
NoSQL データベースのスケーリング: ヒントとコツ
公開: 2022-11-18企業が生成するデータの量が指数関数的に増加し続けているため、NoSQL データベースの人気が高まっています。 ただし、多くの組織は NoSQL への切り替えに消極的です。これは、スケーリングがより困難になることを恐れているからです。 NoSQL データベースのスケーリングは、実際にはリレーショナル データベースのスケーリングとそれほど違いはありません。 主な違いは、NoSQL データベースは水平方向に拡張できるように設計されていることです。つまり、システムにノードを追加することで拡張できます。 これは、垂直方向に拡張可能なリレーショナル データベースとは対照的です。つまり、単一のサーバーにリソースを追加することによってのみ拡張できます。 NoSQL データベースをスケーリングする際に留意すべき点がいくつかあります。 1. データがすべてのノードに均等に分散されていることを確認します。 2. システムの過負荷を避けるために、ノードを徐々に追加します。 3. システムのパフォーマンスを綿密に監視して、ボトルネックを特定します。 4. システムを定期的に調整して、最適なパフォーマンスを確保します。 これらのヒントを念頭に置いておけば、NoSQL データベースのスケーリングは、リレーショナル データベースのスケーリングよりも難しくありません。
データベースの種類に応じて、データベースのスケーリングには多数の方法と原則があります。 NoSQL およびsql データベースのスケーリングは、データベース シャーディングの概念に依存しています。 サーバーが分散されていると、より多くのデータを保存できるという利点が得られますが、分散に伴う問題も継承されます。 自動シャーディングはモノリシック データベースではサポートされていないため、エンジニアはそれを処理するロジックを手動で作成する必要があります。 この問題を解決するために、ロード バランサーなどのプロキシをクエリ サービスとデータベースの前にインストールできます。 そのプロキシを再び使用できるため、シャードが大きい場合、より高速なクエリを取得できます。 エンド ユーザーが認識していないため、NoSQL データベースのスケーリングはほとんど目に見えません。
マスター/スレーブ アーキテクチャとは異なり、各シャードは一意です。 マスター シャードに読み取りクエリがある場合、リクエストはスレーブ シャードに送信されます。 データ センター レベルでは、データベースを複製してバックアップを確保できます。 ノードは、他のノードと通信して情報を交換できるノードです。 各ノードは、プロトコルを介して一定数の他のノードと通信します。 Cassandra ではすべてのノードが同等であるため、ノードはデータを失うことを心配することなく、データを次のノードに複製できます。 ゴシップ プロトコルは、ノードが情報を共有できる多くの方法の 1 つです。
分散データベースには、追加のプロパティを取得することに加えて、多くの利点があります。 可用性を確保するための重要なコンポーネントは、データの複製です。 データベースに非同期レプリケーションを使用する場合、最初は常に完全に一貫しているとは限りませんが、時間の経過とともに一貫性が増します。 SQL データベースは、高精度のデータを必要とする金融アプリケーションで使用されますが、NoSQL データベースは、ビュー カウントなどのそれほど重要でないアプリケーションで使用されます。
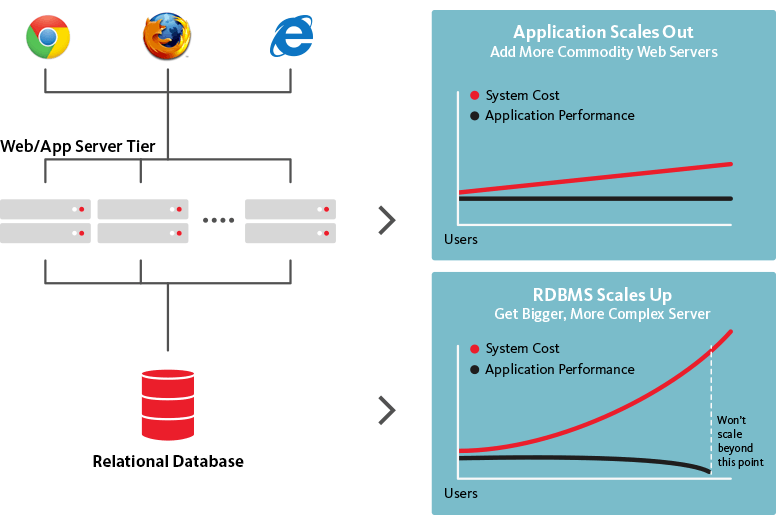
垂直スケーリングとは、ハードウェアのアップグレードを使用してコンピューティング ワークロードを徐々に増やすプロセスを指します。 分散アーキテクチャに移行し、コンピューターを追加して問題を解決するには、水平スケーリングまたはスケール アウトとも呼ばれるスケール アウトが必要です。
NoSQL は、Horizontal メソッドに基づくスケーリングをサポートできます。
NoSQL データベースである MongoDB は、そのデータがリレーショナル データベースに格納されていないため、スケーラブルです。 データは、HTTP 要求を介して簡単にアクセスできる JSON のようなドキュメントとして保存されます。 この方法を使用することで、複数のノードにまたがる水平方向の文書配布を行うことができます。
Nosql データベースをどのようにスケーリングしますか?
一方、NoSQL データベースは水平方向にスケーラブルです。つまり、データベースにサーバーを追加するだけで、必要に応じて増加したトラフィックを処理できます。 NoSQL データベースは、はるかに大規模で強力な構造に変換できるため、大規模なデータ セットや絶えず進化するデータベースには論理的な選択肢です。
このチュートリアルを機能させるには、Node.js 環境が機能している必要があります。 この投稿では、nodejs-dynamodb-sample という名前のフォルダーにDynamoDB ファイルを解凍します。 これの詳細なバージョンについては、私の GitHub ページ (https://www.gofundme.com/adamfowleruk/nodesurvey.html) にアクセスしてください。 サンプルアプリは、DynamoDB から映画情報を検索および取得できます。 Amazon Web Services の S3 にデータを保存し、Amazon の Identity and Access Management サービス (IAM) を介して DynamoDB にアクセスします。 Amazon の In-App Analytics サービスを使用するには、まず登録してアカウントを作成する必要があります。 /movies に投稿する各映画の年とタイトルをメモします。
特定の年の映画を検索するためにキー付きフィールドを入力できます。 その後、独自のアプリケーションをゼロから設計できます。 テーブルは使い終わるまで使用できますが、使用後は削除する必要があります。 アマゾン ウェブ サービスの DynamoDB コンソールにアクセスして、これまでに使用したストレージの量を確認してください。 [ムービー] タブでは、テーブル内のアイテムとアプリケーションからのメトリックを表示できます。また、[キャパシティ] タブで 1 か月あたりの推定月額コストを表示できます。 このコードは、私の GitHub ページ (https://github.com/adamfowleruk/nodejs-dynamodb-sample) にあります。
MongoDB、Apache HBase、および Cassandra は、水平スケーリングに最適な 3 つの NoSQL データベースです。 それらのデータ構造はより水平であるため、システムにサーバーを追加することが容易になり、サーバーを変更する必要もなくなります。 さらに、これらのデータベースは比較的新しいため、まだ開発および改良中であり、時間の経過とともに改善される可能性が高いことを意味します。
Nosql のスケーリングが簡単なのはなぜですか?
Nosql は、水平方向にスケーラブルになるように設計されているため、スケーリングが容易です。 これは、 nosql クラスターにノードを追加することでスケーリングできることを意味します。 Nosql は、大量のデータと 1 秒あたりの多数のクエリを処理できるため、スケーリングも容易です。

アプリケーションが適切に機能するには、高度なスケーラビリティが必要です。 シンプルで効率的なユーザー インターフェイスを備えたデータ ストアを選択することも同様に重要です。 主な論点は、「ASL」データベースと「Nosql」データベースのどちらを使用する方が優れているかということです。 NoSQL データベースは、SQL データベースとは対照的に、構築が簡単であるため人気があります。 NoSQL データベースでのすべての操作の停止は、本質的にシャーディングに依存しています。 一般に、すべてのデータ操作では修飾演算子を使用する必要があり、これを使用してデータを持つノードを識別できます。 データは複数のマシンに保存されるため、最小のマシンでもデータ操作を非常に簡単に実行できます。
その結果、NoSQL ストアは、比較的単純なコモディティ マシンを使用するように拡張できます。 ユーザーは、NoSQL データベースで特定の操作を実行するために同じノードから一度にフェッチできるように、データを計画および構造化することを前提としています。 この方法でデータを非正規化することは、ノードが事前に調理されたデータを実行する準備ができていることを意味する場合もあります。 NoSQL での結合は可能ですが、SQL 結合ほど堅牢ではありません。 NoSQL の実際の世界では、アプリケーション設計者は、最終的にはデータの一貫性が得られると考えています。 さまざまな NoSQL システム間で一貫性を調整するためのスイッチを提供することに加えて、多くの NoSQL システムは、一貫性をより際立たせるためのルーチンを提供します。 アーキテクチャの決定において重要なのは、ユース ケースを評価し、そのケースに基づいて適切なデータ ストアを選択することです。
すべての Nosql データベースはスケーラブルですか?
インターネットとクラウド コンピューティングの時代の結果、スケールアウト アーキテクチャの実装を容易にするために、NoSQL データベースが作成されました。 スケーラビリティは、データのストレージと、スケールアウト アーキテクチャ内の多数のコンピューターでデータを処理するために必要な作業を組み合わせることによって実現されます。
システムは、非常に高いリクエスト レートを処理しながら、非常に短い待ち時間で非常に大きなデータベースを処理できる必要があります。 eBay、Amazon、Twitter、Facebook などの大規模な Web サイトでは、スケーラビリティと高可用性が重要です。 水平スケーリングを使用して、サーバーの複数のインスタンスを同時に実行できます。
MongoDB のデータベースは、その規模とユーザー数の両方において、水平方向と垂直方向の両方でスケーラブルです。 MongoDB では、リソースを追加してデータを小さなチャンクに分割することで、クラスターを垂直方向または水平方向にスケーリングできます。 そのため、MongoDB は大規模なアプリケーションやデータ ストアによく使用されます。
迅速なスケーリングと大量のデータに最適な Nosql データベース
他の NoSQL データベースは、他のデータベースと同様に、特定のニーズに合わせてスケーリングできます。 たとえば、MongoDB は、迅速に拡張でき、大量のデータを処理できるため、人気のあるプログラミング言語です。 Redis に基づくデータストアは、インメモリ機能と速度により広く使用されています。
Nosql 垂直スケーリング
Nosql データベースは水平方向にスケーラブルです。つまり、システムにノードを追加することで、増加したトラフィックを処理できます。 これは、1 つのノードにリソースを追加することでシステムをスケーリングする垂直スケーリングとは対照的です。
毎日生成される大量のデータを処理するには、すべてのデータベースをスケーリングする必要があります。 「スケーリング」という用語は、垂直方向と水平方向の 2 つのタイプに分類されます。 より多くのデータを保存したい場合は、2TB サーバーに投資する必要があります。 単一のサーバーはますます高価になり、大規模になっています。 サーバーにマシンを追加するプロセスは、水平方向のスケーリングになります。 この場合、データはセットに分割され、複数のサーバーまたはシャードに分散されます。 非正規化モデルに従っているため、単一の真実は必要ありません。 このアプローチでは、マスターが書き込みの実行に失敗したときにスレーブ レプリカの情報が更新されないため、マスターが書き込みの実行に失敗したときに情報の更新が行われない場合があります。
SQLの垂直スケーリングとは何ですか?
垂直スケーリング アプローチの目標は、同じ論理サーバーのリソースを増やすことで、1 台のマシンの容量を増やすことです。 既存のソフトウェアを最高の状態で実行するには、メモリ、ストレージ、処理能力などのリソースをアップグレードする必要があります。
データベースを水平方向にスケーリングする方法
水平スケーリングとは何ですか? また、どのように機能しますか? 水平方向のスケーリング方法は、負荷に対応するためにノードを追加する必要がある方法です。 ノード間で関連データを分散するのが難しいため、リレーショナル データベースではこれが非常に困難です。
負荷を共有するためにインスタンスを追加するだけでなく、水平方向のスケーリング (またはスケール アウト) には、アプリケーションまたはサービスのインスタンスの数を増やす必要があります。 対照的に、垂直スケーリングでは、CPU パワーやメモリなど、より多くのリソースをインスタンスに追加する必要があります。 HTTP の基盤となるプロトコル、大部分の Web アプリ、および API により、それらは互いに独立して簡単にスケーリングできます。 一部のデータベースでは、書き込まれたデータを複数のインスタンス間で同期および共有できるようになりました。 トラフィックがこの方法でルーティングされる場合、最も頻繁に要求されるアイテムにより多くのリソースが割り当てられます。 リバース プロキシは一般的に HTTP 要求の処理に使用されますが、データベースは常に使用されるとは限りません。 ほとんどのデータベースは、nginx や HAproxy などのソフトウェアを使用して転送できます。どちらも TCP レベルで実行できます。
プロトコル レベルで接続がどのように機能するかをプロキシが理解できる場合、ネットワーク接続がアクティブであっても、リードレプリカが同期していないか、反応できないかを判断できます。 ルートは、レプリカの負荷と接続数に応じて調整できます。 さまざまな機能を実行できるプロキシ サーバーがいくつかあります。 永続的なボリュームとクレームではいくつかの進歩がありましたが、各インスタンスを等しく評価するデータベースを選択しないと、固有の問題もあります。 コンテナーはクラスター内で移動されているため、読み取りレプリカの 1 つを再起動しても問題ありません。 これがメイン データベースで発生した場合、興奮することはまずありません。