
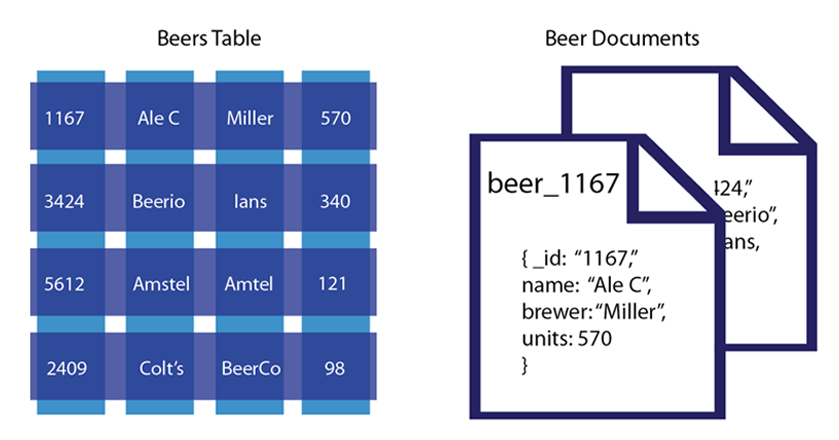
NoSQL データベース内のデータ間の関係を維持する方法
公開: 2022-11-23生成されるデータの量が指数関数的に増加し続けているため、 NoSQL データベースの人気が高まっています。 ただし、これらのデータベースがどのように機能するか、および NoSQL 環境でデータ間の関係を維持する方法については、まだ多くの混乱があります。 従来の SQL データベースでは、データはテーブルに格納され、関係は外部キーによって維持されます。 NoSQL データベースでは、データは多くの場合、オブジェクト指向プログラミング言語のオブジェクトに似たドキュメントに格納されます。 ドキュメントはネストできます。つまり、外部キーを必要とせずに関係を維持できます。 NoSQL データベース内のデータ間の関係を維持するには、いくつかの方法があります。 最も一般的な方法は、参照ドキュメントを使用することです。 参照ドキュメントは、別のドキュメントへの参照を含むドキュメントです。 たとえば、ブログ投稿のコレクションがある場合、各投稿は作成者ドキュメントへの参照を持つことができます。 NoSQL データベース内のデータ間の関係を維持するもう 1 つの方法は、埋め込みドキュメントを使用することです。 埋め込みドキュメントは、別のドキュメント内に保存されているドキュメントです。 たとえば、ブログ投稿のコレクションがある場合、各投稿には、作成者情報を含む埋め込みドキュメントを含めることができます。 参照ドキュメントまたは埋め込みドキュメントを使用する利点は、将来のデータの更新が容易になることです。 たとえば、ブログ投稿の作成者を変更したい場合は、作成者ドキュメントを更新するだけで済みます。 個々のブログ投稿を更新する必要はありません。 参照ドキュメントまたは埋め込みドキュメントを使用することの欠点は、データのクエリがより困難になる可能性があることです。 たとえば、特定の作成者が書いたすべてのブログ投稿を検索する場合は、投稿ごとに作成者ドキュメントをクエリする必要があります。 多数のドキュメントがある場合、これは非効率的です。 NoSQL データベースを使用している場合は、データ間の関係を維持する方法を理解することが重要です。 参照ドキュメントと埋め込みドキュメントは、これを行う最も一般的な 2 つの方法です。
ドキュメント指向データベースでの NoSQL の実装は、オブジェクト間の関係の開発には不十分であるか、存在しません。 このブログ投稿では、オブジェクト/関係管理をデータベースに委任する方法を紹介します。 オブジェクトの関係は、REST API 呼び出しを使用して作成されます。 この例では、PUT 動詞を使用して顧客を問題に結び付けます。 関係がこのように表現される場合、オブジェクトの配列が常に存在します。 オブジェクト (つまり関係) を参照するたびに、元のドキュメントへの変更を確認できます。 データベースは各関係の使用を記録するため、特定のドキュメントが関係のどこで使用されているかを確認することもできます。 以下に示すクエリの例を使用すると、特別なクエリ referencedby=true を使用して、ドキュメントへの暗黙的な参照の存在を見つけることができます。
MongoDB のさまざまなドキュメント間には関係があり、これはそれらの論理関係を示しています。 参照アプローチと組み込みアプローチを使用して、関係をモデル化できます。 次の例で、N:N の関係を持つユーザーのアドレスを格納する場合を見てみましょう。
多対多 (N:M) の関係は、1 対多の関係よりも実装が難しくなります。これは、リレーショナル データベースに実装するコマンドが 1 つもないためです。 それらがMongoDBに実装されている場合、それらは同じ方法です。 MongoDB では、デフォルトでは、いかなる種類の関係も作成できません。
「NoSQL」とも呼ばれる非リレーショナル データベースは、通常、SQL のみのデータベースです。 情報を保持する能力は大きく異なります。 非リレーショナル データベースは通常、データを非表形式で格納するため、SQL や NoSQL データベースなどの最新のデータ構造のニーズにより適合します。
Nosql データベースはリレーショナルにできますか?
NoSQL データベースはリレーショナル データベースではありません。つまり、SQL データベースとは異なる構造 (行や列など) を持つことができ、ユーザーのニーズにより簡単に適合させることができます。
リレーショナルや NoSQL などのデータベース システムは、一般的にクラウド ネイティブ アプリに実装されます。 アーキテクチャとデータ ストレージの手法が異なり、情報とデータへのアクセスも異なります。 SQL を使用しないデータベースは、非構造化データまたは半構造化データを、書式設定のないペアまたはドキュメントで格納します。 NoSQL データストアは、大量のサービスで 1 秒未満の応答時間が必要な場合に適しています。 現在更新中のアイテムの一貫したシステムを探している場合は、すべてのレプリカが正常に更新されるまでその応答を待ちます。 応答が最新でなくても、すべてのノードが即座に応答を返します。 レプリケートされたデータ ノードに障害が発生した場合でも、パーティション トレランスにより、システムが稼働し続けることが保証されます。
サービスとしてのデータベース (DBaaS) は、クラウドネイティブ アプリケーションの他のタイプのデータ サービスよりも優先されます。 これらのサービスを使用して、セキュリティ、スケーラビリティ、および監視を提供できます。 Azure 仮想マシンを構成し、サービスごとに選択したデータベースをその上にインストールできます。 クラウドネイティブのマイクロサービスは、ユーザーの要件に基づいて、リレーショナル データベースまたは NoSQL データベースのいずれかを利用できます。 サービスとしての Azure データベース (DBaaS) プラットフォームには、4 つのマネージド リレーショナル データベースが含まれています。 ジャストインタイムモデルや従量課金制モデルに関しては、躊躇する必要はありません。 Microsoft の主力データベースである SQL Server は、多くのオープン ソースの代替データベースと同様に利用できます。
必要な処理コア、メモリ、およびストレージの量を選択することで、Azure データベースを 1 分未満でプロビジョニングできます。 Microsoft は、Azure をオープン プラットフォームに保つことを約束しているため、人気のあるオープン ソース データベースのマネージド バージョンを提供しています。 サーバーレス コンピューティング レベルでは、非アクティブ期間中にデータベースが自動的に中断され、ストレージ料金のみが差し引かれます。 Oracle は Sun Microsystems を買収し、管理されたバージョンの MariaDB が MySQL のフォークとして作成されました。 Azure Database for MariaDB は、Azure クラウドの一部として提供されるフル マネージド データベース サービスです。 このサービスは、MariaDB コミュニティ エディション サーバー エンジン上に構築されています。 予測可能なパフォーマンスと動的スケーリングを提供することで、ミッション クリティカルなワークロードを処理できます。
コマンド ライン インターフェイス ツールまたは Azure Data Migration Service は、どちらも Postgre データベースを移行するための優れた方法です。 グローバル レベルでのアクティブ/アクティブ クラスタリングのサポートに加えて、CosmosDB は書き込みと読み取りの両方をサポートしているため、任意のデータベース リージョンをそのように構成できます。 CosmosDB データベース システムを使用すると、既存の Mongo、Gremlin、または Cassandra データベースを最小限のコードまたはデータ変更で移行できます。 Azure テーブル ストレージは、それを使用するサービスの CosmosDB テーブル API に簡単に転送できます。 図 5-13 には、Azure Cosmos DB の明確に定義された 5 つの整合性モデルが含まれています。 これらのオプションにより、一貫性、可用性、およびパフォーマンスの間のトレードオフを簡単に管理できます。 次の表は、それぞれの一貫性のレベルを示しています。
Microsoft Program Manager の Jeremy Likness は、5 つのモデルについて優れた説明を提供してくれました。 NewSQL と呼ばれる新しいデータベース テクノロジは、分散スケーラビリティと ACID 保証を組み合わせて、オブジェクト指向データベースを作成します。 クラウド環境が一時的なものである場合、いつでも再起動または再スケジュールできる基盤となる仮想マシンが存在する結果として、新しい SQL データベースが成功することは理にかなっています。 前の図には、Cloud Native Computing Foundation によって作成されたオープンソース プロジェクトが含まれています。 Service コンストラクトを使用する他のワークロードとは対照的に、クライアントは単一の DNS 要求を同一の NewSQL データベース プロセスのグループに送信できます。 データベース インスタンスをそれらに関連付けられたサービスのアドレスから切り離せば、既存のアプリケーション インスタンスの可用性に影響を与えることなくスケーリングできます。 サービスへの特定のリクエストは、同時に送信されるリクエストの数に関係なく、常に同じ結果を生成します。
多くの利点があるため、NoSQL データベースは急速に普及しています。 水平方向にスケーリングし、より多くのデータを処理し、データをより柔軟に保存し、他のシステムと統合する機能はすべて、クラウド コンピューティングの利点です。 NoSQL データベースには、従来のリレーショナル データベースよりも多くの利点があります。
Mongodb はリレーショナルにできますか?
MongoDB は、柔軟性と水平方向のスケーラビリティが向上した定評のある非リレーショナル データベース システムであることに加えて、参照整合性や同時実行性など、リレーショナル データベースよりもいくつかの利点があります。
Snowflake はリレーショナル データベースですか?
Snowflake が強力なリレーショナル データベースであることは驚くことではありません。 標準の 3 つ (テーブル、リレーション、および結合) と、より珍しいスノーフレーク モデルを含む、すべての主要なリレーショナル データ モデルで使用できます。 データベースは、リアルタイム ストリーミング、オブジェクト インデックス作成、クエリ アクセラレーション、および最新のデータベースに見られるすべての最新のリレーショナル データベース機能もサポートしています。 それは関係性ですか? このデータベースはリレーショナル データベースです。
リレーションまたは結合をサポートしていない Nosql データベースはどれですか?

MongoDB、Cassandra、Hbase など、リレーションや結合をサポートしない nosql データベースがいくつかあります。 これらのデータベースは他のデータベースほど普及していませんが、依然として多くの組織で使用されています。
Oracle NoSQL Database は、従来のリレーショナル データベースで使用される一般的な結合演算子をサポートしていません。 ただし、同じ階層を持つテーブルに対して特別なタイプの結合を提供します。 その結果、同じ場所にある行のみが一致するため、結合の実行は非常に簡単です。
Nosqlでのエンティティ関係
nosql のエンティティ関係は、nosql データベース内の 2 つ以上のエンティティ間の関係です。 この関係は、1 対 1、1 対多、または多対多にすることができます。
ドキュメント データベースの Er ダイアグラム
ただし、ER モデリングの原則を使用して、ドキュメント指向データベースの ER ダイアグラムを同様の方法で作成できます。 ドキュメントの保存に使用できるデータ モデルを作成します。 保存するドキュメントのタイプ、各ドキュメントのフィールドとプロパティ、およびモデル全体をすべてこのデータ モデルに含める必要があります。 データ モデルを作成するには、エンティティ ダイアグラムが必要です。 以下の図は、ドキュメント ストア内のデータの構造を示しています。 次に、関係図を使用して、データ モデルを作成します。 以下の図は、データ モデル内のエンティティ間の関係を示しています。
Nosql での多対多の関係
数対多の関係は、同じエンティティの複数のインスタンスによって 2 つのエンティティをリンクできる関係です。 実際の例がいくつかあります。医師は、多くの医師を抱えながら、多くの患者を治療できます。

NoSQL データベースを使用して node.js アプリケーションの分類構造 (地理用語) を実装したいと考えています。 ジオタグの背後にあるアイデアは、特定の都市や町で生まれた人々をそれらの用語で識別し、後でそれらを除外してタグ付けすることでした. John Doe は 1957 年にブラックバーン (ランカシャー) で生まれ、Paul Brown は 1960 年にリバプールで生まれ、Georgia Doe は 1982 年にウィラルで生まれました。できません。 私はNoSQL の世界では初心者です (NoSQL データベースを設計したことがないため、深刻な設計上の課題が待ち受けています)。 それを解決するにはいくつかの選択肢があると思います。
クロウズ フット記法: 多対多の関係
多対多の関係をグラフィカルに表現する場合、通常、データベースにクロウズ フット記法が表示されます。 テーブル間の関係は、この表記に従って一連の線で表されます。 グラフの起点 (左上隅) は、通常、「外部」と呼ばれるテーブルに下る行で始まります (そこが起点であるため)。 それに続いて、行は関連テーブルに移動し、その後に子テーブルが続きます。
Nosql ドキュメント
Nosql ドキュメントは、 nosql コードを記述するために使用されるプロセスまたは一連のルールです。 これは、nosql コードをより読みやすく理解しやすくするために設計されたコーディング スタイルです。
NoSQL データベースは、従来のリレーショナル データベースとは異なり、データを固定形式で保存しません。 最も一般的なタイプは、ドキュメント、キー値、幅の広い列、およびグラフです。 2000 年代後半、ストレージ コストの大幅な削減により、NoSQL データベースが開発されました。 開発者はこれらのツールを使用して大量の非構造化データを保存できるため、幅広いプロジェクトに取り組むことができます。 ドキュメント データベース、キー値データベース、ワイド カラム ストア、およびグラフ データベースは、最も一般的な NoSQL データベースの一部です。 結合が不要なため、クエリが高速になります。 最も一般的なユース ケースには、重要なアプリケーション (例: 財務データ) とより面白いアプリケーション (例: スマートな猫用トイレからの IoT 測定値の保存) が含まれます。
このチュートリアルでは、NoSQL データベースがどのように機能し、さまざまなアプリケーションにとってなぜ有益なのかを見ていきます。 さらに、NoSQL データベースとそのアプリケーションに関する一般的な誤解についても説明します。 DB-Engines によると、MongoDB は世界で最も広く使用されている非リレーショナル データベースです。 このチュートリアルで MongoDB データベースにクエリを実行するために、コンピューターにソフトウェアは必要ありません。 クラスターは、 MongoDB データベースが格納されるデータベースのコレクションです。 クラスタがある場合、Atlas データ ストアにアクセスできます。 作成できるデータベースには、Atlas Data Explorer で手動、MongoDB Shell、MongoDB Compass の 3 種類があり、好みのプログラミング言語に応じて異なります。
この例では、Atlas のサンプル データ セットをインポートする方法を示します。 NoSQL データベースは、柔軟なデータ モデル、水平方向のスケーリング、超高速のクエリ、使いやすさなど、開発者に多くの利点を提供します。 Data Explorer では、新しいドキュメントを挿入したり、既存のドキュメントを編集したり、ドキュメントを削除したりできます。 集計フレームワークを使用すると、非常に強力な方法でデータを分析できます。 Atlas と Atlas Data Lake のデータをグラフで簡単に表示できます。
Nosql クエリ
NoSQL データベースは、データの一貫性よりもスケーラビリティが重要な場合によく使用されます。 NoSQL データベースは、SQL に似たクエリ言語をサポートする可能性があることを強調するために、「SQL だけではない」と呼ばれることもあります。
以前は、データ モデルとクエリ システムは密接に統合されていました。 開発者の生産性を優先するデータベース システムを作成し、開発者の生産性を優先するためにデータ モデルからクエリ メソッドを抽象化することができるようになりました。 世界初の商用データベースである SABRE は、1994 年に IBM とアメリカン航空によって航空券の効率を改善するために設立されました。 NoSQL データベースは、ここ数年で、スケーラビリティ、稼働時間、冗長性、柔軟性、および柔軟性のために最適化されてきました。 Riak と MongoDB のオプションとして map-reduce を追加するだけでなく、CouchDB と Riak にも追加しました。 SQL からの単純なアドホック宣言型クエリを期待していましたが、それはスクリプト トリックであることが判明しました。 簡単にスケーリングできるデータベース システムを構築している場合、クエリは主な目的ではありません。
XQuery と Jsoniq は、ドキュメント データベース内の階層ドキュメントを取得するために使用できる標準クエリ言語を作成する試みです。 XML ドキュメント データベースである MarkLogic は、XQuery に加えて XQuery を採用していますが、ArrangoDB は、データ モデリング用に調整された独自のスーパーセットを採用しています。 両方の言語は、ディスクに保存されているデータの形式と強いつながりがあり、どちらも商業的に使用されています。 ドキュメント データベースで使用されるクエリ言語の 1 つまたは両方は、データベースで使用されるクエリ言語に関連しています。 N1QL (または非第 1 形式クエリ言語) は、SQL とは対照的に、本質的に非常に SQL に似ています。 関係が強制されないという事実にもかかわらず、公式か非公式かに関係なく、私たちはドキュメントで共同作業を行います。 Couchbase と Cassandra はどちらも、インデックスとクエリ解析に多くの時間と労力を費やして、リレーショナル検索を必要とせずにこの方法でデータをクエリできるようにしました。
Nosqlでクエリできますか?
NoSQL という名前は SQL を指していません。 SQL は、No SQL でクエリを記述するための推奨される方法ではありません。 このソフトウェアは、データをリレーショナル形式ではなく、整理された方法で保存します。
Nosqlの例とは?
Cassandra、HBase、Hypertable などの列ベースの NoSQL データベースが一般的です。
Nosql は Sql よりも簡単ですか?
SQL データベースには、クエリを処理し、テーブル間でデータを結合するという利点があり、アドホック リクエストなどの構造化データに対してより複雑なクエリを実行できます。 製品間での NoSQL データベースの一貫性、特に大量のデータを扱う場合の一貫性は、このタイプのデータベースに共通する機能です。
Nosql データ モデル
NoSQL データ モデルとは長所と短所は何ですか? リレーショナル データベース管理システム(RDBMS) などというものは存在せず、これは複製が不可能なモデルです。 その結果、データがどのように関連しているか、つまりデータがどのように組み合わされるかをモデルが理解するための明示的な方法はありません。
8 Data Modeling Patterns in Redis では、NoSQL でのデータ モデリングの基礎と、開始するためのベスト プラクティスについて説明します。 この本は、開発者が従来のデータベースがもたらす困難なしに最新のアプリケーションを作成するために使用できる 8 つのデータ モデルを検証します。 NoSQL を使用すると、2 つの個別のテーブルまたはコレクションを組み合わせて、1 つのテーブルまたはコレクションを作成できます。 その結果、関連するすべてのデータを見つけて、それらの関係を理解することが容易になります。 NoSQL の各テーブルは、個別に表示できます。 1 対多の関係をモデル化する場合は、制限付きリスト (既知のサイズのリストなど) と制限なしリストを別々に埋め込みます。 この場合の製品は 1 つであり、多くのレビュー、著者名、発行日、評価、およびコメントが「多くの」変数です。
最初のパターンは、無制限の側面を持つ多対多の関係です。 リレーショナル データベースの目的は、製品を別々のテーブルに格納することです。 スキーマは非常に柔軟で、コレクションのタイプに基づいてタイプ フィールドを分離できるため、すべての Redis スタック スキーマをこの機能で設定できます。 時系列データを蓄積して集計すると、バケット パターンによってオーバーヘッドが削減されます。 リビジョン パターンは、リアルタイム データが必要なさまざまな状況で使用できます。 これらのパターンを使用して、NoSQL での JOIN 操作に関連する複雑さを解消できます。 ツリーとグラフのパターンは、人事管理、CMS、製品カタログ、ソーシャル ネットワークなど、さまざまな負荷の高い JOIN ベースの操作に特に役立ちます。
このモデルは、リレーショナル データベース管理システム (RDBMS) でサポートされていないモデルに基づいているため、RDBMS ではサポートされていません。 データの保存は、ディスク、メモリ内、またはその両方の使用など、さまざまな方法で行うことができます。 Redis Launchpad には、NoSQL と Redis を使用して作成された多数のアプリケーションがあります。
ドキュメント アプリケーション Nosql データ
ドキュメント アプリケーションを使用してデータを保存する理由は多数あります。 まず、ドキュメント データベースは非常に柔軟で、さまざまな形式のデータを簡単に格納できます。 これは、必要に応じて、JSON、XML、またはバイナリ形式でデータを保存できることを意味します。 次に、ドキュメント データベースは、多くの場合、従来のリレーショナル データベースよりも簡単に拡張できます。 これは、複数のサーバー間で非常に簡単にシャーディングできるためです。 最後に、ドキュメント データベースは、特定の種類のクエリに対してリレーショナル データベースよりも優れたパフォーマンスを提供することがよくあります。
ドキュメント指向データベースのデータは、他の最新のデータベースのように列/行ではなく、JSON 形式で保存されます。 このタイプのデータを使用すると、RDBMS では習得がはるかに困難な課題に対処できます。 ドキュメント ストアを使用すると、開発者はアジャイル ソフトウェアを自然で適応性のあるソリューションにすることで、より迅速にコラボレーションできるようになります。 表現力豊かなクエリ言語と多面的なインデックス機能により、さまざまな方法で簡単にクエリを実行できます。 ACID トランザクションを利用することで、リレーショナル データベースで得られる保証をすべて保持できます。 分散システムの結果として、データは無限にスケーラブルで回復力のあるものになる可能性があります。 各ドキュメントは個別に格納され、サーバー間でより簡単に分散できるため、データの局所性が損なわれることはありません。
ドキュメント データベースは、リレーショナル データベースとは対照的に、より速く読むことができる直感的で実用的なモデリングを使用します。 データの品質が低下するため、テーブルの柔軟性が低下します。 ネイティブ スケーリングがないため、従来のリレーショナル データベースをパーティション分割する場合は、高価なスケールアップ システムを購入する必要があります。 ドキュメント指向データベース内のすべてのドキュメント ストアには、さまざまなタイプのドキュメント用のフィールドが含まれており、これらはオプションです。 各ドキュメントの構造構成は同じですが、各ドキュメントには個別のフィールドがあります。 各ドキュメントには、情報の追加、変更、削除、およびクエリに使用できる独自の一意の ID があります。 ドキュメントのエンコーディングには、一般に、カプセル化されたデータ (または情報) の標準形式または圧縮が含まれると想定されています。
ドキュメント指向データベースは、はるかに柔軟で一貫性を必要としないという点で、従来のデータベースとは異なります。 データベース内の列にデータを送信する代わりに、データはドキュメントから直接取得されます。 すべてのデータセットに新しい情報フィールドを追加する必要はなく、ドキュメント ストア内の関連するものだけを追加する必要があります。
Mongodb と Sql の違い
ドキュメントが異なることに注意することが重要です。 ドキュメントに含めることができるフィールドの数に制限はありません。 ドキュメント タイプには、それらに関連するフィールドを含めることもできます。 たとえば、ドキュメントはデータベース内の顧客を表すことができます。 ドキュメントには、顧客の氏名、住所、電話番号が含まれます。 顧客の注文履歴と口座残高もフィールドに含まれる場合があります。
MongoDB と SQL の違いは、データベースはテーブルではなく、ドキュメントもテーブルではないということです。 MongoDB には、SQL のようなフィールドのコレクションはありません。 一方、ドキュメント コレクションは、関連するフィールドで構成されています。