
Hadoop の差別化要因: オープンソースのスケーラビリティとフォールト トレランス
公開: 2022-11-18Hadoop は、コンピューターのクラスター間でビッグ データ セットを分散ストレージおよび処理するためのオープン ソース ソフトウェア フレームワークです。 単一のサーバーから数千台のマシンにスケールアップするように設計されており、それぞれがローカルの計算とストレージを提供します。 高可用性を実現するためにハードウェアに依存するのではなく、フレームワークは、アプリケーション層で障害を検出して処理するように設計されています。 Hadoop は、従来のリレーショナル データベースとはまったく異なるアーキテクチャを使用しているため、nosql データベースです。 Hadoop は水平方向にスケーリングするように設計されています。つまり、クラスターにコモディティ サーバーを追加することで、より多くのデータに対応できるようにスケーリングできます。 また、Hadoop はフォールト トレラントになるように設計されています。つまり、クラスター内のサーバーがダウンしても、システムはそのサーバーなしで機能し続けることができます。
Hadoop はデータの保存には使用されず、リレーショナル ストレージを使用する必要もありません。 むしろ、分散サーバーに大量のデータを格納するために使用されます。 Hadoop データベースは、大規模な並列コンピューティングを可能にするソフトウェア システムではなく、一種のデータです。 これは NoSQL データベース (HBase など) のバインディング タイプであり、ユーザーはバインドされたさまざまなデータベースに対してクエリと検索を行うことができます。 RDBMS は現在の形では、相対データとトランザクション データの両方を管理できるため、Hadoop と競合することはできません。 Hadoop は、構造化、半構造化、非構造化を問わず、あらゆるタイプのデータを処理する機能を備えており、幅広い方法をサポートしています。 ビッグデータ分析は、より深い洞察を提供することで、企業に現実世界の競争上の優位性をもたらしています。 サービスとしての Hadoop は、データ処理におけるオンライン分析処理 (OLAP) の使用をサポートします。 データ処理速度は、データ要求の数によって決まることに注意してください。 たとえば、ACID トランザクションや OLAP サポートが必要ない場合は、Hadoop を使用できます。
Hadoop とインメモリ データベースは、重複する 2 つのまったく異なるテクノロジです。 それらは同じではありませんが、いくつかの点で一致しています。
SQL-on-Hadoop を使用する分析アプリケーションは、確立された SQL スタイルのクエリ メソッドを新しい Hadoop データ フレームワーク要素と組み合わせます。 SQL-on-Hadoop を使用すると、エンタープライズ開発者とビジネス アナリストは、SQL の使い慣れたクエリを使用して Hadoop クラスターで共同作業を行うことができます。
これは、データの保存と取得の手段を提供する NoSQL データベースです。 非リレーショナル/非 SQL は、この分野で一般的に使用される用語の 1 つです。
データは、Hadoop と SQL によってさまざまな方法で管理されます。 SQL はプログラミング言語ですが、Hadoop はソフトウェア内のコンポーネントのフレームワークです。 どちらのツールもビッグ データに役立ちますが、欠点があります。 Hadoop プラットフォームは、はるかに大きなデータ セットを処理できますが、データを書き込むのは 1 回だけです。
Hadoop と Nosql の違いは何ですか?
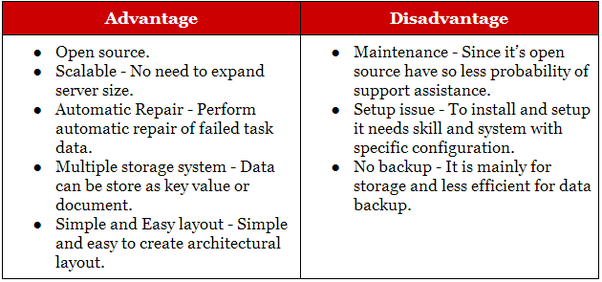
Hadoop は分析および履歴アーカイブ アプリケーションに適していますが、NoSQL はリレーショナル アプリケーションを補完する運用ワークロードに最適です。 NoSQL データベースはキー値ストア データベースとして始まりましたが、後に document/json およびグラフ データベースがそれらに加わりました。
リアルタイム処理、大規模データ、および非構造化データは、NoSQL テクノロジを使用できるシナリオのほんの一部です。 その結果、スケーラビリティや可用性など、これらの課題の一部に対処できます。 NoSQL データベースには、従来のリレーショナル データベースに比べて多くの利点があります。 以前よりもはるかに高速でスケーラブルな方法でデータ セットを処理できます。 また、データベース管理システムは、従来のデータベースよりも知識や専門知識が少なくて済むため、使いやすくなっています。 NoSQL データベースには、従来のリレーショナル データベースに比べてさまざまな利点があります。 考慮すべき最も重要なことは、リアルタイム処理と大規模なデータ セットにそれらが必要かどうかです。
Nosql データベースは、ビッグデータのワークロードを扱うビジネスにとってより良い選択です
データ ワークロードが、ビッグ データなどの大量の多様で構造化されていないデータの分析と処理に重点を置いている場合は、NoSQL データベースを選択することをお勧めします。 リレーショナル データベースとは対照的に、NoSQL データベースは固定スキーマ モデルに依存しません。 RDBMS は、データの保存、処理、および管理の点で従来の RDBMS よりも柔軟であるため、大量のデータに迅速にアクセスし、それを無期限に保存する必要がある企業にとって、より優れた選択肢となります。
ビッグデータは SQL ですか、それとも Nosql ですか?

データ ワークロードが主に、ビッグ データなどの大量のさまざまな非構造化データの迅速な処理と分析に関係している場合は、NoSQL が最善の策です。 NoSQL データベース モデルは、リレーショナル データベースと同じスキーマ構造に依存しないという点で独特です。
ビッグデータが製造業を改善するかどうかはもはや問題ではありません。 それはいつの問題です。 ビッグデータでは、膨大で多様かつ複雑な量の構造化データと非構造化データが利用可能です。 製造現場のセンサー、カメラ、消費者向けデバイスはすべて、製造におけるビッグ データの収集に使用できます。 製造業のデータのほとんどは構造化されていないため、NoSQL アーキテクチャは SQL のような厳格なアプローチと競合することはできません。 NoSQL データベースでは、同じデータベース テーブルにデータを格納するためにスキーマが必要ないため、ユーザーはさまざまな構造でデータを格納できます。 企業の境界線は、使用する予定のデータ量によって決まります。 トランザクションは、リレーショナル データベース トランザクションと見なされるために、4 つの基本的な運用原則に従う必要があります。
NoSQL システムとクラウド システムは統合できるため、クラウド コンピューティング フレームワークを使用して NoSQL システムをサポートすることをお勧めします。 NoSQL によるリアルタイムの製造プロセスの最適化は、製造実行システム (MES) との統合によって実現できます。 この成功は、ビッグデータ分析を使用して変化する状況により迅速に対応することによって可能になりました。 MongoDB はセットアップが簡単で、分析に使用できるため、優れた NoSQL データベースです。 NoSQL などの高速応答データベース アーキテクチャを使用することで、経営陣はより優れたシミュレーションを実行できるようになり、現実世界でより優れた製品決定を行うことができます。 B2B データベースは、クロスサイト攻撃、インジェクション攻撃、ブルート フォース攻撃に対して脆弱です。 インジェクション攻撃は、攻撃者が NoSQL クエリ コマンドまたはストレージ ステートメントにデータを追加するときに発生します。

製造部門は、NoSQL アーキテクチャのセキュリティに特に関心を持っています。 サービス拒否攻撃またはインジェクション攻撃が成功した場合、メーカーは仕様を変更できる可能性があります。 このため、競合他社は競争の激しい市場で優位に立つことができます。
企業が顧客のニーズに対する効率性と応答性を改善する方法を模索するにつれて、リアルタイム データに依存するビジネス プロセスがより一般的になりつつあります。 Cloud Bigtable などのクラウドベースの NoSQL データベースは、大規模なデータ セットを格納してアクセスするための迅速かつ効率的な方法を提供するため、これらのタイプのアプリケーションにとって優れたソリューションとなります。
Cloud Bigtable は、フルマネージドの NoSQL データベース サービスであり、99.999% のアップタイムを提供します。 データフィード速度が速く、スケールアップとスケールダウンが簡単であるため、分析および運用ワークロードに最適です。 その結果、モバイル ゲームや小売り分析などのアプリケーションでのリアルタイム データ処理に最適です。
Nosql は大規模データに最適なデータベースですか?
たとえば、MongoDB は、大量のデータを格納するための優れた選択肢です。 それらは、幅広い高性能で機敏な処理シナリオを可能にします。 さらに、非構造化データは、複数の処理ノードおよび複数のサーバー上の NoSQL データベースに格納されます。 その結果、NoSQL データベースは、世界最大のデータ ウェアハウスの一部でデフォルトの選択肢となっています。 大規模データに最適なデータベースはどれですか? この質問に関しては、組織のニーズがさまざまであるため、大規模データに最適なデータベースを予測することはできません。 Amazon Redshift、Azure Synapse Analytics、Microsoft SQL Server、Oracle Database、MySQL、IBM DB2、およびその他の多くのデータベースは、大規模なデータ ストレージの最も一般的なオプションです。
Hadoop はデータベースですか
Hadoop は、コモディティ ハードウェアの大規模なクラスター上でアプリケーションを実行するための分散ファイル システムおよびフレームワークです。 Hadoop はデータベースではありません。
オープンソース フレームワークである Hadoop を使用すると、大量のデータ セットを効率的に保存および処理できます。 Hive テーブルと Imperative テーブルは、HDFS のテキスト ファイルを使用して作成できます。 シーケンス ファイル、Avro データ ファイル、Parquet ファイルの 3 つの主要なファイル形式をサポートしています。 一連のバイトは、メモリ単位としてデータのシリアル化によって表されます。 効率的なデータのシリアル化フレームワークである Avro は、Hadoop とそのエコシステムによって広くサポートされています。
Hive および Implicit テーブルのストレージ形式としてテキスト ファイルを使用すると、データの管理と操作が簡素化されます。 そのため、バッチ処理やさまざまな形式でのデータの保存に適しています。 さらに、Avro を介したデータのシリアル化により、効率的かつ便利なデータの保存と取得が可能になります。 その結果、さまざまな形式でデータを保存したり、並列処理を実行したりするのに適したオプションです。
Hadoop 対 Nosql
Hadoop は、コモディティ ハードウェアのクラスターのビッグ データを処理します。 機能がニーズを満たさない場合や機能しない場合は、変更することができます。 これは NoSQL と呼ばれ、構造化データ、半構造化データ、非構造化データを格納するデータベース管理システムの一種です。
NoSQL (Not Only SQL) データベースとしての MongoDB は、C++ 開発の結果として 2007 年に作成されました。 Hadoop は、大規模なデータ処理のために主に Java で記述されたオープンソース ソフトウェア プログラムの集まりです。 このプラットフォームには、全文検索、高度な分析ツール、使いやすいクエリ言語も含まれています。 Hadoop は、大量のデータを保存および処理できることで最もよく知られていますが、小さなバッチでも処理できます。 MongoDB は、さまざまなリアルタイム データ処理ツールを提供します。 Kafka や Spark などの外部ツール用の MongoDB のコネクタを使用すると、データの取り込みと処理が簡単になります。 データ処理に関しては、Hadoop と MongoDB は従来のデータベースよりも幅広い利点を提供します。 Hadoop は、その分散ファイル システムにより、大規模なデータ構造を処理するための優れたツールです。 MongoDB は、従来のデータベースの代わりとして使用できる唯一のデータベースです。
SparkはNosqlデータベースですか
ドキュメントでは、NoSQL DataFrame は、データを格納するための Spark 形式に基づく Spark DataFrame であると記載されています。 以前のデータ ソースとは対照的に、これはデータのプルーニングとフィルタリング (述語のプッシュダウン) をサポートしているため、Spark クエリはより少ないデータをクエリし、必要に応じて必要なデータのみを読み込むことができます。
アプリケーションで Apache Spark と NoSQL データベース ( Apache Cassandraと MongoDB) を一緒に使用する場合は、戦術的な認識を維持することが重要です。 このブログでは、NoSQL アプリケーションで Apache Spark を使用する方法に焦点を当てています。 TCP/IP sPark の CassandraLand と MongoLand は、最も人気のある 2 つの乗り物で、テーマ パークが好きな人には最高の場所です。 エネルギー省のデータを検索しているときに、Spark アプリケーションが回転し始めました。 ここでは、クエリに関して Cassandra キー シーケンスがいかに重要であるかについて簡単に説明します。 CassandraLandにはPartitionerジェットコースターもあります. ジェットコースターを楽しんでいるお客様は、乗り物オペレーターと情報を共有して、毎日誰が乗ったかを追跡できます。
MongoDB レッスン 1 の最初のレッスンは、MongoDB 接続を適切に管理することです。 エネルギー省の新しい公園メンバーシップ ステータスに関する情報を更新する必要がある場合、Mongo インデックスは非常に役立ちます。 MongoDB または Spark のお客様は、システムの更新に備えて適切な接続とインデックスを維持する必要があります。