
SQL データベースと Nosql データベースのスケーリング方法
公開: 2022-11-18Web アプリケーションの人気が高まり、それらが生成するデータの量が増えるにつれて、迅速かつ効率的にスケーリングできるデータベースの必要性がこれまで以上に重要になっています。 SQL データベースと NoSQL データベースは、スケーラブルなデータベース ソリューションを探している開発者にとって最も一般的な選択肢の 2 つです。 SQL データベースは何十年も前から存在しており、多くのアプリケーションで伝統的に選択されています。 これらは固定スキーマを使用します。つまり、データベースの構造は事前に定義されており、すべてのデータはそのスキーマに準拠する必要があります。 これにより、データ セットが大規模で複雑な場合、SQL データベースの操作がより困難になる可能性があります。 一方、NoSQL データベースは比較的新しく、大規模で複雑なデータ セットを処理するように設計されています。 それらには柔軟なスキーマがあります。つまり、必要に応じてデータベースの構造を変更できます。 これにより、NoSQL データベースの操作が容易になりますが、SQL データベースほど信頼性が高くない可能性があることも意味します。 スケーラビリティに関しては、SQL データベースと NoSQL データベースの両方に長所と短所があります。 SQL データベースは操作が難しくなりますが、信頼性は高くなります。 NoSQL データベースは操作が簡単ですが、信頼性が低い場合があります。
データベースの種類に応じて、さまざまなスケーリング手法と原則をデータベースに適用できます。 スケーリングは、NoSQL データベースと非 NoSQL データベースの両方にとって重要であり、データベース シャーディングの概念は重要な要素です。 サーバーが分散すると、分散システムの問題を継承しながら、より多くのデータを保存できるという利点が得られます。 メインフレーム データベースでは自動シャーディングがサポートされていないため、エンジニアは自動シャーディングを処理するロジックを手動で記述する必要があります。 解決策として、クエリ サービスとデータベースの前に、ロード バランサーなどのプロキシを配置します。 シャードが大きすぎる場合は、プロキシを再起動できます。これにより、クエリをより迅速に実行できます。 NoSQL データベースのスケーリングは、高度に自動化されたプロセスであり、エンド ユーザーだけが見ることができると広く考えられています。
マスター/スレーブ アーキテクチャはワンショット トランザクションに基づいていますが、シャード ベースのアーキテクチャはランダム トランザクションに基づいています。 スレーブ シャードに向けられた読み取りクエリは、マスター シャードの負荷を軽減します。 データベースをデータセンターレベルで複製して、バックアップを確保できます。 ノードは、情報を交換することによって相互に通信できます。 ノードが所定の数の他のノードと通信することは一般的です。 ノードは等しいと見なされるため、Cassandra のノードは、そのデータを他のノードに簡単に複製できます。 ゴシップ プロトコルは、ノードの概念全体のサブセットです。
分散データベースでは、より多くのプロパティを取得するために特定のプロパティを放棄する場合があります。 可用性を維持するためには、ほとんどの場合、データを複製することが重要です。 最初はデータベースの一貫性にわずかな違いがありますが、これは時間の経過とともに改善されます。 SQL データベースは金融システムのより高精度なデータに使用されますが、NoSQL データベースはビュー数などの重要度の低いデータに使用されます。
データベースをスケーリングする 2 つの方法は、垂直方向のスケーリングと、既存のデータベース マシンの CPU または RAM の増加です。 水平方向にスケーリングするために、データベース クラスターにマシンを追加して、全データのサブセットを処理します。
インターネットとクラウド コンピューティングの時代により、NoSQL データベースの作成が可能になり、スケールアウト アーキテクチャの実装が容易になりました。 スケールアウト アーキテクチャでは、データのストレージとその処理に必要な作業を多数のコンピューターに分散させる必要があります。
大量のデータを処理できることも利点です。 SQL データベースは垂直方向にスケーリングできるため、より多くの CPU、RAM、および SSD パワーを備えた大規模なサーバーをロードできます。
Nosql データベースはどのようにスケーリングしますか?
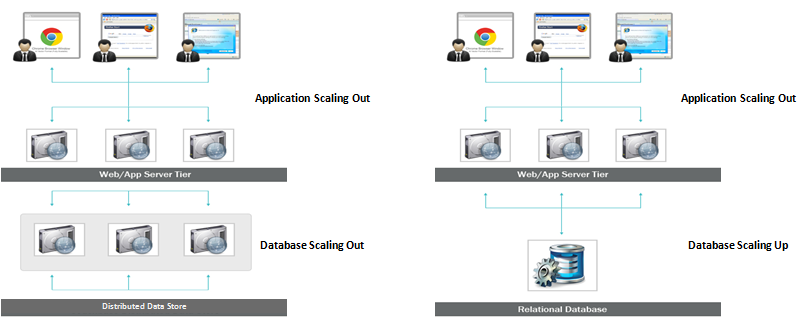
SQL データベースは垂直方向のスケーラビリティであるため、SQL データベースの RAM、SSD、または CPU を増やすことで、単一サーバーの負荷を増やすことができます。 一方、NoSQL データベースは水平方向にスケーラブルです。つまり、サーバーを追加することで、増加したトラフィックをより簡単に処理できます。
Couchbase の Rahim Yaseen が、いくつかの重要なポイントについて説明します。 大量のデータが組織に殺到し、データを管理、保存、活用する方法を模索しています。 データベース管理における重要な決定は、スケールアウトするかスケールアップするかです。 各登録が異なるブースに割り当てられる手動シャーディングにより、登録を複数のチェックイン ブースに分散できます。 明確に定義された事前定義されたスキームがあるため、機能します。 自動ダイヤルがある場合は、各ブースに行って姓が S の人を探す必要があります。ドキュメント データベースには、1 つのキーを介して直接データにアクセスし、別のドキュメントに移動する必要がある多数のキー ダイレクト アクセス パターンがあります。関連するキー。 セカンダリ インデックスとクエリは、分散データを扱う際の 2 つの大きな課題です。
クエリを実行するには、各ノードがクエリの実行に参加する必要があるため、map-reduce 手法を使用する必要はありません。 データ量が増大するにつれて、RDBMS スタイルのスケールアップはますます実用的ではなくなります。 大規模なデータ セットの基盤となるスケールアップ アーキテクチャに障害が発生すると、ほぼ確実に 1 つの大きな障害点が発生します。 超大規模なシェアード ナッシング クラスターの典型的な例として、インターネットがその 1 つです。
NoSQL データベースは、幅広いユーザーのニーズを満たすために水平方向にスケーリングできます。 特殊なハードウェアを必要とせずに、どのマシンでも使用できます。 その結果、NoSQL は、迅速なスケーリングを必要とするシステムや広範な知識を必要としないシステムに最適です。
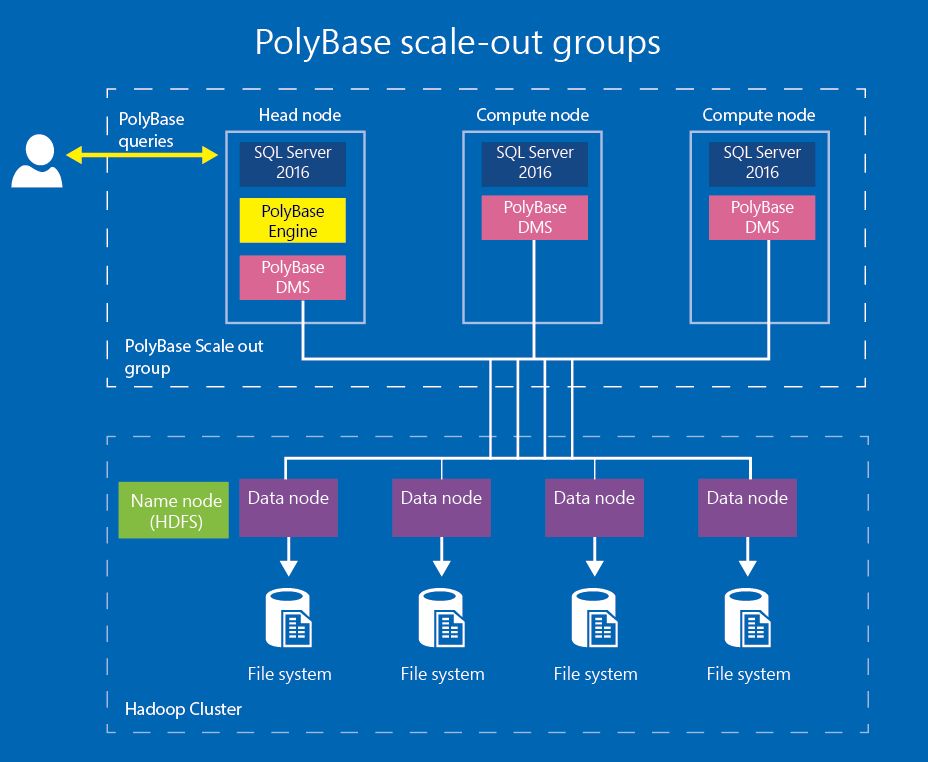
SQL データベースはどのようにスケーリングしますか?
スケールは、小数点の右側に値を持つ数値です。 There is a precision of 5 on this number, and a scale of 2. SQL Server では、numeric および decimal データ型は 38 ビットの最大精度を達成できます。 以前のバージョンのデフォルトの SQL Server の最大数は 28 でした。
この記事では、従来のリレーショナル データベースのスケーリングに関するいくつかの基本的な考え方と指針を提供します。 スケーリングは、より優れたハードウェアを使用して (単一のデータベース サーバー上で) 垂直方向に行う必要があることは広く受け入れられています。 データ型を選択するときは、効率と機能のバランスを取ることが常に重要です。 データの正規化と非正規化は、最適なデータ型について考えるための 2 つの基本的な方法です。 大量のデータを分析する場合、データの前処理が有益な場合があります。 テーブルに適切なインデックスを使用すると、パフォーマンスが大幅に向上します。 クエリ プランナーがクエリをどのように処理するかを正確に把握して、ジョブが適切に実行されるようにする必要があります。
データの構造を見ると、インデックスを追加するか、クエリを書き直すかを決定できます。 SQL:1992 標準で定義されている 4 つの基本的な分離レベルは、データベース システムの使用方法に大きく影響します。 アプリケーション層での圧縮が望ましい効果をもたらすかどうかを判断する前に、まず、データがどのように格納されているか、および圧縮が必要かどうかを調べる必要があります。 特定の場所に列を挿入すると時間がかかるため、テーブルの最後に新しい列を挿入することをお勧めします。 データベースのフードは、圧縮されたデータですでに散らかっている場合があります。 サーバーを追加することで書き込み操作を水平方向にスケーリングできますが、読み取り専用レプリカを使用して容量を拡張することもできます。 強力なパーティション分割により、データベース テーブル (シャード) の一部を異なるサーバーに格納できます。
シャーディングは、データベースにデータを格納するプロセスです。 TimescaleDb や PostGIS などの別のデータベース拡張機能を使用して、データ処理とストレージの効率を向上させることができます。 あるシステムから別のシステムにデータを転送し、そこで処理することができます。 Hadoop や Clickhouse などの分析データベースに送信することもできます。 Apache Spark ディストリビューションは、大規模なデータ計算に使用できる無料のオープンソースの分散クラスター コンピューティング ソフトウェアです。 データを移動する他の方法には、データベースのコピー、SQL を使用したデータの抽出などがあります。 AWS や Azure などのクラウド プロバイダーを選択する場合は、それらがマネージド SQL データベースをサポートしていないことに注意してください。
この制限は、複数のノードに分散された大規模なデータ セットを処理する場合に拡大されます。 これらのデータ セットは、MySQL Cluster によって管理可能なチャンクに分割され、ノードに並行して配布されます。 データベースにスナップショットがあれば、クエリが結果を返すのを待つ必要はありません。 その結果、このスケーラビリティの利点を利用して、大規模なデータ セットをリアルタイムで分析したり、データを一括処理したりできます。 MySQL Cluster は、その使いやすさから単純な操作を必要とするワークロードに最適な選択肢であり、従来のリレーショナル データベースと同じ機能を維持しながら、費用と時間を節約できます。 MySQL Cluster は、パフォーマンスを犠牲にせずにデータベースを水平方向にスケーリングしたい企業にとって優れたオプションです。 企業は、従来のリレーショナル データベース システムの代わりに、MySQL Cluster を利用することで費用と時間を節約できます。

アメリカ合衆国は自由の理念に基づいて設立された国です自由の国
Nosql または Sql はよりスケーラブルですか?
ほとんどの場合、SQL データベースは垂直方向に拡張できます。 1 台のサーバーをアップグレードして CPU、RAM、または SSD の容量を増やし、より多くのトラフィックを処理できます。 NoSQL データベースは水平方向にスケーリングできます。 シャーディングにより、NoSQL データベース内のサーバーの数を増やすことができ、より多くのトラフィックを処理できるようになります。
アプリケーションが複雑になるにつれて、アプリケーションにはより多くのスケーラビリティが必要になります。 効率的かつ簡単にスケーリングできるデータ ストアも検討する必要があります。 この 2 つの主な違いは、データベースを「ASL」にするか「NoSQL」にするかです。 SQL データベースは長い間使用されてきましたが、NoSQL データベースはスケーラビリティの容易さでよく知られています。 NoSQL データベースでのすべての操作では、シャーディングを使用する必要があります。 各データ操作には、データが存在するノードを識別する修飾メソッドが含まれている必要があります。 データは複数のマシンに保存されるため、低電力のマシンでもデータ操作が容易になります。
NoSQL ストアのスケーリングを容易にするために、単純な汎用マシンが使用されます。 NoSQL に基づいて、ユーザーは、特定の操作に必要なすべてのデータを同じノードから一度にフェッチできるように、データを事前に計画して構造化することを前提としています。 正規化するためには、ノード間でデータを正規化する必要もあります (操作用に事前に調理されたデータ)。 NoSQL ではファイルを結合できますが、構造が最適化された SQL スタイルの結合は期待できません。 NoSQL の世界のアプリケーションは、データの一貫性が時間の経過とともに保証されると信じています。 NoSQL システムが必要以上に整合性を変更するためのスイッチを提供することは理にかなっています。 他の側面と同様に、アーキテクチャを決定する際の重要な側面は、ユース ケースを見て適切なデータ ストアを選択することです。
多数のユーザーが必要になるため、適切なデータベースを選択することが重要です。 MongoDB、Apache HBase、および Cassandra は、標準データベースよりも迅速にデプロイできる NoSQL データベースです。 これは、ACID モデルに準拠していないため、パフォーマンスが低下する可能性があるためです。 一方、NoSQL データベースは、必要に応じて高レベルで実行できます。 データベースを選択するときは、それがニーズに適していることを確認してください。
リレーショナル データベースを使用する理由
データベースは十分に保護されており、待ち時間が短いため、データベースを垂直方向にスケーリングすることは完全に理にかなっています。 非リレーショナル データベースは、ACID 準拠のリレーショナル データベースとは対照的に、パフォーマンスとスケーラビリティの一貫性とセキュリティに欠けています。 NoSQL データベースは、サーバー数に制限がなく、処理速度が遅いため迅速にスケーリングできるため、水平スケーリングに最適です。
SQL が水平方向にスケーラブルでないのはなぜですか?
SQL はリレーショナル データベース管理システム(RDBMS) であるため、水平方向にスケーラブルではありません。 RDBMS は、水平方向にスケーリングするようには設計されていません。 これらは垂直方向にスケーリングするように設計されています。つまり、単一のサーバーにリソース (CPU、メモリなど) を追加することでスケールアップするように設計されています。
Nosql が水平スケーリングに適しているのはなぜですか?
NoSQL データベースは水平方向にスケーリングできます。 より高いトラフィックを処理することに加えて、シャーディングを使用すると、NoSQL データベースにより多くのサーバーを追加できます。 NoSQL データベースは、水平方向のスケーリング機能が垂直方向のスケーリング機能を上回っているため、大規模で頻繁に変更されるデータ セットに適した選択肢であることは周知の事実です。
Nosql データベースをスケーリングする方法
nosql データベースのスケーリングは、リソースを追加することで、増加したワークロードを処理するシステムの容量を増やすプロセスです。 nosql データベースをスケーリングするプロセスは、垂直スケーリングと水平スケーリングの 2 つの主なアプローチに分けることができます。
垂直スケーリングは、CPU コア、メモリ、またはストレージを追加するなど、システム内の 1 つのノードにリソースを追加するプロセスです。 このアプローチを使用して、nosql データベースの容量を増やして、より多くのデータまたはより多くのユーザーを処理できます。
水平スケーリングは、システムにノードを追加するプロセスです。 このアプローチを使用して、システムにノードを追加し、ノード間でワークロードを分散することにより、nosql データベースの容量を増やして、より多くのデータまたはより多くのユーザーを処理できます。
Node.js 環境が動作している場合は、このチュートリアルを完了することができます。 インポートした DynamoDB ファイルを含む nodejs-dynamodb-sample というフォルダーを作成しました。 サンプルへのリンクについては、私の GitHub ページを参照してください。 サンプル アプリを使用して、DynamoDB から映画データを検索および取得できます。 この記事では、Amazon の Identity and Access Management (IAM) サービスを使用して S3 にデータを保存し、Amazon Web Services (AWS) 上の DynamoDB にアクセスします。 Amazon の IAM サービスを使用するには、まずユーザーを登録して作成する必要があります。 映画のタイトルと年を入力して、新しい POST /movies アカウントを作成できます。
特定の年の映画を追跡したい場合は、キー付きフィールドに入力します。 次に、これに基づいて独自のアプリケーションの作成に進むことができます。 使用後にテーブルを削除しないと、AWS のホスティングとサービスのコストが発生するリスクがあります。 アマゾン ウェブ サービスの DynamoDB コンソールにアクセスすると、AWS にあるストレージの量を確認できます。 [アイテム] テーブルのテーブルでアイテムを表示したり、アプリケーションからメトリックにアクセスしたり、[映画] をクリックして推定月額費用を確認したりできます。 この演習のコードは、私の GitHub ページ (https://github.com/adamfowleruk/nodejs-dynamodb-sample) にあります。
Nosql および Sql データベースの長所と短所
さまざまな理由から、従来の SQL データベースに代わるものとして NoSQL データベースが登場しました。 スケーリング プロセスはスケーリングを考慮して設計されているため、エンド ユーザーにはほとんど見えません。 その結果、高スループットまたは低遅延を必要とするアプリケーションに最適です。 NoSQL データベースはドキュメントなどの非構造化データに適していますが、SQL データベースは複数行のトランザクションに適しています。 一般に、データベースの種類ごとにトランザクションの処理方法に違いがあります。 SQL データベースはトランザクションのテーブル行で区別されますが、NoSQL データベースはトランザクションのドキュメントで区別されます。 この違いは必ずしも明らかではありませんが、場合によっては重要になる場合があります。
Nosqlはどのように水平方向にスケーリングしますか
Nosql データベースはスケーラブルになるように設計されています。つまり、速度を落とすことなく、増加する量のデータとトラフィックを処理できます。 これを達成する方法の 1 つは、水平方向にスケーリングすることです。これは、必要に応じてシステムにサーバーを追加することを意味します。 これは、より強力なサーバーを追加することを意味する垂直方向のスケーリングとは対照的です。
Nosql データベースは水平方向の拡張が容易
NoSQL データベースはスキーマフリーであるため、行を結合することなくオブジェクトを異なるサーバーに格納できるため、水平方向のスケーリングが容易になります。 水平スケーリングの一環として、複数のサーバーからシステムのデータベースをロードします。
SQLとNosqlの違い
SQL データベースは、データの格納と取得に構造化クエリ言語を使用するリレーショナル データベースです。 NoSQL データベースは、構造化されたクエリ言語を使用しない非リレーショナル データベースであり、多くの場合、SQL データベースよりもスケーラブルでパフォーマンスが優れています。
構造化クエリ言語 (SQL) は、リレーショナル データベース管理システムで最も一般的に使用されているプログラミング言語の 1 つです。 表形式以外の NoSQL モデルで保存および取得されるデータは、より簡単にアクセスできます。 両方の製品は、長所と短所を明確に把握できるように、長所と短所を完全に理解してリストされています。 SQL は RDBMS で最も一般的なプログラミング言語であり、非構造化データ、半構造化データ、および構造化データの格納に使用されます。一方、NoSQL は、構造化データ、非構造化データ、および半構造化データの格納に最もよく使用されるプログラミング言語です。 要件と取り組んでいるプロジェクトによっては、どちらが優れているかが適切なオプションです。 2 つのタイプには違いがあります。前者は、データの一貫性と ACID プロパティを備えた複雑なクエリに焦点を当てていますが、後者はオブジェクト ベースであり、幅広いデータ タイプを処理できます。