
Apriori アルゴリズムを使用してより良い製品を推奨する
公開: 2018-10-05この記事では、効果的な商品レコメンド方法(いわゆるカート分析)を学びます。 特殊なアルゴリズム(アプリオリアルゴリズム)を使用することで、どの商品をセットで売るかを学習します。 別の製品の Web サイトでどの製品を推奨するかについての情報を得ることができます。 このようにして、ストアのカートの平均値を増やします。
インテリジェントな製品レコメンデーション - クロスセル
オンラインストアで売上を伸ばす方法の1つに、関連商品の紹介があります。
残念ながら、このようなレコメンデーションの最も一般的な実装は、同じカテゴリの製品を表示することです。 表示している製品の下に、このタイプの他の製品が表示されます。たとえば、他のフットウェアのオファーです。
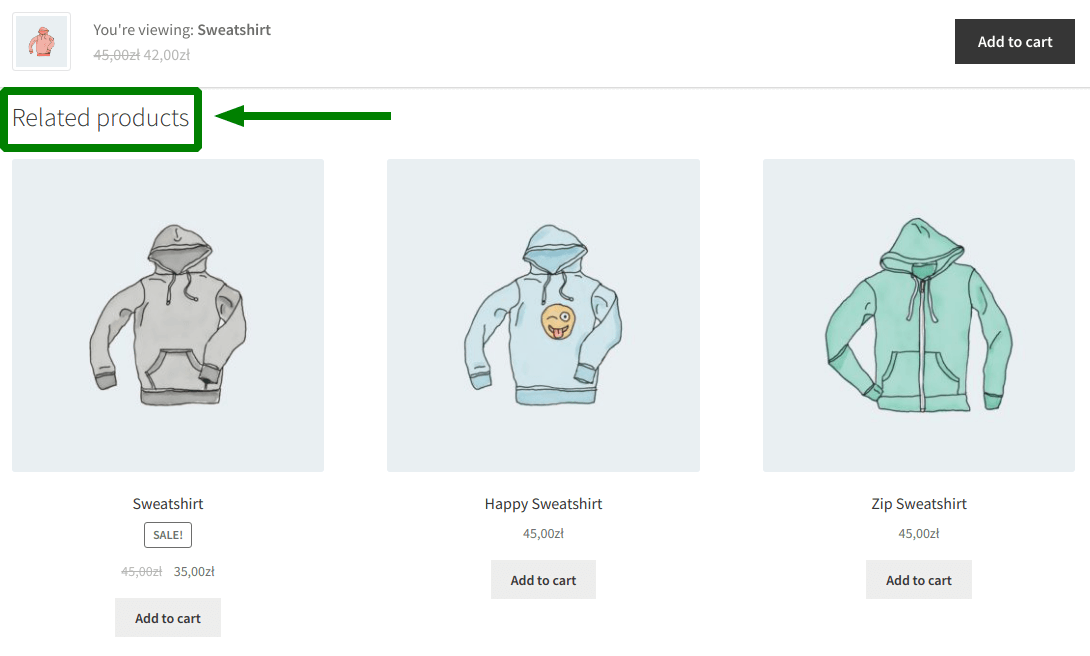
ただし、商品間の関係は、商品がストアに追加された共同カテゴリから生じるものではありません。 顧客がすでに 1 足をカートに入れているのに、他の靴を勧めても意味がありません。 このようにして、これが機能するかどうかを盲目的に推測します。 たぶん、顧客はカートに何か他のものを追加します。
製品レコメンデーションの本質は、顧客が明らかに興味を持っているような製品を提供することです。これらの製品が何であるかをどのように知ることができますか? 統計のおかげです! その助けを借りて、製品 A を購入する顧客の大半が B と C も購入していることがわかります。この場合、A をカートに入れる顧客には B と C をお勧めします。 この種の商品の推奨は、カート ページで最も効果的です。
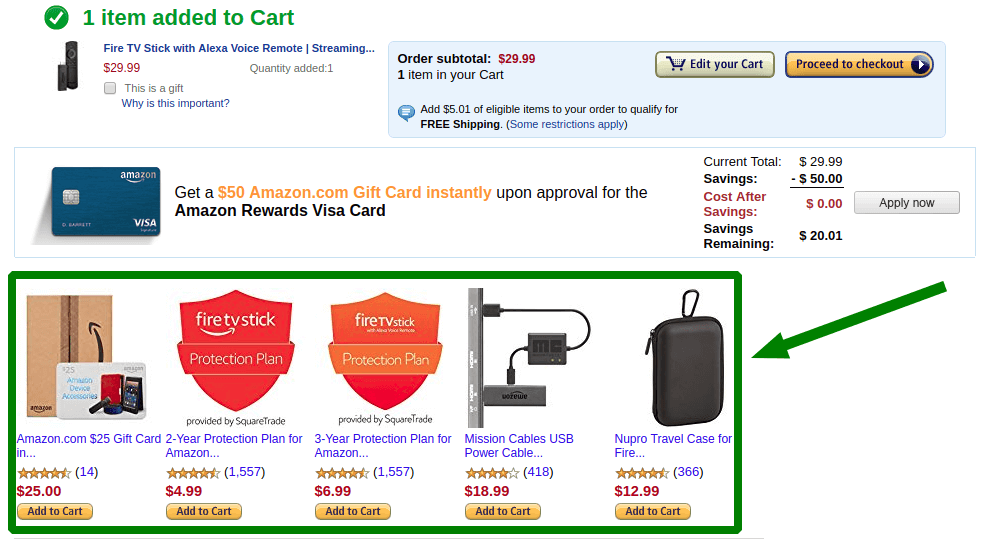
このようにして、購入を行う顧客は、他のアイテムを購入できるという情報を取得します。 特定の購入傾向を認識し、次の顧客への実装を容易にします。
便利なインターフェースのおかげで、後続の顧客は追加の製品を注文に追加します。 カートの価値が上がります。 お店はもっと稼げます。 誰もが満足しています :)
このようなアップセルの場合、アップセルされた製品に割引を適用できます。 このようにして、購入に対する顧客満足度が向上します。
一言で言えばアプリオリアルゴリズム
カート分析とは?
質問 - 製品の推奨のために製品注文から有用なデータを取得するにはどうすればよいですか? その答えは、いわゆるカート分析です。 データマイニングの手法です。
カート分析の効率的で一般的なアルゴリズムは Apriori アルゴリズムです。 このアルゴリズムは、データをマイニングする方法とその有用性を評価する方法を定義します。
顧客のカート内の製品のすべての相関関係がレコメンデーションに使用されるわけではありません。 ケースが1000回に1回発生した場合、そのような推奨事項を店舗レベルで実装しても意味がありません. これは傾向ではなく、単一のケースです。
効果的な実施例
オンラインでは、カート分析が 1990 年代にウォルマートによって使用されたという情報を見つけることができます。 米国最大のハイパーマーケット チェーンの 1 つです。 カート分析のおかげで、ビールとおむつの強い関係が発見されました。 このような奇妙な相関関係は、データ マイニングの結果です。
要するに、ビールと赤ちゃんのおむつは、金曜日の夜に若い男性によって購入されることがよくありました。 この知識のおかげで、アナリストはストアに変更を加えました。 まず、これらの製品をより近づけます。 第二に、彼らはマーケティング活動を変更しました。 大規模なハイパーマーケットでは、すべてのプロモーションと割引が製品に適用されます。 金曜日は、2商品のうち1商品のみ値引きすることが決定しました。 ほとんどの場合、いずれにしても両方とも購入されます。 このようにして、店舗は追加の売上を獲得し、マーケティング活動を節約しました.
従来の店舗の分析で使用される原則と方法の多くは、電子商取引にも適用できます。 それらのいくつかは、実装がより簡単です。 当社のオンライン ストアは、クリック、トラフィック、サイトでの滞在時間など、簡単に監視できます。 カート内の製品に関するデータを使用して、レコメンデーション システムを改善することも価値があります。
ここでの良い例はAmazonです。 注文の 20% 以上は、さまざまな種類のレコメンデーション システムの助けを借りて生成されます。
基本概念
Apriori アルゴリズムは、製品間の関係を示すだけでなく、その設計のおかげで重要でないデータを拒否できます。 この目的のために、2 つの重要な概念を紹介します。
- サポート- 発生頻度
- 信頼- ルールの確実性
このアルゴリズムにより、これら 2 つの指標の最小値を決定できます。 したがって、推奨の品質の前提条件を満たさないトランザクションは拒否されます。
このアルゴリズムの操作は反復的です。 すべてのデータを一度に処理するわけではありません。 これにより、アルゴリズムはデータベースでの計算数を制限します。
実際のアルゴリズムの動作をお見せします。 Apriori アルゴリズムの重要な要素として、サポートと信頼の使用について説明します。
アプリオリアルゴリズムの動作原理
たとえば、初期の仮定
簡単な例を使用してみましょう。 ストアに 4 つの製品 (A、B、C、D) があるとします。顧客は 7 つのトランザクションを行い、次のようになります。

- あいうえお
- A、B
- B、C、D
- A、B、D
- B、C
- CD
- B、D
Apriori を使用して、製品間の関係を判断します。 サポートとして、値を 3 に設定します。これは、指定された反復でルールが 3 回発生する必要があることを意味します。
最初の繰り返し
最初の繰り返しを始めましょう。 製品が注文に表示される頻度を決定します。
- A - 3回
- B - 6回
- C - 4回
- D - 5回
これらの製品はそれぞれ、3 回以上注文されました。 すべての製品がサポート要件を満たしています。 次の繰り返しでそれぞれを使用します。
2回目の繰り返し
次に、2 つの製品のセットに基づく製品の接続を探します。 顧客が選択した 2 つの製品を 1 回の注文でまとめる頻度を調べます。
- A、B - 3回
- A、C - 1回
- A、D - 2回
- B、C - 3回
- B、D - 4回
- C、D - 3回
ご覧のとおり、集合 {A, C} と {A, D} はサポートの仮定を満たしていません。 発生回数は 3 回未満です。 したがって、次の反復からそれらを除外します。
3 回目の繰り返し
次の 3 つの製品で構成されるセットを探します。
- 顧客注文で発生
- セット {A, C} および {A, D} 自体を含まない
したがって、{B、C、D} のセットです。 注文が2回しか発生しないため、サポートの前提を満たしていません。
結果
私たちの仮定は、次のセットを満たしています。
- A、B - 注文で 3 回発生
- B、C - 3回も
- B、D - 4回
この例は、アルゴリズムの動作を説明することのみを目的としています。 ほとんどのオンライン ストアでは、データの計算は、より多くのデータが存在するため、はるかに複雑になります。
パーセントで表されるサポート
サポートによって、すべてのトランザクションにおけるルールのグローバル シェアが定義されることを追加する価値があります。 最小要件を数値 3 でサポートすることに同意しました。ただし、パーセンテージを設定することもできました。 この場合:
- A、B は約 42.9% のサポートを持っています - それらは 7 回のトランザクションで 3 回発生します
- B、C は同じサポートを持っています
- B、D は約 57.14% のサポートを持っています - それらは 7 回のトランザクションで 4 回発生します
この例では、サポートファクターの割合が高いのは、製品の数が少ないためです。 A、B、C、Dの4つの製品しかありません。
たとえば、1000 個の商品を扱う店舗で、注文の半分に同じ商品が常に 2 つあるということはほとんどありません。
この例は意図的に単純化されています。 ストアでアルゴリズムを使用する場合は、これを考慮する必要があります。 支援の最小値は、店舗、業種などで個別に設定する必要があります。
最終的な結論
自信の問題は残ります。 初期セットが発生したすべてのルールに対して、特定のルールの発生を指定します。
計算方法は?
{A, B} - 3 回の注文が発生 初期設定は A です。この商品も 3 回の注文が発生しています。 したがって、信頼度は 100% です。
このペアを鏡像化しましょう。 {B, A} は 3 回の注文で発生しました。 ここでは何も変わっていません - ペアは同じです。 ただし、初期設定は変更されます。 Bです。 この商品は、6回の取引があります。 これにより、50% のレベルで自信が持てます。 製品 A は、製品 B が発生したトランザクションの半分でのみ発生しました。
- A と B の信頼度は 100%
- B と A の信頼度は 50%
- B と C の信頼度は 50%
- C と B の信頼度は 75%
- B と D の信頼度は 66.7%
- D と B の信頼度は 80%
簡単な例 (4 つの製品、7 つのトランザクション) から、次の推奨事項が得られます。
- A -> B
- B -> D
- C -> B
- D -> B
最初の製品は、ユーザーがカートに追加した製品です。 2つ目は、これがおすすめです。
結論
カート分析は、商品レコメンドシステムにとって非常に有効な手法です。 しかし、上記のアルゴリズムに従って手動でデータを処理することは想像できません。 特に大型店は。
効果的なカート分析には、便利な実装が必要です。 Apriori アルゴリズムは、手動のデータ処理ではなく、プログラムの原則に基づいて機能する必要があります。
ネットワーク上には、Python での Apriori Algorithm の実装があります。
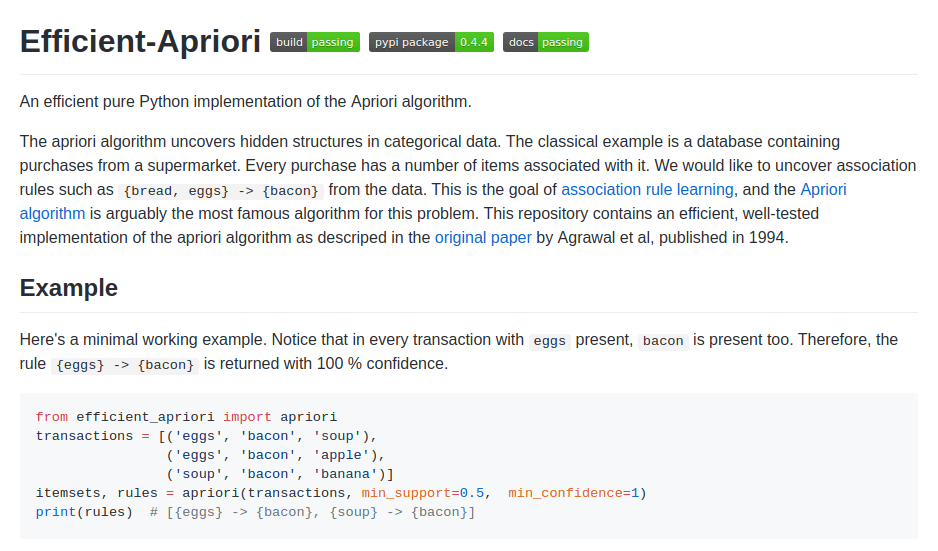
ただし、スクリーンショットでわかるように、それを使用するにはプログラミングのスキルが必要です。
また、eコマースのヒントもチェックしてください→