
Warum objektrelationale Zuordnung verwenden, um relationale Daten in einer NoSQL-Datenbank zu speichern?
Veröffentlicht: 2022-11-22Relationale Daten werden in einer NoSQL-Datenbank mit einer Technik namens „Object-Relational Mapping“ (ORM) gespeichert. Diese Technik ordnet die Objekte in einer relationalen Datenbank der NoSQL-Datenbank zu. Die Objekte werden dann als Dokumente in der NoSQL-Datenbank gespeichert. Die ORM-Technik wird verwendet, um die Beziehungen zwischen den Objekten in der relationalen Datenbank auf die Dokumente in der NoSQL-Datenbank abzubilden. Diese Technik wird verwendet, um die Daten in einer NoSQL-Datenbank zu speichern.
Daten werden in Dokumenten und nicht in Tabellen in NoSQL-Datenbanken gespeichert. Sie sind darauf ausgelegt, die Anforderungen der heutigen Datenverwaltung von Unternehmen zu erfüllen, unabhängig davon, ob sie flexibel, skalierbar oder schnell reaktionsfähig sind. Dokumentdatenbanken, Schlüsselwertspeicher, Datenbanken mit breiten Spalten und Diagrammdatenbanken sind Beispiele für NoSQL-Datenbanken. Global-2000-Unternehmen setzen zunehmend NoSQL-Datenbanken ein, um unternehmenskritische Anwendungen zu unterstützen. Es gibt fünf Haupttrends, die es erforderlich machen, die meisten relationalen Datenbanken aufgrund ihrer technischen Herausforderungen zu vermeiden. Relationale Datenbanken sind aufgrund ihres festen Datenmodells ein großes Problem für die agile Entwicklung, da ihnen die erforderliche Agilität fehlt. Das Anwendungsmodell ist das primäre Modell, das zum Definieren eines NoSQL-Datenmodells verwendet wird.
Das NoSQL-Modell versucht nicht, das Datenmodell zu definieren. Dokumentorientierte Datenbanken verwenden JSON als primäres Format zum Speichern von Daten. Der Overhead von ORM-Frameworks entfällt und die Entwicklung von Anwendungen wird vereinfacht. SQL to JSON kann jetzt mit der neuen Sprache N1QL (ausgesprochen „Nickel“) in Couchbase Server 4.0 erweitert werden. Es unterstützt nicht nur standardmäßige SELECT / FROM / WHERE-Anweisungen, sondern auch Aggregation (GROUP BY), Sortierung (SORT BY), Joins (LEFT OUTER / INNER) und so weiter. Es gibt zahlreiche betriebliche Vorteile für verteilte NoSQL-Datenbanken, die mit einer Scale-out-Architektur erstellt wurden und keinen Single Point of Failure enthalten. Es wird immer wichtiger, eine zuverlässige Website und mobile App zu haben, da Kunden online und persönlich mit uns in Kontakt treten.
NoSQL-Datenbanken können schnell und einfach erstellt, konfiguriert und skaliert werden. Sie wurden entwickelt, um eine Vielzahl von Geräten aufzunehmen, die Daten lesen, schreiben und speichern. Darüber hinaus können sie in jeder Größenordnung bereitgestellt werden, einschließlich der Verwaltung und Überwachung von Clustern unterschiedlicher Größe. Eine verteilte NoSQL-Datenbank ist so aufgebaut, dass sie über mehrere Rechenzentren hinweg repliziert werden kann, wodurch es einfach ist, mit nur wenigen Klicks eine NoSQL-Datenbank zu erstellen. Die Möglichkeit, sofortige Hardware-Router zu aktivieren, stellt sicher, dass Anwendungen ihr eigenes Failover durchführen können, anstatt darauf zu warten, dass eine Datenbank ein Problem erkennt und ihr eigenes durchführt. NoSQL-Datenbanken werden in den heutigen Web-, Mobil- und Internet-of-Things-Anwendungen immer beliebter.
Die relationale Datenbank ist eine Sammlung von Informationen, die Daten in vordefinierten Beziehungen organisiert, in denen Daten in einer oder mehreren Tabellen (oder Beziehungen) von Spalten und Zeilen gespeichert werden, wodurch es einfach ist, zu sehen und zu verstehen, wie Datenstrukturen zueinander in Beziehung stehen.
Transaktionen werden von NoSQL-Datenbanken nicht unterstützt (nur einfache Transaktionen werden unterstützt). Transaktionen (auch Joins genannt) können mit der relationalen Datenbank durchgeführt werden. NoSQL-Datenbanken sind ideal für den Umgang mit sich schnell bewegenden Daten. Daten, die in einem langsam verschlüsselten Zustand ankommen, werden von einer relationalen Datenbank verarbeitet.
Das Ziel von NoSQL-Datenbanken (auch bekannt als nicht nur SQL) ist es, Daten auf natürlichere, nicht tabellarische Weise als herkömmliche Datenbanken zu speichern. Basierend auf dem verwendeten Datenmodell können NoSQL-Datenbanken in verschiedene Typen eingeteilt werden. Ein Dokument kann einen Schlüsselwert, eine breite Spalte oder ein Diagramm enthalten.
Ein Schlüssel ist ein Datensatz mit einer eindeutigen ID, die eine Zeile in einer relationalen Datenbank darstellt. Die Spalten der Tabelle enthalten die Attribute der Daten, und jeder Datensatz hat seinen eigenen Wert für jedes Attribut, was es einfach macht, Datenpunkte zuzuordnen.
Wie werden relationale Daten in einer Nosql-Datenbank gespeichert?
Relationale Daten werden in einer nosql-Datenbank mit einer Technik namens „Object-Relational Mapping“ (ORM) gespeichert. Diese Technik ermöglicht es der nosql-Datenbank, die Daten auf eine Weise zu speichern, die mit der Art und Weise kompatibel ist, wie relationale Datenbanken Daten speichern. Dadurch ist es möglich, Daten in einer nosql-Datenbank mit den gleichen Methoden zu speichern, die zum Speichern von Daten in einer relationalen Datenbank verwendet werden.
Es ist eine Art von Datenbank, die nicht auf SQL beschränkt ist. NoSQL-Datenbanken gibt es in vier verschiedenen Typen. Da jeder NoSQL-Typ ein anderes Datenmodell verwendet, können die Unterschiede zwischen ihnen erheblich sein. NoSQL-Implementierungen haben als eines ihrer Hauptmerkmale das Fehlen einer Datenbank. Es wird einige Zeit dauern, aber Schema, Daten-Clustering, Replikationsunterstützung und Konsistenz werden alle funktionieren. Eine Key-Value-Datenbank ist ideal für die Verwaltung von Sitzungsanfragen und das Caching in Webanwendungen. Die beste Datenabfrage erfolgt aus einem spaltenbasierten Speicher.
Die fünf Hauptaspekte von NoSQL sind API, Datenmodell, Schemaanforderungen, Skalierbarkeit und Datenintegrität. NoSQL-Datenbanken ermöglichen es, die Daten vollständig semantisch oder formfrei zu speichern. Als Ergebnis dieses Ansatzes haben Programmierer ein höheres Maß an Flexibilität, was es einfacher macht, Entwicklungsaufgaben zu erledigen. Um die Integrität der Daten beim Erstellen, Lesen, Aktualisieren und Löschen durch Anwendung und Benutzer zu gewährleisten, unterscheiden sich NoSQL- und SQL-Datenbanken. Der Zweck von ACID besteht darin, sicherzustellen, dass Transaktionen im konsistentesten Datenbankzustand abgeschlossen werden und keine Auswirkungen erzeugt werden. Einzeln ausgeführte Transaktionen werden mit korrekten Ergebnissen abgeschlossen oder wirkungslos beendet. Datenbank NoSQL kann verwendet werden, um einige Datenbanken zu beschreiben, die vor der Entwicklung des relationalen Managementsystems (RDBMS) erstellt wurden. Der Begriff „Cloud“ bezieht sich auf Datenbanken, die in den frühen 2000er Jahren erstellt wurden, um Daten in großen Clustern für Cloud- und Webanwendungen zu speichern.
Aus verschiedenen Gründen werden NoSQL-Datenbanken immer beliebter. Da diese Workloads für Anwendungen mit geringer Latenz ausgelegt sind, erfüllen sie einen Zweck in Anwendungen, die auf sich schnell ändernde Daten reagieren müssen. Halbstrukturierte Daten werden häufig in NoSQL-Suchdatenbanken konvertiert, um analysiert zu werden. Datentypen wie dieser können in einer SQL-Datenbank schwierig zu modellieren sein, aber NoSQL-Suchdatenbanken erleichtern die Analyse und das Verständnis.
Nosql-Datenbanken für unterschiedliche Datenspeicheranforderungen
Wenn Daten in NoSQL-Datenbanken gespeichert werden, werden sie dann mit verschiedenen Programmiersprachen und Konstrukten abgefragt. Mögliche Arten von Datenbanken sind Dokumentdatenspeicher, spaltenorientierte Datenbanken, Schlüsselwertspeicher und Diagrammdatenbanken. Dokumentendatenspeicher sind beliebt, weil sie in der Cloud bereitgestellt werden können und für den groß angelegten Einsatz konzipiert sind. Daten, die in Tabellen organisiert sind, sind in spaltenorientierten Datenbanken am effektivsten. Ein Schlüsselwertspeicher kann Daten speichern, die über eine Datenbank verstreut sind, während eine Diagrammdatenbank Daten ähnlich denen eines Diagramms speichern kann.
Wie speichern relationale Datenbanken Daten?
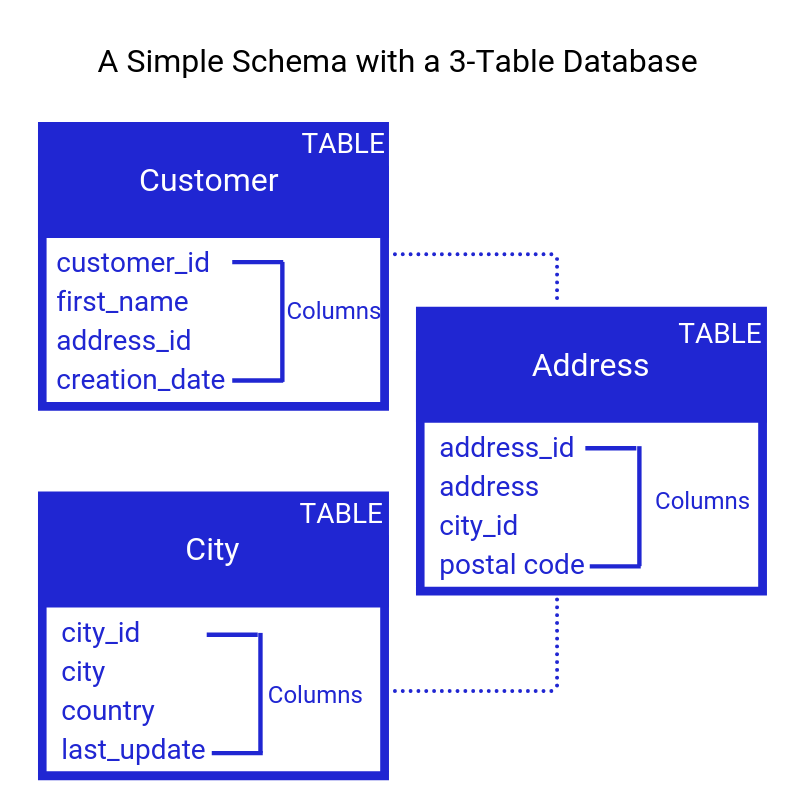
Relationale Datenbanken speichern Daten in Tabellen. Tabellen ähneln Ordnern in einem Dateisystem, in dem jede Tabelle eine Sammlung von Informationen speichert. Tabellen bestehen aus Spalten und Zeilen, wobei jede Spalte eine Information und jede Zeile einen Datensatz darstellt.
Eine relationale Datenbank besteht aus Informationen, die gemäß einer Reihe definierter Beziehungen organisiert sind. Sie werden im Unternehmen verwendet, um Daten zu organisieren und Beziehungen zwischen wichtigen Datenpunkten zu identifizieren. Es ist einfach, Informationen zu sortieren und zu finden, sodass Unternehmen fundiertere Entscheidungen treffen können. Eine relationale Datenbank enthält Informationen über Objekte und ihre Beziehungen. Benutzer definieren die Domäne eines möglichen Werts in einer Datenspalte und die Einschränkungen, die bei der Erstellung einer Datenbank auf diesen Wert angewendet werden können. Die Datenintegrität ist eine große Einschränkung, ebenso wie Fremdschlüssel und Primärschlüssel. Eine relationale Datenbank bietet auch physische Datenunabhängigkeit.
Es sind mehrere Datenbanken verfügbar, darunter solche, die nicht mit dem Internet verbunden sind, und solche, die nicht in relationalen Datenbanken oder NoSQL-Datenbanken verfügbar sind. Ein relationales Datenbankverwaltungssystem (RDBMS) und ein objektorientiertes Datenbanksystem (OODBMS) sind zwei Beispiele für ORDs. Im Allgemeinen werden Daten in einer Datenbank gespeichert. Es wird dann unter Verwendung einer Abfragesprache, die in der Abfragesprache nativ ist, darauf zugegriffen und manipuliert. Eine nicht relationale Datenbank, auch NoSQL-Datenbank genannt, enthält keine Datensätze. Es ist mehr als nur die Entscheidung für eine nicht-relationale Datenbank für ein Unternehmensprojekt. Berücksichtigen Sie die Art der verwendeten oder entwickelten Daten, wenn Sie bestimmen, welche Daten enthalten sein sollen. Bei der Entscheidung für eine Software für eine Datenbank ist es wichtig, bestimmte Initiativen in Betracht zu ziehen. Bei IoT-Initiativen steht viel auf dem Spiel, wenn es um NoSQL im Vergleich zu relationalen Datenbanken geht.
Eins-zu-eins-Beziehungen sind die häufigste Art von Beziehung. In einer Eins-zu-eins-Beziehung ist die Beziehung eines Segments zu einem anderen Segment begrenzt.
Die zweithäufigste Art von Beziehung ist eine Eins-zu-Viele-Beziehung. In einer Datenbank stellt die Anzahl der Segmente in einer Eins-zu-Viele-Beziehung die Anzahl der verwandten Segmente dar.
Die Viele-zu-Viele-Beziehung ist die dritthäufigste Art von Beziehung. Die Beziehung zwischen einem Segment und seinen Viele-zu-Viele-Gegenstücken in einer Datenbank wird als Viele-zu-Viele-Beziehung bezeichnet.
Wie wird eine relationale Datenbank gespeichert?
Tabellen bestehen aus Zeilen und Spalten in einer relationalen Datenbank. In der Regel können Daten mithilfe eines Primär- oder Fremdschlüssels verknüpft und über mehrere Tabellen hinweg strukturiert werden.
Datenspeicher: Vor- und Nachteile
Datenspeicher werden anhand ihrer Vor- und Nachteile in verschiedene Kategorien eingeteilt. Objektdatenbanken, NoSQL-Datenbanken und relationale Datenbanken sind einige der häufigsten Arten von Datenbanken.
Warum ist eine relationale Datenbank beim Speichern von Daten wichtig?
Eine relationale Datenbank ist eine Art Datenbank, in der eine eindeutige ID oder ein „Schlüssel“ verwendet werden kann, um auf Daten zuzugreifen, die in verschiedenen Tabellen gespeichert sind. Dieser Schlüssel ist nützlich, um Dateneinträge zu entsperren, die sich auf einen Schlüssel in einer anderen Tabelle beziehen, sodass Benutzer Inventar verwalten, Artikel versenden und eine Vielzahl anderer Dinge tun können.
Wie eine relationale Datenbank Ihrem Unternehmen helfen kann
Die relationale Datenbank kann auf vielfältige Weise verwendet werden, ihr Hauptzweck besteht jedoch darin, Daten zu speichern, die miteinander in Beziehung stehen. Daher können Geschäftsinhaber, die ihre Kunden, Produkte und Bestellungen im Auge behalten müssen, es verwenden.
Die relationale Datenbank kann auch zum Speichern von Daten verwendet werden, die Unternehmen täglich in ihrem Betrieb speichern. Kunden, Produkte, Bestellungen und andere Informationen werden alle auf diese Weise gesammelt. Folglich kann eine relationale Datenbank von Unternehmen jeder Größe verwendet werden.
Welches Datenbanksystem speichert Daten in relationalen Tabellen in Nosql?

Es gibt viele Datenbanksysteme , die Daten in relationalen Tabellen in nosql speichern, aber die beliebtesten sind MySQL, Oracle und Microsoft SQL Server. Jedes dieser Datenbanksysteme hat seine eigenen Stärken und Schwächen, daher ist es wichtig, dasjenige auszuwählen, das Ihren Anforderungen entspricht.
SQL-Datenbanken hingegen fehlt die Flexibilität und Skalierbarkeit, die NoSQL-Systeme wie Azure Table Storage bieten. Sie ermöglichen ein viel skalierbareres Speichersystem sowie die Möglichkeit, neue Datentypen einfach hinzuzufügen, ohne die vorhandene Datenstruktur zu beeinträchtigen. Da das Datenschema flexibler ist, können Entwickler Apps flexibler erstellen.
Wie unterscheidet sich die Nosql-Datenbankspeicherung von der relationalen SQL-Datenbankspeicherung?
MySQL-Datenbanken sind relationale Datenbanken, SQL-Datenbanken hingegen nicht. SQL-Datenbanken haben vordefinierte Schemata und verwenden eine strukturierte Abfragesprache. Dynamische Schemata werden in NoSQL-Datenbanken für unstrukturierte Daten verwendet. SQL-Datenbanken sind vertikal skalierbar, während NoSQL-Datenbanken horizontal skalierbar sind.

SQL ist eine Abfragesprache, die seit den 1970er Jahren verwendet wird. Eine NoSQL-Datenbank enthält im Gegensatz zu einer SQL-Datenbank keine verschachtelten Strukturen. NoSQL-Datenbanken können von Natur aus vertikal skaliert werden, sodass Sie mehr Ressourcen auf einen Server laden können. In einer NoSQL-Datenbank kann mit einer Vielzahl von Datenstrukturen gearbeitet werden. Da NoSQL-Datenbanken Daten nicht in Zeilen oder Tabellen speichern, verlassen sie sich nicht ausschließlich auf diese. Da sie mit dynamischen Schemas für unstrukturierte Daten umgehen können, ist es weniger wahrscheinlich, dass Daten im Voraus geplant und organisiert werden müssen. SQL- und relationale Datenbanken können eine große Anzahl von Datenpunkten verarbeiten, nach Bedarf skalieren und mehr Flexibilität beim Datenzugriff ermöglichen.
Da jede Information an einem einzigen Ort gespeichert ist, sieht eine frühere Version des Bildes jetzt nicht fehl am Platz aus. Darüber hinaus ist NoSQL eine ausgezeichnete Wahl, wenn es um große (oder sich ständig ändernde) Datensätze geht. Da große Datenmengen benötigt werden, sind große Datenbanken für große Unternehmen wie Facebook, Google und andere von entscheidender Bedeutung. Cassandra und andere NoSQL-Datenbanken verarbeiten enorme Datenmengen, die auf zahlreiche Server verteilt sind. Wenn Sie ohne starke Integritätsgarantien in kurzer Zeit auf einen Schlüsselwertspeicher zugreifen müssen, ist Redis möglicherweise die beste Wahl. Elastic Search ist eine ausgezeichnete Wahl, wenn es um eine komplexe oder flexible Suche geht.
NoSQL-Datenbanken haben die Art und Weise, wie wir über Datenspeicherung und -abruf denken, komplett verändert. Der Vorteil dieser Datenbanken gegenüber herkömmlichen relationalen Datenbanken liegt in ihrer Benutzerfreundlichkeit und Leistung. NoSQL-Datenbanken können große Mengen unstrukturierter Daten verarbeiten, insbesondere Dokumente, Multimedia- und Sensordaten. Viele der weltweit größten Online-Händler wie Amazon und eBay speichern riesige Mengen an Kundendaten in NoSQL-Datenbanken. Es gibt keinen Grund, warum NoSQL-Datenbanken nicht der De-facto-Standard für das Speichern und Abrufen von Daten sein sollten, da sie immer beliebter werden. Diese Datenbanken haben viele Vorteile gegenüber herkömmlichen relationalen Datenbanken und können in einer Vielzahl von Anwendungen verwendet werden.
Welcher Datentyp wird häufig in Nosql-Datenbanken gespeichert?
Es gibt viele verschiedene Arten von Daten, die in einer NoSQL-Datenbank gespeichert werden können, aber der häufigste Typ sind unstrukturierte Daten. Diese Art von Daten ist nicht durch ein bestimmtes Schema eingeschränkt, wodurch sie flexibler und einfacher zu skalieren sind als andere Datenbanktypen.
Die vier häufigsten Arten von NoSQL-Datenbanken sind Schlüsselwertspeicher, Dokumentenspeicher, spaltenorientierte Datenbanken und Diagrammdatenbanken. Das Problem, das nur durch einen dieser Typen gelöst werden kann, ist dasselbe wie das, das nur durch eine relationale Datenbank gelöst werden kann. OrientDB zum Beispiel ist eine NoSQL-Datenbank, die Modelle und Typen kombiniert. Durch das Hinzufügen von Verknüpfungstabellen und Entitätstypen kann eine relationale Datenbank aus vielen Entitäten bestehen. Die Daten einer Person oder Entität werden vollständig in einer Zeile angezeigt. Da nur wenige Spalten beteiligt sind, speichert die Datenbank jede Spalte separat, was zu schnelleren Scans führt. Im Gegensatz zu Indizes ordnen Spalten in Datenbanken Daten Zeilen zu.
Der Key-Value-Store ist in Bezug auf die Komplexität die am wenigsten komplexe NoSQL-Datenbank. Die Belege können wie bisher abgelegt und auf dieser Basis einfach abgefragt und berechnet werden. Normalisierung ist für Dokumentenspeicher nicht wichtig, solange die Daten sinnvoll strukturiert sind. Das Ziel grafischer Datenbanken besteht darin, die Verwaltung von Beziehungen zwischen Entitäten zu rationalisieren. Graphdatenbanken bestehen aus zwei Hauptkomponenten: Daten und Struktur. Dies ist die zuständige Stelle. Eine Linie verbindet zwei Einheiten; es stellt die Beziehung der Entität und ihre Eigenschaften dar. Graph-Datenbanken wie Neo4j behaupten, dass sie ACID-konform sind, während Key-Value-Speicher und Dokumentenspeicher sich an den Standard halten.
NoSQL-Datenbanken unterscheiden sich von herkömmlichen relationalen Datenbanken in Bezug auf die Zero-Downtime-Funktion. Bei relationalen Datenbanken kann es zu Systemausfallzeiten für Updates und Reparaturen kommen, was für Unternehmen kostspielig sein kann. Aufgrund von NoSQL ist es für Unternehmen einfach, ihre Daten auf dem neuesten Stand zu halten, ohne Ausfallzeiten einplanen zu müssen.
Darüber hinaus bieten NoSQL-Datenbanken eine flexiblere Datenstruktur, die es Unternehmen ermöglicht, ihre spezifischen Datenanforderungen zu erfüllen. Daher müssen sich Unternehmen bei der Entwicklung ihrer Daten in relationalen Datenbanken an vorgegebene Regeln und Strukturen halten, deren Änderung schwierig oder restriktiv sein kann.
Der Aufstieg von NoSQL-Datenbanken ist auf ihre Fähigkeit zurückzuführen, eine effizientere und flexiblere Lösung als herkömmliche Datenbanken bereitzustellen. Diese Lösungen sind ideal für Unternehmen, die ihre Daten ohne Ausfallzeiten auf dem neuesten Stand halten müssen, und sie bieten eine flexiblere Datenstruktur, die auf die Bedürfnisse jeder Organisation zugeschnitten ist.
Welche Art von Daten eignet sich am besten für Nosql?
Eine NoSQL-Datenbank eignet sich in der Regel besser zum Speichern und Modellieren strukturierter, halbstrukturierter und unstrukturierter Daten in einer einzigen Datenbank.
Welcher der folgenden ist ein Nosql-Typ?
Die vier Typen von NoSQL-Datenbanken sind Key-Value (KV) Stores, Document Stores, Column Family Data Stores und Graph Databases.
Arten von Nosql-Datenbanken
Eine NoSQL-Datenbank ist eine nicht relationale Datenbank, die nicht das traditionelle tabellarische Schema von Zeilen und Spalten verwendet. NoSQL-Datenbanken werden häufig für Big-Data-Anwendungen verwendet, die ein hohes Maß an Skalierbarkeit und Flexibilität erfordern. Es gibt vier Haupttypen von NoSQL-Datenbanken: Schlüsselwertspeicher, Dokumentenspeicher, Spaltenspeicher und Diagrammdatenbanken.
Die Verwendung von NoSQL-Datenbanken zur Erfüllung der Anforderungen alternativer Systeme wird als Äquivalent zu SQL-Datenbanken bezeichnet. Ein relationales Datenbankverwaltungssystem verwendet ein Zeilen- und Spaltentabellenmodell, während eine XML-Datenbank ein Datenmodell mit einer anderen Struktur verwendet. NoSQL-Datenbanken unterscheiden sich erwartungsgemäß voneinander. Dokumentendatenbanken mit großen Scale-out-Architekturen werden am häufigsten in Organisationen verwendet. Der Einsatz dieser Technologie in einer Vielzahl von Branchen, von E-Commerce-Plattformen über Handelsplattformen bis hin zur App-Entwicklung, ist von Vorteil. In diesem Artikel gehe ich darauf ein, wie MongoDB im Vergleich zu PostgreSQL abschneidet und was die führende NoSQL-Datenbank ist. Eine spaltenorientierte Datenbank kann nun die Werte verschiedener Spalten aggregieren.
Da sie Daten auf diese Weise schreiben, kann es für sie schwierig sein, eine starke Konsistenz zu haben. Graphdatenbanken sind für die Suche nach Datenelementen mit Verbindungen optimiert. Mehrere Tabellen in SQL können über diese Methoden JOINED werden, wodurch der Bedarf an SQL-Overhead eliminiert wird.
NoSQL-Datenbanken sind nicht nur flexibler und skalierbarer als herkömmliche SQL-Datenbanken , sondern werden auch immer beliebter. MongoDB ist die beliebteste NoSQL-Datenbank und eine Open-Source-Datenbank, die sich auf die Dokumentenverarbeitung konzentriert. Dies ermöglicht eine größere Flexibilität bei der Datenmodellierung und Abfrage. MongoDB hingegen unterstützt eine breite Palette von Programmiersprachen, wodurch es einfach zu erlernen ist. Datenbank NoSQL wird aufgrund ihrer höheren Flexibilität und Skalierbarkeit immer beliebter als SQL-Datenbanken. Wenn Sie mehr Flexibilität und Skalierbarkeit als eine SQL-Datenbank suchen, sind NoSQL-Datenbanken möglicherweise die beste Wahl für Sie.
Nosql-Datenbanken
Eine NoSQL-Datenbank ist eine nicht relationale Datenbank, die nicht das herkömmliche tabellarische Schema einer relationalen Datenbank verwendet. NoSQL-Datenbanken werden häufig für Big Data und Echtzeit-Webanwendungen verwendet.
Mit dem Fokus auf Skalierung, schnelle Abfragen und einfachere Programmierung wurden Ende der 2000er Jahre NoSQL-Datenbanken entwickelt. Da NoSQL-Datenbanken flexibel, horizontal skalierbar und einfach zu verwenden sind, können sie auf die Bedürfnisse von Entwicklern zugeschnitten werden. SQL-Datenbanken (Structured Query Language) mit starren, komplexen und tabellarischen Schemata sind ideal für den Zugriff über relationale Datenbanken. In MongoDB 4.0 werden jetzt mehrere ACID-Transaktionen sowie eine Erweiterung der Transaktionen in 4.2, um Sharding-Cluster zu umfassen, unterstützt. Datenmodelle werden in Nummer eins untersucht. Das Hauptziel von NoSQL-Datenbanken ist es, Daten für die Abfrage zu optimieren, anstatt die Datenduplizierung zu reduzieren. Als Teil von Nr.
Nein. Bei SQL-Datenbanken kann die Komprimierung auch den Speicherbedarf reduzieren. Graph-Datenbanken eignen sich hervorragend für die Analyse von Zusammenhängen, sind aber möglicherweise nicht in der Lage, alle Informationen bereitzustellen, die Sie täglich benötigen. Die Verwendung von MongoDB in Ihrem Anwendungsfall kann anhand des Whitepapers Where to Use MongoDB bestimmt werden. MongoDB Atlas ist eine großartige NoSQL-Datenbank für den Anfang. Sie können MongoDB von Grund auf mit der MongoDB University lernen, die völlig kostenlose Online-Schulungen anbietet.
Organisationen, die große Datenmengen verwalten müssen, können stark von NoSQL profitieren. Es ist nicht nur schnell und skalierbar, sondern auch sehr nützlich. Es ist ideal für große Datenanwendungen, da es sehr einfach zu bedienen ist.
Relationale Datenbanken
Relationale Datenbanken sind Datenbanken, die Daten in Tabellen speichern. Tabellen ähneln Ordnern in einem Dateisystem, in dem jede Tabelle eine Sammlung von Informationen speichert. Tabellen sind durch Beziehungen miteinander verbunden, die durch die darin enthaltenen Daten definiert sind. Beziehungen können Eins-zu-Eins-, Eins-zu-Viele- oder Viele-zu-Viele-Beziehungen sein.
Was ist eine relationale Datenbank? Die Tabelle besteht aus Zeilen und Spalten in einer relationalen Datenbank. Es ist normalerweise in Tabellen mit Primär- und Fremdschlüsseln angeordnet, die miteinander verbunden werden können. Eine relationale Datenbank ist ein Datenbanktyp, der Befehle und Transaktionen an einem einzigen Ort speichert. Die strukturierte Abfragesprache (SQL), eine Erfindung von IBM, ist eine Programmiersprache, die häufig in Datenbanken verwendet wird. Aufgrund eines Markenproblems wurde SQL in SEQUEL umbenannt und SEQUEL wurde entfernt. Es ermöglicht Benutzern, mit nur wenigen Codezeilen auf Daten in Datenbanken zuzugreifen.
Eines der erfolgreichsten Produkte von IBM ist die DB2-Datenbank. Da IBMs zweite Familie von Datenbankverwaltungssoftware als DB2-Familie bekannt ist, wurde die DB2-Familie relationaler Datenbanken 1983 eingeführt. Nichtrelationale Datenbanken erfordern kein so starres Datenbankschema wie relationale Datenbanken. Der Hauptvorteil einer relationalen Datenbank ist ihre Fähigkeit, aussagekräftige Informationen zu generieren, indem die Tabellen verknüpft werden. Wenn eine Bank- oder Finanztransaktion einen Fehler und eine erneute Übermittlung enthält, sind die Informationen möglicherweise besser als die vorherige. Obwohl relationale Datenbanken traditionell als eine starrere und unflexiblere Speicherlösung angesehen wurden, haben Fortschritte in der Technologie diese Perspektive obsolet gemacht. Bei cloudbasierten relationalen Datenbanken wird der Datenverlust bei einer Wiederherstellung in Sekunden oder Minuten gemessen. Die meisten relationalen Datenbanken verfügen über einfache Export- und Importoptionen, die Backups und Wiederherstellungen vereinfachen. Die Lesereplikation ermöglicht es Ihnen, eine schreibgeschützte Kopie Ihrer Daten in einem Cloud-Rechenzentrum zu speichern.
Dokumentorientierte Datenbanken wie MongoDB, Couchbase und Apache HBase sind aufgrund ihrer Flexibilität und Benutzerfreundlichkeit ideal für Rapid Application Development. Diese Datenbanken können schnell mit Daten aus verschiedenen Quellen gefüllt werden, was sie ideal für die Entwicklung von Anwendungen macht, die schnell auf sich ändernde Datenbedingungen reagieren.
Dokumentorientierte Datenbanken haben den zusätzlichen Vorteil, dass sie einfach vergrößert oder verkleinert werden können. Die Datenbank von MongoDB kann einfach erweitert werden, wenn eine bestimmte Anwendung mehr Speicherplatz benötigt. Wenn eine kleinere Anwendung heruntergefahren werden muss, können Couchbase und Apache HBase einfach herunterskaliert werden.
Dokumentorientierte Datenbanken sind aufgrund ihrer Benutzerfreundlichkeit, Skalierbarkeit und Geschwindigkeit eine ausgezeichnete Wahl für die schnelle Anwendungsentwicklung.
Die Vorteile relationaler Datenbanken
Relationale Datenbanken erfreuen sich immer größerer Beliebtheit, da sie gegenüber nicht relationalen Datenbanken eine Reihe von Vorteilen bieten. Es hat auch die Fähigkeit, nach oben und unten zu skalieren sowie Tabellen miteinander zu verknüpfen und so schnell wie möglich tabellenübergreifend zu suchen.