
MapReduce: 大規模なデータ セットのプログラミング モデル
公開: 2023-01-08MapReduce はプログラミング モデルであり、クラスター上で並列分散アルゴリズムを使用して大規模なデータ セットを処理および生成するための関連する実装です。
新しいテクノロジーを使用して、大量のデータを処理する方法を変革しています。 Hadoop、NoSQL、Spark などのデータ ウェアハウスは、この分野で最も有名なプレーヤーです。 DBA およびインフラストラクチャ エンジニア/開発者は、高度なシステム管理を専門とする新しいタイプのプロフェッショナルです。 データベースの代わりに、Hadoop は大量のファイルの形で並列コンピューティングを可能にするソフトウェア エコシステムです。 このテクノロジーは、ビッグデータの大規模な処理ニーズをサポートするという点で大きなメリットをもたらしました。 大規模なデータ トランザクションの場合、中央のリレーショナル データベース システムでは通常 20 時間かかる大規模なトランザクションを処理するのに、平均的な Hadoop クラスターは 3 分しかかからない場合があります。
mapreduce クラスターは、並列アルゴリズムと、通常のクラスターと同じ方法で大規模なデータ セットを処理および生成するプログラミング モデルを備えたクラスターです。
Apache Hadoop エコシステムは、分散コンピューティングをサポートするように設計されており、信頼性が高く、スケーラブルで、すぐに使用できる環境を提供します。 このプロジェクトの MapReduce モジュールは、Hadoop (分散ファイル システム) 上にある巨大なデータセットを処理するために使用されるプログラミング モデルです。
このモジュールは、Apache Hadoop オープン ソース エコシステムのコンポーネントであり、 Hadoop Distributed File System (HDFS) 内のデータのクエリと選択に使用されます。 そのような選択を行う目的で使用できる MapReduce アルゴリズムを使用して、さまざまなクエリに対してデータを選択できます。
MapReduce を使用すると、大規模なデータ処理タスクを実行できます。 MapReduce プログラムは、C、Ruby、Java、Python などの任意のプログラミング言語で作成できます。 これらのプログラムを同時に使用して MapReduce プログラムを実行できるため、大規模なデータ分析に非常に役立ちます。
Mapreduce は Mongodb で何に使用されますか?
MongoDB のマップは、ユーザーが大規模なデータ セットを実行し、それらから集計結果を生成できるようにするデータ処理プログラミング モデルです。 MapReduce は、マップを縮小するために MongoDB で使用されるメソッドです。 この関数は、map 関数と reduce 関数の 2 つのコンポーネントに分かれています。
MongoDB のMapReduce ツールを使用すると、大規模なデータ セットを整理および集約できます。 MongoDB のこのコマンドは、大量のデータを処理するために、MongoDB の 2 つの主要な入力である map 関数と reduce 関数を使用します。 例を定義するには、次の手順に従います。 map 関数、reduce 関数、および例を定義します。
MapReduce は、既定の並べ替え方法を使用しているかどうかに関係なく、既定の並べ替え方法を使用して文字列を比較し、出力を並べ替えます。 データの並べ替え方法を変更するには、まず並べ替えアルゴリズムを作成し、マッパー クラスを使用して実装する必要があります。
SpiderMonkey は、広く使用されている JavaScript エンジンです。 小規模なアプリケーションには適していますが、いくつかの制限があります。 たとえば、SpiderMonkey にはソート アルゴリズムがありません。 そのため、Mapmapper を使用してデータを並べ替える場合は、まず独自の並べ替えアルゴリズムを作成し、それを Reduce クラスに実装する必要があります。
その人気にもかかわらず、SpiderMonkey はソート アルゴリズムを使用しません。 SpiderMonkey には他にも制限がありますが、これは注目に値します。 たとえば、SpiderMonkey には適切なガベージ コレクタがありません。そのため、プログラムの速度が低下し始めた場合は、速度を上げるために何らかの対策を講じる必要がある場合があります。
Mapreduce 関数を使用する理由
MapReduce 関数は、さまざまな状況で役立ちます。 このメソッドは、場合によってはバッチ データ処理に使用できます。 また、単一のアプリケーションまたはプロセスで大量のデータを処理する必要がある場合にも役立ちます。 MapReduce 関数を使用して、分散システム内の複数のノードに分散されたデータを処理することもできます。 MapReduce 関数を利用することで、ノードからのデータを 1 つの出力に結合できます。 MapReduce アプリケーションは通常、大量のデータを処理するために使用されますが、非常に大量のデータを処理する必要がある場合もあります。
Mapreduce と呼ばれる理由
MapReduce と呼ばれる理由については、いくつかの説があります。 1 つは、これは言葉遊びであるということです。map-reduce アルゴリズムでは、問題を小さな断片に分割し (マッピング)、それらの断片を解決して元に戻す (削減) 必要があるからです。 もう 1 つの理論は、2004 年に Google の従業員によって書かれた「MapReduce: Simplified Data Processing on Large Clusters」という論文への言及であるというものです。 この論文では、著者は「マップ」と「リデュース」という用語を使用して、提案された処理モデルの 2 つの主要なフェーズを説明しています。
ただし、MapReduce モデルは限定的にしか使用されないことに注意してください。 大規模なデータセットには適さず、適切に機能させるには並列化する必要があります。 これらの問題に対処する場合、Apache Spark には MapReduce の強力な代替手段があります。 Spark クラスター コンピューティング システムは、Hadoop に基づいており、汎用コンピューティング プラットフォームとして機能します。 このツールを使用すると、データ マイニングや機械学習などの従来のデータ分析タスクだけでなく、データ ウェアハウスやビッグ データ分析などのより複雑なデータ処理タスクを高速化できます。 このソフトウェアは、スケーラブルでフォールト トレラントなプログラミング言語である Erlang を使用して構築されています。 大量のデータを処理でき、同時に複数のマシンで実行できます。 さらに、Spark は並列処理を採用しているため、複数のノードが同じタスクを同時に実行できます。 全体として、大規模なデータ分析タスクを自動化し、よりスケーラブルにする可能性があります。 処理を並列化し、大規模なデータ セットを処理する必要がある場合、これは MapReduce の優れた代替手段です。
Mapreduce と集計の違いは何ですか?
ビッグデータを扱う場合、mapreduce は大量のデータからデータを抽出するための重要な方法です。 現在、MongoDB 2.2 には新しい集計フレームワークが含まれています。 機能の点では、集計は mapreduce に似ていますが、紙の上では、より高速に見えます。
このシナリオでは、MongoDB Aggregation と MapReduce が Sharded セットアップの Docker コンテナーで実行されます。 アグリゲーター パイプラインのパフォーマンスは、mapreduce よりも優れています。より高速で簡単なナビゲーションが可能だからです。 問題の仕組みは次のとおりです。tweet は、Twitter のハッシュタグで「den」、「denne」、「denna」、「det」、「han」、「hon」、「hen」などのスウェーデン語の代名詞 (大文字と小文字を区別) をカウントします。 ユーザーはいくつの Twitter ハンドルを持っていますか? 400万以上のツイートが送信されました。 この実験では、最初に MongoDB データベースを作成し、シャーディングを有効にします。 Twitter ストリームがデータベースにインポートされ、MapReduce と Aggregation Pipeline を使用したクエリが実行されました。
Mapreduce: 究極のデータ集約ツール
mapReduce プログラムは、コレクションからドキュメントのリストを読み取り、一連の定義済み関数を使用してそれらを処理します。 mapReduce オペレーションは、reduce 段階で処理される、すぐに処理できるドキュメントのストリームを生成します。 さまざまな状況で mapreduce と集計を組み合わせることができます。 $group 集計演算子は、ドキュメントを 1 つのフィールドにグループ化するために使用できるツールです。 $merge 集計演算子を使用して複数のドキュメントをマージすると、新しいドキュメントを作成できます。 $accumulator 集計演算子を使用して、複数の map-reduce 操作の結果を 1 つのドキュメントに表すことができます。
Mongodb で Mapreduce
Mongodb mapreduceは、大規模なデータ セットのデータ処理テクノロジです。 これは、データを分析するための強力なツールであり、データを並列かつ分散して処理および集計する方法を提供します。 MapReduce は、Web トラフィック分析、ログ分析、ソーシャル ネットワーク分析など、さまざまなドメインでのデータ分析に広く使用されています。

mapReduce コマンドを使用すると、コレクションに対して map-reduce 集計操作を実行できます。 map 関数は、任意のドキュメントをゼロまたはその他のドキュメントに変換できます。 4.2 以前の MongoDB バージョンでは、各エミットは最大 BSON ドキュメント サイズの半分しか保持できません。 MapReduce で使用されている非推奨の BSON タイプの JavaScript コードはサポートされなくなり、そのコードはその機能に使用できなくなりました。 MongoDB 4.4 には、スコープ (BSON タイプ 15) を持つ非推奨の BSON タイプ JavaScript コードが含まれなくなりました。 scope パラメーターは、reduce 関数がアクセスできる変数を指定します。 入力を減らすために、MongoDB は BSON ドキュメントのサイズを最大サイズの半分に制限します。
サーバーに返された大きなドキュメントが返され、その後の削減でマージされる可能性があり、要件に違反する可能性があります。 MongoDB 4.2 が最新バージョンです。 このオプションを使用して新しいシャード コレクションを作成したり、map-reduce を使用して同じコレクション名で新しいコレクションを作成したりできます。 finalize 関数は、キー値と reduce 関数からの縮小値を引数として受け取ります。 out パラメータの設定には 3 つのオプションがあります。 このオプションは、新しいコレクションの作成に加えて、レプリカ セットのセカンダリ メンバーでは機能しません。 NonAtomic: false オプションは、渡すコレクションがすでに存在し、明示的な指定がある場合にのみ指定できます。
新しいドキュメントのキーが既存のドキュメントのキーと同じ場合、新しいドキュメントと既存のドキュメントの両方で reduce 関数を使用します。 collectionName が設定済みのハード化されていない既存のコレクションである場合、map-reduce は機能しません。 この場合、nonAtomic が true の場合、MongoDB はデータベースをロックできません。 このオプションを使用するレプリカ セットのセカンダリ メンバーのみをセットから除外できます。 map-reduce 操作を書き直すためのカスタム関数は必要ありません。 cust_id は、cust_id メソッドによって $group ステージ グループの値フィールドを計算するために使用されます。 $merge ステージは、利用可能な集約パイプライン演算子を使用して、$merge ステージの結果を出力コレクションに結合します。
例として、$out ステージを使用して、コレクション agg_alternative_1 の出力を書き込むことができます。 各入力ドキュメントはマップ機能で処理できます。 注文の各アイテムは、カウント 1 と注文のアイテム数量の両方を含む新しいオブジェクト値に関連付けられます。 ReducedVal では、カウント フィールドは、配列要素によって生成されたカウント フィールドの合計を表します。 ファイナライズ関数が、avg という名前の計算フィールドを含むように ReducedVal オブジェクトを変更すると、変更されたオブジェクトがユーザーに返されます。 $unwind ステージは、items 配列フィールドを使用して、ドキュメントを各配列要素のドキュメントに分割します。 $project ステージは、2 つのフィールド -id と value を含めることにより、mapreduce の出力をミラーリングするために、出力ドキュメントを再形成します。
新しい結果と同じキーを持つ既存のドキュメントがない場合は、既存のドキュメントを上書きします。 out パラメーターを指定すると、結果をコレクションに書き込みたい場合、mapReduce は次の形式の出力としてドキュメントを返します。 出力がインラインで書き込まれる場合、結果のドキュメントの配列が返されます。 各ドキュメントには、ソース ドキュメントの名前と受信者ドキュメントの名前の 2 つのフィールドがあります。 キー値が -id フィールドに入力されると、キーの値を削減または確定するための値フィールドが作成されます。
MongodbのEmitとは何ですか?
マップ関数として、マップ関数はいつでも emits (key,value) を呼び出して、キーと値を含む出力ドキュメントを生成できます。 MongoDB 4.2 以前の単一の発行では、MongoDB の BSON ファイルの最大サイズの半分しか保持できません。 MongoDB のバージョン 4.4 から、この制限はなくなりました。
Mongodb が柔軟でスケーラブルなデータに最適な理由
厳格なスキーマがないため、MongoDB は NoSQL と関連付けられることがよくあります。 厳格なスキーマがないため、データはアプリケーションにとって便利な任意の形式で格納できます。 データベースの柔軟性は、アプリケーションのニーズに合わせて調整された方法でデータを格納できることを意味するため、スケールアップまたはスケールダウンする際に重要な利点を提供します。
ER図を含むデータ図を使用して、さまざまなデータ間の関係を視覚化できます。 ER ダイアグラムは、データのコレクションを表す一連のノードを表し、それらの間の接続が識別子として機能します。
MongoDB はリレーショナル データベースではないため、関係は適用されません。 ER図は、データ内に存在する関係を示し、それらを視覚化するのにも役立ちます。
MongoDB は、柔軟でスケーラブルなデータに最適です。 その柔軟性により、アプリケーションにとって意味のある方法でデータを格納でき、そのスケーラビリティにより、大規模なデータ セットをすばやく簡単に処理できます。
Map-reduce Mongodb の例
MongoDB では、map-reduce はコレクションからデータを集約するためのデータ処理パラダイムです。 これは、関数型プログラミングの map および reduce 関数に似ています。
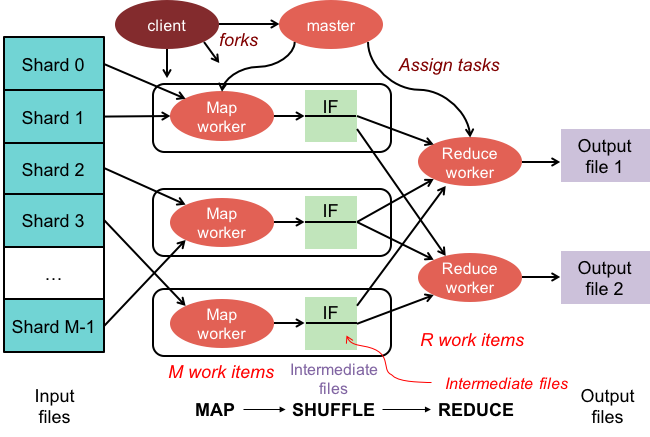
Map-Reduce 操作には 2 つのフェーズがあります。
1. マップ フェーズでは、コレクション内の各ドキュメントにマッピング関数を適用します。 マッピング関数は、入力ドキュメントごとに 1 つ以上のオブジェクトを発行します。
2. reduce フェーズは、reduce 関数を map フェーズによって生成されたドキュメントに適用します。 reduce 関数はオブジェクトを集約し、単一のオブジェクトを出力として生成します。
たとえば、記事のコレクションを考えてみましょう。 map-reduce を使用して、各記事の単語数を計算できます。
まず、各ドキュメントのキーと値のペアを発行するマッピング関数を定義します。ここで、キーは記事 ID で、値は記事内の単語数です。
次に、各キーの値を合計する reduce 関数を定義します。
最後に、コレクションに対して map-reduce 操作を実行します。 結果は、集計データを含むドキュメントです。
mongosh にはデータベースがあります。 mapReduce() メソッドは、mapReduce コマンドのラッパーです。 このセクションでは、カスタム集計式を使用しない集計パイプラインの代替例など、いくつかの例を示します。 Map-Reduce to Aggregation Pipeline Translation Examples を使用して、カスタム式でマップを変換できます。 map-reduce 操作は、利用可能な集計パイプライン演算子を使用してカスタム関数を定義することなく変更できます。 map 関数を使用して、入力内の各ドキュメントを処理できます。 各アイテムには、番号 1、注文の数量番号、およびアイテムのリストを含む新しい値に関連付けられた独自のオブジェクト値があります。
現在のドキュメントのキーが新しいドキュメントのキーと同じである場合、操作はそのドキュメントを上書きします。 カスタム関数を定義するのではなく、集計パイプライン演算子を使用して map-reduce 操作を書き直すことができます。 $unwind ステージは、items 配列フィールドごとにドキュメントを分割し、各配列要素のドキュメントを作成します。 $project ステージが出力ドキュメントを再形成すると、map-reduce 出力がミラーリングされます。 操作は、新しい結果と同じキーを持つ既存のドキュメントを上書きします。
Hadoop の Mapper 関数とは何ですか?
リデューサーとして、マッパーからのデータを組み合わせて、統一された回答を生成する必要があります。 縮小出力は、生成された結果のサブセットを表すマップ出力のセットが入力として受け入れられたときに生成されます。
マッパーは、データを管理可能なチャンクに分割し、各チャンクをそのサイズに基づいてタスクに割り当てるために使用されます。 入力データはマッパー関数によって受信されます。ここには、実行するタスクを示すパラメーターがあります。
一連のアイテムは、出力でマッパーによってマップされたデータのチャンクに対応します。 その結果、map 出力は reducer に転送され、reduce 出力に変換されます。
エラーもマッパー関数によって処理されます。 この場合、マッパーはエラー出力を返しますが、これはマップ出力ではありません。 レデューサーはこのデータを処理できないため、マッパーはエラー メッセージを返します。
Hadoop エコシステム
Hadoop エコシステムは、ビッグ データを処理および保存するためのプラットフォームです。 これは多数のコンポーネントで構成されており、それぞれがデータの処理と保存において特定の役割を果たします。 エコシステムの最も重要なコンポーネントは、Hadoop 分散ファイル システム (HDFS)、MapReduce フレームワーク、およびHadoop 共通ライブラリです。