
NoSQL データベースと不均一なデータ
公開: 2023-03-03NoSQL の Non Uniform Data は、データベースのスキーマと一致しないデータです。 これは、データが整形式でない場合、正規化されていない場合、またはデータベースのルールに従って有効でない場合に発生する可能性があります。 NoSQL の不均一なデータは、データベースのパフォーマンスに問題を引き起こす可能性があり、データの損失も引き起こす可能性があります。
非リレーショナル Nosql データベースとは?
非リレーショナル データベースは、標準データベースにある表形式のスキーマに依存しないデータベースです。 一方、非リレーショナル データベースは、保存されるデータの種類の特定のニーズに合わせて調整されたストレージ モデルを使用します。
クラウド用に設計されたデータベース ソフトウェアは、従来のリレーショナル データベースよりも優れたスケール、パフォーマンス、データ モデルの柔軟性などの利点を提供します。 NoSQL などのデータベース テクノロジは、非常に柔軟で使いやすく、テーブル ベースのアプローチに限定されないように作成されています。 構造化および非構造化を問わず、すべてのデータ タイプを簡単に処理でき、スケールアップして費用対効果の高い方法で保存できます。 カスタマー エクスペリエンスをパーソナライズするシステムの構築に関しては、NoSQL データベースが最も一般的な選択肢です。 NoSQL データベースとリレーショナル データベースの主な違いの 1 つは、そのスケーラビリティです。 NoSQL データベースに加えて、データと目的に最適なものを選択するオプションがあります。 グラフ データベースは、グラフ メタファを使用してデータ関係を接続するデータ ストアです。
マルチモデル データベースは、NoSQL 市場と RDBMS 市場の両方で人気を集めています。 NoSQL データベースは、クラウド アプリケーションをターゲットとする分散型システムをサポートするように設計されています。 ほとんどの場合、NoSQL データベースには、他のデータベース管理システムに比べて次の利点があります。 定義済みのスキーマは必要ありません。 その場でデータのタイプとフィールドを変更できます。 NoSQL データベースを使用すると、データのコピーを複数のサーバーに複製することで、データが常に利用可能になります。 プライマリ/セカンダリとピアツーピアの 2 つの方法で NoSQL データベースを複製するために使用されます。 キー値、ドキュメント、表形式、およびグラフ モデルなどの各 NoSQL データ モデルの API は、独自のものです。
RDBMS はデータの読み取り、書き込み、および配布用に設計されていますが、NoSQL データベースはデータの読み取り、書き込み、および配布用に設計されています。 たとえば、MongoDB は、Cassandra などの NoSQL クラスター内のすべてのノードで書き込みと読み取りをサポートします。 分散システム アーキテクチャや SQL などの NoSQL の原則の多くは、現在、新しい SQL データベースで使用されています。
NoSQL データベースは、より多くのユーザーに対応するために垂直方向にスケーリングすることもできます。 レプリケーションとフォールト トレランス メカニズムは、スケーラビリティを実現するための 2 つの重要な方法です。 その結果、停止が発生する可能性を減らすために、データを複数のサーバーに保存できます。
需要の高い NoSQL データベースも利用できます。 故障率が低く、高負荷に耐えることができます。 レイテンシとスループットが低いため、高いスループット要件を持つアプリケーションに最適です。
非リレーショナル データベースの利点
リレーショナル データベース システムを使用しないことの利点は何ですか?
リレーショナル データベースではなく非リレーショナル データベースを使用することには、多くの利点があります。 非リレーショナル データベースは、迅速なアプリケーション開発に最適です。 データを保存する方がより便利です。これらは実行速度が速く、高速であることが多いからです。 ただし、それらはより適応性が高く、迅速に処理できるため、問題なく管理できます。
Nosqlのデータ型とは?
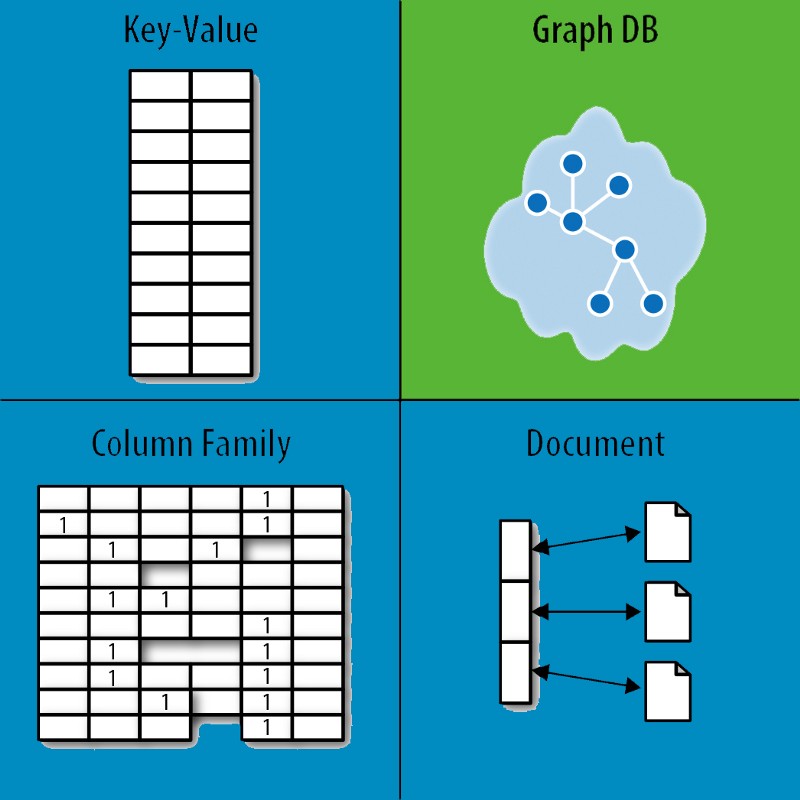
NoSQL システムは、従来の SQL データベースに代わるものとして定義されています。 SQL データベースと NoSQL データベースは非常に異なるデータベースです。 彼らは、リレーショナル データベース管理システム (RDBMS) で使用される従来の行と列のテーブル モデルとは異なる方法でデータ モデルを作成しました。
NoSQL データベースは、キー値ストア、ドキュメント ストア、列指向データベース、グラフ データベースの 4 つのタイプで構成されています。 リレーショナル データベースは、どのような種類のソリューションでも問題を解決できません。 たとえば、OrientDB は、NoSQL とマルチモデル タイプを組み合わせたデータベースです。 大規模なリレーショナル データベースには、多数のエンティティ タイプとテーブル リンク オプションがあります。 すべてのエンティティ (人) は、複数の列にまたがる行に表示されます。 列は列データベースに個別に格納されるため、関連する列が少ない場合でも簡単に検索できます。 インデックスは行と列をデータにプロットしますが、列データベースは行と列をデータにプロットします。
キー値ストアは、NoSQL データベースとは対照的に、最も複雑ではありません。 クエリや計算が簡単な方法で日常のドキュメントを保存でき、ドキュメントをそのまま保存できます。 データが正しく構造化されている限り、ドキュメント ストアにとって正規化は重要ではありません。 グラフィカル データベースの目的は、エンティティ間の関係を簡単に追跡できるようにすることです。 グラフ データベースは、データと構造という 2 つの主要なコンポーネントで構成されています。 エンティティ全体。 エッジは、線で表される 2 つのエンティティのプロパティです。 ドキュメント ストアとキー バリュー ストアは BASE に準拠していますが、Neo4j などのグラフ データベースは ACID を支持すると主張しています。
Json による柔軟なデータ ストレージ
JSON ドキュメントは柔軟で使いやすいため、NoSQL データベースで一般的なデータ型です。 JSON は、行と列ではなく行と列に格納されることを除いて、スプレッドシートに似たタイプのデータ ストレージです。 これは、特定の整理手順を必要としない半構造化データの保存に最適です。
Nosql は非構造化データですか、それとも半構造化データですか?
通常、NoSQL データベースは、半構造化データ、完全非構造化データ、ドキュメント、グラフ、または動的スキーマの処理に適しています。 従来の RDBMS は高度に構造化されたデータを処理できますが、NoSQL データベースは通常、半構造化レベルまたは完全構造化レベルで処理します。
スプレッドシートからテキスト、ビデオ、オーディオ ファイルに至るまで、さまざまな種類のデータがあります。 構造化データは、特定の方法でストレージに格納できるように事前定義されたデータのタイプです。 事前定義されたデータ モデルが含まれていないため、非構造化データはリレーショナル データベースに格納されません。 非構造化データという用語は、構造化されていないが、ユーザーが部分構造または階層構造を識別できるメタデータを含む非構造化データを指します。 機械学習や人工知能を使用する科学者やエンジニアは、効率的で奥深い技術を使用して、この種のデータから意味を抽出します。 半構造化データ ファイルには、同じ形式の電子メールやその他のドキュメントが含まれますが、ユーザーが特定のレベルで情報にアクセスできるようにするメタデータが含まれています。 この記事では、データの種類ごとに実際の例をいくつか見て、現代の組織における主な用途について説明します。

通常、構造化データはデータベースに格納され、データ ウェアハウスも含まれます。 特定の属性に従う必要がある定義済みのスキーマがないため、非構造化データは Data Lakes データベースまたは非リレーショナル データベースに格納されます。 MongoDB などの最新の NoSQL データベースは、何らかの方法で半構造化データ (構造または階層を含む) を格納するために使用されます。
このタイプのデータベースは、より迅速な開発やより柔軟なデータ モデルなどの利点を提供するため、一般的な選択肢となっています。 主要なNoSQL ソリューションであるMongoDB は、非構造化データのアーカイブに特に優れています。 その結果、そのドキュメント データ モデルは、関連するすべてのデータを 1 つのドキュメントに格納します。これは、厳格なリレーショナル データベース モデルよりもはるかに柔軟です。 その結果、MongoDB は非構造化データおよび半構造化データに最適です。
半構造化データの多くの利点
半構造化データは、その名前が示すように、構造、量、構成のいずれのカテゴリにもうまく適合しません。 この 2 種類のデータは、混在して一致していると見なすことができます。 格納できる半構造化データのタイプは、JSON、XML、およびテキストです。
Nosql データベース
NoSQL データベースは、従来のリレーショナル データベースよりも緩やかな整合性モデルを使用する、データの保存と取得のメカニズムを提供します。 多くの場合、NoSQL データベースはよりスケーラブルで、より優れたパフォーマンスを提供します。
従来のデータベースとは対照的に、NoSQL データベースはより柔軟です。 NoSQL データベースは、ドキュメントなどの他の種類のデータベースと同じデータ構造にデータを格納します。 非リレーショナル データベースは、その関係性のレベルが低いため、大規模で通常は構造化されていないデータ セットを管理するために使用できます。 データベース NoSQL システムは、テーブルの接続を必要としません。 NoSQL データベースを使用すると、さまざまなデータ構造を保存できるため、データ分析、ソーシャル ネットワーク、モバイル アプリで役立ちます。 各タイプのデータベースにはいくつかの利点がありますが、NoSQL およびリレーショナル データベースは企業によって多数使用されています。 ドキュメント データベースにはデータがドキュメントとして含まれており、アプリケーションでの使用時に相互に同期が保たれます。
ドキュメント データベースは、コンテンツ管理システムやユーザー プロファイルで頻繁に使用されます。 情報は大規模なデータベースの列に格納されるため、ユーザーは特定の列に簡単にアクセスできます。 たとえば、Apache HBase と Apache Cassandra は、このタイプのデータベースの 2 つの例です。 グラフ データベースは、グラフ要素間の接続のネットワークを管理および格納します。 データはディスクではなくメモリに格納されるため、従来のディスクベースのデータベースよりも高速にアクセスできます。 マイクロサービス ベースのアプリケーションを使用すると、複数のアプリケーションにまたがる単一の共有データ ストアが不要になるため、有利です。 その結果、IBM は幅広いアプリケーション向けに幅広い NoSQL および NoSQL データベースを提供できます。 IBM Data Management Platform for MongoDB Enterprise Advanced は、IBM Cloud Pak for Data Suite のコンポーネントです。 Apache CouchDB、PouchDB、およびその他の一般的な Web およびモバイル開発ライブラリはすべて、オープン ソース エコシステムの一部であるサービスによってサポートされています。
NoSQL データベースのスキーマを作成する最良の方法は何ですか? NoSQL データベースのスキーマを作成する場合、データベースのネイティブ構造を出発点として使用できます。 さらに、スキーマ エディタを使用してスキーマを作成できます。
Nosql データベース: 長所と短所
NoSQL データベースは、企業でより一般的に使用されている SQL データベースと比較されることがあります。 NoSQL データベースは、SQL が処理できる方法とは異なる方法でデータを保存するアプリケーションにも役立ちます。
たとえば、ドキュメント データベースは JSON または XML 形式でデータを格納できます。 キーと値のストアにデータを格納する場合、2 つのキーと値のペアが存在する必要があります。 幅の広い列ストアでは、データはさまざまな幅の列に格納されるため、明確に定義されていないデータや迅速なアクセスが必要なデータの格納に最適です。 グラフを表示することで異なるエンティティ間の関係を表すために、データをグラフ データベースに格納できます。
一方、SQL データベースは NoSQL データベースほど強力ではありません。 さらに、SQL データベースは非常に高価であり、限られた数のトランザクションしか処理できません。 その結果、リレーショナル データベースに格納するのが難しいことが多い非構造化データは、これらのシステムで処理される可能性が高くなります。
ただし、NoSQL データベースにはいくつかの制限があります。 SQL データベースは明確に定義されており、複数行のトランザクションに適していますが、これらのデータベースはあまり適していない可能性があります。 さらに、それらは SQL データベースよりも習得が困難です。
データ ストア
データ ストアは、コンピューターがアクセスできるデータのリポジトリです。 アプリケーションによってアクティブに使用されているデータを格納するために使用されるアクティブ データ ストアと、アプリケーションによってアクティブに使用されていないデータを格納するために使用されるパッシブ データ ストアです。 データ ストアはさらに、表形式でデータを格納するリレーショナル データ ストアと、非表形式でデータを格納する非リレーショナル データ ストアの 2 つのサブタイプに分けることができます。
データ ストアとは
データ ストアは、データがデータベースに格納されているか、1 つ以上のファイルに格納されているかに関係なく、2 つ以上のデータ ストア間に存在する接続です。 データ ストア、またはプロセスのデータ ソースになるか、データ ストアへのプロセスのステージングされたデータの結果のソースになる可能性があります。
プライマリ ストレージの重要性
これは、現在使用中のデータ、プログラム、および命令を格納するコンピューターのプライマリ ストレージです。 マザーボードのプライマリ ストレージにより、データの読み取りと書き込みを非常に高速に行うことができます。 サーバーは、ネットワーク上の複数のクライアントからデータを受信して保存するコンピューターです。 ファイルへの長期アクセス用にディスクに保存されます。 ストレージは、サーバー システムのコンポーネントとして含めることも、サーバーから分離することもできます。
一般的なグラフ データベース モデル
一般的なグラフ データベース モデルには、プロパティ グラフ モデル、リソース記述フレームワーク モデル、トリプル ストア モデルの 3 つがあります。 プロパティ グラフ モデルは最も一般的なモデルであり、Neo4j を含む多くのグラフ データベースで使用されています。 リソース記述フレームワーク モデルは、グラフ データベースにデータを格納するための標準モデルであり、AllegroGraph などのデータベースで使用されます。 トリプル ストア モデルは、Virtuoso を含む多くのグラフ データベースで使用される単純なモデルです。
Mongodb: グラフ データベース?
MongoDB はグラフ データベースです。