
Nosql に階層データを格納する方法
公開: 2023-01-15最近、nosql データベースに階層データを格納する方法について多くの議論がありました。 最も一般的なアプローチは、ルート ノードから現在のノードまでのパスを文字列として格納するマテリアライズド パスを使用することです。 ただし、このアプローチにはいくつかの欠点があります。 たとえば、データのクエリが困難な場合や、データが変更された場合にパス文字列を最新の状態に保つのが困難な場合があります。 もう 1 つの方法は、ネストされたセットを使用することです。 このアプローチでは、ツリー内の各ノードの左右の境界が格納されます。 これにより、データのクエリが容易になりますが、ツリー構造が変更された場合、データの更新が難しくなる可能性があります。 どのアプローチが最適かは、特定のアプリケーションによって異なります。 一般に、具体化されたパスは、大量のデータを保存する必要があり、データを頻繁に更新する必要がないアプリケーションに適しています。 ネストされたセットは、データをより頻繁に更新する必要があるが、それほど多くのデータを保存する必要がないアプリケーションに適しています。
一方、NoSQL データベースは、より効果的な方法で階層型データベース モデルにデータを格納できます。
Nosql は階層データ ストレージを許可しますか?
Nosql データベースでは、階層的なデータ ストレージを使用できません。 これは、それらがスケーラブルで効率的になるように設計されており、階層データ構造は簡単にスケーラブルでないためです。
大量のデータを処理する必要がある企業は、NoSQL データベースを検討する必要があります。 固定スキーマがないため、これらのデータベースは膨大な量のさまざまな非構造化データを処理できると同時に、処理が高速で簡単になります。 特に、MongoDB を使用して、大規模な階層構造およびネストされたデータ関係をツリーのような構造でモデル化できます。 このデータ モデルは、親ノードを参照して子ノードにドキュメントを格納することで、ドキュメントを整理します。 ドキュメントは、データベース内のどこにあるかに関係なく、どこからでも検索およびアクセスできます。
Nosql データベース: パフォーマンスとスケーラビリティの優れた選択肢
大規模なデータ セットを処理する場合、NoSQL データベースは SQL データベースよりも優れたパフォーマンスを発揮する傾向があります。 データの編成方法によって、パフォーマンスの良し悪しが決まります。これは通常、キー値またはグラフです。
通常、NoSQL データベースはメモリの消費量が少なくなりますが、SQL データベースよりもスケーラブルです。 この場合、NoSQL データベースは標準データベースとは異なるデータ モデルを使用します。これは、大規模なデータ セットを処理する場合により効率的です。
階層データを保存する最良の方法は何ですか?
階層データを格納する方法はいくつかありますが、最適な方法はプロジェクトの特定のニーズによって異なります。 一般的なアプローチの 1 つは、各レコードがその親レコードへのポインターを持つ自己参照テーブルを使用することです。 もう 1 つのオプションは、隣接リストを使用することです。これは、データをより線形に格納しますが、クエリが難しい場合があります。 最終的に、階層データを格納する最善の方法は、プロジェクトの特定の要件によって異なります。
Sql は階層型データベースで使用できますか?
これは、階層データから意味のある結果を生成する SQL クエリ タイプの 1 つです。 相互に関連する一連のデータ項目を含む階層データは、階層データとして分類されます。
階層データをどのように表現しますか?
階層データは、ツリー構造に似たグラフで表されます (ただし、上下が逆になり、ルートがまだ一番上にあるツリーが表されます)。
SQL で階層データをどのように表現しますか?
階層構造を持つテーブルを作成したり、階層構造を持つ別の場所に格納されたデータを記述したりするには、hierarchyid をデータ型として使用します。 Transact-SQL hierarchyid 関数を使用すると、階層データのクエリと管理を行うことができます。
Nosqlにデータを保存するさまざまな方法は何ですか?
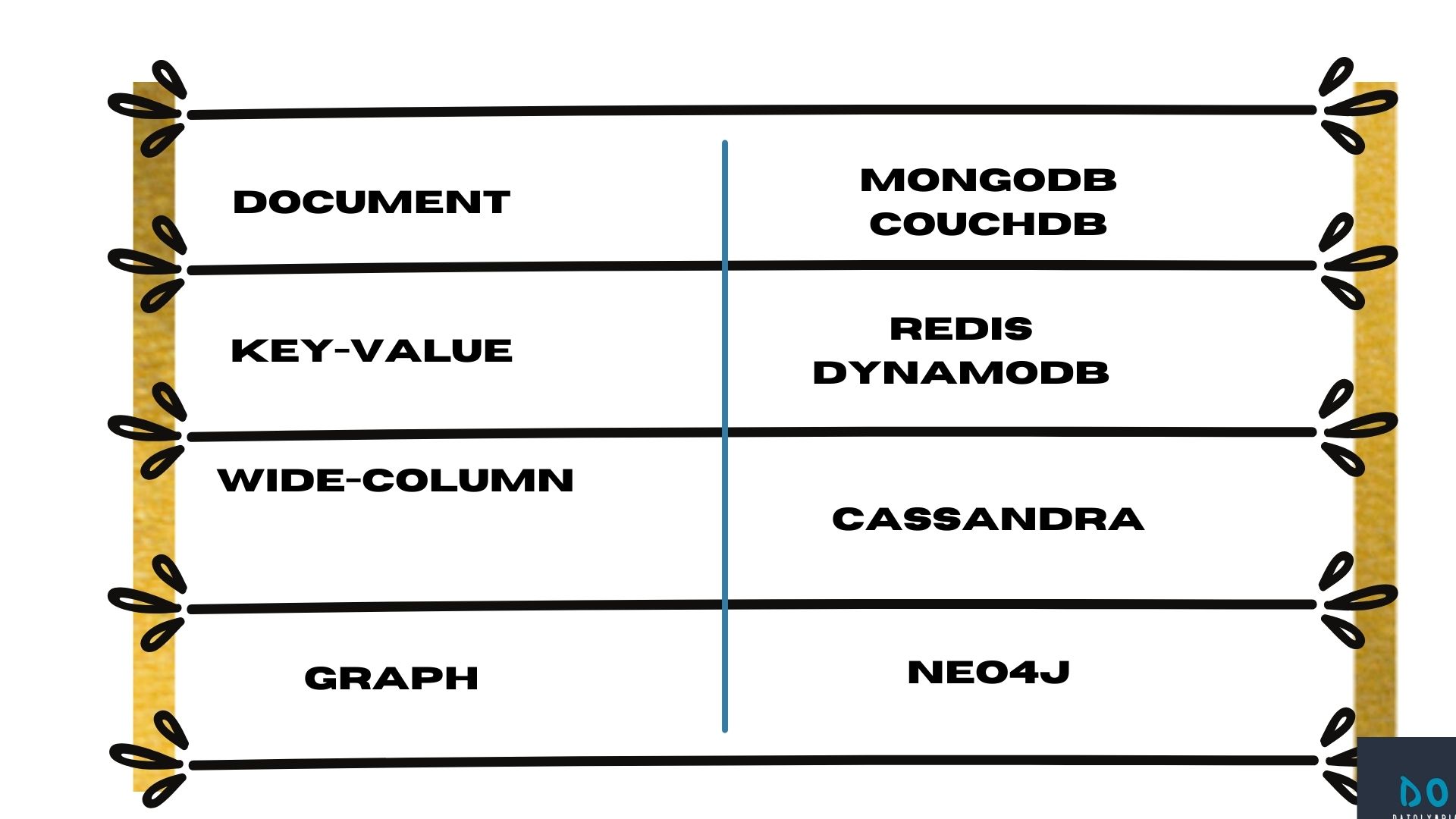
NoSQL データベースは、リレーショナル データベースではなくドキュメントにデータを格納します。 したがって、それらを柔軟なデータ モデルによってさまざまなデータ モデルに分割し、それらを SQL のみとして分類します。 ドキュメント データベース、キー値ストア、幅の広い列のデータベース、およびグラフ データベースは、NoSQL データベースの例です。
Nosql ドキュメント ストアの利点
行と列ではなく JSON データ形式を使用する NoSQL ドキュメント ストアは、最新のデータ格納方法です。 それを通してデータが表現される方法は、あるべき方法です。 これらのストアは、非構造化データ ストレージや、ソーシャル ネットワーク、検索エンジン、e コマース サイトなどのアプリケーションに最適です。
階層データベースに SQL を使用できますか?
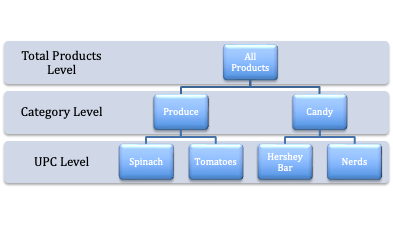
SQL は、階層データベース内のデータを管理するための強力なツールです。 SQL を使用すると、階層型データベース内のデータを簡単にクエリおよび更新できます。
階層クエリは、階層構造を使用してデータを編成するクエリです。 再帰的な共通テーブル式 (CTE) は、この方法で SQL に実装されます。これは、単一のテーブルに含まれる階層データに最適です。 一方、階層クエリは、複数のテーブルにわたって階層的に格納されたデータを取得するために使用できます。 今日の世界では、地理データとファイル システムを格納するために、階層クエリが最も一般的に使用されています。 多くの場合、地理情報は階層化されており、複数の国や複数の大陸で共有されている場所などがあります。 ファイルの内部ディレクトリは通常、ファイル システム内にもあります。

ツリー構造を Nosql に格納する
ツリー構造を NoSQL データベースに格納するには、いくつかの方法があります。 1 つの方法は、子ノード ID の配列を含むフィールドを使用して、各ノードをドキュメントとして格納することです。 もう 1 つの方法は、ノード間の関係をより柔軟に表現できるグラフ データベースを使用することです。
構造化データを Nosql に保存できますか?
データは、さまざまな形式で NoSQL データベースに格納できます。 これらは、半構造化 (JSON、XML) 形式を使用するため、非構造化 (すべてのフィールドが既知ではない) データに最も役立ちます。
Tree Store は Nosql データベースの一種ですか?
近年、大量のデータの保存と取得がより困難になっているため、大量の情報を保存および取得するための最も一般的な選択肢は NoSQL データベースになっています。
Dbストアツリー構造はどのようになっていますか?
階層データを格納する最も一般的な方法は、単純な親子関係を使用することです。 データベース内の各レコードには -parent ID があり、それを介した各再帰クエリにより、子、兄弟、およびツリー レベルのリストが生成されます。
Nosqlはスキーマを持つことができますか?
NoSQL にはスキーマがありますか? NoSQL データベースは、リレーショナル データベースと同じ構造ではありません。リレーショナル データベースは通常、リレーショナル データベースと同様に構造化されています。 NoSQL データベースには 4 つの種類があります。それらはすべて、基礎となる構造を使用してデータを格納します。
Postgresql が階層データを格納するために使用する Nosql 機能はどれですか?
Postgresql は、さまざまな nosql 機能を使用して階層データを格納します。 これには、さまざまなデータ型を使用してデータを格納することや、さまざまなインデックス方法を使用してデータを格納することが含まれます。
Postgresql: 非構造化データの保存に最適なオプション
PostgreSQL は、非構造化データを格納するための優れた選択肢です。 NoSQL ツールは時間の経過とともに進化し、現在ではNoSQL システムで半構造化データを保存するために最も一般的に使用される形式である JSON データをサポートしています。
データベースへの階層データの格納
階層データの格納に使用されるデータベースを作成する場合、データの編成方法を考慮することが重要です。 階層データを格納する一般的な方法の 1 つは、ツリー構造を使用することです。 ツリー構造では、各データはノードに格納され、各ノードには親ノードと 0 個以上の子ノードがあります。 このタイプの構造は視覚化が容易で、探しているデータを見つけるために簡単にトラバースできます。 階層データを格納するもう 1 つの方法は、グラフ構造を使用することです。 グラフ構造では、各データはノードに格納され、各ノードには他のノードに接続する 0 個以上のエッジがあります。 このタイプの構造は、ツリー構造よりも柔軟ですが、クエリが難しくなる可能性があります。
Trie を Nosql データベースに格納する方法
トライを nosql データベースに保存する方法はたくさんあります。 1 つの方法は、ノード間のエッジをリンクとして表して、各ノードをドキュメントとして保存することです。 もう 1 つの方法は、トライをグラフとして格納し、ノードとエッジをグラフのノードとエッジとして表すことです。
Trie: ソートされたキーのシーケンスを格納するための優れたデータ構造
トライは、ソートされた一連のキーを格納するために使用できるデータ構造です。 各ノードは1 つのキーをトライとして格納し、キーはトライ内にツリーとして格納されます。 他のすべてのノードには、その前のノードに格納されていたキーのプレフィックスが格納され、ルート ノードにはシーケンス全体が格納されます。 トライを作成するには、データ構造によって制約が課されることに注意してください。 別の言い方をすれば、トライはツリーを垂直方向および水平方向にトラバースし、ソートされたキーのシーケンスを格納できなければなりません。 トライは、ソートされた一連のキーを格納するのに適したデータ構造です。
階層データのグラフ データベース
グラフ データベースは、階層データの処理に最適です。 グラフの柔軟な性質は、あらゆる種類の関係を簡単に表すことができることを意味し、複雑な構造を持つデータを格納するのに理想的です。 たとえば、グラフ データベースを使用して、家系図に関するデータを格納できます。各ノードは人物を表し、エッジは人物間の関係を表します。
階層データをどのように表示しますか?
階層情報は簡単な方法で表すことができます。 ほとんどの場合、情報設計者はツリー ダイアグラム (またはツリー ダイアグラムの変形) またはツリー マップを使用して、ユーザーに効率的な方法でデータを表示します。
Nosql ドキュメント データベース
NoSQL (元は「非 SQL」または「非リレーショナル」を指す) データベースは、リレーショナル データベースで使用される表形式の関係以外の方法でモデル化されたデータの格納と取得のメカニズムを提供します。 このようなデータベースは 1960 年代から存在していましたが、「NoSQL」という名前が造られたのは 21 世紀初頭のことでした。これは、Web 2.0 企業が大量のデータを処理し、アーキテクチャを拡張する新しい方法を見つけるというニーズに端を発したものです。 NoSQL データベースは、ビッグ データ アプリケーションや、データの規模やアプリケーションのパフォーマンス要件がリレーショナル データベースの能力を超える状況でますます使用されています。
Nosql データベースの 3 つの異なるタイプ
ドキュメント データベースは、最も一般的なタイプの NoSQL データベースです。 ドキュメントはさまざまな形式で保存でき、移動できます。 その結果、特定のドキュメントを見つけやすくなります。 さらに、ドキュメントには、管理と保存を容易にする限られた数のフィールドがあります。
キー値データベースは、それに加えて NoSQL データベースです。 これらは、キーと値のペアを組み合わせて配置できるという概念に基づいています。 各キーには一意の識別子が含まれており、その値はそこに格納されている情報です。 その結果、データをすばやく保存して見つけることができます。
多くの列を持つデータベースの種類には、幅の広い列のデータベースが含まれます。 ワイドテーブルをイメージしたデザインです。 複数の列のデータを 1 つのテーブルに格納できます。
グラフ データベースは、NoSQL データベースの一種であるだけでなく、まだ初期段階にあります。 それらは一般的にグラフに触発されています。 つまり、グラフはデータが格納される形式です。 これにより、より簡単に検索できる方法でデータを他のデータ ソースにリンクできます。