
さまざまな種類のコンピューター クラスター
公開: 2023-02-16コンピューティングでは、クラスターは、多くの点で単一のシステムと見なすことができるように連携して動作する独立したコンピューター システムのグループです。 クラスターは通常、単一のコンピューターよりもパフォーマンスと可用性を向上させるために展開されますが、通常、同等の速度または可用性の単一のコンピューターよりもはるかに費用対効果が高くなります。 コンピューター クラスターには、高性能コンピューティング クラスター、商用目的で使用されるコンピューター クラスター、ストレージ クラスターなど、さまざまな種類があります。 各タイプのクラスタでは、コンポーネント システムが連携して共通のタスクを実行します。 ハイパフォーマンス コンピューティング (HPC) クラスターは、大量の計算能力やデータ ストレージを必要とする科学および工学アプリケーションに使用されます。 これらのクラスタは通常、高速なローカル エリア ネットワーク (LAN) で接続された汎用コンピュータのグループで構成されます。 通常、HPC クラスター内のコンピューターは、同じまたは類似のオペレーティング システム (OS) を実行し、同じまたは類似のハードウェア コンポーネントを備えています。 商用クラスタは、高度な可用性やスケーラビリティを必要とするビジネス アプリケーションを実行するために使用されます。 これらのクラスターは、多くの場合、さまざまな OS を実行し、さまざまなハードウェア コンポーネントを備えたサーバーで構成されています。 多くの場合、商用クラスタ内のサーバーはストレージ エリア ネットワーク (SAN) にも接続されているため、共通のデータ ストアにアクセスできます。 ストレージ クラスタは、コンピュータのグループからアクセスできる集中ストレージ リポジトリを提供するために使用されます。 通常、ストレージ クラスタは、SAN に接続されたストレージ サーバのグループで構成されます。 ストレージ クラスタ内のサーバは、通常、さまざまな OS を実行し、さまざまなハードウェア コンポーネントを備えています。
シャード mongodb クラスターとは何ですか?また、MongoDB で 1 つに接続するポイントは何ですか? ローカルホストに接続するか、単にローカルホストに接続するにはどうすればよいですか? 金メダルは Noob 7461 バッジで授与されます。 銀バッジ10個、ブロンズバッジ23個が生産されました。 レプリケートされたクラスターは、mongos インターフェイス用に 1 つ、各レプリカ セット用に 3 つ、各構成サーバー レプリカ セット用に 1 つの 10 台のサーバーで構成されます。 レプリケーション システムでは、何か問題が発生した場合に常にバックアップが存在するように、コンポーネントが複製されます。 シャードを製造するには、すべてのシャードがレプリカである必要があります。
たとえば、mongodb クラスターは、MongoDB のシャード クラスターを表すためによく使用されます。 分割された mongodb は、次の機能を提供します。 複数のノードからの読み取りと書き込みのスケーリング。 各ノードはデータ セット全体を処理するわけではないため、データをシャード内のリージョンに分割することしかできません。
データベース クラスタ は、その名前が示すように、実行中のデータベース サーバーの 1 つのインスタンスで実行できるデータベースのコレクションです。 PostgreSQL の「デフォルト」データベースを意味する Postgres は、データベース クラスタの作成後にデフォルト データベースとして含まれます。
MongoDB クラスターは、「レプリカ セット」または「シャード クラスター」とも呼ばれます。 レプリカ セットでは、複数のサーバーが同じデータのコピーを保持します。 レプリカ セット内のノードは通常 3 つです。 クライアント アプリケーションがノードで操作を実行すると、すべての読み取りと書き込みがそのノードに送信されます。 何か問題が発生した場合、2 つのセカンダリ ノードがそれを保護します。
クラスターとデータベースは同じですか?
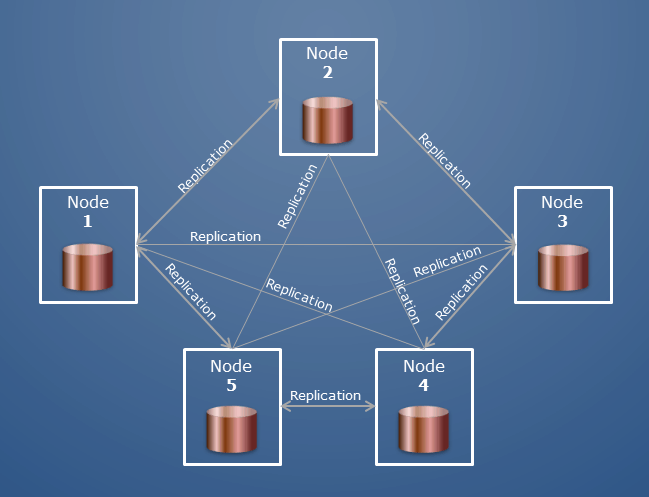
クラスターを構成するホストの複数のクラスターがあります。 分割クラスターのホストは、さまざまな役割に分類されます。 データベースはコレクションのコレクションです。 Oracle では、データベースとスキーマに相当します。
データベース クラスタは、あるデータベースを別のデータベースに接続するサーバーまたはインスタンスの集合です。 データベース クラスタリングは、さまざまな理由でサーバーによって使用されます。その主な理由は、データの冗長性、負荷分散、高可用性、および監視と自動化です。 その結果、コンピューターに障害が発生した場合、すべてのデータを他のユーザーが利用できるようになり、データの冗長性という利点が得られます。 クラスタリングを使用すると、潜在的な問題を特定するためのルールを作成しながら、データベースのプロセスの多くを自動化する機会があります。 クラスタ アーキテクチャでは、すべての要求が複数のコンピュータにルーティングされ、それぞれのコンピュータが要求を処理してユーザーに提供することができます。 フェールオーバーまたは高可用性クラスターは、サーバーを複製し、ハードウェアを再構成してサービスの可用性を確保します。 これらのタイプのクラスターは、システムに完全に依存しているコンピューター ユーザーにとって有益です。 高性能クラスタの目標は、パフォーマンスを向上させながらネットワーク容量を増やすことです。
Hadoop 分散システムでは、ノードはデータ ストレージおよび処理センターとして機能します。 クラスターとサーバーの主な違いは、クラスターが一連の操作を実行するために相互に通信する複数のノードを使用することです。 クラスタには、一連の操作を実行する多数のノードが含まれています。 Hadoop 分散システムは、最大 10,000 のデータベースをサポートできます。 同じデータベース内の複数のテーブルからのデータを、同じクラスター内の複数のデータベースからのクエリに結合すると、同様のクエリ結果が得られます。
クラストの利点
クラスターを使用すると、すべてのデータベースに均一なテーブルと列のストレージを提供することで、複数のデータベースを簡単に管理できます。 これにより、パフォーマンスとデータの整合性が向上し、システムの効率が向上します。
クラスター名は Mongodb のどこにありますか?
クラスター名は、使用されている MongoDB クラスターのタイプによって異なる場所にあるため、この質問に対する明確な答えはありません。 たとえば、レプリカ セットでは通常、クラスター名は local.system.replset コレクションに格納されますが、シャード クラスターでは通常、config.shards コレクションに格納されます。
MongoDB Atlas は、MongoDB-as-a-Service NoSQL Database-as-a-Service オファリングであり、Microsoft Azure、Google Cloud Platform、および Amazon Web Services パブリック クラウドで利用できます。 リンクをクリックしてセットアップすることにより、お気に入りの Web ブラウザーを使用して、数分で動作する MongoDB クラスターを作成できます。 ワークステーションを介して Web に接続するためにワークステーションにソフトウェアをインストールする必要はなく、Web インターフェイスを使用して接続できます。 MongoDB レプリカ セットを複数の MongoDB サーバーと組み合わせて使用すると、データの冗長性と高可用性が保証されます。 MongoDB クラスターには追加の読み取り操作容量があり、クライアントを追加のサーバーに誘導できます。 レプリケーションでは、レプリカ セットの 1 つ以上のメンバーがプライマリ ノードの oplog からセカンダリに非同期的にレプリケートされるため、メンバーに障害が発生した場合でもレプリカ セットは機能します。 MongoDB では、標準の入力および出力コマンドに加えて、追加の読み取りおよび書き込み操作を実行できます。
ほとんどの場合、プライマリ ノードはすべての読み取り操作のソースですが、セカンダリへのルーティングを構成できます。 最も近いノードがセカンダリ ノードである場合、データが古くなる可能性があるリスクが高くなります。 書き込みがクラスター全体に正常に反映されるようにするには、MongoDB レプリカ セットにデータを書き込むためのオプションを含める必要があります。 このプロセスの一環として、挿入する書き込み関連プロパティを追加する必要があります。 書き込み要求が受信されると、クラスターは、大部分のデータ ベアリング ノードで書き込みが成功したことを確認するように要求されます。 シャード クラスターを構成すると、レプリカ セットとしても構成できます。 レプリカ セットには、プライマリとセカンダリの両方の mongod プロセスが含まれています。 マスターに障害が発生した場合、過半数が確実に実行されるように、これらのプロセスの合計数を奇数にすることをお勧めします。
MongoDB クラスター は、名前が示すように、連携してデータを保存および管理するノードのクラスターです。 MongoDB クラスターを作成するときは、含めるノードの数と構成対象を指定します。 アプリケーションが作成されたら、ノードを使用してアプリケーションを MongoDB クラスターに接続できます。 MongoDB Compass は、MongoDB JS ライブラリのドライバーまたは MongoDB の PyMongo ドライバーと考えることができます。 アプリケーションをクラスターに接続する主な利点は、データを読み書きできることです。 MongoDB Compass を使用すると、さまざまな方法でデータを探索、変更、視覚化できます。 データを表示する方法の例はグリッドで見つけることができます。これにより、時間の経過とともにデータがどのように変化するか、およびクラスター内で誰がデータを配布しているかを観察できます。
Mongodb Atlas のクラスターはどこにありますか?
この質問に対する決定的な答えはありません。MongoDB Atlas 内のクラスターの場所は、クラスターが配置されている地理的地域や稼働しているアプリケーションの特定のニーズなど、さまざまな要因によって異なる可能性があるためです。 ただし、一般に、MongoDB Atlas のクラスターは、MongoDB Atlas コンソールの「クラスター」セクションにあります。

クラスタは、レプリカ セットまたはシャード セットのいずれかです。 各プロジェクトのノードの総数は、地域全体の機能の範囲に基づく特定の制約によって制限されます。 各 Atlas プロジェクトは、最大 25 のデータベースをデプロイできます。 データベースの配置制限に関する質問については、データベース管理者にお問い合わせください。 TLS バージョン 1.2 は、2020 年 7 月 1 日以降に作成されたクラスターのデフォルトの TLS バージョンです。
Mongodb のクラスターとは
MongoDB では、クラスターは、同じデータのコピーを保持するデータベース サーバーのグループです。 クラスタ内の各サーバーはノードと呼ばれます。 クラスターは 1 つ以上のノードを持つことができます。
データベース クラスタリングの目的複数のサーバーまたはインスタンスを単一のデータベースに接続するプロセスは、SQL 接続と呼ばれます。 MongoDB では、クラスターは、MongoDB のタイプに応じて、レプリカ セットまたはシャード クラスターのいずれかになります。 これらのクラスターのそれぞれの特徴について、次の段落で詳しく説明します。 MongoDB の負荷分散とマシン数により、高レベルの可用性が実現します。 クラスターを使用して、多くのデータベース プロセスを自動化しながら、潜在的な問題を警告するルールを作成することもできます。 MongoDB データベースは、レプリカ セットとシャーディング クラスターの 2 つのタイプに分けることができます。
データはシャード内の複数のマシンに保存されます。 データのスケーラビリティを提供する MongoDB の方法は、これに基づいています。 これにより、大量のデータを管理するのにかかる時間が短縮されます。 レプリカが提供するデータ量により、分散アプリケーションもレプリカから恩恵を受けることができます。
複数の Atlas プロジェクトが同じクラスターにデプロイされている場合、パフォーマンスの問題とデータの競合が発生する可能性があります。 Atlas では、Atlas プロジェクトごとに 1 つの無料クラスターのみを使用することをお勧めします。 幅広いデータ分析およびデータ マイニング アプリケーションでは、優れたデータ クラスタリング ツールが必要です。 Atlas プロジェクトでの潜在的なパフォーマンスの問題とデータの競合を回避するために、Atlas では、プロジェクトごとに 1 つの無料クラスターのみを使用することをお勧めします。
Mongodb クラスターのアーキテクチャ
MongoDB クラスターは、連携してデータを保持する MongoDB サーバーのグループです。 クラスタ内の各サーバーはノードと呼ばれます。 クラスターには、任意の数のノードを含めることができます。 クラスターは、それぞれがデータのコピーを持つノードのグループであるレプリカ セットで構成されます。 レプリカ セットには少なくとも 3 つのノードがあるため、1 つのノードがダウンしてもデータは引き続き使用できます。
レプリカ セットのアーキテクチャは、MongoDB の容量と機能において重要な要素です。 通常、MongoDB クラスターは 3 つのノードのレプリカに分散されます。 災害後のデータベース リカバリは、特に余波において常に安定している必要があります。 シャード クラスターを展開する最良の方法の 1 つは、レプリケーション戦略を使用することです。 シャード キーに含まれるデータは、同じ方法で配布する必要があります。 データベースを水平方向にスケーリングし、1 つのインスタンスで実行できる操作の数を減らす必要があります。 シャードが少ないと、シャードの数によって操作の数が制限されるため、読み取り操作と書き込み操作が遅くなる可能性があります。
シャード内の各データは、特定の基準セットに基づいたその部分のサブセットで構成されています。 シャーディングの重要性を達成するために必要なシャードの最小数は 2 であるのが一般的です。 スキャッター/ギャザー クエリは、すべてのシャードで同時に使用できる場合にのみ使用してください。 クラスタを選択するときは、選挙プロセスをできるだけ簡単にするために、少なくとも 7 人の投票メンバーを持つことが重要です。 投票メンバーが 7 人以下で、メンバー数が同数の場合は、アービターを使用する必要があります。 アービターはデータのコピーを保存しないため、データの処理に必要なリソースが少なくなります。 レプリカ セット メンバーまたはシャード クラスター メンバーを構成する場合は、IP アドレスではなく論理 DNS ホスト名を使用することをお勧めします。 一部のドライバ グループ レプリカ セット接続はレプリカ セット名によって行われるため、これらの名前はセットに対して個別に使用する必要があります。 レプリカ セット ノードの地理的分散は、データ センターの 1 つが存在しない場合に冗長冗長性に対処し、フォールト トレランスを確保するのに理想的です。
Mongodb クラスター名
MongoDB クラスターは、連携して高可用性とスケーラビリティを提供する MongoDB サーバーのグループです。 通常、クラスタには、マスター サーバーとして機能するプライマリ サーバーと、スレーブとして機能する 1 つ以上のセカンダリ サーバーがあります。 プライマリ サーバーにはデータが含まれ、セカンダリ サーバーはプライマリ サーバーからデータをコピーします。
ドキュメント指向のデータベース プログラムは、クロスプラットフォーム プログラムである MongoDB の助けを借りて、大容量ストレージ用に作成されます。 NoSQL データベース プログラムである MongoDB は、オプションのスキーマを持つ JSON スタイルのドキュメントを採用しているため、NoSQL データベース プログラムとして分類されます。 データベースを他の DigitalOcean リソースと同じデータ センターにインストールすることで、パフォーマンスを向上させることができます。 リージョンには 1 つ以上のデータセンターがあり、それぞれに独自の VPC ネットワークがあります。 データベースノードのマシンタイプ、数、およびサイズはすべて選択できます。 別の言い方をすれば、最大 2 つのスタンバイ ノードをクラスターに追加できます。 プロジェクト名を追加して完成させ、作成時に使用したいタグを使用します。 クラスターが完了するまでに最大 5 分かかる場合があります。
Mongodb Atlas Cluster のパワー
MongoDB Atlas Cluster は、 MongoDB で実行されるパブリック クラウドのサービスとしての NoSQL データベース ソリューションです。 これは、アプリケーションを迅速に作成して展開できる、堅牢でスケーラブルなデータ プラットフォームです。 MongoDB Atlas Cluster を使用することで、世界中のどこからでも安全に MongoDB に接続できます。
Mongodb でクラスターを作成する方法
次の手順を使用して、MongoDB でクラスターを作成します。
1. 展開トポロジを選択します。
2. デプロイするレプリカ セットのタイプを選択します。
3. デプロイするレプリカ セットの数を選択します。
4. レプリカ セットを構成します。
5. mongos ルーターに接続します。
6. シャード キーを構成します。
7. クラスターにシャードを追加します。
8. クラスタが動作していることを確認します。
MongoDB Atlas は、MongoDB のフルマネージド クラウド データベース サービスである MongoDB の無料利用枠です。 このサービスは、エンタープライズ ワークロードとグローバル クラスター向けに設計されています。 アマゾン ウェブ サービス (AWS)、Google Cloud Platform、または Microsoft Azure でアカウントを作成する必要はありません。 サービスにアクセスするには、管理者アカウントを作成する必要があります。 サービスにアクセスするには、クラスターが IP アドレスにリンクされている必要があります。 MongoDB Atlas のデフォルトのセキュリティ設定は、すべての外部接続を防ぎます。 Studio 3T に簡単に接続できるように、パスワードには特殊文字を使用せず、英数字のみを使用してください。 MongoDB の接続文字列を作成するときは、特殊文字をエンコードする必要があります。 ステップ 1 で、DRIVER ドロップダウン リストから Java を選択し、次に VERSION ドロップダウン リストから選択します。 ドライバーとバージョンを選択すると、サービスは手順 2 で接続文字列を自動的に更新します。
Mongodb クラスタリング: 高需要スループットのための優れたオプション
MongoDB クラスタリングを使用すると、大規模環境の高いスループット、可用性、およびスループットの要件を満たすことができます。 MongoDB クラスターは、単純な単一ノードのセットアップから高可用性のマルチノード構成まで、幅広い MongoDB レプリカ セット タイプをサポートするように構成できます。
Mongodb クラスター チュートリアル
MongoDB クラスターは、連携してデータを保持する MongoDB サーバーのグループです。 MongoDB クラスターは、単一のサーバーのように小さくすることも、数百のサーバーに大きくすることもできます。 MongoDB クラスターを作成するときは、クラスターに含めるサーバー (ノード) の数を指定します。 MongoDBクラスター内の各ノードには、データのサブセットが格納されます。 MongoDB クラスターは、スケーラブルで高可用性を提供するように設計されています。 容量を増やしたり、障害が発生したノードを交換したりするために、いつでもクラスターにノードを追加できます。 クラスターからノードを削除すると、データがクラスター全体に均等に分散されるように、他のノードが削除されたノードからデータを再分散します。
Hevo の MongoDB クラスタリングの簡単なガイドは、最初のステップです。 データベースが小さすぎたり遅すぎたりしてシステムを実行できない場合でも、組織の運用は継続されます。 MongoDB には、シャーディングやレプリケーションなど、クラウド向けに設計された多数の高度な機能があります。 MongoDB を使用すると、同じデータの複数のコピーを保存できるため、アクセスしやすくなります。 一方のサーバーに障害が発生した場合、もう一方のサーバーからデータをすぐに取得できます。 Hevo Data を使用して、データ レプリケーションのプロセスを自動化、簡素化、強化できます。 14 日間の無料試用版にアクセスできる場合、データ複製は簡単で簡単に使用できます。
MongoDB クラスターをセットアップするには、最初に 3 つの必要なコンポーネントをすべてインストールする必要があります。 Hevo の自動化されたノーコード プラットフォームを使用すると、スムーズなデータ レプリケーション エクスペリエンスのために必要なすべてを追跡できます。 最大限の可用性を確保するには、複数の構成サーバーまたはルーターが存在する必要があります。 ルーターは、データが格納されているシャードを判別すると、適切なクラスターに要求を送信します。 MongoDB クラスターを確立するプロセスでは、シャードを追加するために次の手順が必要になります。 クラスター構成では、ポート 27018 がシャード サーバーのデフォルトとして使用されます。 これは、構成サーバーではなく、シャード サーバーであることを意味します。