
NosqlのSparkですか
公開: 2023-02-05Spark は、データ、特に大規模なデータ セットを操作するための強力なツールです。 高速かつ効率的に設計されており、 NoSQL データベースを含むさまざまなデータ形式をサポートしています。 NoSQL データベースは、大量のデータの処理に適しているため、ますます人気が高まっています。 Spark は、NoSQL データを効率的にクエリおよび操作するのに役立ちます。
効果的に作業するには、Apache Spark と NoSQL ( Apache Cassandraと MongoDB) を使用してアプリケーションのデータベースを管理することが重要です。 このブログの目的は、NoSQL バックエンドを使用して Apache Spark アプリケーションを開発するためのヒントを提供することです。 これはテーマ パークであり、TCP/IP sPark には CassandraLand と MongoLand の両方に乗り物があります。 DOE データのクエリを実行しようとすると、Spark アプリケーションが軸から外れ始めました。 ここでの教訓は、Cassandra にクエリを実行する場合、キー シーケンスが重要であるということです。 CassandraLand では、最も人気のあるアトラクションの 1 つであるパーティショナー ジェット コースターも提供しています。 顧客がジェット コースターに乗って楽しんでいる間、乗り物のオペレーターは情報を保持することで、毎日誰が乗ったかを追跡できます。
レッスン 1 では、MongoDB 接続の管理について説明します。 エネルギー省の新しい公園メンバーシップ ステータスなど、公園に関する情報を更新する必要がある場合は、 mongo インデックスを使用できます。 MongoDB と Spark を使用して、接続が適切に管理されていることを確認し、特定の場合にはインデックスを作成する必要があります。
Apache Spark は、大規模なデータ ワークロードで使用するために構築された、オープン ソースの一般的な分散処理システムです。 この機能は、インメモリ キャッシュと最適化されたクエリ実行に加えて、大量のデータに対する高速な分析クエリを可能にします。
ほぼ同じコードで、より効率的で汎用性が高く、バッチ データとリアルタイム データを同時に処理できます。 その結果、古いビッグ データ ツールは、この機能が不足しているため、ますます時代遅れになっています。
Spark とはどのような種類のデータベースですか?
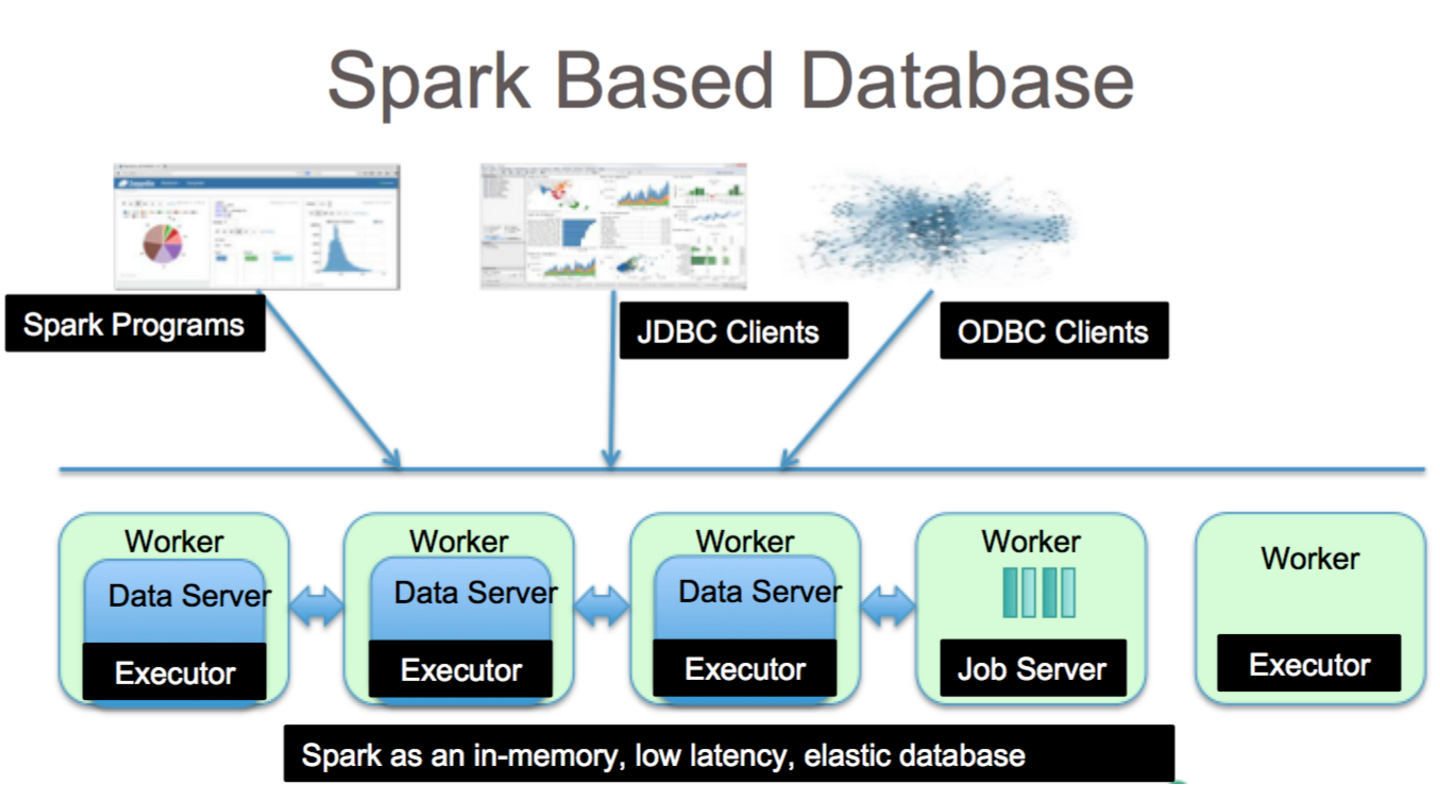
Apache Spark は、(HDFS)、NoSQL データベース、リレーショナル データベースなど、さまざまなデータ リポジトリからのデータを処理できるデータ処理フレームワークです。
リレーショナル データベースには数多くのハイプ サイクルがありましたが、最新の進歩や NoSQL データベースの台頭に関係なく、人気は続くでしょう。 時間の経過とともに、リレーショナル データベースにデータを格納することはますます難しくなっています。 この記事では、リレーショナル データベースの能力を世界規模で利用する際の重要な進歩のいくつかを見ていきます。 最初にリリースされたとき、Spark と Big Data Analysis の間のインターフェースは最小限でした。 多くの人がこのプログラムを実行するために多くのコードを書きました。このプログラムは強力ですが、比較的低速でした。 ユーザーは、これら 2 つのモデルをSpark SQLデータベースで簡単に組み合わせることができます。 また、さまざまなソースからの幅広いデータ形式も受け入れます。
Apache Spark オープン ソース プロジェクトは最も活発で、何百人ものコントリビューターが貢献しています。 無料のオープン ソース プロジェクトであることに加えて、Spark SQL は主流の業界で人気を博し始めています。 Spark SQL に加えて、Databricks Cloud のお客様 (Spark を実行しているホストされたサービス) の約 3 分の 2 が他のプログラミング言語を使用しています。 最初のケース スタディの結論に続いて、この実践的なケース スタディでデータブリックをケースに適用する方法を示します。 Spark DataFrameは、同じスキーマで配布される一連の行 (行の種類) です。 データセットの各列には名前が付けられています。 DataFrame の API を使用すると、開発者は手続き型コードとリレーショナル コードを統合できます。
Spark は、UDF などの高度な機能も処理できます。 リレーショナル データベースのテーブルは、データフレーム データベースのデータフレームに似ていますが、さらに最適化が必要です。 これらは、Spark のネイティブ分散コレクション (RDD) と同じ方法で操作できます。 一般に、 Spark SQL クエリは Shark クエリよりも高速で、Impulsa との競合性が高くなります。 クエリの選択性によってテーブルの 1 つが非常に小さくなるクエリ 3a では、Impala と Impala の間に大きな違いがあります。

これは、Spark SQL を使用したデータ分析のための素晴らしいツールです。 HiveQL 構文、Hive SerDes、および HiveDF には、HiveQL 構文、および Hive SerDes と HiveDF を介してアクセスできます。 Hive メタストア、SerDes、および UDF は既に実装されています。 Spark はデータベースですが、NoSQL データベースでもあります。 その結果、Spark でマネージド テーブルを作成すると、さまざまな SQL 準拠のツールを使用してデータを格納できるようになります。 jdbc.org からコネクタ経由で JDBC に接続することにより、SQL 式を使用して Spark のテーブルにアクセスできます。 その結果、Tableau、Talend、Power BI などのサードパーティ ツールも使用できます。 Spark を使用できることはデータ分析に最適であり、幅広い業界で役立つツールです。
Spark Sql: 両方の長所
前述の 2 つのモデル (手続き型モデルとリレーショナル モデル) の間のギャップを埋めるために、2 つの主要なコンポーネントが含まれています。 その結果、DataFrame API を使用して、外部データ ソースと Spark の組み込み分散コレクションで大規模なリレーショナル操作を実行できます。
データベースのスパークとは何ですか? これは、機械学習、対話型クエリ処理、およびリアルタイム ワークロードを使用するオープン ソース フレームワークです。 この会社には独自のストレージ システムがありません。 むしろ、独自のストレージ システムに加えて、HDFS、Amazon Redshift、Amazon S3、Couchbase などの他のストレージ システムで分析を採用しています。 構造化データ処理に関して言えば、Spark SQL は単なるデータベースではありません。 それもモジュールです。 その大部分は、SQL クエリと連携して動作するプログラミングの抽象化である DataFrames で記述されています。
「sparksql」の SQL sql のタイプは何ですか? Hive SQL は HiveQL 構文、Hive SerDes および UDF をサポートしているため、以前に作成された Hive ウェアハウスにアクセスできます。 Spark SQL で既存の Hive メタストア、SerDes、および UDF を使用することは難しくありません。
Mongodb は Spark を実行できますか?
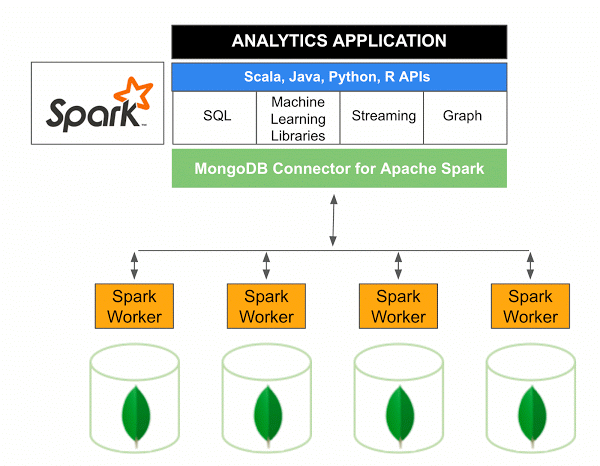
MongoDB Connector for Apache Spark のバージョン 10.0 には、新しい Spark Data Sources API V2 による Spark Structured Streaming のサポートと、新しい Spark Data Sources API V2の実装が含まれています。
Spark 用の MongoDB コネクタは、MongoDB からデータを書き込み、Scala を使用して MongoDB からデータを読み取ることができるオープン ソース プロジェクトです。 コネクタのユーティリティ メソッドにより、Spark と MongoDB 間のやり取りが簡素化され、高度な分析アプリケーションを作成するための強力な組み合わせになります。 組み込みのレプリケーションおよびシャーディング機能を使用して、Spark はMongoDB データベースを使用するさまざまなワークロードに実装できます。
Spark: データが豊富なアプリケーションを迅速に構築する方法
強力なツールである Spark の助けを借りて、より機能的なアプリケーションを迅速に開発できます。 MongoDB を組み込むことで、開発者は単一のデータベース テクノロジを利用して開発プロセスを高速化できます。 さらに、Spark はクラウドネイティブであり、 NoSQL データ ストアのサポートが含まれているため、データ集約型のアプリケーションに最適です。