hilfreich sein, zu sehen, wie sich Datentrends geändert haben. Es gibt ein Data Warehouse, das Sie dabei unterstützen kann. Data Warehouses speichern und indizieren Spalten mithilfe der Datentabellenstruktur. Columnstore-Indizes werden in dieser Technologie verwendet, die sowohl komplex als auch einfach zu verstehen ist.
Da sowohl Datenbanken als auch Data Warehouses relationale Datenstrukturen verwenden, kann es sich lohnen, dort eine zu verwenden, wo sie am nützlichsten ist. Infolgedessen bietet Ihnen eine zeilenbasierte Datenbank nicht die Leistung, die Sie bei der Durchführung von Datenanalysen benötigen. Microsoft Redshift, Google BigQuery und BigQuery von Google sind nur einige der besten Cloud Data Warehouses. Fivetran ist das beste Cloud Data Warehouse zum Replizieren von Daten aus Ihren OLTP-Systemen.
Es ist wichtig, sich daran zu erinnern, dass sowohl das Data Warehouse als auch die Datenbank darauf ausgelegt sind, Daten auf vielfältige Weise zu verarbeiten. Das Data Warehouse besteht aus zwei Teilen: Datenlesen und Datenschreiben. Die Fähigkeit, analytische Leistung zu nutzen, um den täglichen Betrieb eines Unternehmens effizient zu verwalten, ist möglich, ohne seine Transaktionssysteme zu beeinträchtigen.
Mit einem Data Warehouse können Sie Daten auch schnell analysieren. Dies liegt daran, dass sich die Data-Warehouse-Verarbeitung von der Datenbankverarbeitung unterscheidet. Data Warehouses bieten nicht nur eine schnellere Datenanalyse, sondern auch diese.
Das Data Warehouse: Hauptunterschiede und Vorteile
Im Gegensatz zu einem Data Warehouse hilft ein Datenverarbeitungssystem bei der schnellen und präzisen Beantwortung komplexer Fragestellungen. Es ist beispielsweise in der Lage, umfangreiche Datensuchen durchzuführen.
Liste der Nosql-Datenbanken
Es gibt viele Arten von NoSQL-Datenbanken, jede mit ihren eigenen Stärken und Schwächen. Die beliebtesten NoSQL-Datenbanken sind MongoDB, Cassandra und Redis.
NoSQL-Datenbanken können verwendet werden, um Daten eher konzeptionell als in relationalen Datenbanken zu speichern. In diesem Artikel gehen wir auf MongoDB, Cassandra, Elasticsearch, Amazon DynamoDB, HBase und andere ein, die die meisten NoSQL-Datenbankplattformen sind. Wenn wir den vollständigen Text eines Artikels finden müssen, ist dies die Datenbank für unsere Organisation. Eine Datenbank wie diese ist nützlich, um große Datenmengen zu speichern und zu analysieren. Amazon DynamoDB wird hauptsächlich für Hochleistungsanwendungen aller Größenordnungen verwendet und kann auf vielfältige Weise konfiguriert werden. Rund 700 Organisationen nutzen diese Datenbank, die an einem einzigen Tag 10 Billionen Anfragen bearbeiten kann. DynamoDB ist die beste Wahl für die Verarbeitung einer großen Anzahl von Abfragen bei der Durchführung einer einfachen Schlüsselwertabfrage. Es gibt eine Datenbank, die Petabyte an Daten verarbeiten kann, aber wenn wir eine kleine Menge haben, können sie uns nicht das gewünschte Ergebnis liefern. In unserem Anwendungsfall ist diese Datenbank die beste Option, wenn wir zufällig und in Echtzeit auf Daten zugreifen müssen.
Die 5 Arten von Nosql-Datenbanken
Als Ergebnis stehen jetzt fünf Arten von nosql-Datenbanken zur Verfügung.
MongoDB ist das beliebteste Betriebssystem, gefolgt von Cassandra, HBase, Neo4j und Redis.