
PostgreSQL を使用した動的 API のための Hasura GraphQL エンジンの紹介
公開: 2019-11-07一般に、過去数年間、REST API は急速に変化する技術要件に対処する際に柔軟性に欠けるとの批判を受けてきました。 振り返ってみると、GraphQL は、API 開発におけるさらなる柔軟性と効率の必要性に対処するために作成されたと多くの人が信じています。 したがって、REST API の欠陥を軽減します。 Facebook が HTML5 アプリケーションからより堅牢でネイティブなセットアップに移行した結果、過去 5 年間で GraphQL の人気と採用が高まったのには十分な理由があります。 このブログでは、GraphQL の現象である PostgreSQL について詳しく説明し、後で Hasura GraphQL エンジンを徹底的に紹介します。 スニペットでは、Hasura GraphQL エンジンと PostgreSQL の関係とエコシステムを示しています。
GraphQL: Facebook の反乱
GraphQL は REST API への反逆として作成されたと多くの人が信じていますが、これは真実とはかけ離れている可能性があります。 皮肉なことに、これは単に Facebook の社内ニーズを満たすために作成されたものです。 GraphQL は、もともと Facebook チームによって設計およびオープンソース化されたものですが、データベース テクノロジと混同されることがよくあります。 基本的に、誤解にもかかわらず、GraphQL は技術的には API のクエリ言語であり、データベースではありません。 その結果、API の構築の複雑さが軽減され、すべてのリクエストが単一のエンドポイントに抽象化されます。 従来の REST API とは異なり、GraphQL は宣言型です。つまり、要求されたものは何でも返されます。 もう少しコンテキストを理解するために、一歩下がって REST API を再検討する必要があります。
REST アーキテクチャ
通常、API は、ソフトウェア コンポーネントがどのように対話するかを指定するルール、ルーチン、またはプロトコルです。 Representational State Transfer (REST) は基本的に、すべてが「リソース」と見なされる Web サービスの実装で通常利用される API 設計アーキテクチャです。 残念ながら、RESTful な方法論は一貫して単一のリソースの処理に限定されていました。 したがって、データが必要であり、投稿やユーザーなどの 2 つ以上のリソースから取得された場合、必要なすべてを収集するには、サーバーへの複数回の往復が必要になります。 さらに、REST は「オーバー」および「アンダー」フェッチの問題に直面していました。 特に、関連するリソースを組み合わせた大規模なデータセットを処理するデータ駆動型アプリの出現により、これらすべてが理想的ではありませんでした。 これは、Facebook が直面した苦境を説明できます。
したがって、より柔軟で進歩的なアプローチを取る API アーキテクチャが必要です。
代替案の作成
あるいは、 GraphQL はリソース URL、セカンダリ キー、またはテーブルの観点からデータを考えるのではなく、 NSObjectsまたはJSON を利用するオブジェクトとモデルのグラフの観点からデータを考えます。 具体的には、GraphQL は、さまざまな機能とユース ケースを 1 つの「グラフ」で表すことができるため、ユース ケースごとに専用のエンドポイントを必要としません。 GraphQL クエリ言語を使用すると、応答がどのように見えるかを正確に記述できるため、追加のサーバー ラウンド トリップは必要ありません。 アプリケーション層のクエリ言語として、サーバー/クライアントからの文字列を解釈し、そのデータを安定した、理解可能で予測可能な形式で返すように設計されています。 これは、データをより適切に統合するための単なるツールです。
シンプルさ、安定性、効率性。
真実は、明確に定義されたスキーマにもかかわらず、すべてのプロジェクトが GraphQL を必要とするわけではないということです。 ただし、MySQL、Postgres、その他の API など、複数のソースからのデータに依存するエンタープライズ製品がある場合は、GraphQL の方が適しています。 GraphQL は、データが共通のエンドポイントまたは呼び出しの下で収集されるため、特にデータ取得に関してシンプルであることを誇りにしています。 基本的に、クライアントは正確に必要なものを取得するため、クライアントが行う各リクエストのサイズが効果的に削減され、高性能アプリケーションが実現します。 GraphQL は複数のエンドポイントを必要とするデータを統合するため、複雑な繰り返しの取得が容易になり、クエリの効率が向上します。 その結果、そのシンプルさにより、バックエンドの安定性、計画、構築、実行、および長期にわたる継続的な運用が実現します。
GraphQL の利点
簡単に言えば、GraphQL を使用すると、わかりやすいクエリでデータを抽出でき、データがサーバー経由ではなく直接アクセスされるため、軽量で高速なアプリケーションを迅速に開発できます。 さらに、すべてのデータに対して 1 つのエンドポイントを使用しながら、複数の URL やリソースの連鎖を使用せずに、1 つのクエリで複数のリソースを取得できます。 データはグラフベースのスキームを使用してサーバー上で定義されるため、複数の呼び出しではなくパッケージとして配信されることに注意してください。 これにより、API 開発中に API 応答を集約する際の運用上のブーストが可能になります。
これにより、フロントエンド開発チームの負荷が軽減され、API のバージョン管理が容易になり、メンテナンスが簡素化され、データ転送の需要が節約されます。 さらに、データ受信時の予測可能性を高め、宣言型データ フェッチをサポートし、オーバーフェッチとアンダーフェッチを軽減します。 基本的に、オーバーフェッチは、クライアントがアプリで実際に必要な情報よりも多くの情報をダウンロードした場合に発生しますが、アンダーフェッチは、特定のエンドポイントが十分な情報を提供していないため、クライアントが必要なものをフェッチするために追加のリクエストを行う必要があることを意味します。
技術的には、GraphQL は定義可能なラッパーであるため、REST システムを完全に置き換える必要はありません。 基本的に、これは GraphQL が、REST 中心の API と互換性のあるシステムと互換性があることを意味します。 さらに、GraphQL により、フロントエンドとバックエンドのシームレスで独立した開発が可能になります。 これは、スキーマが適切に定義されると、フロントエンドとバックエンドで作業するチームの両方がデータの明確な構造を認識するためです。 これらの利点はすべて、多くのフルスタック エンジニアに有利であると見なされています。 最後に、GraphQL には、徹底的なイントロスペクションと自己文書化のための驚くべき能力があります。

API開発におけるGraphQLユースケース
GraphQL は非常に強力であると考えられており、迅速な速度とインデックス作成で安定した可読性を求めるフルスタック開発者によって使用されています。 具体的には、GraphQL は、高いデータ スループットを必要とする API 開発に役立ちます。 実際のところ、ネットワーク経由での転送に必要なデータ量を最小限に抑えます。 これは、モバイル ユーザー、低電力デバイス、ずさんなネットワークにとって非常に有益です。 これが、Facebook が GraphQL を設計した最初の理由の 1 つです。 信じられていることとは反対に、GraphQL は巨大で複雑なデータベースに適用できるだけでなく、比較的単純なデータベースをより効率的に作成できます。
さらに、さまざまな独自のフロントエンド フレームワークやプラットフォームに適用でき、すべてのユーザー要件に適合する 1 つの API で維持される異種環境を提供します。 さらに、フルスタックの開発者チームの機能速度が劇的に向上するため、迅速な機能開発が容易になります。 フロントエンド開発者は、バックエンド開発者が提供するのを待たずに、新しい機能を導入したり、既存の機能を変更したりするなどの API 要求を行うことができるため、新しい機能を開発する際に必要なチーム間でのコミュニケーションを減らすことで、これを実現します。 Hasura GraphQLエンジンの紹介に入る今のところ、このGraphQLの簡単な要約で十分です。 ただし、もう少しコンテキストについて PostgreSQL に触れてみましょう。
PostgreSQL とは何ですか?
無料のコミュニティ主導のリレーショナル データベース管理システムである PostgreSQL は、特定の企業によって所有されているわけではありません。 最も強力で内部的に一貫性のある RDBMS であると考えられている Postgres は C で記述されており、C/C++、JavaScript、Java、Python、R、Go、Lisp、.Net などの多くのプログラミング言語をサポートしています。フルスタックの開発者にとって、PostgreSQL は姉妹の MySQL よりも機能が豊富で、その機能、スケーラビリティ、およびパフォーマンスにより人気を集めています。 PostgreSQL は、要件が複雑な手順、複雑な設計、オーダーメイドの統合、およびデータの整合性を中心に展開するプロジェクトで人気があります。
フルスタック開発者にとっての Postgres の利点
一般に、全文検索、JSON 列、論理レプリケーションなどの機能により、Postgres は MySQL よりも優位に立つことができます。 これは、一般的な商用データベースのパフォーマンス要求に最適であり、オーバーヘッドとコストを削減するために複数のデータベース システムを 1 つに統合できます。 さらに、Key-Value-Storage (JSON / JSONB 列タイプ) の最新の機能により、NoSQL データベースの適切な代替手段になります。 さらに、クラスタリングまたはマスター スレーブ アーキテクチャをサポートしているため、クラウドのような環境に適しています。 さらに、その一般的な外部データ ラッパー拡張機能により、必要に応じて PostgreSQL 内から直接外部ソースにクエリを実行できます。 具体的には、複雑なクエリの実行、データ ウェアハウス、および動的データ分析を必要とするシステムに最適です。
実際のところ、PostgreSQL は、MySQL がサポートしていない特定の機能をより適切にサポートしています。 たとえば、チェック制約、豊富なデータ タイプ (配列、マップ、JSON など)、豊富な地理空間サポート (PostGIS)、豊富な全文サポートなどがあります。 さらに、ノンブロッキング インデックスの作成、部分インデックス、共通テーブル式、およびより動的な分析機能をサポートします。 それにもかかわらず、PostgreSQL は、クライアント/サーバー通信の暗号化のための接続のネイティブ SLL サポートと、SELinux ポリシーに基づく追加のアクセス制御を提供する SE-PostgreSQL という組み込みの拡張機能を提供します。
エンタープライズ グレードの製品向けの多くの豊富な機能を備えた PostgreSQL は、データの認証が必要で、読み取り/書き込み速度がプロジェクトの成功に不可欠な大規模システムに適しています。 さらに、独自のソリューションで通常利用できる複数のパフォーマンス エンハンサーもサポートしています。 これには、読み取りロックのない同時実行、SQL サーバー、地理空間データのサポートなどがあります。

Postgres アーキテクチャのもう 1 つの主な利点は、独自の拡張性です。 ユーザーは、コア システム コードを変更することなく、データ型、インデックス アクセス メソッド、サーバー プログラミング言語、外部データ ラッパー (FDW)、ロード可能な拡張機能などの機能を追加できます。 最新のマルチコア プロセッサ アーキテクチャを活用しているため、コア数の増加に伴ってパフォーマンスがほぼ直線的に向上します。 これは重要です。一般に、全文検索、JSON 列、論理レプリケーションなどの機能により、Postgres は MySQL よりも優位に立つことができます。 これは、一般的な商用データベースのパフォーマンス要求に最適であり、オーバーヘッドとコストを削減するために複数のデータベース システムを 1 つに統合できます。 さらに、Key-Value-Storage (JSON / JSONB 列タイプ) の最新の機能により、NoSQL データベースの適切な代替手段になります。 さらに、クラスタリングまたはマスター スレーブ アーキテクチャをサポートしているため、クラウドのような環境に適しています。 さらに、その一般的な外部データ ラッパー拡張機能により、必要に応じて PostgreSQL 内から直接外部ソースにクエリを実行できます。 具体的には、複雑なクエリの実行、データ ウェアハウス、および動的データ分析を必要とするシステムに最適です。

PostgreSQL の短所
一般に、ANSI SQL 標準に興味がある場合は PostgreSQL を検討してください。ただし、ODBC 標準を好む場合は MySQL を選択してください。 残念ながら、Postgres は、ライブの「常時稼働」の本番環境では、パフォーマンスが不足することがあります。 Postgres のもう 1 つの欠点は、レプリケーションがストレージ エンジン レベルで実装されていることです。 これにより、「クエリ エンジン レベル」でより成熟して実装されている MySQL のレプリケーションよりもコストがかかります。
Hasura GraphQLエンジンの紹介
GraphQL API 開発と PostgreSQL について簡単に説明したので、Hasura GraphQL エンジンを紹介するのに十分なコンテキストがあるはずです。 基本的に、Hasura は PostgreSQL RDBMS 用の単純な GraphQL エンジンであり、GraphQL API 開発のブートストラップと管理の簡素化された方法を提供します。 振り返ってみると、Hasura は現在、GraphQL-as-a-Service を既存の PostgreSQL ベースのアプリケーションに即座に追加できる、すぐに利用できる唯一のソリューションです。 基本的に、GraphQL を処理するバックエンド コードを記述するという時間のかかるタスクを回避します。
ハスラ簡体字
Hasura をさらに単純化してみましょう。 基本的に、API は、情報を要求 (クエリ) できるインターフェイスであり、JSON または XML データを送信して応答します。 通常、そのデータベースはホストされ、サーバーからフェッチされます。 ここで Hasura が登場し、物事を簡素化します。 後から考えると、Hasura GraphQL エンジンは、Postgres データベースで GraphQL クエリを処理するサーバーです。 これにより、アプリが本番環境に対応するまでの時間が効果的に短縮され、データベースのテーブルを数回クリックするだけで簡単に作成、表示、変更できるようになります。 その結果、フルスタックの開発者は PostgreSQL でスケーラブルな GraphQL アプリケーションを短時間で構築できます。 これにより、開発者は何週間も前もってコーディングする必要がなくなり、問題のあるデータ漏洩バグが本番環境に移行するのを防ぐことができます。
Hasura が API 開発で解決している問題は何ですか?
一般に、Hasura は、特に複雑な API の大規模な本番使用中の API ライフサイクル管理を簡素化します。 何よりも、GraphQL エンジンは、既存の PostgreSQL データベースを利用するエンタープライズ API 開発プロジェクトで未処理のフルスタック開発者を引き付けます。 理想的には、GraphQL は超高速の API 開発サイクルを可能にするため、既存のアプリケーション、データベース、またはユーザーに影響を与えることなく、組織が段階的に GraphQL に移行するための簡素化された方法を Hasura が提供します。 軽量で高性能なだけでなく、エンジンには管理 UI が付属しており、GraphQL API を探索し、データベース スキーマとデータを視覚的に管理できます。
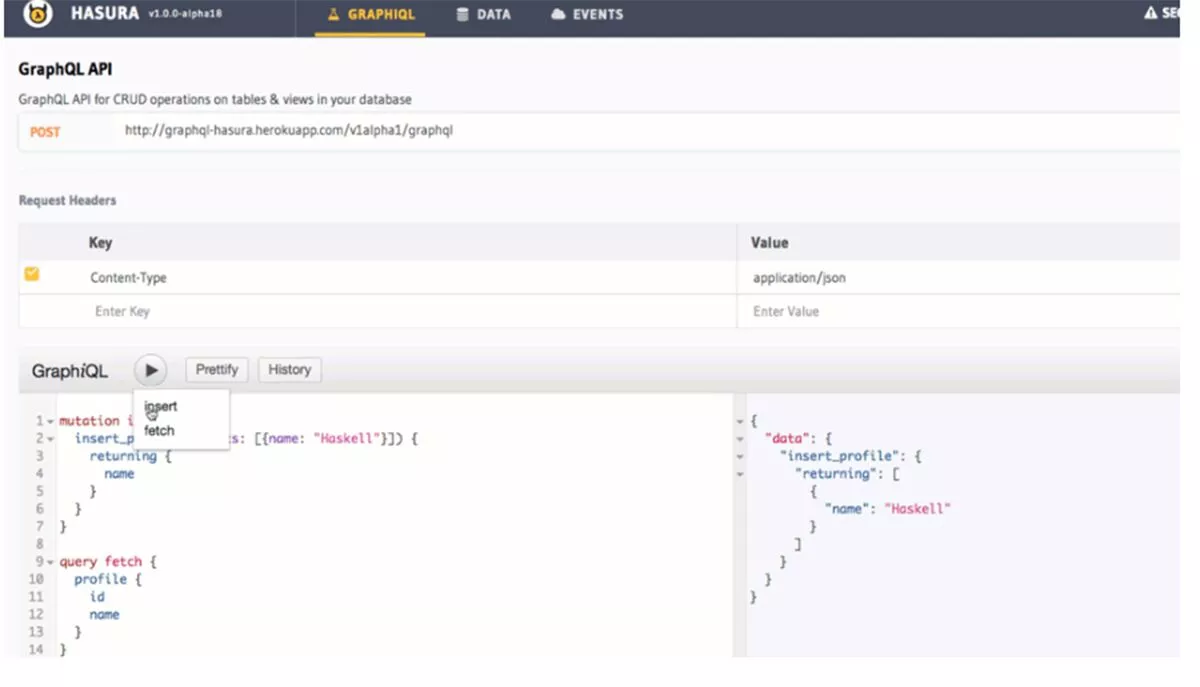
ハスラのメリット
まず、Hasura には、データベースの変更または「移行」を管理するための堅牢で安定したモデルがあります。 データベース スキーマの管理は難しいことが多いため、これは有利です。 たとえば、次のようなタスクです。 経時的な変更の追跡と、スキーマの変更と API の拡張との関連付け (スキーマ管理)。 さらに、新しいデータベースをデプロイしたり、変更をロールバックしたりできるスクリプトの保守などの日常業務は、退屈で、診断が困難なバグや機能停止を引き起こす可能性があります。 良い点として、Hasura データベース移行コンポーネントはプレーン SQL であるため、Hasura ツールセットの外に移植できます。 全体として、Hasura には優れたスキーマ管理機能があり、Web ソケット接続を処理するためのコードを記述する必要はありません。
次に、Hasura GraphQL エンジンにより、単一のクエリで必要なデータを簡単に取得できます。 これは、テーブルまたは他のビューへの関係としてビューを追加できるようにすることで実現します。 さらに、データベース イベントでトリガーされるサーバーレス関数またはマイクロサービス API のスキーマ ステッチおよび統合を使用して、カスタム リゾルバーを作成できます。 これは便利で、3factor アプリの構築を容易にします。 実のところ、ハスラは非常に軽量なエンジンです。 振り返ってみると、1 秒あたり 1000 を超えるリクエストを処理している場合でも、最大 50 MB の RAM しか消費しません。 素晴らしい投資収益率!
具体的には、Hasura は、きめ細かな API データレベルの承認と認証をさらに容易にします。 Webhook、JWT、Auth0、またはカスタム実装のいずれかを介して、優先認証プロバイダーに接続できます。 したがって、管理者、匿名ユーザーなど、さまざまなデータにアクセスできるユーザーを定義する、ユーザーの役割の仕様。一般に、その詳細なアクセス制御システムは、GraphQL スキーマと同様のデータベース テーブル構造に基づいています。 さらに、データベースの操作と値に基づいて、カスタム パーミッション ルールが厳密に定義されます。
最後に、Hasura は、単純な SQL に似たオフセット/制限モデルを使用して効率的なページングを見事にサポートします。 たとえば、アクセス制御モデルを使用して、特定のクエリに対して返される行数を制限します。 そのモデルにより、役割ごとに制限を調整できます。 たとえば、はるかに高いリクエスト レートを課すユーザーは、より小さな行制限に制限されます。 これにより、データベースと GraphQL エンジンへの負荷が回避されます。 さらに、特筆すべきは、Hasura は GraphQL のみに制限していません。 Hasura が管理する Postgres テーブルに対して REST またはその他の非 GraphQL マイクロ サービスを引き続き実行できます。 これは、Hasura の自動スキーマ ステッチで可能です。 これにより、Hasura 以外の GraphQL サービスとバックエンドを単一の統合スキーマにマージし、Hasura が管理する新しい API をレガシー API およびデータと組み合わせることができます。
ハスラのユースケース
高性能環境に適した Hasura Engine は、既存のデータベースでの GraphQL-Postgres 実装を自動化しながら速度を提供します。 その結果、これにより、既に Postgres を使用している企業は、既存のテーブルを「グラフ」にリンクすることで、ストレスの少ない漸進的な方法で GraphQL に移行できます。 Hasura はスキーマ スティッチングを効率的に処理し、カスタム ビジネス ロジックを簡単に適用できるようにします。 リモート GraphQL スキーマを使用すると、Hasura をカスタム ビジネス ロジックのゲートウェイとして活用して、好みの言語で GraphQL サーバーに書き込み、後でデータを単一のエンドポイントに公開できます。 さらに、Hasura には、GraphQL のサブスクリプションと呼ばれる組み込みのライブクエリを使用したクエリとミューテーションのための優れた構文があります。
ハスラのいくつかの制限
残念ながら、Hasura のアクセス制御システム モデルは、すべてのアプリケーションで完全に機能するわけではありません。 たとえば、個々の入力パラメーターのレベルでの API アクセス許可は完全にはサポートされていません。 ほとんどの場合、移行が必要な Postgres データベースに限定されているという事実は言うまでもありません。 無視できるものではありますが、GraphQL API が不正な形式のリクエストに対して返すエラー メッセージは、Hasura では非常に使いにくいものです。 それ以外の場合、この Hasura GraphQL Engine の紹介で見たように、Hasura ができないことはほとんどありません。
結論
結論として、GraphQL が成長するにつれて、企業内での API 開発がさらに簡素化され、Web スケールで構築されるようになります。 さまざまな業界で GraphQL が広範に急速に採用されていることから、Hasura は業界標準のテクノロジーである GraphQL と Postgres を使用して、API の作成と管理をさらに自動化する可能性を秘めています。 Hasuraは、CRUD (作成、読み取り、更新、および削除) GraphQL バックエンドの作成を簡素化します。 さらに重要なことは、バックエンド コードを記述せずに、GraphQL 中心の API と Postgres を使用してゼロから始める場合、Hasura が断然最良かつ唯一のオプションです。 GraphQL と Hasura エンタープライズの可能性に関するご質問やご相談は、お気軽にお問い合わせください。 Hasura GraphQL Engine の紹介は以上です。