
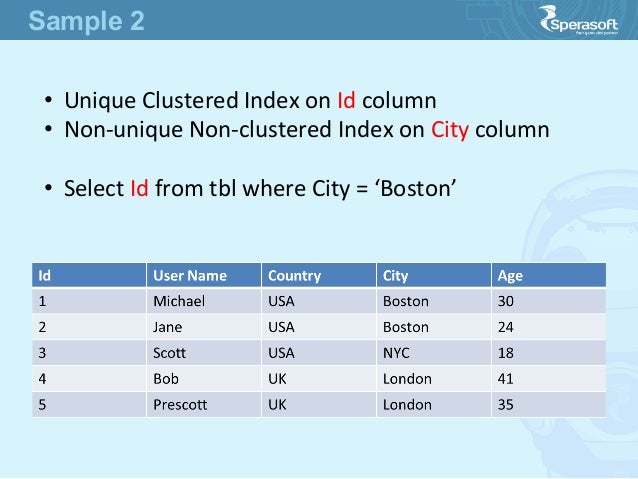
NoSQL データベースのインデックスの利点とコスト
公開: 2023-03-03一般に、クエリのパフォーマンスが懸念される場合は、 Nosql データベースでインデックスを使用する必要があります。 インデックスは、データベースが必要なデータをすばやく見つけられるようにすることで、クエリの実行を高速化するのに役立ちます。 ただし、インデックスは書き込み操作を遅くし、追加のストレージ領域を消費する可能性もあります。 そのため、インデックスを使用するメリットがコストを上回るかどうかを慎重に検討することが重要です。
RESTful Web サービスを採用したドキュメント指向のデータベース管理システムです。 さまざまなサイズと構造のドキュメントに大量のデータを格納できます。 データベース管理者にとって最も重要なツールの 1 つは、インデックスを作成することです。 このチュートリアルの目的は、インデックスの仕組みと作成方法を説明し、データベースでインデックスがどのように使用されるかを示すことです。 インデックス データ構造は、コレクションから収集されたデータの一部のみを格納する特別なタイプのデータ構造です。 データベースをすばやく簡単にトラバースできるように実装されているため、MongoDB はこの目的に適しています。 このガイドでは、サンプル データベースの作成方法とインデックスの作成方法について説明します。
このチュートリアルでは、さまざまなフィールドを持つドキュメントのコレクションを作成する方法を説明します。 山は、世界で最も高い 5 つの山を説明するドキュメントに記載されています。 出力には、新しく挿入されたオブジェクトの識別子の配列が含まれます。 このガイドの目的は、MongoDB がインデックスを使用して、インデックス内のクエリの詳細を強調表示することにより、トラバースされるドキュメントを制限する方法を説明することです。 createIndex() メソッドを使用して、peaks コレクションの高さフィールドにインデックスを作成できます。 この例で 1 つのフィールド インデックスを作成する場合、ドキュメントには 1 つのキー (この例では高さ) が含まれていると想定できます。 以前と同じクエリを使用する必要があるため、インデックスを使用して再試行する必要があります。
インデックスはクエリ実行のコンポーネントであるため、出力は異なります。 2 番目のステップは、市場に固有のインデックスを作成することです。 両方の _id 値が同じである場合、2 つのドキュメントをコレクションに追加することはできません。 これは、データベースが _id フィールドに単一のフィールド インデックスを自動的に維持するためです。 このステップでわかるように、特定のフィールドの値は、インデックスを使用してコレクション内のドキュメントごとにカスタマイズできます。 4 番目のステップは、MongoDB データベースの埋め込みフィールドにインデックスを追加することです。 クエリがデータベースの容量を超えると、パフォーマンスが大幅に低下する可能性があります。
この手順の目的は、埋め込みドキュメントのフィールドに単一フィールド インデックスを生成する方法を示すことです。 インデックスの数が多すぎると、インデックスの数が少ない場合と同様に、パフォーマンスが低下する可能性が非常に高くなります。 インデックス内のフィールドは最終的な順序に含まれるため、MongoDB は最終的な順序でインデックスを使用します。 つまり、すべてのドキュメントを取得した後、それらを再ソートする必要はありません。 前の例では、インデックスは *ascents.total: 1 * 構文を使用して昇順形式で作成され、クエリ要求の山のピークは降順に並べ替えられました。 単一のフィールド インデックスを使用して、MongoDB がクエリを実行しようとしているすべてのドキュメントを識別できます。 インデックスがクエリの最初の部分でしか利用できない場合、MongoDB は最初にコレクション スキャンを実行します。
場合によっては、複合インデックスの場合とは異なる場合があります。 追加のスキャンが不要になるように、複数のフィールドにまたがるインデックスを定義すると便利な場合があります。 6 番目のステップは、マルチキー インデックスを開発することです。 この手順では、インデックスの生成に使用されるフィールドが配列などの複数の値を格納するフィールドである場合の MongoDB の動作を示します。 場所フィールドのインデックスがないため、MongoDB はフル コレクション スキャンを実行してクエリを実行します。 これら 4 つのピークのそれぞれは、複数の値の配列である国にまたがっており、複数の国を表しています。 配列内のすべてのフィールドは、MongoDB でマルチキー インデックスとして自動的に作成されます。
たとえば、配列 [「中国、ネパール」] を含む場所フィールドを持つドキュメントには、同じドキュメントに対して 2 つの個別のインデックス エントリがあります。1 つは中国用、もう 1 つはネパール用です。 MongoDB は、クエリがこのようにコンテンツに対して部分一致のみを要求する場合でも、インデックスを効率的に使用できます。 MongoDB インデックスは、特別なデータ構造を使用することで、クエリの実行中に分析する必要があるデータの量を減らすことができます。 使用頻度の高いデータベースでのクエリ パフォーマンスを向上させるために、MongoDB のインデックス作成機能のサブセットについてチュートリアルで説明しました。 MongoDB のインデックス作成の詳細については、 MongoDB の公式ドキュメントを参照してください。
テーブルにアクセスするたびにデータベース テーブル内の行を検索するだけでなく、インデックスを使用してデータをすばやく見つけることができます。 データベース テーブルの 1 つまたは複数の列を使用してインデックスを作成するのは簡単です。これにより、迅速かつ効率的なランダム ルックアップと順序付けられたレコードへのアクセスの両方が可能になります。
NoSQL システムは、検索インデックスを次の 2 つの方法で保存します。NoSQLデータベースに保存されるオンサイト インデックスと、リモート検索サービスを使用する方法です。 NoSQL システムは通常、インデックスとデータを同じノードに保持します。 一部の NoSQL システムでは、全文検索に外部検索サービスを採用しています。
クエリの WHERE 句でフィルター条件としてインデックスを使用する場合、データ行の大部分を返す列でインデックスを使用することはお勧めしません。 本の索引に「the」または「and」という単語のエントリがある場合、それらを見つけることはできません。 インデックス付きテーブルを使用して、大規模なバッチ更新ジョブのバッチを定期的に実行できます。
MongoDB のインデックスはコレクション スキャンを必要としないため、通常はコレクション内の各ドキュメントをスキャンしてクエリに一致するものを見つける必要があるため、コレクション スキャンを実行する必要はありません。 適切なインデックスを使用すると、ドキュメントの数が最初から制限されているため、より効果的にクエリを実行できます。
データベース インデックスはいつ使用する必要がありますか?
インデックスとは何ですか? なぜ使用するのですか? データ インデックスの速度と使いやすさにより、データベースからのデータの取得が容易になります。 このメソッドは、select クエリと where 句を高速化します。 INSERT のパフォーマンスは向上しましたが、UPDATE のパフォーマンスも低下しました。
データベース テーブルのインデックスには、1 つ以上の列 (または列) のコピーが含まれています。 同様に、コピーされた各行は、インデックス内のテーブルの列の元の行にリンクされており、このリンクはコピーされた各行にも存在します。 データベースが書き込み操作よりも多くの読み取り操作を実行する場合、インデックスが最も役立ちます。 テーブル列で読み取るのではなく書き込むアクションには、ほぼ確実にインデックスは必要ありません。 データベース内の複数の列に対してインデックスを作成することは可能ですが、列の順序は非常に重要です。 ユーザーは、新しい機能を実装することで、監督の名前を使用して映画を検索し、どの映画が上映されたかを時系列で確認できるようになります。 最初に release_date でインデックスを作成した場合、各リリースにインデックスに関連付けられた複数のディレクター ID が含まれているかどうかを知る方法がありません。 ディレクターは、各ディレクターのリリース日を設定して、より正確な検索を要求されるようになりました。 データベース インデックスは、バランス ツリーまたは B ツリーによって区別されます。
テーブル内の行のサブセットは、インデックスを使用して取得できるため、テーブル スキャンの結果が高速になります。 テーブル スキャンの相対速度と、インデックス キーに関連付けられた行のクラスターに応じて、インデックスによって取得される行は異なります。
値の範囲が広いテーブルの場合、インデックスはそれらの検索にかかる時間を短縮するのに非常に役立ちます。
Nosql はインデックスを使用しますか?
NoSQL データベースのインデックス作成技術を使用して、Iインデックス付き構造のインデックス作成は、キーとデータ レコードの場所をペアにするプロセスです。 NoSQL データベースは、さまざまな方法でインデックスにすることができます。 このセクションでは、B ツリー、T ツリー、O2 ツリー インデックスなど、より一般的なインデックス作成方法について簡単に説明します。
Mongodb: 強力なドキュメント指向データベース
MongoDB データベースは、マルチキー インデックスを使用して配列の内容にインデックスを付けるドキュメント指向のデータベースです。 この場合、クエリは要素または配列の要素の一致を使用して、ドキュメントに配列が含まれているかどうかを判断できます。 プライマリ インデックスとは別に、MongoDB はプライマリ以外の属性のクエリに使用できるセカンダリ インデックスをサポートしています。
インデックスはどこで使用する必要がありますか?
データ取得プロセスを高速化するには、データベースでインデックスを使用する必要があります。 インデックスを使用して、SQL クエリのパフォーマンスを向上させることができます。
名前、主題、およびそれらが見つかった場所にリンクされているその他のトピックのリストが含まれています。 これらのシステムは、データを整理および分類するためにオンライン データベースでも使用できます。 この記事では、インデックスの作成とメンテナンスについて説明し、インデックスの基礎についても説明します。 インデックスの下書きには、メイン トピックと代替トピックを含めます。 サブカテゴリは、著者が興味を持ち、本のトピックに関連している場合にのみ作成する必要があります。 業界の出版物に執筆している場合は、一部の単語に代替用語または俗語を使用する必要がある場合があります。 索引語を開始するときは、名詞を使用します。
インデックス内のエントリの大部分には、大文字の単語が含まれていません。 出版物を参照している場合は、イタリック体にする必要があります。 一部の発行元には、サイトの各ページがインデックス ページ カウンターと一致することを保証するプロのインデクサーがいます。 そもそも名前や役職を使用する場合は、スペルが一貫していて正しいことを確認する必要があります。 John Grey という名前の研究者を引用する場合、オートコレクトをインデックス内の彼または彼女の名前に一致させることはできません。
インデックスを作成すると、必要な情報にすばやく簡単にアクセスできるようになります。 システムでレポートを生成して、ビジネスに関するより良い意思決定を行うのに役立てることができます。
Mongodb でインデックスを使用する必要があるのはなぜですか?
MongoDB でインデックス作成を使用する理由はいくつかあります。
1. インデックスを作成すると、クエリのパフォーマンスが向上します。特に、全文検索を使用するのではなく、特定の値をクエリしている場合に顕著です。
2. インデックス作成は、データに一意性制約を適用するのに役立ちます。これは、データの整合性に依存するシステムを構築している場合に役立ちます。
3. インデックスを作成すると、結果を取得するために必要なデータのみを保存できるため、ストレージ スペースの使用を最適化するのにも役立ちます。
MongoDB によると、過剰なインデックスもパフォーマンスに悪影響を与える可能性があります。 この記事では、いくつかの簡単な実験を行い、いつ、いくつのインデックスが必要になるかを判断するのに役立つヒューリスティックをいくつか紹介します。 この記事で紹介する調査結果を生成するために、N=1 の実験が使用されました。 MongoDB は素晴らしいパフォーマンスを発揮するため、アプリを構築するために他のものを使用することはありません。 優れたインデックス戦略のおかげで、小規模なクラウド ワークロードで 1 つの MongoDB クラスターを使用して、毎年 5,000 万ドルの収益を上げています。 いくつかの設計パターンを用意し、既知の遅い操作に注意することで、数千万のドキュメントのコレクションを簡単に処理できます。

SQL対Nosqlでのインデックス作成
SQL データベースと NoSQL データベースのインデックス作成には、いくつかの重要な違いがあります。 まず、SQL データベースは B ツリー インデックスを使用する傾向がありますが、NoSQL データベースはハッシュ インデックスを使用することがよくあります。 次に、SQL データベースは通常、テーブル内のすべての列にインデックスを付けますが、NoSQL データベースは通常、クエリ対象の列のみにインデックスを付けます。 最後に、SQL データベースでは通常、テーブル内のデータが更新されたときにインデックスを更新する必要がありますが、NoSQL データベースではインデックスが自動的に更新されることがよくあります。
この投稿では、SQL データベースと NoSQL データベースの違いと、それらのパフォーマンスについて説明します。 さらに、一方が他方よりも優れている使用例のリストを提供します。 すべてのデータベースには、データベースに応じて、データをクエリするための独自のクエリ言語またはアプローチがあります。 SQL データベースと比較すると、NoSQL データベースは 1 秒あたりの書き込み操作の実行効率が高くなります。 データはデータベースに入る前に構造化されておらず、検証もされていないため、形式が正しくないデータや正しくないデータを挿入したり保存したりする可能性があります。 NoSQL データベースについて言及する場合、「スキーマレス」データベースは、データの入力と取得に固定スキーマを必要としません。 1 秒あたり複数の読み取り操作が必要な状況では、SQL データベースが効果的な選択肢となります。
これは、大量のデータを保存する必要があるログ ロギング サービスに特に役立ちます。 これらのデータベースには、従来のデータベースよりも効率的で堅牢性が低い新世代のインデックス エンジンがあります。 NoSQL データベースは強力で人気がありますが、SQL データベースはさまざまな点で優れています。 それはすべて、組織のニーズと可能性にかかっています。 多くの業界知識を備えた実績のあるテクノロジーが必要な場合は、従来のデータベースを使用してください。 一方、NoSQL は、大量の非構造化データを可能な限り迅速に格納するための最適なツールです。
Nosql インデックス
NoSQL データベースは、リレーショナル データベースの従来のテーブル ベースの構造を使用しない非リレーショナル データベースです。 NoSQL データベースは、ビッグ データやリアルタイム Web アプリケーションによく使用されます。
セカンダリ インデックスには、インデックスの親テーブルに含まれていない属性の配列が含まれています。 個別のパーティションとテーブルの並べ替えが利用可能です。 ベース テーブルとは対照的に、このソフトウェアはデータの並べ替えと分割に使用できます。 セカンダリ インデックスは、想定したように、パーティション キーによってパーティション分割されたテーブルで構成されていません。 テーブルは、親テーブルと同じノードに格納されます。 キー値 NoSQL データベースのパーティション テーブルを使用して、追加のインデックスを定義できます。 ベース テーブルと同じノードでは、セカンダリ インデックスはデータ構造です。 インメモリ データベースの実装に関するセクションでセカンダリ インデックスを実装するのは簡単でした。 この実験では、2 つのインデックス作成戦略 (コピーとフェッチ) を実装する方法を示しました。
Mongodb インデックス作成
MongoDB のインデックス作成は、データ構造を作成してクエリのパフォーマンスを最適化するプロセスです。 インデックスは、MongoDB でのクエリの効率的な実行をサポートします。 インデックスがないと、MongoDB はコレクション内のすべてのドキュメントをスキャンする必要があり、コストがかかり遅くなる可能性があります。
インデックスは、コレクションのデータの一部を簡単にアクセスできる形式で保持する特別なデータ構造の一種です。 この方法でのインデックス エントリは、等価一致と範囲ベースのクエリ操作の両方が効率的になるように並べ替えられます。 MongoDB は、コレクション内の任意のフィールドまたはサブフィールドのドキュメントにインデックスを付け、コレクション レベルで定義できます。 MongoDB のインデックスを使用すると、データを検索し、必要なデータとクエリのタイプに基づいてクエリを実行できます。 複合インデックスでは、フィールドがリストされる順序と表示される順序に大きな違いがあります。 MongoDB は、マルチキー インデックスを使用して配列に格納されたデータにインデックスを付けます。 MongoDB は、静止システムで座標データを管理するための 2 種類のインデックスを提供します: 2dsphere と 2dsphere です。
疎インデックスの代わりに、MongoDB 5.3 バージョンではクラスター化インデックスを作成できます。 非表示のインデックスは、クエリ プランナーには表示されず、クエリのサポートには使用できません。 非表示のインデックスはプランナー内で非表示にできるため、ユーザーは実際にインデックスを削除しなくても、インデックスの削除がインデックスの値にどのように影響するかを確認できます。 MongoDB では、大文字小文字やアクセント記号など、比較文字列に適用する規則をユーザーが指定できます。 操作で別の照合順序が指定されている場合、操作では、照合順序のあるインデックスを使用して、インデックス付きフィールドで文字列比較を実行できません。 Analyze Query Performance チュートリアルでは、インデックスの有無にかかわらず実行されたクエリの統計の例を示します。 MongoDB はインデックスを使用して、それらの交差を使用してクエリを実行できるようにします。
インデックス キーは、場合によっては特定の制限を受けます。 インデックスが作成されると、アプリケーションのパフォーマンスが低下する場合があります。 ドライバーは、インデックス指定として 1 ではなく NumberLong(1) を使用する場合があります。 その結果、結果のインデックスは変更されません。
Mongodb でインデックスを使用する必要がありますか?
MongoDB でインデックスを使用することの長所と短所は何ですか?
インデックスを作成することで、MongoDB はクエリのパフォーマンスを向上させ、データをより高速に検索できます。 インデックスは、複数のシャードおよびノード間でデータの一貫性を確保するのにも役立ちます。 一方、インデックスはクエリの複雑さとコストを増加させる可能性があるため、必要がない場合は注意して使用する必要があります。
Mongodb複合インデックスと単一インデックス
複合インデックスは、ドキュメントの 1 つのフィールドだけにインデックスを付けるわけではありません。 複数のフィールドに昇順または降順でインデックスを付け、フィールドに入力すると複数のフィールドのデータを並べ替えます。
MongoDB のインデックス作成は、クエリをより有効に活用するのに役立ちます。 複合インデックスという用語は、単一のフィールドへの複数の参照を持つインデックスを指します。 MongoDB では、単一のハッシュ インデックス フィールドを使用して、複合インデックスを表すことができます。 その結果、作成したインデックスのおかげで、db.collection.sort (manufacturer:1, price:-1) などのクエリをより効率的に実行できます。 MongoDB インデックスでは、MongoDB によって sort() が提供されます。 MongoDB Sort 式の一致 (プレフィックスの一致) は、順序付けられたレコードを含むインデックスから取得できます。つまり、MongoDB は、順序付けされたレコードを含む任意のインデックスから、Sort 式の一致 (プレフィックスの一致) を取得できます。 MongoDB がインデックスを使用して並べ替え順序を生成できない場合、ブロック並べ替え操作が実行されます。
Mongodb の単一インデックスとは何ですか?
MongoDB は、ドキュメントが保存されているフィールドと、コレクション内の他のフィールドに基づいてドキュメントのインデックスを作成します。 すべてのコレクションは -id フィールドにインデックスを持つことができ、アプリケーションとユーザーはインデックスを追加して、重要なクエリと操作をサポートできます。 インデックス プロットは、ドキュメントの 1 つのフィールドで昇順または降順で配置されます。
インデックス作成が重要な理由
ドキュメントまたは一連のドキュメントのインデックスを作成して、情報をすばやく簡単に取得できるようにするプロセスは、インデックス構築と呼ばれます。 索引付けが役立つ理由は 2 つあります。 索引の最初の利点は、大きな文書内の特定の情報をより速く見つけるのに役立つことです。 たとえば、新聞の特定の記事を探している場合、インデックスを使用すると、記事のタイトルが何であるかがわかります。 インデックスの利点の 1 つは、ドキュメント内の情報に障害を持つユーザーがより簡単にアクセスできるようになることです。 たとえば、株価指数を使用すると、ティッカー シンボルで特定の企業について調べることができ、目の不自由な人でも調べることができます。
Mongodb でインデックスを作成するための別のオプションは何ですか?
MongoDB は、複数のキー インデックスを使用して、MongoDB の配列内のコンテンツにインデックスを付けます。 MongoDB は、配列値を持つフィールドにインデックスを付ける場合、配列の各要素に対して個別のインデックス エントリを作成します。 これらのマルチキー インデックスでは、配列の要素または部分をマルチキー インデックスと照合することにより、クエリで配列を含むドキュメントを選択できます。
Mongodb でインデックスを削除すると検索パフォーマンスが低下する
欠点の 1 つは、インデックスが削除された場合、関連するレコードを見つけるために MongoDB がデータを再分析しなければならないことです。
イントロダクション
Mongodb は、強力なドキュメント指向のデータベース システムです。 インデックスベースの検索機能を備えているため、データをすばやく簡単に取得できます。 Mongodb にはスケーラビリティ機能もあり、大規模なデータを処理できます。
MongoDB は、クロスプラットフォームでオープンソースの NoSQL データベースであり、データを格納するために多くのノードベースの Web アプリケーションで使用されています。 このチュートリアルでは、Mongo をインストールする方法と、Mongo を使用してデータを保存およびクエリする方法を紹介します。 ノード プログラムを使用して Mongo データベースとやり取りする方法を学習し、Mongo と従来のリレーショナル データベースの違いをいくつか調べます。 MongoDB は、公式の Linux ソフトウェア チャネル経由でダウンロードしてインストールするのが一般的ですが、古いバージョンになる場合があります。 Ubuntu ベース以外の Linux ディストリビューションを使用している場合は、このページにアクセスしてインストールの詳細を確認できます。 MongoDB には、グラフィカル ユーザー インターフェイスを使用してデータベースに接続し、管理できる Compass というツールも用意されています。 MongoDB では、アクセス制御を行う必要はありません。
本番環境で Mongo を使用している場合は、この機能を変更する必要があります。 頭字語 CRUD は、何かが作成、読み取り、更新、または削除されたことを示すために使用されます。 これらは、アプリケーションを構築する場合に実行する必要がある 4 つの基本的なデータベース操作です。 すべてのユーザー ドキュメントを取得するために実行できるいくつかの手順を次に示します。 これは、"From USERS" 列から読み取る SQL データベースのクエリに対応します。 MongoDB には、作成操作を含む、ドキュメントを更新するためのさまざまな方法が用意されています。 たとえば、18 歳未満のすべてのユーザーに対して登録の値を 18 歳に設定できます。
スキーマのないデータベースである MongoDB を使用する場合、列の数や型を指定する必要はありません。 一方、JSON スキーマは、データの検証ルールを指定するために使用できます。 MongoDB サーバーと通信するには、ドライバーと呼ばれるクライアント側のライブラリを使用する必要があります。 コールバック、約束、または待機はすべて、データベースとやり取りするための可能な方法です。 Mongo に接続するには、コードで名前とパスワードを指定する必要があります。 MongoDB にはドライバーが組み込まれていますが、MongoDB ドライバーとしても知られています。 MongoDB でデータを管理するには、まずスキーマを確立する必要があります。 MongoDB コレクション内の各ドキュメントの形状は、スキーマのマッピングによって決まります。
Mongodb: リレーショナル データベースの Nosql 代替手段
MongoDB は、分散データの大規模なコレクションを安全かつ効率的な方法で管理するための API を提供する、オープン ソースの NoSQL データベース管理プラットフォームです。 MongoDB は、JSON ストレージと非リレーショナル ドキュメント構造をサポートする非リレーショナル ドキュメント データベースです。 従来のリレーショナル データベースは、MongoDB での処理に最大 5 分かかる場合があります。 さらに、MongoDB は、分散データの大規模なセットを管理するためのリレーショナル データベースの優れた代替手段です。