
グラフ データをディスクに保存するさまざまな方法
公開: 2022-11-22グラフ データベースは NoSQL データベースの一種で、ノード、エッジ、およびプロパティを含むセマンティック クエリにグラフ構造を使用してデータを表現および格納します。 グラフ データベースは、データをグラフ形式で格納するという点で、他の NoSQL データベースとは異なります。 これは、データがノード (エンティティ) とそれらのノード間の関係 (エッジ) によって表されることを意味します。 これにより、従来のデータベースよりもはるかに柔軟で簡単にクエリを実行できます。 グラフ データベースがデータをディスクに格納する方法はいくつかあります。 最も一般的なのは、隣接リストを使用することです。 これは、各ノードが接続されている他のすべてのノードのリストを持っている場所です。 これはグラフ データを格納する最も簡単な方法ですが、グラフが非常に大きい場合は非効率的です。 グラフ データを格納するもう 1 つの方法は、隣接行列を使用することです。 ここでは、ノード間のエッジを表すためにマトリックスが使用されます。 これは、グラフが大きいほど効率的ですが、クエリが難しくなる可能性があります。 グラフ データを格納する最後の方法は、プロパティ グラフを使用することです。 これは、各ノードが一連のプロパティ (属性) を持ち、ノード間のエッジがそれらのプロパティによって定義される場所です。 これは、グラフ データを格納する最も柔軟な方法ですが、クエリが難しくなる可能性があります。 グラフ データベースは、データ分析のための強力なツールであり、さまざまなアプリケーションに使用できます。 これらは、複雑なクエリを必要とするアプリケーションや、柔軟な方法でデータを保存する必要があるアプリケーションに特に適しています。
これらの論文がグラフをファイル システムに保存するために使用している方法は何ですか? 何をメモリにロードする必要があるのか 、またIDが具体的に何を必要とするのかわかりません。 さらに調査が必要な場合は、探すべき主要な機能を指摘すると、これをより明確に理解するのに役立ちます.
これは、SQL と NoSQL (「SQL だけではない」) の両方を使用して、構造化データ、半構造化データ、または非構造化データの大規模なコレクションを管理するためのテクノロジです。 組織は、さまざまなソースからのデータを統合して分析することにより、ビッグデータとソーシャル メディア分析をよりよく理解できるようになります。
グラフ データベースシステムは通常、データ構造に関してリンク リストと同様の構造でデータを格納します。 単なるデータ チェーンではなく、データへの直接リンクが格納されます。
データ型をプライマリ識別子として使用して、API の型システムを定義し、これを使用してGraphQL クエリ言語を使用してクエリを実行します。 GraphQL は既存のコードとデータに支えられているため、特別なデータベースやストレージ エンジンは必要ありません。
グラフのデータはストア ファイルに保存されます。ストア ファイルには、ノード、関係、ラベル、プロパティなど、グラフの特定の部分に関する情報が含まれています。 前述のように、データはこのように分割され、パフォーマンスの高いグラフ トラバーサルを支援します。
グラフ Nosql にデータはどのように格納されますか?
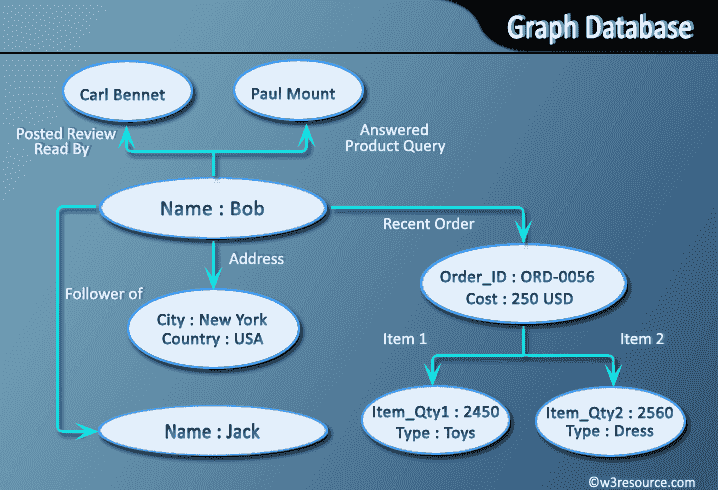
グラフ データベースは NoSQL データベースの一種で、ノード、エッジ、およびプロパティを含むセマンティック クエリにグラフ構造を使用してデータを表現および格納します。
グラフ データベース (NoSQL または SQL とも呼ばれます) は、構造化データ、半構造化データ、非構造化データの大規模なコレクションを格納できるデータベースの一種です。 企業がさまざまなソースからのデータへのアクセス、統合、分析を支援し、ソーシャル メディアやビッグデータ分析を分析できるようにします。 再定義する必要のない NoSQL データベースに新しいデータを追加する前に、再定義する必要はありません。 Web 上のデータを表すために使用される W3C 標準は、グラフ データベースで使用されます。 標準的な手法を使用すると、データの統合、交換、およびデータセット間のマッピングが容易になります。 推論により、組織は新しい知識を追加し、より関連性の高い方法ですべてのデータを表示できるようにすることで、グラフ データベースの能力を高めることができます。 組織は、ソーシャル メディア分析の分野でセマンティック テクノロジと NoSQL の恩恵を受けることもできます。
グラフ データベースが登場してからしばらく経ちますが、ますます人気が高まっています。 それらのデータ ストレージは一意であり、一部のユーザーにとっては価値がある場合があります。 文書化やエンティティ間の関係の優先順位付けなど、従来のデータベースが失敗した問題解決に役立ちます。
グラフ データベースに関しては、MongoDB が適しています。 無料の MongoDB Atlas クラスターがあるため、グラフ データベースのセットアップと使用を可能な限りシンプルにすることが簡単になります。
グラフ データベース: データ ストレージの未来
データは、ノード (人、投稿、コメントなど)、関係 (いいね、共有など)、およびプロパティ (タイムスタンプなど) ごとにグラフ形式で保存されます。 これらのタイプの構造により、データをより簡単に視覚化し、エンティティ間の関連付けをより簡単にすることができます。 グラフ データベースは、相互接続が激しい大量のデータを格納するためにも使用できます。 視覚化を容易にするために、データ間の関係が優先されます。
グラフ データベースは、スタンドアロン データベースとして、現在 NoSQL 形式でのみ利用できます。 一方、MongoDB では $graphLookup 機能を介してグラフ作成を利用できます。 また、ゼロから始めることなく、どこからでもデータを確認できることも意味します。
グラフ データベースはどのように保存されますか?
グラフ データベースは、ノードとエッジの集合であるグラフにデータを格納します。 ノードは人、場所、物などのエンティティを表し、エッジはそれらの間の関係を表します。 たとえば、ソーシャル ネットワークでは、ノードは人を表し、エッジはそれらの間の関係 (友人、家族、同僚など) を表す場合があります。
ネイティブ グラフ データベースは、市場で NoSQL およびリレーショナル データベースの実行可能な代替手段として勢いを増しています。 設計理論によれば、ネイティブ グラフ データベースには幅広い機能が備わっているはずですが、現時点では Neo4j が最も人気があるようです。 すべてのエッジには、エッジ (関係) 行のソースと宛先が含まれます。 インデックスを使用すると、書き込みに費やす時間を減らしながら、データのサイズを増やすことができます。 これらの問題を解決するために、O(log(n) であるネイティブのグラフ ストレージ モデルを使用します。各レコードには、ノードの関係 ID (first_rid) が表示されます。たとえば、エッジ A は両方のノードに関連付けられています 1.
この場合、新しいノード 4 と新しいノード 2 を追加する必要があります。ノード 4 の first_rid、D は、新しいレコードと共にリレーションシップ ストレージに格納されます [図 4 (d)]。 サーバーのコードには、src と dst の 2 つのパラメーターがあります。 図 4 (a) のグラフ ストレージ モデルが更新されました。 データの継続的なブロブは、mmap を使用して Native-Graph 物理ストレージに保存されます。 その結果、連続ブロブの ID * record_size 定数からレコードを直接読み書きできます。 Mmap は、オペレーティング システムとアプリケーションの両方で二重コピーが表示されるのを防ぐため、便利なツールです。
Neo4j のノード レコードの in_use 情報、first_rid、最初のプロパティ ID、および最初のラベル ID を見つけることができます。 ノード。 プロパティ ID とラベル ID は、ノードのプロパティとラベルへの 2 つのポインタです。 同様に、別の方法を使用して、関係レコードの効用を全期間にわたって最大化します。
API ごとに新しいクエリ言語を学習する必要がないため、GraphQL は強力なツールです。 各 API で同じクエリ言語を使用することが最善の解決策です。 このようにして、アプリケーションをより簡単に開発および保守できるようになります。 GraphQL スキーマは、ネットワーク データベースのデータ構造を定義します。 このスキーマのデータ ノードは、それらの間の関係によって表されます。 このため、通常のリレーショナル データベースのデータ構造は、推論によってのみアクセスできます。 GraphQL を使用する API はデータベースではなく、クエリ言語です。 さまざまな種類のデータベースと統合でき、データベースをまったく統合できないため、データベースが存在する場所ならどこでも使用できます。 GraphQL は簡単に使用できるため、API がクエリごとに新しい言語を学習する必要がなくなります。 データをより細かく制御できるため、GraphQL の使用はネットワーク データベースに最適です。 これは、データをカスタマイズできるオプションと柔軟性の数を増やすため、特に重要です。
Neo4j はディスクデータをどのように保存しますか?
Neo4j は、高速な読み取りと書き込み用に最適化された独自の形式でディスク データを保存します。 データは多数のファイルに保存され、各ファイルには一定量のデータが含まれています。 新しいデータがデータベースに追加されると、新しいファイルに保存されます。 データベースからデータが削除されると、ファイルが削除されます。
データ関連ファイルは、data/databases/graph.db (v3.x+) ファイル タイプに配置されている場合、Neo4j データ ディレクトリに配置されます。 フィールドは、キーまたは値のいずれかに保持されます。 文字列または配列が 8B ブロックに収まらない場合は、文字列/配列ストア (128B) のレコードへのポインターがあります。 ディスク データは、リンクされたリスト内のすべての固定サイズ レコードに編成されます。 プロパティは、レコードのリンクされたリストとして格納され、それぞれがキーと値を含み、次のプロパティを指します。 これを例として想像できます: ディスク容量の計算。 このシナリオの初期ステータス。
ノード数は 4M です。 各ノードには、3 つの個別のプロパティがあります。 関係は、2 つ以上の他の関係の形で形成されます。 各関係には 2 つのプロパティ (M) があります。 以下のディスクサイズに対応しています。 ノード 4.000.x15B には 600.000MB のメモリ容量があります。
グラフはどこにデータを保存しますか?
グラフはデータベースにデータを格納します。
データを表現および保存するために、リレーショナル データベースでは実行できない方法で使用されます。 プロパティ グラフでは、データは分析とクエリにリンクされていますが、RDF グラフではデータ統合です。 グラフには、点 (頂点) で構成されるグラフと、それらの点間の接続を伴うグラフの 2 種類があります。 グラフとグラフ データベースは、データ間の関係を表すだけでなく、グラフ モデルの作成にも使用されます。 これらのシステムは、クエリを実行し、グラフ アルゴリズムを適用して、パターン、パス、コミュニティ、インフルエンサー、単一点障害、およびその他の関係を識別することができます。 分析におけるグラフの機能には、洞察を提供する能力、異種のデータ ソースをリンクする能力、および洞察を生成する能力が含まれます。 グラフ データベースには、非常に用途が広く強力な多数の機能があります。
グラフはデータ間の関係を強調するため、さまざまな方法で使用できます。 グラフ分析を使用して、ソーシャル ネットワーク、通信ネットワーク、Web サイト、トラフィックと使用状況、および金融取引とアカウントを調査できます。 グラフ データベースは、さまざまなソーシャル ネットワークの分析に使用できますが、通常はグラフの分析に使用されます。 エンティティ間のトランザクションまたは情報を共有するエンティティから作成されたグラフを使用できます。 グラフ分析は、ボット パターンではなく自然なパターンを識別するために使用できます。 グラフ データベースは、金融業界で不正を検出するための効果的なツールになりました。 不正を検出する最も一般的な方法であるパターン識別は、多くの場合、防御の最前線です。
ユーザーの予想される購入パターンは、場所、頻度、店舗の種類などの要因に影響されます。 ノード間のパターンを理解するグラフ分析の能力は、他の追随を許しません。 データの能力とサイズが増大したため、グラフ データベースは進化してきました。 通常、機械学習は不正行為の検出に使用されますが、グラフ分析はこの取り組みを補完して、より正確で効率的なものにすることができます。 Oracle のコンバージド データベースは、マルチモデル、マルチワークロード、およびマルチテナント環境を処理するように設計されています。

グラフには、利便性に加えて多くの利点があります。 グラフを使用する利点はいくつかあります。 グラフ コンピューティングのもう 1 つの利点は、さまざまな要因に基づいてグラフを計算できることです。 グラフはさまざまな方法で保存できます。 これを行う最も簡単な方法の 1 つは、各エッジのベクトルを保持することです。 これが正しく行われないと、状況は非常に非効率になる可能性があります。 グラフを保存するには、エッジごとにペアを保持することもお勧めします。 これはより効果的ですが、どのエッジが関連しているかを追跡するのが難しい場合があります。 各エッジに構造体を割り当てることで、グラフを格納することもできます。
グラフ データベースの長所と短所
リレーションシップは、グラフ データベースで暗黙的に表すことができます。これは、データを格納する際に大きな利点があります。 探しているデータを直接見つけることができます。 グラフ データベースも、この種の脆弱性に対して脆弱である場合、操作がより困難になる可能性があります。
グラフ データベースは、何かに関連するデータを格納するための最良の選択です。 このカテゴリは、ソーシャル ネットワーキングや科学研究など、あらゆるソースからのデータに適用できます。
グラフ データベース ストレージ
グラフ データベース ストレージは、グラフ データ構造を使用してデータを格納するデータベース ストレージの一種です。 このタイプのストレージは、データ項目間に多くの関係があるデータを格納するのに適しています。 たとえば、ソーシャル ネットワークでは、グラフ データベース ストレージ システムを使用して、ユーザーと他のユーザーとの関係に関する情報を格納できます。
グラフ データベースとリレーショナル データベースの違いは、主にエンティティ間の関係を格納する方法にあります。 グラフ データベースにはデータの事前定義された構造がないため、クエリ中に各レコードを個別に調べる必要があります。 このシステムの列は、データ構造と型に関して非常に柔軟であるという点でテーブルとは異なります。 頻繁にデータを取得する場合は、グラフ データベースが最適なオプションであり、データ取得用に最適化されています。 データが本質的にトランザクションである場合、グラフ データベースの使用を希望する可能性はほとんどありません。 データをより効果的に保存できるため、場合によっては複雑でない分析が必要になる場合があります。 一方、グラフ データベースは柔軟で、スキーマ データベースよりも抽象的です。
データ モデルに一貫性がなく、頻繁に変更する必要がある場合は、グラフ データベースの使用を検討してください。 グラフ データベースを使用すると、開始する特定のポイント、または少なくとも一連のポイントを追跡する必要がある場合に、関係をたどることができます。 グラフ データベースは、相互接続されたデータ管理の分野で強力なツールになり得ます。 グラフ データベースを使用したくない場合は、代わりに単純な識別子 (キー) を使用して単一のノードを返します。 BLOB や CLOB などの非常に大きなデータ セットを格納する必要がある場合、グラフ データベースは最適な選択肢ではありません。 ただし、これらの属性をデータベース内の他のエンティティに接続する必要がある場合は、データベースよりもグラフ データベースの方が有利な場合があります。
テーブルはデータの格納に使用されるため、リレーショナル データベース内のデータ間の関係を表すには、テーブルよりもグラフの方が適しています。 グラフはデータと関係の両方を表し、頂点はオブジェクトを表し、エッジはオブジェクト間の関係を表します。 グラフ データベースは、リレーショナル データベースとは異なり、リレーションシップを中心に全体として構造化されています。
グラフ データベースは、接続性が高いため、大量の相互接続されたデータをかなりの時間で処理できます。 グラフの明確で扱いやすい関係の表現により、理解しやすくなります。 さらに、グラフの柔軟性と俊敏性により、幅広いデータに最適です。
グラフ データベースの欠点の 1 つは、クエリ言語が統一されていないことです。 その結果、ユーザーがデータベースを把握して使用することが困難になる可能性があります。 さらに、関係の表現は理解しにくい場合があります。
グラフ データベースには多くの長所と短所がありますが、その長所は明らかに短所よりも優れています。 その結果、高度に相互接続されたデータを明確で管理しやすい方法で提示する必要があるシステムに適しています。
グラフデータベースとビッグデータの違い
グラフ データベースとビッグ データは同じものであるという一般的な誤解があります。 グラフ データベースでは、データをチャンクに格納する方法に制限はありません。 ノードとリレーションシップがデータの格納に使用されるため、小さなデータ セットをより効率的に管理できます。 グラフ データベースは現在でも使用されていますが、大規模なデータ セットを処理するという点では、従来のリレーショナル データベースよりも効率的です。
リレーショナル データベースへのグラフの格納
リレーショナル データベースにグラフを格納するには、さまざまな方法があります。 1 つの方法は、グラフのエッジをレコードとしてテーブルに格納することです。各レコードには、エッジが接続する 2 つの頂点の ID が含まれます。 もう 1 つの方法は、グラフのエッジをレコードとしてテーブルに格納することです。各レコードには、エッジが開始する頂点の ID、エッジが終了する頂点の ID、およびエッジの重みが含まれます。
ノードとエッジで構成されるデータ構造です。 2 つのノード間の関係を示すエッジを見つけることはよくあります。 ノード間の関係は、データベース内のこれらの関係のトピックです。 テーブルは、さまざまな方法でこの構造を表示できます。 その成長により、NULL 値を含むセルの数が増加します。 スパース テーブルは実装が簡単ですが、単一システム内の多数のエンティティほど効率的ではありません。 場合によっては、運用が行き詰まったり遅延したり、移行に手間がかかる場合があります。
サテライト テーブルの名前は、前に見たスパース テーブルに由来します。 サテライト テーブルには、エンティティの種類ごとに個別のテーブルを持つさまざまなテーブルが含まれています。 データは複数のテーブルに分散されているため、読み取りと書き込みはスパース テーブル設計ほど混雑しません。 移行の影響は拡大していますが、その分布は減少しています。 NoSQL では、ケーキを食べるだけでなく、情報を保存することもできます。 RDS のようなものはなく、データをそのように処理できるスキーマレス クエリ言語のようなものはありません。 DB では、通常のデータは正規化されています。
ほとんどの場合、データへの移行はデータベース レベルで行われます。 一般に、NoSQL データベースはリレーショナル データベースよりもスケーラブルですが、この利点は、多数のデータ セットが関係する場合にのみ実現されます。 適切なパーティション キーの選択は、事前に行う必要があります。 DynamoDB はスループット制限のあるバッチ更新を目的としていますが、MongoDB はデータベースの mapreduce を削減できます。
個々のレコード レベルで関係を保存する利点
リレーションシップは個人レベルで保存できるため、効率が向上します。 データベースがよりタイムリーにレコードにアクセスすると、テーブルを検索する必要がなくなります。
グラフ データベース ストア データ
グラフ データベースはデータをグラフとして格納し、データはノードとエッジとして表されます。 これにより、より柔軟で効率的なデータのクエリと、より強力なデータ分析が可能になります。
グラフ データベースは、高度に相互接続されたデータを持つユーザーが使用することを目的としています。 真のグラフ、トリプル ストア、および従来のデータベースは、3 種類のグラフ データベースです。 Neo4j のグラフ データベースは、組織がデータをより適切に管理するのに役立ちます。 また、組織は AI および機械学習モデルを迅速かつ簡単に進化させることができます。 要素を同時にリンクする必要があり、数秒でアクセスでき、同時に何百万もの関係を照会できる状況に最適です。 データベース内で物理的にリンクされているノードは相互にリンクされているため、関係へのアクセスはデータ自体と同じくらい簡単です。 グラフ データベースの種類ごとに 1 つのソリューションを見つけることはできません。
グラフ データベースの目標は、複雑なデータ モデルとの関係の大規模な動的ネットワークを処理することです。 これらのシステムは、チャットボット、会話型システム、レコメンデーション アルゴリズム、最適化アプリケーション、ルーティング、マップに加えて、データ管理とデータ インテリジェンスに必要です。 アプリケーションがグラフ データベースに対して動作するように構成されている場合、その価値は急上昇します。
多くの人がさまざまな理由でグラフ データベースを使用しています。 これらのシステムの最初の利点は、クエリが簡単な複雑なデータを格納できることです。 さらに、それらは接続されたデータのストレージにおいて非常に汎用性があります。 また、環境の変化にも適応できます。 データベースを選択する際には、以下に示す要因をすべて考慮する必要があります。
グラフ データベースの人気は、さまざまな要因の結果です。
グラフ データベースを使用すると、ユーザーは大量の複雑なデータに簡単にアクセスできます。 複雑なデータは読みにくいことが多いため、これは重要です。 グラフ データベースは、接続されたデータの格納にも適しています。 ノード間の接続は、多くの場合、ノードの成功にとって重要です。 グラフ データベースは、規模の点でも非常に効率的です。 この点で、パフォーマンスを損なうことなく大量のデータを格納できます。
一般に、グラフ データベースに格納されたデータは、複雑な情報を格納するのに適しています。 使い方は簡単で、明確で読みやすいデータ表現を提供します。 接続してデータを保存できるため、優れたデータセンターになります。 最後に、彼らはスケーリングする能力を持っています。
グラフ データベースにドキュメントを保存できますか?
テーブルやドキュメントの代わりに、ノードと関係がグラフ データベースに格納されます。 ホワイトボードにアイデアをスケッチするのと同じ方法でデータを保存できます。
グラフ データベースの利点
グラフ データベースは、従来のデータベースに比べて多くの利点があるため、人気が高まっています。 グラフ データベースは、データベースに外部キーと大規模なデータ セットがある場合により効率的です。 さらに、グラフィカルな方法で簡単にクエリを実行でき、リアルタイムのデータ分析アプリケーションに適しています。
グラフ データベースのユース ケース グラフ データベース
ソーシャル ネットワーキング、不正検出、レコメンデーション エンジンなど、グラフ データベースには多くのユース ケースがあります。 ソーシャル ネットワーキング アプリケーションは、グラフ データベースを使用して、人、場所、物の関係をモデル化し、クエリを実行できます。 不正検出アプリケーションは、グラフ データベースを使用して、金融取引間の関係をモデル化し、クエリを実行できます。 レコメンデーション エンジンは、グラフ データベースを使用して、製品、サービス、および人々の間の関係をモデル化し、クエリを実行できます。
グラフ データベースを使用する場合、安全に保存できるため、データを失う心配はありません。 リレーションシップは、行と列ではなく、行と列のモデルに基づいてデータベースに格納されます。 現代の金融市場は、さまざまな不正行為を懸念しています。 グラフ テクノロジを使用すると、ML ベースの不正検出システムのパフォーマンスが向上します。 会社のデータは、グラフ データベースによってより完全に表すことができます。 アルゴリズムを使用して、グラフやネットワークから有用な洞察を生成できます。 グラフを使用すると、パターンをより迅速かつ効率的に見つけることができます。
グラフ技術、高度なアルゴリズム、人工知能を使用して、治療を設計する能力を向上させることができます。 最も人気のあるソーシャル メディア プラットフォームの多くで使用されているグラフ データベースは、ユーザー インタラクションの分析に使用されています。 この方法の目的は、ボットによって実行されているアカウントを特定できるようにすることです。 グラフ データベースがビジネスに適したソリューションであるかどうか疑問に思っていますか?
グラフ データベースとデジタル資産
グラフ データベースを使用すると、リレーションシップを接続してデータを格納できます。 これらの専門家は、映画やテレビ番組などのデジタル資産を管理する技術の専門家です。