
NoSQL データベース: 高トラフィックおよび大規模データ セット向けの Web スケール データベース
公開: 2022-11-18Nosql データベースは、大量のトラフィックと大規模なデータ セットを処理できる Web スケール データベースです。 スケーラブルで高負荷を処理できるように設計されています。 システムにサーバーを追加することで、nosql データベースを水平方向にスケーリングできます。 これにより、システムはより多くのトラフィックを処理し、より多くのデータを保存できます。
複雑なアプリケーションに対する需要の高まりにより、より高い柔軟性が必要になっています。 スケーリングが容易で効率的に実行できるデータ ストアを選択することも同様に重要です。 最も重要な問題は、「ASL」データベースと「NoSQL」データベースのどちらがアプリケーションの実行に適しているかということです。 SQL データベースはかなり長い間使用されてきましたが、NoSQL データベースは拡張が容易であることが知られています。 NoSQL データベースの場合、すべての操作でシャーディングを実行する必要があると想定されています。 ノードは、データベース内のすべてのデータ操作で期待される修飾関数によって識別できます。 データは複数のマシンに保存されるため、最も基本的なマシンでもデータ操作を処理するのは非常に効率的です。
この機能により、単純な汎用マシンを使用して NoSQL ストアをスケーリングできます。 NoSQL は、ユーザーがデータを計画および構造化して、特定の操作に対して特定の時点で同じノードからのみデータを取得できることを前提としています。 さらに、ノード間のデータの非正規化 (起動用に事前に調理されたデータ) を実行できます。 NoSQL 結合の場所はありますが、SQL リッチまたは最適化されているとは思わないでください。 実際には、データは常に NoSQL アプリケーションと一貫性があると想定されています。 一貫性が重要な場合、時間の経過とともに一貫性を変更するためのスイッチを提供する多数の NoSQL システムがあります。 ユース ケースを評価するという目標と同様に、アーキテクチャに関する決定の目標は、適切なデータ ストアを選択することです。
リソースの水平スケーリング プールはマシンを追加することで拡張できますが、垂直スケーリング プールはマシンを追加することで拡張できます。
SQL データベースと NoSQL データベースは、データの格納方法 (関連するテーブルと関連のないコレクション) のために垂直方向のスケーリングを使用しますが、NoSQL データベースは関連するテーブルを使用しないため、水平方向のスケーリングを使用します。
NoSQL でサポートされているスケーリングのタイプは水平方向です。
水平方向にスケーリングするために、MongoDB は複数のサーバー間でデータを移動できる組み込みメカニズムを採用しています。 このプロセスはシャーディングと呼ばれ、Atlas UI の構成ページのトグル ボタンを押すことで実行できます。 それとは別に、プロセスはダウンタイムなしで完了することもできます。
Nosqlで水平スケーリングはどのように機能しますか?
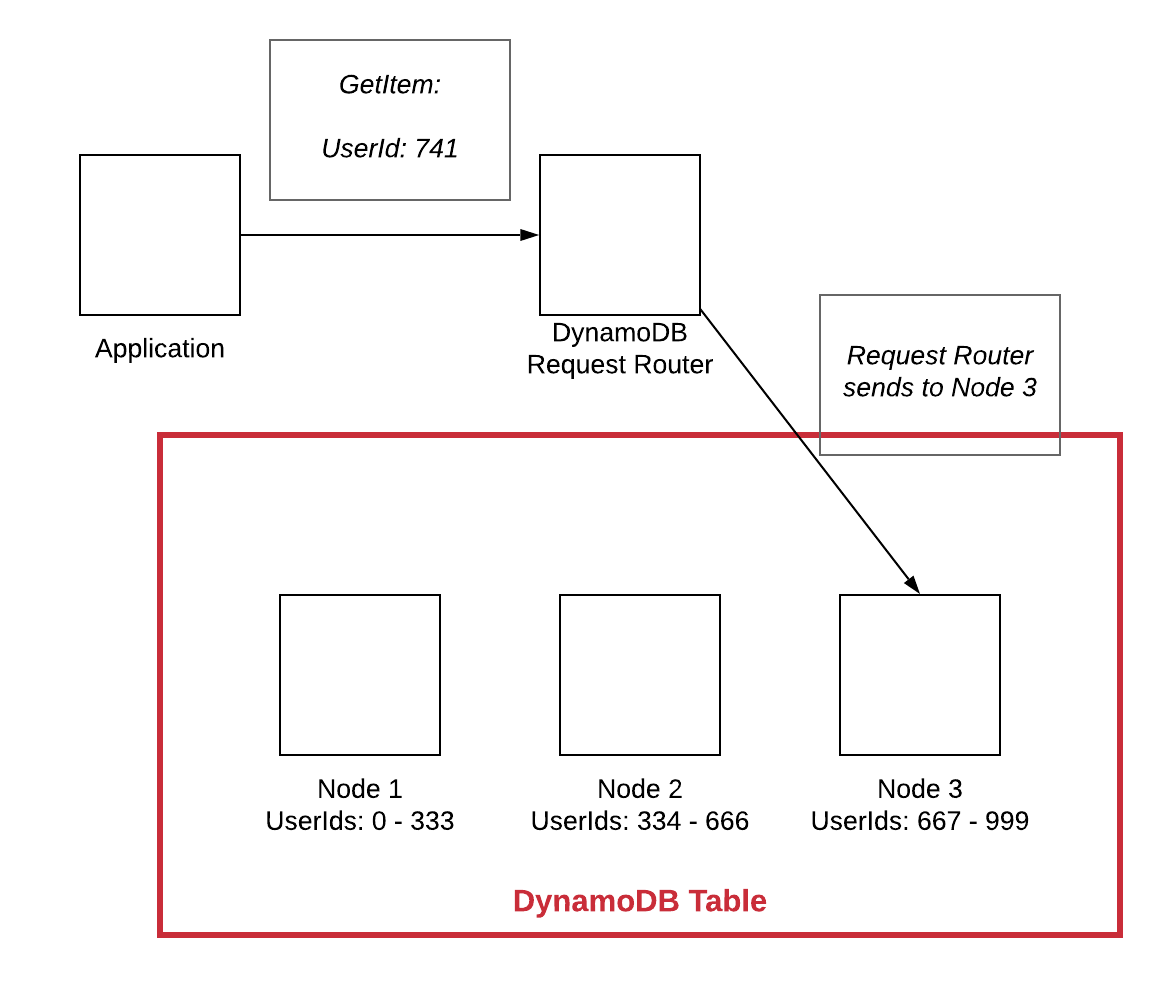
NoSQL データベースでの水平スケーリングとは、単一のマシンを高速化または強化するのではなく、システムにマシンを追加することでデータベースをスケーリングできることを意味します。 これにより、システムはパフォーマンスの問題に遭遇することなく、より多くのトラフィックとデータを処理できます。
水平方向のスケーリングには多くの利点があります。増加したトラフィックを処理するためにサーバーを簡単に追加でき、複数のサーバーから同時に行をロードすることを心配する必要はありません。 その結果、NoSQL データベースは、データ ストレージの費用を節約しながらオンデマンドでデータを保存したい企業にとって優れた選択肢となります。
Nosql データベースは大規模なデータ セットの処理に適しています
リレーショナル データベースの制限により、大規模なデータ セットを処理できません。 MongoDB などの NoSQL データベースは、データを自己完結型のドキュメント形式で保存するため、データを複数のノードに分散できます。 この機能により、データベースは大規模なデータセットを迅速かつ簡単に処理できます。
Mongodb はどのように水平方向にスケーリングできますか?
MongoDB は、シャーディングを使用して水平方向にスケーリングできます。 シャーディングは、データを複数のサーバーに分割するプロセスです。 各サーバーにはデータ セットの独自の部分があり、データはサーバー間で均等に分散されます。 リクエストが行われると、MongoDB サーバーは、リクエストされているデータを持っているサーバーを特定し、そのサーバーからデータを取得します。 このプロセスにより、MongoDB は水平方向にスケーリングし、大量のデータを処理できます。
インフラストラクチャのスケーリングに関しては、多くの企業が苦労していることに気付きます。 サービスとしてのMongoDB データベースプラットフォームは、幅広いスケーリング オプションをサポートし、そのバックエンドに組み込まれています。 水平方向にスケーリングする手法は、シャーディングとして知られています (好まれるため)。 「階層型スケーリング」という用語は、単一のサーバーまたはクラスターが上方向にスケーリングする能力を指します。 これは、複数のノードにデータを分散する水平方向のスケーリング方法です。 MongoDB Atlas プラットフォームはシャード キーを自動的に構成しますが、これは私たち次第です。 レプリカ セットとシャーディングが類似していることは明らかですが、データセットは同じではありません。
さらに、アプリケーションの大量の書き込みトランザクションで問題が発生する可能性があります。 MongoDB Atlas は、水平方向と垂直方向のスケーリングもサポートしています。 シャード クラスターをデプロイすると、水平方向のスケーリングが可能になります。 簡単に言えば、垂直方向のスケーリングは、クラスター層を構成するのと同じくらい簡単です。 完全なシャットダウンの場合、クラスターを一時停止してクラスターを 0 に維持し、ストレージを除くクラスター全体を効果的に 0 にスケーリングできます。
MongoDB は、大規模なデータセットを処理するために水平方向にスケーリングする必要がある最新のアプリケーションと同様に、優れた NoSQL データベースです。 MongoDB には、開発者がデータに簡単にアクセスして操作できるようにするシンプルな API があり、そのスキーマフリー ストレージにより、データの保存と取得が簡単になります。 さらに、MongoDB はレプリケーションをサポートしているため、複数のサーバー間でデータを簡単にレプリケートでき、将来の使用に備えて引き続き使用できるようになります。
Mongodb のスケーラビリティ
MongoDB は、最も柔軟なプログラミング言語の 1 つです。 MongoDB のようなドキュメント指向のデータベースでは、データは JSON のようなドキュメントに格納されます。 MongoDB プロセスは、シャーディングを使用して水平方向にスケーリングしています。 スレーブは、複数のコレクションとマシンを使用してデータベースとマシンにデータを分散するデータ分散技術です。
Sql Db は水平方向にスケーラブルですか?
水平スケーリングでは、全体的な容量やパフォーマンスの増減など、特定のタスクを実行するためにデータベースが追加または削除されます。 水平方向のスケーリングは、通常、複数の同じ構造のデータベースのデータを結合し、それらを個別のテーブルに分割することによって実装されます。
生成されるデータ量を処理するために、毎日、すべてのデータベースをスケーリングする必要があります。 スケーリングは、縦方向と横方向の 2 種類に分類されます。 2 TB サーバーのメモリは、より多くのデータを格納するのに十分です。 大規模なサーバーを非常に高額で購入しています。 サーバーへのマシンの追加は、水平スケーリングと呼ばれます。 その目的は、データ セットを複数のサーバーまたはシャードに分割することです。 非正規化に基づく単一の真実のポイントを持つことは無意味です。 この方法には欠点が 1 つあります。書き込みの実行中にマスターがスレーブ レプリカの更新に失敗すると、マスターはスレーブ レプリカを更新しません。

レプリケーションは、クラスター内のノード間でデータを交換する行為です。 データを複製することにより、サーバーの可用性と回復を向上させることができます。 さらに、レプリケーションを使用して、負荷を複数のノード クラスタに分散できます。 組織は、データを水平方向に小さなチャンクに分割し、それらのチャンクを複数のノードに分散できます。 水平に分割すると、パフォーマンスが向上します。 デフォルトの MongoDB クラスターに加えて、いくつかの異なるタイプのMongoDB クラスターがあります。 一般に、単一ノード クラスタは最も単純なタイプのクラスタであり、テストと開発に適しています。 2 ノード クラスターは、最も一般的な種類のクラスターであり、中規模から大規模のアプリケーションに適しています。 3 ノード クラスターも人気があり、大規模なアプリケーションに適しています。 たとえば、2 ノード クラスターでは、データは各ノードで 2 つの個別のシャードに分割されます。 この場合、各ノードにはデータのコピーがあります。 一方のノードの負荷が大きくなると、もう一方のノードが負荷を処理できる場合があります。 負荷分散クラスターは、最も一般的なタイプのクラスターの 1 つです。 3 ノード クラスターは 3 つの個別のデータ センターで構成され、各データ センターには 3 つの個別のシャードが含まれます。 1 つのノードの負荷が上昇すると、他の 2 つのノードが引き継ぐことができる場合があります。 バランスの取れたクラスターは、これらのクラスターの 1 つです。 MongoDB データベースは、水平方向のスケーリング機能 (レプリケーションと水平方向のパーティショニング (またはシャーディング)) を備えた最新のドキュメント ベースのデータベースです。 データベースを水平方向にスケーリングするプロセスには、需要の増加に対処するためにインスタンスまたはノードを追加することが含まれます。 より多くの容量が必要な場合は、クラスターにサーバーを追加するだけです。 さらに、サーバーは通常、デスクトップ コンピューティングに使用されるサーバーよりも小型で安価です。 クラスタ内のノード間でデータをコピーするプロセスです。 データを水平に分割すると、データが小さなチャンクに分割され、分散システム内の複数のノードに分散されます。 MongoDB クラスターにはいくつかのタイプがあり、それぞれに異なる機能セットがあります。 3 ノード クラスタも一般的ですが、4 ノード クラスタほど効果的ではありません。
リレーショナル データベースによる水平方向のスケーリング
従来の SQL データベースは通常、より多くのサーバーを収容する必要があるため、水平方向にスケーリングできませんが、他のマシンのレプリカを追加することはできます。 Write Ahead Log は、すべての書き込み操作をメイン サーバーから他のマシンに伝達するために使用されます。 クエリ構文の柔軟性のため、リレーショナル データベースは水平方向にスケーリングできません。 クエリを実行するまでデータの一部がフェッチされないようにするために、SQL では、データベースがどの部分が取得されるかを予測できないほど多くの条件とフィルターをデータに追加できます。 その結果、大量のデータを処理しようとすると、データベースが遅くなる場合があります。 リレーショナル データベースは水平方向にスケーリングできるため、Spark ストリーミングまたはバッチ計算のストレージ メディアとして機能するかどうかにかかわらず、Spark が通常あまり効果的でない領域をカバーするのに役立ちます。 クラウド SQL プラットフォームは、これらの構成をネイティブにサポートしていませんが、ProxySQL などの業界ツールを使用して実装できます。 ただし、Cloud SQL の基本的な概念は、これらのタイプのシナリオを対象としていません。
Nosql が水平方向にスケーラブルな理由
NoSQL データベースは、要件に応じて水平方向または垂直方向にスケーリングできます。 NoSQL データベースをシャーディングし、プロセスにサーバーを追加することで、トラフィックの多い状況に対処できます。 NoSQL データベースは、垂直方向ではなく水平方向にスケーリングできるため、大規模で頻繁に変更されるデータ セットに適しています。
非常に大きなデータベースを、非常に高いリクエスト レートで、非常に短いレイテンシで処理できる必要があります。 スケーリングと可用性は、eBay、Amazon、Twitter、Facebook などの大量の Web サイトにとって重要な要件です。 サーバー上で同時に複数のインスタンスを実行できる場合は、水平スケーリングが理想的です。
NoSQL データベースは、そのスケーラビリティと柔軟性により、SQL データベースと比較して人気が高まっています。 さらに、処理と保存が困難な非構造化データのテーブルベースのデータベースと比較して、パフォーマンスが向上します。
Nosql データベースをスケーリングする方法
この質問に対する万能の答えはありません。NoSQL データベースをスケーリングする最善の方法は、アプリケーションと格納されるデータの特定のニーズによって異なるためです。 ただし、NoSQL データベースをスケーリングする方法に関するヒントには、クラスターにノードを追加して容量とパフォーマンスを向上させる、シャーディングを使用して複数のノードにデータを分散させる、データを複数のノードに複製して高可用性を確保するなどがあります。
Couchbase の Rahim Yaseen が説明する中で、いくつかの重要なポイントが取り上げられています。 組織は、膨大な量のデータを管理、保存、収益化するために奮闘しています。 データベースに関する重要な決定事項の 1 つは、スケールアウトするかどうかです。 登録は手動シャーディングでチェックイン ブースに分散されます。 これは、明確に定義された事前定義されたスキームによって実現されます。 自動シャーディングの一環として、各ブースに行って、S で始まる姓でチェックインした人を見つける必要があります。ドキュメント データベースには、ユーザーが特定のキーを介して別のドキュメントに移動し、単一のキーを介してデータにアクセスする必要があるアクセス パターンがあります。鍵。 分散データ セットのサイズが大きくなるにつれて、インデックス作成とクエリがますます難しくなります。
クエリ内のすべてのノードが参加する必要があるため、map-reduce 手法を使用しても意味がありません。 データの量が増えるにつれて、 RDBMS モデルのスケールアップはますます現実的ではなくなります。 大規模なデータ セットの場合、スケールアップ アーキテクチャの障害は、非常に大きな障害点になる可能性があります。 インターネットは、超大規模なシェアード ナッシング クラスターの一例です。
Nosql データベース: スケーラビリティの未来
Nosql データベースでは複数のマシンにまたがってデータが送信されるため、非常にスケーラビリティが高くなります。 その結果、専用の機器を必要とする高価なマシンを購入する代わりに、CPU パワーを簡単に追加できます。 さらに、Nosql データベースは大量のデータを制限なく保持できるため、非常に用途の広いデータ管理システムになります。
SQLデータベースは水平方向にスケーリングできますか
はい、SQL データベースは水平方向にスケーリングできます。 これは、それらが複数のサーバーに分散され、それぞれが全データの一部を処理できることを意味します。 これにより、単一のサーバーが提供できるよりも優れたスケーラビリティが可能になります。
SQL データベースが水平方向にスケーラブルでないのはなぜですか?
クエリ構文の柔軟性により、リレーショナル データベースで水平方向にスケーリングすることは不可能です。 SQL の結果として、クエリが完了するまでデータのどの部分が返されるかをデータベース システムが認識できないようにする条件とフィルターをデータにいくつでも追加できます。
SQL が垂直方向にスケーリングするのはなぜですか?
垂直スケーリングの目標は、既存のシステムの消費電力と RAM 容量を増やし、基本的に利用可能なリソースを増やすことです。 垂直方向のスケーリングは簡単なだけでなく、コストも低くなります。 また、この問題は長期的な修正を必要としません。