
NoSQL データベースでのマスター/スレーブ レプリケーションとマルチマスター レプリケーションの比較
公開: 2023-01-13NoSQL データベースでサポートされているさまざまな種類のレプリケーションがあります。 最も一般的なタイプのレプリケーションは、マスター/スレーブ レプリケーションです。 このタイプのレプリケーションでは、すべてのデータを含む 1 つのマスター サーバーがあります。 その後、スレーブ サーバーはマスター サーバーからデータを複製します。 このタイプのレプリケーションは非常に単純で、セットアップも簡単です。 また、非常に効率的で、優れたパフォーマンスを提供します。 NoSQL データベースでサポートされている別のタイプのレプリケーションは、マルチマスター レプリケーションです。 このタイプのレプリケーションでは、複数のマスター サーバーがあります。 各マスターサーバーにはデータのコピーがあります。 その後、スレーブ サーバーはすべてのマスター サーバーからデータを複製します。 このタイプのレプリケーションはセットアップがより複雑ですが、パフォーマンスが向上し、耐障害性が向上します。
NoSQLデータ レプリケーションに加えて、サーバー クラッシュが発生した場合に、構造化データ、非構造化データ、および半構造化データをコピーして保存できる堅牢な機能を提供します。 簡単なステップバイステップのプロセスで NoSQL データベースを使用する方法を発見してください。
データ複製: データはあるサーバーから別のサーバーに複製されるため、データの各ビットは複数のサーバーで見つけることができます。 レプリケーション プロセスは、マスター スレーブ レプリケーションとスレーブ アウェア レプリケーションの 2 つの段階に分けられます。 マスター/スレーブ レプリケーションでは、1 つのノードに書き込みを処理する権限が割り当てられますが、スレーブ認識レプリケーションでは、スレーブが読み取りとマスターとの同期を行うことができます。
MySQL には一方向の非同期レプリケーションが含まれており、1 つのサーバーがソースとして機能し、別のサーバーがレプリカとして機能します。
レプリケーション ファクター (RF) は、その名前が示すように、データ (行とパーティション) がレプリケートされるノードの数です。 複数のノード (RF=N) が接続されてデータが送信されます。 RF が 1 の場合は、クラスター内に行のコピーが 1 つしかなく、ノードがクラッシュまたは侵害された場合にデータを回復する方法がないことを示します。
Nosqlのシャーディングとレプリケーションとは?
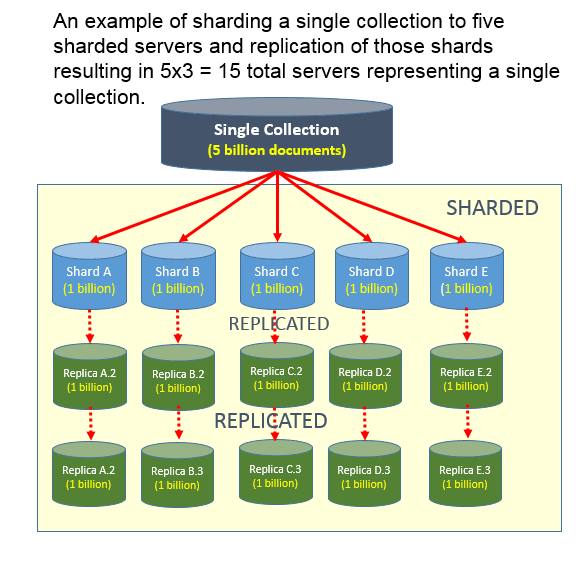
シャーディングとレプリケーションの違いは何ですか? データ複製は、プライマリ サーバー ノードとセカンダリ サーバー ノードがデータを交換するときに発生します。 これは、プライマリ サーバーに障害が発生した場合のバックアップとして、データの可用性を高めるのに役立ちます。 サーバー間で水平にスケーリングする機能は、シャード キーの使用に基づいています。
SQL データベースでは、データ セットをテーブルに分割し、各テーブルのパーティションを作成できます。 MongoDB などのNoSQL データベースには、テーブルはなく、代わりにドキュメントのコレクションがあります。 mongo shard コマンドは、MongoDB コレクションを分割するために使用されます。 単一のシャーディング環境で複数のサーバーに負荷を分散できるため、パフォーマンスが向上します。 大規模なデータセットになると、これは特に当てはまります。 さらに、シャーディングは、データの整合性を提供することにより、大規模なデータセットの管理と保護に役立ちます。 データのスケーリングに加えて、シャーディングはデータを効果的に管理するための優れたツールです。 このパターンは、実装が容易で幅広いサポートがあるため、NoSQL データベースで広く使用されています。
データ書き込みにシャーディングが適している理由
一般に、レプリケーションでは読み取りの水平スケーリングが可能ですが、単一のキーで複数のサーバー間でデータをスケーリングすることはできませんが、シャーディングでは可能です。
Nosql でサポートされているデータの種類は?
NoSQL データベースは、幅広いデータ型をサポートしているため、ますます人気が高まっています。 これには、数値や文字列などの従来のデータ型と、JSON や XML などの新しいデータ型の両方が含まれます。 NoSQL データベースは幅広いプログラミング言語もサポートしているため、複数の言語を使用する企業に適しています。
NoSQL データベースには、キーと値のペア、列、グラフ、およびドキュメントの 4 つのタイプがあります。 すべてのカテゴリには、独自の一連の特性と制限があります。 MongoDB データベースは、人気のある NoSQL データベースです。 これは、両方のペアを格納するキーと値のペア データベースです。 このアプリケーションは使いやすく、スケーラブルで高速です。 ドキュメント指向データベースは、CouchDB の焦点です。 このアプリケーションは使いやすく、複数のユーザーに対応できる柔軟性があります。 データベース CouchBase は列指向で、トランザクションに重点を置いています。 Cassandra のデータベースは、高度な列指向のアーキテクチャに基づいています。 HBase ストレージ システムは、大規模なデータ セット向けのスケーラブルで分散型のペタバイト規模のストレージ ソリューションです。 Redis で動作する分散メモリ データベースです。 Riak をデータ ストアとして使用すると、オープンソースの高性能システムを構築できます。 グラフ データベースである Neo4J は、Java プラットフォーム上に構築されています。
Nosql が迅速に拡張する必要がある企業にとって最適な選択肢である理由
迅速にスケーリングする必要があるビジネスの場合、より柔軟なアーキテクチャを持ち、水平方向にスケーリングできる NoSQL が適しています。 さらに、NoSQL データベースは、従来のリレーショナル データベースほどスキーマの変更に敏感ではありません。
Nosql データ レプリケーションは
Nosql データ レプリケーションは、nosql データベースから別の nosql データベースにデータをコピーするプロセスです。 これは、データを安全に保ち、障害が発生した場合に常に使用できるようにするために行われます。
Nosql対。 Rdbms: どちらがパフォーマンスに優れていますか?
MongoDB などの NoSQL データベースが従来の RDBMS よりも優れていることを示す研究が増えています。 このテクノロジーにより、データのシャーディングとレプリケートが可能になるため、高いスループットとデータへの迅速なアクセスを必要とするアプリケーションに最適です。 データをレプリケートできる場合もありますが、常に可能であるとは限りません。
Nosql でのマスター/スレーブ レプリケーション
マスター/スレーブ レプリケーションは、プライマリ (「マスター」) サーバーから 1 つ以上のセカンダリ (「スレーブ」) サーバーにデータがコピーされるタイプのレプリケーションです。 スレーブ サーバーは読み取り操作に使用できますが、すべての書き込み操作はマスターに送信する必要があります。 このタイプのレプリケーションは、高可用性とスケーラビリティを提供できるため、Nosql データベースでよく使用されます。 たとえば、マスター サーバーがダウンした場合でも、スレーブを使用して読み取り要求を処理できます。 また、より多くの読み取り容量が必要な場合は、スレーブ サーバーを追加できます。
マスター/スレーブ レプリケーションの課題
マスター/スレーブ レプリケーション モデルのすべてのスレーブ ノードでデータを維持することは困難な場合があります。 スレーブ ノードの 1 つがダウンすると、そのスレーブ ノードのデータは失われます。
すべてのノードでデータベースの読み取りおよび書き込み操作をサポートするレプリケーション モデルはどれですか?
すべてのノードでデータベースの読み取りおよび書き込み操作をサポートする複製モデルは、Master- Master 複製モデルです。 このモデルでは、各ノードがマスターとして機能できるようになります。つまり、各ノードはデータベースの読み取りと書き込みを行うことができます。 これは、1 つのノードがダウンしてもすべてのノードが動作し続けることができるため、高可用性と冗長性を必要とする組織にとって有益です。

すべてのメモで、データベースの読み取りおよび書き込み操作をサポートするアプリケーション モデルはどれですか?
RDBMS は通常、スキーマ オン ライト モデルを使用します。このモデルでは、データ構造が事前に定義され、すべての読み取り操作と書き込み操作がその構造に依存します。
データベースの変更と更新は読み取り/書き込みモードで発生する可能性があります
OpenReadWrite() または OpenWrite によって制御される読み取り/書き込みモードでデータベースが開かれている場合、変更と更新は読み取り/書き込みモードで発生する可能性があります。 DatabaseReader は、データベースへのデータの読み取りと書き込みに使用できるクラスです。 DatabaseWriter オブジェクトを使用して、データベースにデータを書き込むことができます。
リレーションシップによって接続されたノードをサポートするデータベースのタイプはどれですか?
関係は、構造化された関係を使用してグラフ データベースに格納およびアクセスできます。 リレーションシップは、最も価値のある市民の一部であるため、グラフ データベースの最も価値のある側面です。 ノードはグラフ データベースでデータ エンティティを格納するために使用され、エッジはエンティティを接続するために使用されます。
Mongodb と Node.js: Javascript でグラフを操作するための完璧な組み合わせ
JavaScript でグラフを使用する場合は、MongoDB を使用する必要があります。 MongoDB は最も人気のある NoSQL データベースですが、Node.js も人気のある JavaScript プログラミング言語です。
非リレーショナル データベース レプリケーションの仕組み
ピア ツーピアの NoSQL データ レプリケーション インスタンスでは、データは、各コピーが独自のコピーを更新し続ける必要があるという概念に基づいて、あるデータベースから別のデータベースに複製されます。 これが機能するのは、スキーマの各コピーが同じタイプのデータを同じ形式で格納する場合のみです。 このデータ複製方法のもう 1 つの重要な側面は、データベースの復元です。
さまざまな種類のレプリケーション
*br *ストレージ レプリケーション *br データの変更を一貫した方法で保存するタイプのレプリケーションです。 ソース レプリカ サーバーは、データベースのスナップショットを作成した後、現在の状態情報を使用してデータベースのスナップショットを作成します。 次に、スナップショットが宛先レプリカ サーバーに送信されます。 スナップショットに続いて、宛先レプリカ サーバーはデータベースの新しいコピーを構築します。 データでのトランザクション レプリケーションの参照 トランザクションは、頻繁に変更されるデータに格納され、トランザクション レプリケーションを使用してレプリケートできます。 トランザクションはまとめてバッチ処理され、単一のバッチで複製されます。 データへの変更は、レプリケーションと呼ばれるプロセスによって複製されます。 ピア ツー ピア レプリケーションは、サーバーを使用して実現できます。 ピア ツー ピア データ レプリケーションは、頻繁に変更されないデータをレプリケートすることを目的としたデータ レプリケーションの一種です。 ピア ツー ピア データ レプリケーションでは、ノードのクラスターがデータをレプリケートします。 クラスタ内の各ノードには、独自のデータ モデルがあります。 クラスタ ノードはお互いを認識しません。
Nosql ドキュメント データベースのレプリケーション
Nosql ドキュメント データベースは、複数のサーバー間でデータを複製することにより、高可用性とスケーラビリティを提供するように設計されています。 これにより、1 つまたは複数のサーバーに障害が発生した場合でも、データベースは動作を継続できます。
ビッグ Nosql データベース
ユーザーの特定のニーズに依存するため、この質問に対する決定的な答えはありません。 ただし、最も人気のある大規模な nosql データベースには、MongoDB、Cassandra、Hadoop などがあります。 これらのデータベースはすべて、スケーラビリティと高性能を提供するように設計されているため、大規模なデータ処理に最適です。
たとえば、MongoDB のような NoSQL データベースは、大量のデータをすばやく簡単に処理できるため、ビッグ データに最適です。 MongoDB はドキュメント指向の MongoDB であるため、膨大な量のデータを処理できます。 つまり、MongoDB は、JSON、BSON、JavaScript Object Notation (JSON) など、さまざまな形式のデータを処理できます。 また、データへのアクセスと保存が簡単になります。 さらに、MongoDB はスケーラブルであるため、大量のデータを処理できます。
ビッグデータに最適な Nosql データベースはどれですか?
非構造化データと半構造化データをアプリケーションで使用できる形式に変換するために、分析ツールが使用できる形式を作成します。 ビッグ データを格納するための独自の要件により、MongoDB などの NoSQL (非リレーショナル) データベースが優れた選択肢になります。
Mongodb がビッグデータの保存に最適な理由
MongoDB は、大量のデータを保存および管理するための優れた選択肢です。 CRUD (作成、読み取り、更新、削除) 操作、集計フレームワーク、テキスト検索、および Map-Reduce 機能により、ユーザーはデータへのアクセス、操作、および分析を簡単に行うことができます。
ビッグデータは Nosql ですか?
データ ワークロードが、ビッグ データなどの大量の多様で構造化されていないデータの迅速な処理と分析に重点を置いている場合は、NoSQL を選択することをお勧めします。 NoSQL データベースには、リレーショナル データベースと同じデータ型の制限はありません。
Nosql データベースがデータ管理の未来である理由
データベース NoSQL は、従来のリレーショナル データベースに比べてパフォーマンスが大幅に優れているため、ますます人気が高まっています。 これは、HBase などの特定のタイプの NoSQL データベースを有効にする NoSQL データベース イネーブラーであり、パフォーマンスを低下させることなくデータを数千のサーバーに分散できます。 Google のクラウド プラットフォーム (GCP) は、スキーマを必要とせずに非常に大規模で動的なデータセットを処理できる独自の機能を備えた、さまざまなデータベース サービスのセットを提供します。
大企業は Nosql を使用していますか?
クラウド コンピューティング、Web、ビッグ データ、およびビッグ ユーザーに基づくデータベース テクノロジ。 従来の RDBMS の代替として NoSQL を提供することで、NoSQL は、LinkedIn、Google、Amazon、Facebook などの多くの人気のあるインターネット企業にとって実行可能な選択肢になりました。
Nosql は Instagram のバックエンド データベースの未来ですか?
現時点では、Instagram はプライマリ データベースとして PostgreSQL を優先しているように見えますが、これは変更される可能性があります。 人気のある NoSQL データベースである Cassandra は、Instagram に最適な場合とそうでない場合があります。 Cassandra は、大量のデータを格納するための優れたツールですが、パフォーマンスの実績はあまりありません。
現時点では、Instagram が NoSQL データベースをプライマリ バックエンド データベースとして使用するかどうかを予測することは困難です。 PostgreSQL と Cassandra は優れた選択肢ですが、パフォーマンスの点で SQL と競合することはできません。