
Hadoop HDFS と NoSQL: ビッグデータ向けの強力な組み合わせ
公開: 2023-01-05Hadoop は、単純なプログラミング モデルを使用してコンピューターのクラスター間で大規模なデータ セットの分散処理を可能にするオープン ソース フレームワークです。 HDFS は、スケーラブルでフォールト トレラントなデータ格納方法を提供するHadoop 分散ファイル システムです。 NoSQL データベースは、従来のリレーショナル データベースに代わるスケーラブルで柔軟な高性能のデータベースを提供するように設計された新しいクラスのデータベースです。
Hadoop と HDFS の主な違いは、Hadoop がデータを保存、処理、分析するためのオープン ソース フレームワークであるのに対し、HDFS はユーザーが Hadoop データにアクセスできるようにするファイル システムであることです。 その結果、HDFS はHadoop モジュールです。
SQL と Hadoop はどちらも、さまざまな方法でデータを管理できます。 Hadoop フレームワークはソフトウェア コンポーネントの組み立てに使用され、SQL フレームワークはデータベースの組み立てに使用されます。 ビッグデータの場合、各ツールの長所と短所を考慮することが重要です。 Hadoop プラットフォームはデータを一度だけ保存しますが、Hadoop ははるかに多くのデータセットを保存します。
Hadoop はデータベースではなく、大規模な並列コンピューティングを可能にするソフトウェアです。 このテクノロジーにより、NoSQL データベース (HBase など) は、パフォーマンスをほとんど低下させることなく、数千のサーバーにデータを分散させることができます。
Hadoop は、リレーショナル ストレージと同じ方法でデータを保存しません。 分散サーバーは、それを最もよく使用するアプリケーションの 1 つです。 Hadoop データベースですが、HDFS (分散ファイル システム) にファイルを格納するため、リレーショナル データベースとは言えません。
NosqlとHdfsの違いは何ですか?
ファイルシステムであり、ファイルシステムとも呼ばれます。 このアプリが多くの機能を提供することはすでに明らかです。 この NOSQL はどこで入手できますか? リレーショナル データベースやその他の機能を使用する必要がないため、大量のデータをリアルタイムで処理できます。
Hadoop で実行される HBase ストレージ マネージャーは、低レイテンシーのランダム読み取りと書き込みを提供します。 HBase システムは、大きなテーブルが動的に分散される自動シャーディング機能を採用しています。 各リージョン サーバーは一連のリージョンにサービスを提供する責任があり、1 つのリージョンにサービスを提供できるリージョン サーバーは 1 つだけです (つまり、HMaster と HRegion は、HBase によって提供される主要なサービスの 2 つです。HBase テーブルの HRegion コンポーネントが処理を担当します)。テーブルのデータのサブセット. リージョン サーバーが起動されると、各リージョンに割り当てられます. その結果、マスターは読み取りおよび書き込み操作に関与しません.
構造化されていない膨大なデータの処理に関しては、MongoDB や Cassandra などの NoSQL データベースが従来のリレーショナル データベースよりも際立っています。 ビッグ データなどの大規模なデータ ワークロードを扱う企業は、これらのツールを使用して、大量の多様な非構造化データを迅速に処理および分析することを好みます。 MongoDB はコレクションにデータを格納しますが、hadoopは HDFS と呼ばれる別のファイル システムにデータを格納します。 この違いの結果として、異なるアーキテクチャを持つことは有利です。 また、個々のファイルを検索するよりも、MongoDB でデータをクエリする方がはるかに高速です。 さらに、mongodb は大量の環境向けに設計されているため、比較的低コストで大量のデータを処理するのに適しています。 ビッグ データ ソリューションを必要とする企業は、NoSQL データベースを使用することをお勧めします。 処理速度と分析の点で従来のデータベースよりも多くの利点があり、大規模なデータ分析と管理に適しています。
Hadoop は Nosql データベースですか?
Hadoop は、従来のリレーショナル データベース管理システムではありません。 これは、汎用サーバーのクラスター全体で大規模なデータ セットを保存および処理するのに役立つ分散ファイル システムです。 Hadoop は、単一サーバーから数千台のマシンにスケールアップできるように設計されており、それぞれがローカル コンピューティングとストレージを提供します。
超大規模なデータの使用は、新しいテクノロジーによって革命を起こしています。 ビッグ データ インフラストラクチャには、Hadoop、NoSQL、Spark など、多数のプレイヤーがいます。 DBA とインフラストラクチャ エンジニア/開発者は、新しい種類の DBA とインフラストラクチャ エンジニアの複雑なシステムを管理するために、彼らのために働いています。 Hadoop はデータベースではなくソフトウェア エコシステムであるため、大量のデータを効率的かつ効果的な速度で計算できます。 それが処理する大量のデータに対して提供する利点は、ビッグデータ処理のゲームチェンジャーでした. 集中リレーショナル データベース システムで完了するのに 20 時間かかるような大規模なデータ トランザクションは、Hadoop クラスターではわずか 3 分で完了できます。
選択できる SQL 言語は複数あります。 純粋なドキュメント データベースである MongoDB は、NoSQL データベースの一種です。 もう 1 つの例として、ワイドカラム データベースの Cassandra があります。 もう 1 つは、グラフ データベースである Neo4j です。 この機能は SQL- on-Hadoopによって作成されました。 SQL-on-Hadoop は、確立された SQL クエリと Hadoop データ フレームワークを組み合わせた新しいクラスの分析ツールです。 SQL-on-Hadoop を使用すると、企業の開発者やビジネス アナリストは、SQL の使い慣れたクエリを実行できるようにすることで、コモディティ コンピューティング クラスターで Hadoop と連携できます。 SQL-on-hadoop の利点。 使いやすさに加えて、SQL-on-Hadoop の多くの利点は、エンタープライズ データの開発者やアナリストの時間とリソースを費やす価値があります。 まず、コモディティ コンピューティング クラスターで Hadoop を使用できるため、ビッグ データ分析をすばやく簡単に開始できます。 また、SQL-on-Hadoop を使用すると、使い慣れた SQL クエリを利用できるため、ビッグ データ分析の習得が容易になります。 さらに、SQL-on-Hadoop は、Hadoop の map/reduce 機能と、Hadoop が提供する豊富なデータ分析機能を提供します。
増加している Nosql データベース
その結果、スケーラビリティ、読み取り/書き込みパフォーマンス、およびデータの柔軟性により、NoSQL データベースの人気が高まっています。 DynamoDB、Riak、Redis など、市場には NoSQL データベースの良い例がいくつかあります。
Hive は、優れたパフォーマンス メトリックを備えた軽量のモジュラー NoSQL データベースです。 純粋な Dart プログラミング言語で書かれており、そのシンプルさから開発者の間で人気があります。
Hadoop とデータベースの違いは何ですか?

RDBMS はデータを保存および処理しませんが、Hadoop はデータを分散ファイル システムとして保存および処理します。 一方、RDBMS は、データを行と列に格納し、SQL で更新してさまざまなテーブルで表示できる構造化データベースです。
ビッグデータのテクノロジーとツールの採用は急速に拡大しています。 オープンソースの Hadoop ディストリビューションは、分散ファイル システムで実行され、大規模なデータ セットの交換と処理を可能にします。 RDB は、Microsoft SQL Server、Oracle、MySQL などのすべてのデータベース管理システムで最も単純な形式で使用される基本的なデータベース管理システムです。 RDBMS は進化として分類されていますが、主要な事業というよりも、他の標準データベースに似ています。 これはデータベースではなく、大量のデータ ファイルのコレクションを格納して処理できる分散ファイル システムです。 Hadoop のようなシステムはより優れたパフォーマンスを提供できますが、めったに説明されない欠点がいくつかあります。 Hadoop クラスター、セキュリティ、Presto、または使用するその他のインターフェイスを管理する方法を検討する必要があります。
SQL Server や Oracle などのリレーショナル データベース システムの大部分は、はるかに使いやすくなっています。 ほとんどの組織は、Hadoop を効果的に運用できる十分なスキルを持つ人材がいないという大きな問題に直面しています。 従業員が 10,000 人いる場合、従業員全員を追跡するには大量のデータが必要になります。 この情報は、Presto を使用してさまざまな方法で保存できます。 日付パーティションは、毎日の人の位置を格納するために使用できます。 一方、RDBMS はデータ モデルの例として使用できます。 この方法を使用する唯一の方法は、前日のデータに既にアクセスできる場合です。
リレーショナル データベースとビッグ データの主な違いは何ですか?
リレーショナル データベースとビッグ データの主な違いは、リレーショナル データベースは構造化データの格納に最適化されているのに対し、ビッグ データは非構造化データと半構造化データの格納に最適化されていることです。 リレーショナル データベースはリレーショナル モデルに基づいてモデル化されていますが、ビッグ データ データベースは分散モデルに基づいてモデル化されています。 構造化データは、効率的な方法でリレーショナル データベースに格納および処理できます。 テーブルにはデータが含まれており、構造化照会言語 (SQL) へのアクセスと取得が可能です。 ビッグデータは、非構造化または半構造化されたデータとして定義されます。

Hadoop と Mongodb の違いは何ですか?
MongoDB は C で実行されるため、他のどのデータベースよりもメモリ管理に優れています。 Hadoop は、データの保存、取得、および処理のためのフレームワークを提供する Java ベースのソフトウェア セットです。 Hadoop は、MongoDB よりも効果的にスペースを最適化します。
MongoDB は、C で作成された NoSQL (SQL だけではない) データベースでした。Hadoop は、大量のデータの処理を可能にする Java を主な構成要素とするオープンソース ソフトウェア プラットフォームです。 さらに、MongoDB Atlas には、全文検索、高度な分析、直感的なクエリ言語が含まれています。 Hadoop は大量のデータの保存と処理に効果的ですが、それは小さなバッチで行われます。 MongoDB には、さまざまな組み込みのリアルタイム データ処理ツールが用意されています。 Kafka や Spark などの外部ツール用のコネクタがあるため、MongoDB はデータの取り込みと処理をシンプルにします。 ビッグデータの分野における従来のデータベースに対する Hadoop と MongoDB の利点は数多くあります。 分散ファイル システムである Hadoop を使用すると、膨大なファイルを処理できます。 MongoDB は、パフォーマンスの点で従来のデータベースを置き換えることができる唯一のデータベースです。
Rdbms 対 Nosql 対 Hadoop
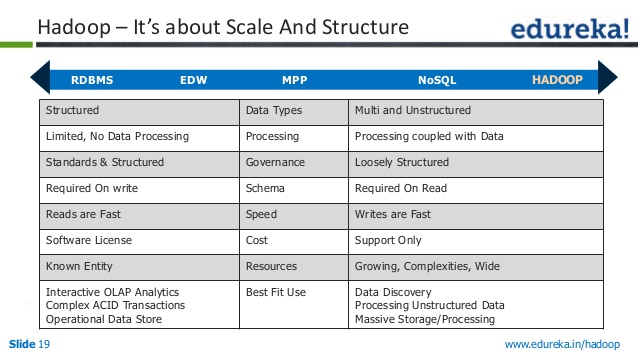
データ ストアには、主に RDBMS、NoSQL、Hadoop の 3 つのタイプがあります。 それぞれに長所と短所があるため、ニーズに合ったものを選択することが重要です。
RDBMS (リレーショナル データベース管理システム) は、最も一般的なタイプのデータ ストアです。 使いやすく、スケーリングも簡単です。 ただし、NoSQL や Hadoop ほど柔軟ではなく、維持費が高くなる可能性があります。
NoSQL (SQL だけではない) は、より一般的になりつつある新しいタイプのデータ ストアです。 RDBMS よりも柔軟で、よりスケーラブルです。 ただし、使いやすくはなく、維持費が高くなる可能性があります。
Hadoop は、ビッグ データ用に設計されたデータ ストアの一種です。 非常にスケーラブルで、大量のデータを処理できます。 ただし、RDBMS や NoSQL ほど使いやすくはなく、維持費が高くなる可能性があります。
データの保存、処理、および分析に対する企業のアプローチは、 Apache Hadoopプラットフォームによって大幅に改善されます。 データ レイクは、同じハードウェアとソフトウェアで複数のタイプの分析ワークロードを実行できるだけでなく、大規模なデータ ボリュームを管理できます。 アナリストは、Apache Impala や Apache Spark などのツールを使用して、外出先で効果的にデータを操作できるようになりました。 Hadoop は、リレーショナル データベース管理システム (RDBMS) とは異なり、データベースと同じ機能を備えていませんが、代わりに、大量のデータを処理できる分散ファイル システムに近いものです。 簡単かつ効果的に処理できるデータの量は、データ ボリューム ボリュームと呼ばれます。 つまり、最適化できるのは、特定の期間の総データ ボリューム プロセスです。 幅広いソースからのデータを保存および処理し、分析のために準備する機能があります。
少量では、RDBMS は構造化データと半構造化データしか管理できませんでした。 Hadoop は、さまざまなソースや構造化された構造からのデータを処理できません。 応答時間、スケーラビリティ、およびコストは、考慮すべきその他の重要な要素の一部です。
Rdbms が依然として最も人気のあるデータベース管理システムである理由
世界で最も広く使用されているデータベース管理システムは RDBMS です。 幅広い機能を提供するだけでなく、非常に信頼性が高いです。 リレーショナル データベースは、複数のユーザーがアクセスする必要があるデータを格納するのに最適です。
NoSQL データベースは、リレーショナル データベースよりもパフォーマンスが優れていることもあり、人気が高まっています。 また、複数のユーザーと共有する必要のない大量のデータを保存することもできます。
Hadoop Nosql
コモディティ ハードウェア クラスターでは、Hadoop はビッグ データを格納します。 必要に応じて、動作しない機能やニーズを満たす機能を変更するオプションがあります。 対照的に、 NoSQL データベース管理システムは、構造化データ、半構造化データ、非構造化データの格納に使用されるデータベース管理システムの一種です。
Hdfs はデータベースですか
HDFS ファイル システムは、コモディティ ハードウェア上で動作する分散ファイル システムです。 この機能を使用して、単一の Apache Hadoop クラスターを構成して、数百 (場合によっては数千) のノードをサポートできます。 MapReduce と YARN も含む Apache Hadoop は、いくつかの主要なコンポーネントで構成されています。
データへの高性能アクセスは、 Hadoop オペレーティング システムのコンポーネントである Hadoop 分散ファイル システム (HDFS) によって提供されます。 クラスタのプライマリ ネーム ノードは、クラスタのファイル データが格納されている場所を追跡する役割を果たします。 Name ノードは、ファイル アクセスの管理に加えて、読み取り、書き込み、作成、削除などのファイルへのアクセスを管理します。 Yahoo は、オンライン広告の配置と検索エンジンの要件の一部として、Hadoop 分散ファイル システムを導入しました。 HDFS プロトコルは、ユーザー データを格納するためにファイル システムの名前空間を公開します。 DataNode は相互に通信するため、通常のファイル操作中に相互に通信できます。 Hadoop 分散ファイル システム (HDFS) は、多くのオープン ソース データ レイクのコンポーネントです。 HDFS は、大量のデータを分析するために eBay、Facebook、LinkedIn、および Twitter で使用されています。 ノードまたはハードウェアに障害が発生した場合、HDFS が正常に機能するにはデータの複製が必要です。
Hadoop データベースの例
Hadoop データベースは、基礎となるストレージに Hadoop 分散ファイル システム (HDFS) を使用するデータベースです。 Hadoop データベースは通常、大きすぎて 1 台のサーバーに収まらない大量のデータを格納するために使用されます。
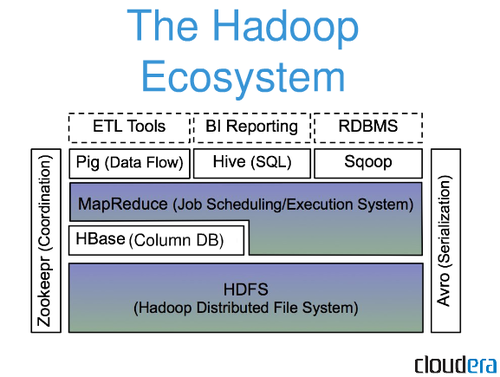
Apache Hadoop は、コモディティ ハードウェア上で大規模なデータ セットを分散方式で格納および処理するためのオープン ソース フレームワークであり、さまざまなアプリケーションで使用されています。 これは、2004 年の論文 MapReduce で使用された Google パラダイムのオープン ソース バージョンです。 この記事では、ビッグ データ エコシステムの初心者からよく寄せられる質問のいくつかについて説明します。 Apache Hadoop プラットフォームは、データベース ストレージやリレーショナル ストレージではなく、分散データ処理に重点を置いています。 処理に使用されるファイルを格納する HDFS (Hadoop Distributed File System) と呼ばれるストレージ コンポーネントが存在するにもかかわらず、HDFS はリレーショナル データベースのカテゴリに分類されます。 Hive と HiveQL を使用して、HDFS に組み込まれている HDFS のHDFS ストレージをクエリできます。
Hadoop の例は何ですか?
Hadoop は、金融サービス企業がリスクを評価し、投資モデルを構築し、取引アルゴリズムを作成するために使用できます。 Hadoop は、これらのアプリケーションの作成と管理を支援するためにも使用されています。 このテクノロジーは、構造化データと非構造化データを分析することで、小売業者が顧客をよりよく理解し、顧客にサービスを提供できるようにするために使用されます。
Hadoop のさまざまな用途
Hadoop を使用して、ビッグ データ分析、リアルタイム データ分析、科学研究、データ ウェアハウジングなどの大規模データ アプリケーションのデータを管理できます。 その結果、幅広いアプリケーションに最適な多用途で適応性の高いプラットフォームです。
SparkはNosqlデータベースですか
ドキュメントによると、NoSQL DataFrame は Spark DataFrame のデータ ソース形式です。 このデータ ソースでは、DataPruning とフィルタリング (述語のプッシュダウン) を使用できます。これにより、Spark クエリを少量のデータで実行でき、アクティブなジョブに必要なデータのみが読み込まれます。
Apache Spark と NoSQL (Apache Cassandra と MongoDB) データベースを相互に接続するには、多くの戦術的努力が必要です。 このブログは、NoSQL バックエンドで Apache Spark アプリケーションを作成する方法について説明しています。 TCP/IP sPark は人気のあるテーマ パークの目的地で、有名な CassandraLand と MongoLand セクションに多数の乗り物があります。 私たちの Spark アプリケーションが DOE からデータを検索していたとき、それは車輪を回転させてフラストレーションを感じました。 ここでの教訓は、Cassandra のキー シーケンスは、データをフェッチするプロセスにおいて重要であるということです。 CassandraLand には、Partitioner と呼ばれる人気のジェット コースターもあります。 ジェットコースターに乗っている顧客は、オペレーターが毎日誰が乗ったかを追跡できるように、乗車履歴を追跡することをお勧めします。 Mongo レッスン 1 – MongoDB 接続を正しく管理する エネルギー省の新しい公園メンバーシップのステータスなどのデータを更新する場合、Mongo インデックスは非常に役立ちます。 特定の更新の場合、MongoDB と Spark は適切な接続管理とインデックス作成を保証する必要があります。
Spark: ビッグデータの未来
Apache Software Foundation と共同で開発された分散処理システムである Apache Spark は、Hadoop ベースのビッグ データ処理システムです。 大規模なデータ セットを最適化し、手続き型モデルとリレーショナル モデルの間のギャップを埋めるために使用できるオープン ソース フレームワーク。 さらに、Spark は MongoDB をサポートしているため、リアルタイム分析と機械学習に使用できます。