
リレーショナル データベースから NoSQL データベースへのデータの移行
公開: 2023-02-22リレーショナル データベースは、長年にわたって企業にとって頼りになる選択肢でした。 しかし、ビッグ データの台頭と、より多くの非構造化データを処理する必要性から、NoSQL データベースと呼ばれる新しい種類のデータベースが生まれました。 リレーショナル データベースから NoSQL データベースへのデータの移行は、困難な作業になる場合があります。 しかし、適切なツールと計画があれば、比較的簡単に実行できます。 データを移行する際に留意すべき点がいくつかあります。 1. ニーズに適した NoSQL データベースを選択します。 NoSQL データベースにはさまざまな種類があるため、ニーズに合ったものを選択することが重要です。 2. リレーショナル データベースからデータをエクスポートします。 これは、データベースに応じて、さまざまなツールを使用して実行できます。 3. データを NoSQL データベースにインポートします。 繰り返しますが、これを支援するために利用できるさまざまなツールがあります。 4. テスト、テスト、テスト。 新しい NoSQL データベースでデータをテストして、すべてが正しく移行され、データにアクセスできることを確認することが重要です。
企業のデータ センターで実行され、30 年以上にわたり世界のデータの大部分を保持してきた、古いリレーショナル データベース管理システム (RDBMS) が、主要なデータ システムです。 続行できません。 RDBMS は、生成および消費されるデータの量、速度、および種類の増加に対応できなくなりました。 ビッグデータの新時代には NoSQL データベースが必要です。 従来の RDBMSから最新の NoSQL データベースへの移行が簡単であることは間違いありません。 リレーショナル データベースから NoSQL データベースに移行する適切な NoSQL ソフトウェアを選択するには、慎重な計画が必要です。 SQL と NoSQL Land は構文が大きく異なるため、この言語は、新しいユーザーには精神的な体操が必要になる場合があります。
これは一部の開発者が次のプロジェクトで NoSQL を使用することを思いとどまらせるかもしれませんが、そうするのを思いとどまらせるべきではありません。 Foursquare の規模により、数百万人のユーザーと 25 億を超えるチェックインを引き付けることができます。 NoSQL の優れた点の 1 つは、特定のビジネス ニーズを満たすために必要に応じてモデルを反復できることです。 リレーショナルの世界から移行した後、多くの新しいユーザーがクラウドに向かいます。 Foursquare と Art.sy は、リレーショナル データベースから NoSQL データベースに移行した 2 つの企業です。 RDBMS データをCassandra などの列指向データベースに移動するプロセスは、Riak などのキー値ストアにデータを移動するプロセスや、MongoDB にデータを移行するプロセスとは異なります。 成功しているビジネスのほとんどは、Nosql を主要なビジネス プロセス管理ツールとして使用して、最初から規模を拡大しています。
NoSQL データベースは完全に移行できますが、データを受け取るプログラミング言語で完全なスキーマ マッピングを行う必要があります。 データがますます異種化し、NoSQL データベースへの移行が加速し続けるにつれて、NoSQL データベースは、データ固有のスキーマの変更を受け入れる方法でデータを解釈できるようになります。
リレーショナル データベースを Nosql データベースに移行するにはどうすればよいですか?
リレーショナル データベースを nosql データベースに移行するには、いくつかの手順を実行する必要があります。 まず、データをリレーショナル データベースから、nosql データベースにインポートできるファイル形式にエクスポートする必要があります。 次に、nosql データベースのスキーマを作成する必要があります。 最後に、データを nosql データベースにインポートする必要があります。
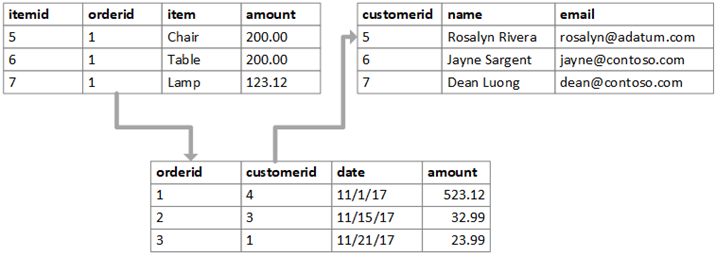
リレーショナル データを Nosql に保存できますか?
リレーションシップは一意であり、同じ方法で格納されないという点でリレーショナル データベースとは異なるため、NoSQL データベースに格納できます。 多くの NoSQL データベース ユーザーは、関連データをテーブル間で分離する必要がないため、NoSQL データベースでのリレーションシップ データのモデリングは、リレーショナル データベースでのデータのモデリングよりも簡単であると報告しています。
データは、単純なキーと値のペア、JSON ドキュメント、またはグラフを使用して保存できます。 Database-as-a-service (DBaaS) は、クエリを実行するために SQL を必要としないタイプのデータベースです。 これらのデータベースの多くは SQL 互換クエリをサポートしているため、「NoSQL」という用語は非リレーショナル データベースを指します。 ドキュメント ストアでは、すべてのドキュメントが同じ構造である必要はありません。 このアプローチにより、幅広いオプションを利用できます。 キーは、頻繁にハッシュされるドキュメントに割り当てられる一意の識別子です。 アトミック構造を持つ 1 つのドキュメントには、通常、複数のフィールドで記述された操作が含まれます。
ハッシュを計算する代わりに、ほとんどの列ファミリー データベースのデータはキー順に物理的に格納されます。 行キーはプライマリ インデックスと見なされ、特定のキーまたはキーのセットを介してキー ベースの情報にアクセスできます。 一部の実装を使用して、列ファミリー内の列にセカンダリ インデックスを作成できます。 キーまたはキーのセットの値を使用して単純なルックアップを実行するために、キー/値ストアは高度に最適化されています。 グラフ データ ストア内のデータ ストアは、ノードとエッジの 2 つのカテゴリに分けられます。 ノードは任意のエンティティを表すことができ、エッジは任意のエンティティまたはエッジ間の関係を示すことができます。 グラフ データベースなどのクエリ言語を使用すると、リレーションシップのネットワークを簡単にトラバースできます。
時系列データ ストアは、最適な方法でテレメトリ データを格納するように設計されています。 IoTセンサーやアプリ・システムカウンターの利用が可能です。 場合によっては、オブジェクト データ ストアが複数のサーバー ノード間で BLOB をレプリケートします。 ファイル共有を使用する場合、サーバー メッセージ ブロック (SMB) などの標準ネットワーク プロトコルを使用して、ネットワーク経由でファイルにアクセスできます。 外部インデックスは、データ ストアの場合にセカンダリ インデックスとして機能します。 このソフトウェアは、膨大な量のデータを保存し、それにほぼリアルタイムでアクセスできます。 インデックスは、インデックス方式を利用して作成されます。 フリーテキスト検索は、多次元になる可能性があるため、場合によってはサポートされる場合があります。
クラウド アーキテクチャは、クラウドネイティブになるように設計されています。 これは、ソフトウェアの開発と展開における最新のイテレーションです。 このモデルの目標は、クラウド、オンプレミス、またはハイブリッド モデルとして展開できる応答性の高いアプリケーションを有効にすることです。
組織は、ソフトウェアの全体的なコストを削減すると同時に、開発および配信プロセスをより適切に管理するために、ますますクラウドネイティブ アーキテクチャを採用しています。 クラウドネイティブ アーキテクチャを利用することで、迅速にスケールアップおよびスケールダウンできるアプリケーションを構築できます。 さらに、以前よりも変化に敏感であるため、今日のダイナミックなビジネス環境に最適です。
クラウドネイティブ アーキテクチャの目標は、マイクロサービスと分散システムを使用することです。 マイクロサービスの実装は、小規模で自己完結型の単一サーバーまたは仮想マシンの実装です。 分散システムは、複数のサーバーに分散されたマイクロサービスの集合です。
クラウドネイティブ アーキテクチャの一部として、マイクロサービスは重要なコンポーネントです。 この機能を使用して、アプリケーションを個別に展開でき、更新および迅速な置き換えが可能な小さなモジュラー ピースに分割できます。 このアプローチをソフトウェア開発に利用することで、アプリケーションの新しいバージョンを簡単にテストして展開できます。
マイクロサービス ベースのアーキテクチャは、クラウドネイティブ アーキテクチャの作成にも使用されます。 サーバーは、さまざまなマイクロ サービスの処理を処理します。 このアプローチの結果として、さまざまな方法でアプリケーションをスケーリングし、残りの部分から分離することができます。
一方、マイクロサービスベースのアーキテクチャは、分散システムに基づいています。 これは、アプリケーションがネットワーク内のすべてのノードに分散されていることを意味します。 この方法を使用すると、パフォーマンスに影響を与えずにアプリケーションをスケールアップまたはスケールダウンできます。
今日のグローバル化された世界では、企業はますますクラウドネイティブ アーキテクチャを採用しています。 以下のほかにもさまざまなメリットがあります。
ソフトウェアのコストが削減されました。
わずかなストレスに対処する能力
変化に適応すること。
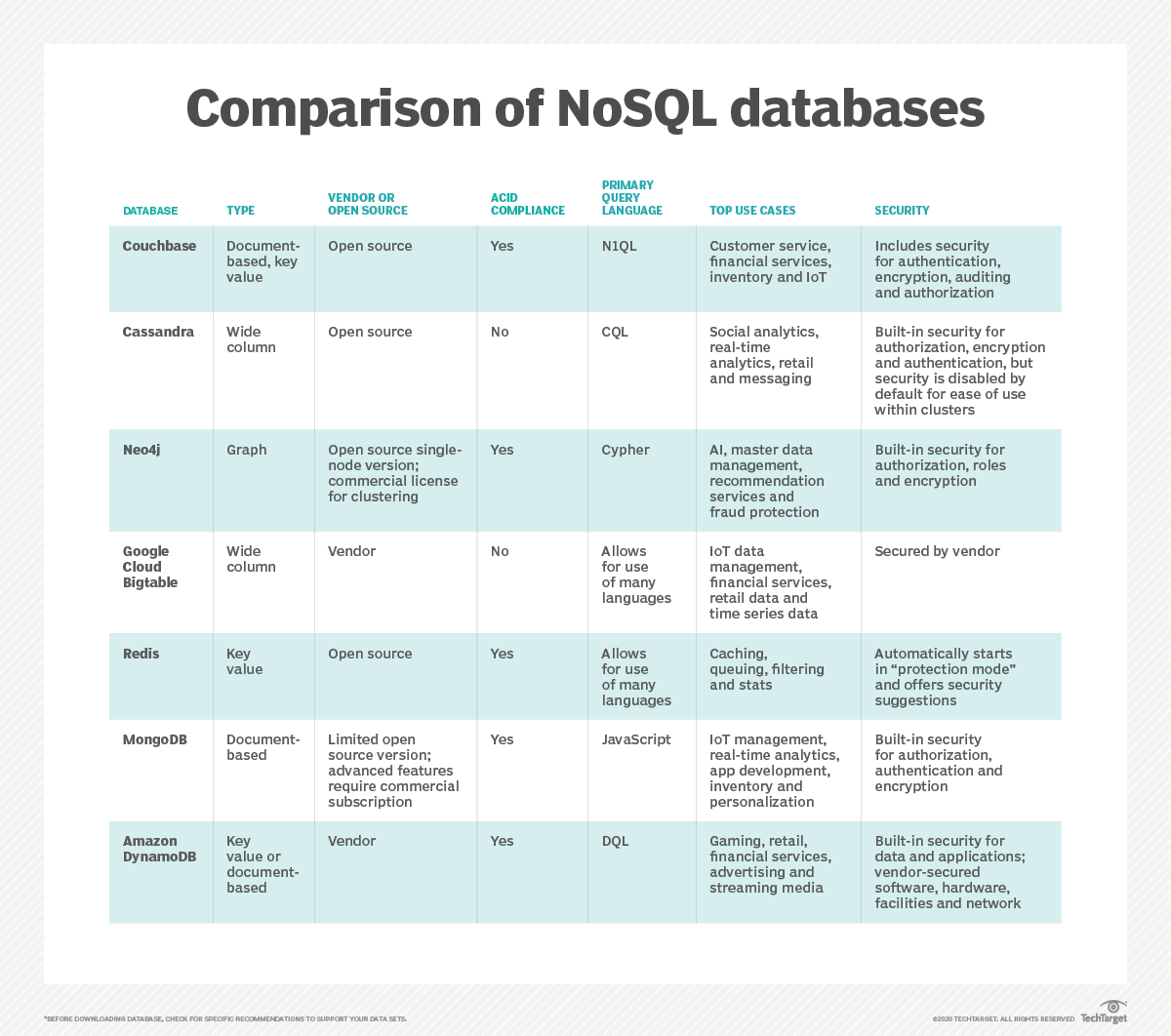
Nosql データベースの長所と短所
NoSQL データベースとリレーショナル データベースの主な違いは、データがドキュメントに格納されることです。 そのため、「SQL だけではない」と分類され、柔軟性に基づいてさまざまなデータ モデルに分類されます。 NoSQL データベースには、ドキュメント データベース、キー値ストア、幅の広い列のデータベース、およびグラフ データベースがあります。
MongoDB では、リレーショナル データベース管理システムやリレーショナル データベース構造 (RDBMS) を使用する必要はありません。 リレーショナル データベースと組み合わせて MongoDB を使用すると、それが可能になります。 たとえば、さまざまなデータ ソースのコレクションに関するデータ ビジュアライゼーションを作成している場合です。
Cassandra のデータ モデルは、大規模な読み取りクエリを中心に構築され、最適化されています。 さらに、Cassandra は、リレーショナル データベース (正規化されたトランザクションなど) 向けのトランザクション データ モデリングをサポートしていません。 Cassandra では、データを非正規化するのではなく、一度に 1 つのテーブルに対してクエリを実行できます。
NoSQL データベースは、厳格さの欠如にもかかわらず、場合によってはリレーショナル データベースと統合できます。 この方法では、リレーショナル データベースに依存して、データ モデルとデータ スキーマ、および NoSQL データベースを格納します。 その結果、NoSQL データベースとリレーショナル データベースの両方でのデータ クエリがより効率的になります。
SqlをNosqlに変換するにはどうすればよいですか?
Nosql データベースは、データの一貫性よりもスケーラビリティが重要な場合によく使用されます。 sql データベースを nosql データベースに変換するには、最初に sql データベースからファイルにデータをエクスポートする必要があります。 次に、 nosql データベース インポート ツールを使用して、データを nosql データベースにインポートできます。
NoSQL データベースは、単一のソフトウェアであったり、RDBMS および NoSQL データベースと連携して機能したりしている場合でも、さまざまな設定で頻繁に使用されます。 SQL から NoSQL に移行するには、スキーマとデータ ロジックをリファクタリングする必要があります。 ホスティングは提案されたテクノロジで実行する必要があり、パフォーマンスを最大化するために必要に応じて実行する必要があります。 AWS (Amazon Web Services) や Azure (Microsoft Azure) などのクラウド プラットフォームは NoSQL 上に構築されているため、このプラットフォームに移行することをお勧めします。 No SQL データベースを使用することの最も重要な利点の 1 つは、JSON を含むさまざまな形式でデータを取得できることです。 移植性が高いため、Web アプリケーションとモバイル アプリケーションの両方に最適です。
Sql と Nosql はハイブリッド データベースで一緒に使用できます
sql と nosql を一緒に使用できますか? ハイブリッドデータベースで組み合わせても問題ありません。
Rdbms から Mongodb にデータを転送するにはどうすればよいですか?

これを行うにはいくつかの方法がありますが、最も一般的なのは、MongoDB の mongoimport ユーティリティのようなツールを使用することです。 このツールは、さまざまなソースからデータを取得して、 MongoDB データベースにロードできます。
MongoDB は、高速かつ効率的なデータ ストレージの両方でうまく機能する NoSQL データベースです。 NoSQL データベースは、大量の非構造化データと半構造化データを格納および管理できます。 この記事では、リレーショナル データベースと MongoDB の間で基本的なリレーショナル概念をマッピングする方法を紹介します。 人気のある NoSQL データベースであるMongoDB は、その柔軟性と大規模なデータ コレクションを効果的に格納する機能により、大規模なデータ セットに最適です。 Hevo Data は、MongoDB、100 以上のデータ ソース (40 以上の無料データ ソースを含む)、多数の無料および有料データ ソースからの完全に管理されたデータ統合を提供するノーコード データ パイプラインです。 データをデータ ウェアハウスに直接アップロードすると、選択した宛先にそのデータが自動的に読み込まれます。 リレーショナル データベースから NoSQL データベースへの移行は難しいプロセスですが、柔軟でスケーラブルなソリューションを探している場合は価値があります。
データベース管理システムのバックグラウンドにより、事前定義されたリレーショナル モデルからリッチで動的なドキュメント データ モデルへの移行が困難になるという事実にもかかわらず、移行は可能です。 リレーショナル データベースから MongoDB にデータを移行することができます。 ただし、MongoDB ドライバーとツールを使用すると、プロセスがはるかに簡単になります。 この記事では、MongoDB でリレーションシップとリレーショナル データをモデル化する方法を紹介します。 これは、Linking Documents と Embedding Documents のアプローチを利用して実現します。 この記事では、リレーショナル データベースと MongoDB について、またそれらを区別する方法について説明します。 次に、リレーショナル データベースから MongoDB への移行に関連する手順について説明しました。 ビジネス パフォーマンスを理解するには、MongoDB およびその他のデータ ソースをクラウド データ ウェアハウスまたはさらにビジネス分析を実行できる別の場所に統合することが重要です。

Mongodb と Rdbms の大きな違い
同様に、MongoDB と RDBMS には、データへのアクセス方法にも違いがあります。 ドキュメント アクセスは、MongoDB でのデータ アクセスの推奨される方法です。 ドキュメントという用語は、フィールドの集まりを指します。 ドキュメント内の各フィールドの名前を使用してアクセスできます。 このメソッドを使用してフィールドの値を検索するだけで、データを照会できます。
MongoDB と RDBMS の大きな違いの 1 つは、データの更新方法です。 MongoDB データベースは、ドキュメントへの変更で常にデータを更新します。 ドキュメント内のフィールドを変更すると、新しい値がドキュメントに適用されます。
Rdbms を Nosql に移行する
この記事では、RDBMS から NoSQL への移行プロセスについて説明します。 RDBMS から NoSQL システムに移行する場合は、ドキュメント スキーマを定義する必要があります。 既存のアプリケーションで最もよく使用されるクエリを調べて、それらが適切に機能していることを確認します。 頻繁にアクセスされるデータ グループのリストにアクセスします。
RDBMS と NoSQL の違いは何ですか? RDBMS は、定義済みのスキーマとテーブルベースの構造を採用しています。 データは NoSQL でリッチ ドキュメントに編成され、埋め込まれたドキュメントは結合に置き換えられます。 用語に関して言えば、NoSQL と既存の DBMS の間にはいくつかの大きな違いがあります。 MongoDB などの NoSQL テクノロジーの進歩により、データの状況は劇的に変化しています。 RDBMS から NoSQL に移行する場合、いくつかの要因を考慮することが重要です。 最も効率的な方法は、コスト削減と柔軟性です。 オープンソース データベースの専門家を利用すると、移行がはるかにスムーズになります。
構造化データベースがデータ移行に最適なオプションである理由
新しいデータベースに移行する場合、最適なオプションは構造化データベースを使用することです。 リレーショナル データベースは大量のデータを処理できるため、他の種類のデータベースよりも操作が難しい場合があります。 一方、データ移行は構造化データベースの焦点です。 これらは、大規模なデータ セットの管理を容易にし、管理をより効果的に行うのに役立つ機能を備えています。
Nosql データベース
Nosql データベースは、従来のリレーショナル モデルを使用しないデータベースです。 代わりに、キー値、ドキュメント、コラム、グラフなど、さまざまなモデルを使用します。 Nosql データベースは、多くの場合、リレーショナル データベースよりもスケーラブルでパフォーマンスが高いため、ますます人気が高まっています。
データベース NoSQL データベースは、同じタイプのテーブルではなくドキュメントにデータを格納します。 それらは、柔軟でスケーラブルであり、変化するデータ管理のニーズに迅速に対応できることにより、現代のビジネスのニーズを満たすように設計されています。 原則として、NoSQL データベースは、純粋なドキュメント データベース、キー値ストア、ワイドカラム データベース、およびグラフ データベースです。 世界の 2000 の大企業では、NoSQL データベースを使用してミッション クリティカルなアプリケーションを強化するのが一般的になっています。 これらの 5 つの傾向は、リレーショナル データベースが処理できない 5 つの課題を浮き彫りにします。 リレーショナル データベースの主な問題は、固定データ モデルによりアジャイル開発が困難になるため、アジャイル開発がうまくサポートされないことです。 アプリケーション モデルは、NoSQL を使用してデータ モデルを定義します。
NoSQL では、データ モデリングは静的ではありません。 ドキュメント指向のデータベースは、データを格納するためのデファクト フォーマットとして JSON を使用します。 その結果、ORM フレームワークは、アプリケーションが簡素化されている間、オーバーヘッドをなくす必要がなくなりました。 SQL を JSON に拡張できる強力なクエリ言語である N1QL (ニッケルと発音) は、Couchbase Server 4.0 によってリリースされました。 標準の SELECT / FROM / WHERE ステートメントをサポートするだけでなく、集計 (GROUP BY)、並べ替え (SORT BY)、結合 (LEFT OUTER / INNER) などの関数もサポートできます。 スケールアウト アーキテクチャで構築され、単一障害点がない NoSQL 分散データベースには、多くの運用上の利点があります。 モバイル アプリや Web アプリを介した顧客とのやり取りが増加しているため、可用性が問題になっています。
NoSQL データベースは、インストール、構成、スケーリングが簡単です。 それらは、書き言葉と話し言葉のすべての範囲にアクセスできるように設計されています。 これらのシステムは、大規模または小規模で使用でき、さまざまなサイズのクラスターを管理および監視できます。 データは、分散型の NoSQL データベース内のデータ センター間で複製されるため、個別のソフトウェアは必要ありません。 ハードウェア ルーターは、データベースが問題を発見するのを待たずにアプリケーションがデータベース障害に対応できるようにするだけでなく、ハードウェア ベースの即時フェールオーバーを可能にします。 NoSQLデータベース テクノロジの使用は、今日の Web、モバイル、モノのインターネット (IoT) アプリケーションでますます一般的になっています。
RavenDB は、顧客データや製品データなど、大量の非構造化データを格納できるため、多くのエンタープライズ アプリケーションに最適です。 さらに、大量のデータを迅速かつ簡単に処理する必要があるアプリケーションにも適しています。 さらに、RavenDB には、データ管理のための優れたツールとなる多数の機能が付属しています。
RavenDB は、単一のデータベースでリレーショナル データベースのすべての利点を提供する素晴らしい NoSQL ドキュメント データベースです。
Nosql データベース: 大容量データ、低レイテンシ、柔軟なデータ モデルの利点
大量のデータ、低レイテンシ、およびさまざまな方法でデータをモデル化する機能を必要とするアプリケーションは、NoSQL データベースの恩恵を受けます。 NoSQL データベースは、純粋なドキュメント データベース、キー値ストア、幅の広い列のデータベース、またはグラフ データベースに基づくデータベースです。 これらのデータベースでは、さまざまなデータ モデルを使用して、さまざまな方法でデータにアクセスして管理できます。 このような大規模データベースは、大量のデータ、短い待機時間、および柔軟なデータ モデルを備えたアプリケーション向けに特別に設計されています。
SqlからNosqlへのオンラインコンバーター
SQL を NoSQL に変換する方法は多数ありますが、最も一般的なのはオンライン コンバーターを使用する方法です。 このサービスを提供する Web サイトは多数ありますが、通常は簡単なプロセスです。 SQL ファイルをアップロードするだけで、あとはコンバーターが処理します。
Microsoft SQL Server データベースから Couchbase Server データベースへの変換を自動化するプロジェクトです。 データベース間を移動することは、開始前に言語間の翻訳を行うことによく似ていることに留意することが重要です。 その道とは、リスク、努力、報酬を伴うものであり、複数の選択肢があるものです。 Couchbase を使用する場合、テーブルは厳密に適用されますが (そのため「リレーショナル」データベースという用語が使われます)、コレクションのようなものはありません。 スコープを作成し、スキーマを無視し、スコープを作成するための引数としてデフォルトのスコープ (MySQL の dbo とほぼ同等) を使用します。 SqlServerToCouchbase ユーティリティは、見つかったテーブルごとにコレクションを生成します。 SQL Server のテーブル名は、Couchbase Server よりもはるかに長くなる可能性があります。
N1QL クエリはドキュメント キーを使用しないため、クエリ タイプに応じてさまざまなインデックスを利用できます。 ただし、これはレベル 5 の変換であるため、開始するには十分なはずです。 最新バージョンの Couchbase Server では、インデクサーを使用して、必要なクエリに対して N1QL インデックスを推奨できます。 同等のフル テーブル スキャン (プライマリ インデックスなど) は、デフォルトでは Couchbase Server ではサポートされていません。 SqlServerToCourier ユーティリティを使用すると、各テーブルからすべての行を取得し、コレクションごとに JSON ドキュメントに書き込むことができます。 Couchbase Server 7 のベータ版がダウンロードおよびテストできるようになりました。 変換ユーティリティを使用すると、SQL Server データベースの Couchbase Server 変換を行うことができます。 ただし、現時点では、クライアント コードを変換することはできません。 これは、移行するデータベース (SQL Server または別のデータベース) に関係なく、解決が難しい問題です。
Mongodb で 2 つのドキュメントを結合する方法
MongoDB で 2 つのドキュメントを結合する場合は、同じ方法で結合する必要があります。 1つ目の文書に結合したい分野を入力することで、2つ目の文書に結合したい分野を入力することができます。
2 番目のドキュメントで、結合するフィールドを見つけて、最初のドキュメントでそのフィールドに移動します。
$lookup(Aggregation) 関数を作成し、それを使用して複数のフィールドを一度に結合します。
フィールドを結合すると、結果フィールドにデータが表示されます。
$where 関数を使用して、データをフィルター処理できます。
リレーショナル データベースを Mongodb に変換する
MySQL、Oracle、Microsoft SQL Server などのリレーショナル データベースは、データを格納および取得するための強力なツールです。 しかし、町で唯一のゲームではありません。 MongoDB は、その柔軟性とスケーラビリティで人気を集めている強力なドキュメント指向データベースです。
リレーショナル データベースを MongoDB に変換することを検討している場合は、留意すべき点がいくつかあります。 まず、MongoDB はリレーショナル データベースとは異なるデータ モデルを使用します。 MongoDB では、データは JSON に似たドキュメントとして表され、入れ子にすることができ、さまざまなデータ型を持つことができます。 これにより、データを構造化する方法に大きな柔軟性がもたらされます。
次に、MongoDB は分散データベースです。つまり、複数のサーバーに分散できるということです。 これにより、データの増加に合わせてデータベースを簡単に拡張できます。
最後に、MongoDB には、データのグループ化や集計などを実行できる強力なクエリおよび集計機能があります。 これは、データ分析に非常に役立ちます。
リレーショナル データベースを MongoDB に変換することを検討している場合は、次の点に注意してください。 MongoDB は、データを格納および取得するための強力なツールになる可能性がありますが、MongoDB とリレーショナル データベースの違いを理解することが重要です。
MongoDB とリレーショナル データベースの間でデータベースをマップするために、MongoDB は SQL をそれにインポートします。 近年、NoSQL データベースの人気が高まっています。 データを JSON 形式で格納する NoSQL データベースであるオープン ソースの MongoDB は、ドキュメント指向の NoSQL データベースの優れた例です。 この記事を読むことで、RDBMS/SQL ドメイン、その機能、用語、MongoDB データベースへのクエリ言語のマッピングについて理解を深めることができます。 MongoDB では、実行可能な動的ドキュメントを作成できます。 コレクション内の各ドキュメントは、異なるスキーマを持つ場合があります。 フィールドは int 型と配列型を同時に保持でき、配列は次のインスタンスで格納できます。
動的スキーマを採用しているため、NosSQL データベースは非常に高いスケーラビリティ ファクターを備えています。 リレーショナル データベースは、プライマリ キー id と contact_id を使用して、user と contact の 2 つの部分に分割できます。これらは両方とも user テーブルと contact テーブルにあります。 通常、MongoDB は auto generated_id フィールドを主キーとして使用してドキュメントを識別します。 リンク ドキュメントと埋め込みドキュメントを使用して、そのような関係を設計する方法を示します。 この記事では、コレクション (またはテーブル) の作成と編集、ドキュメント (または行) の挿入、読み取り、更新、および削除に関連するプロセスについて説明します。 MongoDB では、コレクション構造を明示的に作成する必要はありません (CREATE TABLE クエリを介してテーブル構造にあるように)。 コレクションに最初の挿入が行われると、ドキュメント構造が自動的に変更されます。
MongoDB がクエリ データを更新すると、1 つのドキュメント (およびそれに一致するテキスト) のみが更新されます。 $or 演算子は、論理 OR を find メソッドの基準に接続するために使用されます。 例として、降順で、フィールドの値として -1 を使用します。 たとえば、次のステートメントでは、最初の 5 つをスキップして 10 件の投稿が行われます。 ドキュメントの削除は簡単で、SQL と非常によく似ています。 各 MongoDB コレクションには、_id フィールドを入力してカスタマイズできるインデックスが含まれています。 ensureIndex メソッドを使用して、フィールドの新しいインデックスを作成します。 さらに、一部のオンライン ツールは、SQL クエリを MongoDB クエリに変換するのに役立ちます。