
NoSQL データベース: ビッグ テーブル
公開: 2023-01-04NoSQL データベースは、その柔軟性、スケーラビリティ、およびパフォーマンスにより、ますます人気が高まっています。 NoSQL データベースは事前定義されたスキーマを必要とせず、任意の形式でデータを格納できます。 これにより、常に変化する大量のデータを保存する必要があるアプリケーションに最適です。 ビッグ テーブルは、大量のデータを格納するように設計された NoSQL データベースの一種です。 Big table は、Google、Facebook、Amazon など、多くの大規模な組織で使用されています。 ビッグ テーブルはスケーラビリティが高く、数十億の行と数百万の列を処理できます。 大きなテーブルも非常に高速で、データへのリアルタイム アクセスを提供できます。
Google は、 Cloud Bigtable データベース サービスの一般公開されている一連の更新プログラムをリリースしました。 新しいアップデートの結果、ノードあたり最大 5 倍のストレージ容量が利用できるようになりました。 また、Google は、データベース クラスターをニーズに応じて自動的に拡張または縮小できるようにする、改良された自動スケーリング機能も追加しました。 新しい CPU 使用率メトリックとクラスター グループ ルーティングにより、アプリケーションのリソースがどのように使用されているかをより詳細に把握できます。 コンピューティングとストレージが分離されているため、Bigtable では各タイプのリソースを個別にスケーリングできます。 ユーザーは、新しい機能のおかげで、高可用性の展開を簡単に管理し、ワークロード管理を改善できるようになりました。
NoSQL は、大量のデータを保存するための一般的な選択肢です。 このタイプのデータベースは、今日の Web 企業の間でますます人気が高まっています。 NoSQL ソリューションの支持者は、従来のデータベースよりも単純なスケーラビリティとパフォーマンスの向上を提供すると述べています。
Bigtable は、開発者とデータベース管理者の両方が使用できるNoSQL データベース サービスの一種です。 BigQuery は、SQL 方言を使用し、Google のデータ処理技術である Dremel に基づいているため、ハイブリッドです。
Bigtable は SQL ですか、それとも Nosql ですか?
各用語をどのように定義するかによって異なるため、この質問に対する決定的な答えはありません。 ただし、構造化クエリ言語を使用するデータベースとして SQL を広く定義し、構造化クエリ言語を使用しないデータベースとして NoSQL を広く定義すると、Bigtable は NoSQL データベースと見なされます。
Bigtable と BigQuery の比較とは? Bigtable は、安全でスケーラブルな方法でデータを保存できる NoSQL データベースです。 BigQuery は、大量のデータを SQL データベースに格納するリレーショナル データ ウェアハウスです。 Bigtable は、日々の運用のために、Analytics、Finance、Personalized Search、Earth、Writely などの Google の製品に統合されています。 変更可能なデータの NoSQL データベースである Bigtable は、OLTP シナリオでうまく機能します。 BigQuery は、OLAP アプリケーションに使用できるリレーショナル SQL データ ウェアハウスです。 Bigtable と BigQuery はどちらもクラウド ネイティブであり、業界をリードするサービス レベル アグリーメントを備えています。 さらに、自動バックアップ (複製あり)、無限のスケーラビリティー、自動シャーディング、および自動障害回復 (複製あり) を提供します。
NoSQL データベースではなく、BigQuery はこれを行いません。
Bigtable とはどのタイプの Nosql データベースですか?
Cloud Bigtable は、データの分析と操作の実行に使用できる NoSQL データベースです。 これは、HDFS を使用する列指向データベース システムである HBase の代替です。 帯域幅が 10 MB 未満のアプリケーションは、高レベルのスループットとスケーラビリティをサポートできる Cloud Bigtable に適しています。
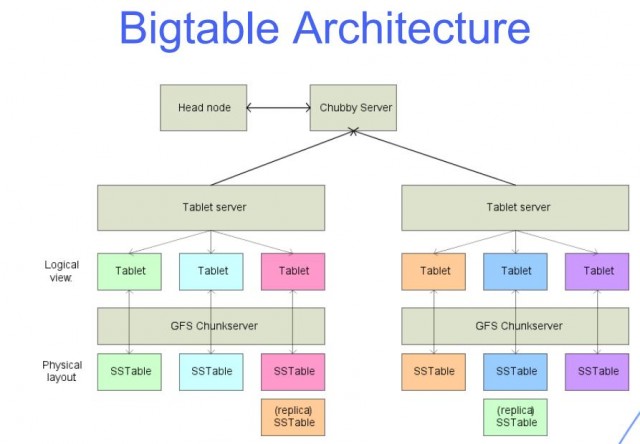
Big Table データベースは、NoSQL データベースのサブセットとして知られています。 Google のアプリケーションである Bigtable は、Kleenex に似ています。 Bigtable データベースは、模倣とインスピレーションの業界標準です。 この記事は主に Bigtable に関係していますが、他の NoSQL データベースにも注目しています。 Bigtable は、主に Google による内部使用を目的として設計されており、外部からのアクセスはありません。 Bigtable は 2004 年に Google に導入されて以来、60 以上の Google アプリケーションで使用されています。 Bigtable の実装では、他のサーバーのクラスター全体でタブレットを追跡するために 1 つのマスター サーバーが必要です。
Apache Software Foundation は、特にデータベースの分野で、数多くの優れた技術的イニシアチブに貢献してきました。 Accumulo と HBase は、Google Bigtable と同じ設計原則を採用していますが、形式は市販されています。 現在、Apache HBase は Facebook のメッセージング システムを実行しており、Hadoop と緊密に統合されているため、大規模なデータ セットを処理できます。 Hypertable データベースは、単純な表形式データベースである Bigtable に基づいています。 Hypertable は、Hadoop や HFS と同じように動作します。 中国最大の検索エンジンの 1 つである Baidu は、Hypertable の主要スポンサーの 1 つです。 顧客には、eBay、Groupon、Rediff.com などのオンライン オークション サイトのほか、Lowe's や TJ Maxx などのオフライン小売業者が含まれます。
Hadoop は、ユーザーが大量のデータを効率的に保存および処理できるようにするオープンソース ソフトウェア プラットフォームです。 これにより、NoSQL データベースが有効になり、単一サーバーに格納するために必要なデータの量を減らすことができます。 一方、NoSQL データベースはスケーラビリティ主導であるため、固定スキーマは必要ありません。 このため、大量のデータを分散して保存するための優れた選択肢です。
Bigtable はどのタイプの Nosql データストアに分類されますか?
ジェネリック市場で利用できる数少ない機能の 1 つです。 最も基本的なレベルでは、Bigtable は幅広い列にまたがる NoSQL データベースです。
Bigtable は列型データベースですか?
Bigtable や Apache Cassandra などのワイドカラム ストアは、2 つのレベルでカラム データ構造をまったく使用しないため、従来の意味でのカラムではありません。
Bigtable は非リレーショナル データベースですか?
「非リレーショナル データベース」をどのように定義するかによって異なるため、この質問に対する決定的な答えはありません。 Bigtable は列指向のデータ ストアであり、NoSQL データベースの一種と考える人もいます。 ただし、通常はリレーショナル データベースに関連付けられているトランザクションとインデックス作成はサポートされています。 つまり、非リレーショナル データベースをどのように定義するかに大きく依存します。
CREATE EXTERNAL TABLE ステートメントを使用して、データを取得するテーブルを指定することで、BigQuery にテーブルを作成できます。 uri オプションを使用して、データを取得するテーブルを指定できます。 テーブル スキーマには、テーブル名、テーブル タイプ、列名、データ型、および bigtable_options オプションのテーブル スキーマが含まれます。
MySQL を使用している場合は、BigQuery インポート ツールを使用して、MySQL テーブルから BigQuery にデータを自動的にインポートできます。 テーブル名と列ファミリーをツールに入力すると、データが BigQuery テーブルにインポートされます。
Google Cloud コンソールを使用する場合は、テーブル名と列ファミリーの修飾パラメーターを手動で入力する必要があります。 Google Cloud プラットフォームでは、MySQL、PostgreSQL、MongoDB、Redis など、さまざまなソースからデータをインポートできます。
Bigtable の主な機能
Bigtable の機能にはどのようなものがありますか?
Bigtable の読み取りと書き込みの速度、大規模なスケーラビリティ、および大量のデータを処理する能力は、その多くの機能のほんの一部です。 さらに、Bigtable は NoSQL データベースであるため、SQL クエリはサポートされていません。 これにより、別のデータベースで SQL 操作を実行する必要がなくなります。
Bigtable はデータベースですか?
Bigtable はリレーショナル データベースではありません。 これは、構造化データを管理するための分散ストレージ システムであり、非常に大きなサイズ (数千の汎用サーバーにまたがるペタバイトのデータ) に拡張できるように設計されています。 Google は Bigtable を使用して、Google アナリティクスや Google マップなどの大規模なサービスの多くを強化しています。
Cloud BigTable は独自の機能セットを提供し、100,000 を超える列と数十億の行にスケーリングできます。 約ペタバイトおよびテラバイトのデータのストレージをサポートします。 BigTable と比較して、レイテンシは非常に低く、大量のデータを保存できる可能性もあります。 BigTable は構造化データを列に格納できるため、Web サービスや企業のインターネット検索データを処理できます。 圧縮アルゴリズムは、システムの容量を増やすためにも使用されます。 BigTable には、BigTable に含まれている自己管理型の HBase インストールよりも優れた特典を提供する、影響力のあるバックエンド サーバーがあります。 BigTable の行は同じ境界線を共有しているため、ブロックとも呼ばれます。
「タブレット」と呼ばれるこれらのデバイスは、クエリのワークロードを管理するのに役立ちます。 すべてのタブレットの保存には、Google のクラウドベースのファイル システム Colossus が使用されています。 BigTable のすべての書き込み操作は、SSTable ファイルと同様に Colossus の共有ログに保存されます。 BigTable の 7 つの主要な機能は、ビジネスが成功するために不可欠です。 BigTable には、さまざまな方法で生活をパーソナライズ、高速化、自動化する可能性があります。 行と列は、BigTable のデータの 2 つの次元です。 各行には、単一の行キーを使用してアクセスできる一意の識別子またはインデックスが含まれています。
ファミリ内の各列には、修飾列があります。 行キーなどの列修飾単位を使用すると、列の識別に役立ちます。 データベースに関して言えば、BigTable はスパース データベースとして知られています。 BigTable の各タイムスタンプ バージョンは、3D マップ構造内のディメンションの 1 つであるセルで表されます。 この強力なデータベースは、パーソナライズ可能でスピードに敏感であり、モバイル Web サイトやアプリを強化するために使用できます。 過去を振り返ると、どのインタラクションが最良の結果をもたらしたかがわかります。 より多くのデータ分析を実装するのに役立ち、より良い顧客サービスにつながります.
オープンソースの NoSQL データベースである Google Cloud Bigtable は、Google のクラウドと統合されています。 非常に多くの既存のビッグデータおよび Hadoop エコシステムと互換性があるという事実は、非構造化データまたは低レイテンシーを必要とするデータに使用できることを意味します。
Bigtable: データ集約型アプリケーションに最適な選択肢
NoSQL データベース サービスである Bigtable は、大規模な分析および運用ワークロードに使用されます。 そのため、データ集約型のリアルタイム アプリケーションに最適です。 さらに、列指向であるため、データを 3 次元で格納するのに最適です。
Bigtable 対 Mongodb
Bigtable と MongoDB にはいくつかの重要な違いがあります。 まず、Bigtable は列指向のデータベースですが、MongoDB はドキュメント指向のデータベースです。 これは、Bigtable ではデータが列に保存されるのに対し、MongoDB ではデータがドキュメントに保存されることを意味します。 次に、Bigtable はセカンダリ インデックスをサポートしていませんが、MongoDB はサポートしています。 これは、Bigtable でデータを照会する場合、照会する特定の列を知っている必要があることを意味します。 MongoDB では、ドキュメント内の任意のフィールドに対してクエリを実行できます。 最後に、Bigtable は水平方向にスケーリングするように設計されていますが、MongoDB は垂直方向にスケーリングするように設計されています。 つまり、Bigtable ではクラスターにマシンを追加して容量を増やすことができ、MongoDB ではサーバーに RAM と CPU を追加して容量を増やすことができます。
Google の Cloud Bigtable: ビッグデータだけではない
Bigtable は 2007 年に作成され、今でも Google のインフラストラクチャのコンポーネントです。Cloud Bigtable は低レイテンシで大量のデータを格納するのに理想的ですが、頻繁にアクセスする必要のないデータには理想的ではありません。 たとえば、Cloud Bigtable はデータレイクには適していません。
Bigtable データベース
bigtable データベースは、 bigtable データ構造を使用するデータベースです。 bigtable は、非常に大きなサイズにスケーリングするように設計された、構造化データ用の分散ストレージ システムです。
大規模なテーブルとは、多くの行と列を持ち、通常はデータがまばらに存在するテーブルです。 Bigtable は、レイテンシが低く、密度が高いため、大規模なデータ セットに最適です。 このデータ ソースは、低レイテンシで高い読み取り/書き込みスループットをサポートし、大規模なデータ セットに最適であるため、MapReduce 操作に最適です。 Bigtable テーブルのデータは、クエリの負荷を軽減するために、それぞれがタブレットと呼ばれる連続する行のブロックに分割されます。 SSTable 形式は、同社のファイル システムである Colossus に Google タブレットを保存するために使用されます。 各タブレットは、ノードとも呼ばれる Bigtable インスタンス内の特定のノードにリンクされています。 クラスターにノードを追加すると、複数の同時要求を処理するためのクラスターの容量を増やすことができます。
各行には、列ファミリー、列識別子、およびタイムスタンプの組み合わせが含まれ、基本的にはキー/値エントリの配列です。 ほとんどの場合、Bigtable はすべてのデータを生のバイト文字列に変換します。 Bigtable は連続してミューテーションを保存し、数か月に 1 回だけ圧縮するため、ミューテーションが行に変更されると、より多くのストレージ スペースが必要になります。 Bigtable は、インテリジェントなアルゴリズムを使用してデータを圧縮し、圧縮技術を採用しています。 削除は特殊なタイプの突然変異であるため、短期的には余分なストレージ容量が必要になります。 Google 独自のストレージ方式により、標準の 3 方向 HDFS レプリケーションの範囲を超えたデータの時間の試練に耐えることができます。 ユーザーは、Google Cloud プロジェクトと Identity and Access Management (IAM) によって割り当てられた役割を使用して、Bigtable テーブルにアクセスできます。 Google Cloud データの大部分は、暗号化されたデータで使用するのと同じ強化された鍵管理システムを使用して保存時に暗号化されます。 バックアップを使用して、テーブルのスキーマとデータのコピーを保存したり、後でバックアップを新しいテーブルに復元したりできます。
Bigtable は、最大ペタバイトのデータを格納できる、適切に設計された分散ストレージ システムです。 使い方が簡単なため、大規模なデータ ストレージに最適です。

クラウド Bigtable のパワー
Cloud Bigtable データベースには、数万の行と列を保持する容量があり、世界中のどこからでもアクセスできます。 そのため、大規模なデータ ストレージに適しています。 Cloud Bigtable は、2015 年 5 月 6 日の時点で Google Cloud で利用できるようになりました。これにより、10 エクサバイトを超えるデータが提供され、1 秒あたり 50 億を超えるリクエストが処理されるようになりました。 その結果、Cloud Bigtable は現在も使用されており、データ ストレージの貴重なツールとなっています。
Bigtable 対 Cassandra
各ノードは、独自の方法を使用して読み取りおよび書き込み操作用に選択されます。 Cassandra ではパーティション キーが識別されますが、Bigtable では行キーが使用されます。 Cassandra の負荷分散ポリシーは、最初にクライアントによって検査されます。
Bigtable や Cassandra などのデータベース システムが分散されています。 1 秒あたり数万のクエリ (QPS) を処理できる多次元のキー値ストアを作成します。 このドキュメントの目的は、2 つのデータベース システムの相違点と類似点を説明することです。 Bigtable には、Bigtable で説明されている主な機能の多くが含まれています。 この論文では、構造化データの分散ストレージ システムについて説明します。 Bigtable がデータセットに必要な範囲割り当てを特定すると、ストレージ レイヤーが処理レイヤーから分離されているため、処理ノードのデータ範囲は簡単に変更できます。 さらに、Bigtable では、最大 4 つのトポロジで地理的に分散したクラスター間で非同期レプリケーションを行うことができます。
Cassandra によってフォールト トレランスが提供されます。これは、一貫性のレベルに関連付けられています。 構成可能なデータ レプリケーション トポロジ戦略を使用して、地理的レプリケーションを定義できます。 ほとんどのマルチデータセンター トポロジでは、QUORUM (または LOCAL_QUORUM) がデフォルト設定です。 このレベル設定が成功したと見なされるためには、コーディネーター ノードへのレプリカ ノードの過半数の応答が必要です。 Cassandra のデータ レプリカは、データ センターとラックの構成を使用することで、フォールト トレランスの点で改善できます。 トポロジは、読み取りおよび書き込み操作中に一貫性を保証するために必要なノードを決定します。 Bigtable インスタンスは、1 つ以上のクラスターを持つことができます。または、最大 4 つの複製されたクラスターのコレクションを持つことができます。
Bigtable と Cassandra はどちらも NoSQL ワイドカラム ストアとして機能します。 行キーは、テーブルのグローバル データ ソートが Bigtable に表示される順序を決定します。 Bigtable では、ノードは、一般にタブレットと呼ばれるキー範囲の責任のバランスをとるために使用されます。 Bigtable サービスは、クライアントが送信する列のデータ型を強制しません。 Bigtable 列ファミリーは、テーブル内のどの列を保存し、次から次へと取得するかを選択します。 各テーブルには少なくとも 1 つの列ファミリーが必要ですが、多くの場合、テーブルにはそれ以上の列ファミリーが含まれます (テーブルが持つことができる列の最大数は 100 です)。 行キーは一方のセルに配置され、列名はもう一方のセルに配置されます。
Cassandra と Bigtable は、異なる方法を使用して、読み取り操作と書き込み操作の両方の処理ノードを選択します。 Cassandra ではパーティション キーが区別されますが、Bigtable では行キーが使用されます。 マルチクラスタ ポリシーを作成することにより、データ センターを認識する負荷分散ポリシーにより、フェールオーバーの利点が得られます。 どちらのデータベースも高速書き込み用に最適化されており、同様のプロセスを使用して書き込みます。 どちらのデータベースも、不変ファイルである SSTable ファイルにデータを格納します。 Cassandra では、書き込みが完了したことをコーディネーターがクライアントに通知する前に、いくつかのレプリカに接続する必要があります。 Bigtable の各行キーは 1 つのノードにのみ割り当てられるため、書き込みが成功したことを確認するには、そのノードからの応答が必要です。
SSTable のマージの結果、両方のデータベースでセルを除外できます。 Cassandra にデータを返す場合、CQL クエリの WHERE 句によって行数が制限されます。 Bigtable を使用する場合、キー範囲を担当するノードのみを参照する必要があります。 ノードの読み取り結果は、さまざまな方法で制限できます。 圧縮フェーズでは、Bigtable とCassandra は定期的にマージされる SSTable にデータを格納します。 Bigtable は、各セルのタイムスタンプ バージョンの数を制限しませんが、他の行サイズの場合があります。 Colossus が提供するレプリケーションは、高いデータ耐久性を保証します。
Bigtable のコマンドライン インターフェースと、さまざまな一般的なプログラミング言語用のクライアント ライブラリは、Cassandra の機能を補完します。 Bigtable の各ノードは、それらのテーブルに格納されたデータを含む一連の SSTable を提供する必要があります。 クラスタのサイズを決定するときに、Cassandra で行うように、Bigtable でストレージ レプリカを計算する必要がなくなりました。 Bigtable インスタンスは通常、ソリッド ステート ドライブ (SSD) またはハード ドライブ (HDD) にデータを保存します。 フォールト トレランスを実現するためにストレージ密度が失われないという理論に基づく Cassandra とは対照的に、ワークロードは密度を失いません。 ワークロードの要件を満たすために必要に応じて Bigtable インスタンスを簡単にスケールアップまたはスケールダウンし、最小限の労力とダウンタイムを維持します。 インスタンスは 4 つのクラスターしか持つことができませんが、地球上でサポートされている任意のクラウド リージョンでクラスター化できます。
ノードあたりの QPS のメトリクスを作成するには、代表的なデータとクエリで Bigtable のパフォーマンスを使用することをお勧めします。 Bigtable には、共通の Cassandra 管理機能用のマネージド コンポーネントが含まれています。 クラスタの一部であるテーブルは、bigtable バックアップ内のテーブルの復元可能なコピーとして作成されます。 バックアップの価格は Cloud Storage の価格よりも低いか、ノード リソースを消費しません。 もう 1 つのオプションは、Cloud Storage へのマネージド データ エクスポートを使用して Bigtable をバックアップすることです。 Bigtable は、OS のパッチ適用、ノードの復旧、ノードの修復、ストレージ圧縮の監視、SSL 証明書のローテーションなど、Cassandra の一般的な内部メンテナンス タスクを簡単に管理します。 ダッシュボードは、Bigtable の Google Cloud コンソール ページで、インスタンス、クラスタ、テーブル レベルでスループットと使用率の指標を追跡するために事前に作成されています。 監視ダッシュボードを使用して、高度なパフォーマンス チューニングを実行できます。
SQL は、NoSQL データベース内のデータへの行キー アクセスと同様に、Bigtable で使用されます。 ノードはネットワーク全体に分散され、ネットワークの一貫性を維持するためにゴシップが使用されます。 このシステムにより、データ ストレージ容量が増加し、単一障害点なしで可用性が維持されます。
一方、Bigtable はよりスケーラブルで、Cassandra よりも高いレベルの可用性を提供します。 また、Bigtable は他のプログラミング言語よりもユーザー フレンドリーであるため、リソースの少ないデータ セットに最適です。
Google はまだ Bigtable を使用していますか?
Google アナリティクス、ウェブ インデックス作成、MapReduce、および Google マップ、Google ブックス、検索履歴、Google Earth、Blogger.com、Google コード ホスティングなどの他の多くの Google アプリケーションは、Bigtable、Google マップに保存されたデータの生成と変更に使用します。 、Google ブックス、マイサーチ
Google は Cassandra を使用していますか?
DataStax Astra Cassandra as a Service トポロジは、TensorFlow オペレーティング システムを使用して Google Cloud にデプロイされ、3 つの Google Cloud ゾーンで Apache Cassandra オペレーティング システムを使用しました。
Bigtable は Hbase と同じですか?
Bigtable のタイムスタンプはマイクロ秒単位で保存されますが、HBase のタイムスタンプはミリ秒単位で保存されます。 この区別は、Bigtable 用の HBase クライアント ライブラリを使用し、逆のタイムスタンプを確認する場合に役立ちます。
Bigtable は何に適していますか?
Bigtable NoSQL データベースは、NoSQL データベースでの使用に最適な幅広い列のデータベースです。 システムは、低レイテンシ、多数の読み取りと書き込み、および大規模な高性能を提供するように最適化されています。 通常、テーブル ケースの使用は、モノのインターネット (IoT)、AdTech、FinTech など、高レイテンシを必要とする特定の規模またはスループットに限定されます。
Bigtable 対 BigQuery
bigtable と bigquery にはいくつかの重要な違いがあります。 Bigtable はスケーラブルな列指向のデータベースになるように設計されていますが、bigquery はスケーラブルなリレーショナル データベースになるように設計されています。 Bigtable は SQL をサポートしていませんが、bigquery はサポートしています。 Bigtable は bigquery ほど広く使用されていませんが、より多くの列と行にスケーリングできるなど、bigquery よりもいくつかの利点があります。
Google は、膨大なデータのクラウド ストレージにおいて、長年にわたって大きな進歩を遂げてきました。 Bigtable は、オブジェクト指向データベース管理 (OOPA) に基づくペタバイト規模のフルマネージド NoSQL データベース サービスです。 BigQuery は、Bigtable と Google Cloud Platform、および Google の Dremel データベース システムを使用して構築されています。 BigQuery と Bigtable には 3 つの大きな違いがあります。 Big Data as a Service (BaaS) ソリューションは、Google Cloud BigQuery が提供するソリューションです。 BigQuery は、Analytics、Finance、Personalized Search、Earth、Orkut、Writely などの Google 製品で使用されています。 BigQuery の超高速データ処理を使用すると、350 億行を数秒で処理できます。
NoSQL データベースは、データベース サービスの頭字語です。 つまり、リレーショナル データベースではありません。 キー列は複数のサイズにすることができ、キー バーは水平方向にスクロールできます。 10 メガバイトのより大きなストレージ容量を持つ個々のデータ要素は、パフォーマンスを損なう可能性があります。 構造化されていないオブジェクト (ビデオ ファイルなど) の包括的なストレージ ソリューションが必要な場合は、クラウド ストレージの方が適している可能性があります。 これは、テーブル スキャンを必要とするクエリや、大規模なデータベースを一度に調べる場合に最適です。 アップロードされたオブジェクトが BigQuery の存続期間中に変更されることは不可能であり、そのデータは常に不変です。 bigtable 内のテーブルには、キー、行、およびタイムスタンプによって並べ替えられたキー/値マップに並べ替えられたスケーラブルなデータが格納されます。
Integrate.io を使用すると、ETL とデータ統合プロセスを自動化して、データ ソースとクラウド データ ウェアハウスをリンクできます。 統合プラットフォームには、BigQuery を含む 100 を超える事前構築済みの統合と、統合プロセスの管理をこれまで以上に簡単にするドラッグ アンド ドロップ インターフェースが含まれています。 当社のデータ エキスパート チームに連絡して、状況について話し合うか、Integrate プラットフォームの 14 日間のパイロットを開始してください。
MySQLがまだ広く使用されているという事実にもかかわらず、Google BigQueryは機能の面でトップに立っています。 これは、データのインポートとエクスポート、データ分析、データ フェデレーションなど、ビジネス アプリケーションで一般的に使用される機能に特に当てはまります。 一方、MySQL は 28 個の機能しかないため、多くのビジネスのニーズを満たすことができない可能性があります。 Google BigQuery はクラウドベースであるため、インターネット接続があればどこからでもアクセスできます。 一方、MySQL はクライアント サーバー アーキテクチャで実行され、クラウドでは利用できません。
Bigquery と Bigtable の違いは何ですか?
Bigtable は、大量の読み取りと書き込み用に最適化されたワイドカラム NoSQL データベースです。 大量のリレーショナル データのエンタープライズ データ ウェアハウスである BigQuery とは対照的に、Oracle Data Warehouse は重複除外サービスとして機能します。
BigQuery は Bigtable 上に構築されていますか?
Google および Microsoft と共同で開発されたクラウドベースのクエリ サービスである Bigtable と、アドホック クエリ用の Google の Dremel システムがそれぞれすぐ後に続きました。
いつ Bigtable を使用する必要がありますか?
Bigtable は、値ごとに 10 MB 以下のデータで、キー/値データを処理する際に高いスループットとスケーラビリティを必要とするアプリケーションに最適です。 Bigtable の強みは、バッチ MapReduce 操作、ストリーム処理/分析、および機械学習にあります。
スケーラブルな Nosql データベース サービス
スケーラブルな nosql データベース サービスは、大規模なデータを処理できるデータベースの一種です。 これは、大量のデータを保存および管理するために使用できる Web ベースのサービスです。 このタイプのデータベースは、大規模なデータを処理できるようにスケーラブルになるように設計されています。
このチュートリアルでは、Node.js 環境が整っていることを前提としています。 DynamoDB ファイルを解凍する nodejs-dynamodb-sample というフォルダーを作成しました。 プロジェクトの GitHub ページは https://www.gofundme.com/adamfowleruk/nodesurvey.html です。 サンプルアプリは、DynamoDB を使用して映画データを検索および取得します。 S3 にデータを保存するには、Amazon の Identity and Access Management サービス (IAM) を使用し、AWS 上の DynamoDB にアクセスするには、Amazon の DynamoDB サービスを使用します。 Amazon の iADM サービスを使用するには、まずユーザーを登録して作成する必要があります。 映画のタイトルと年は、検索の POST/movies セクションに追加できます。
キー入力フィールドを入力して、特定の年の映画のリストを作成します。 この基本的な例に従って、独自のアプリケーションを作成できるようになりました。 テーブルを再度使用する場合は、使用が終了したら削除する必要があります。これにより、AWS のホスティングとサービスのコストが発生します。 AWS では、DynamoDB コンソールに移動し、使用したストレージの量を入力します。 [映画] をクリックしてテーブル内の項目を表示し、アプリケーションに表示される指標を確認し、[容量] タブをクリックして月額料金の見積もりを確認できます。 私の GitHub ページには、この演習のコードのサンプルが含まれています: https://github.com/adamfowleruk/nodejs-dynamodb-sample.
Google Cloud Bigtable データベース
Google Cloud Bigtable は、高速でフルマネージドのペタバイト規模の NoSQL データベース サービスであり、大規模な分析および運用ワークロードに最適です。
Google のデータストアは、ユーザー リクエストへの迅速な応答が必要なアプリケーションに適しています。
Google の Bigtable データベースには、リレーショナル データベースはありません。 SQL クエリ、結合、および複数行のトランザクションはサポートされていません。 その結果、標準のデータベース サポートを探している場合、それは期待できません。 一方、Bigtable は大量のデータや分析を提供しません。 Bigtable の最適化された性質の一部は、その高性能な分析およびデータ処理機能によるものです。 一方、データストアは、高価値のトランザクション データをアプリケーションに提供できるように設計されています。 その結果、Datastore は、ユーザー リクエストへの迅速な応答を必要とするアプリケーションにより適しています。