
HDF5 データ形式: 大規模なデータ コレクションを格納および管理するための魅力的なオプション
公開: 2023-02-13HDF5 は、大規模で複雑なデータ コレクションを格納および管理するために設計されたデータ形式です。 科学および工学用途で頻繁に使用されており、その人気は近年高まっています。 HDF5 はデータベースではありませんが、ファイル システムに似た階層形式でデータを格納するために使用できます。 これにより、HDF5 は、大量のデータを保存および管理する必要があるアプリケーションにとって魅力的なオプションになります。
HDF5 および netCDF4 ファイルからメタデータと生データを抽出し、Hadoop ストリーミングを使用して、Hadoop Distributed File System (HDFS) HDF5 Connector Virtual File Driver (VFD) を使用して Hadoop データを分析できます。
Hdf5 はデータベースですか?
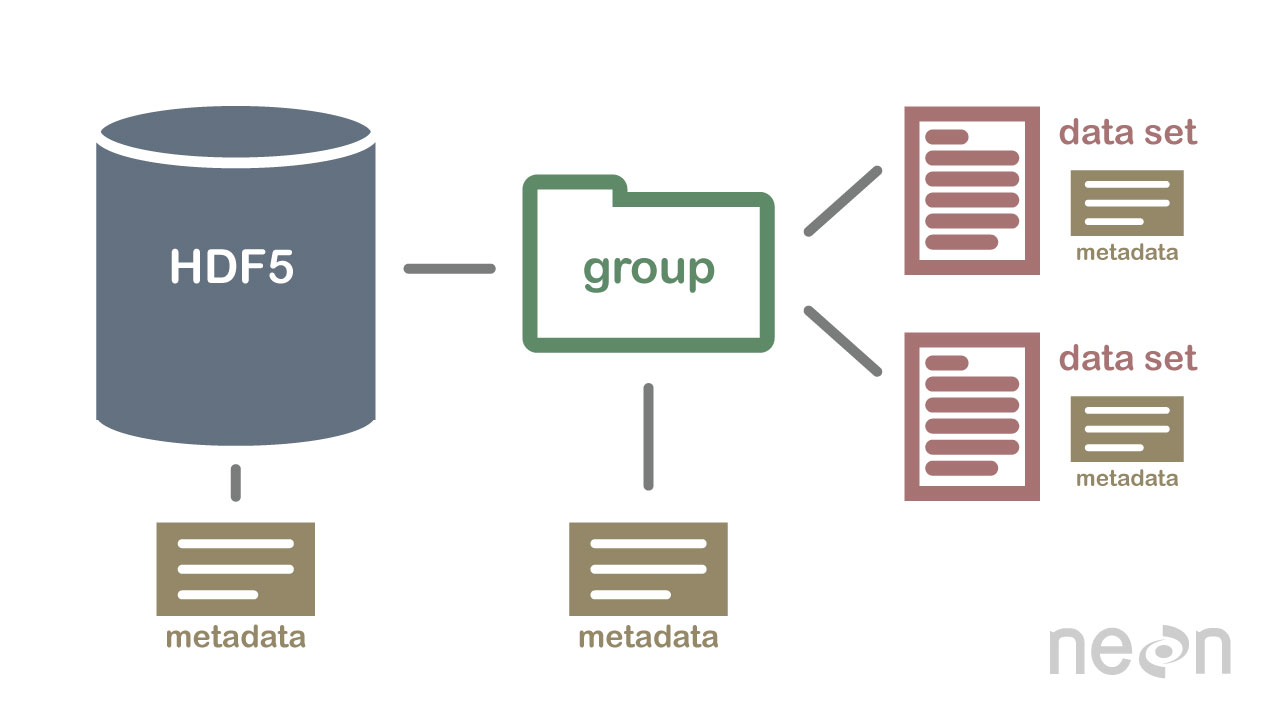
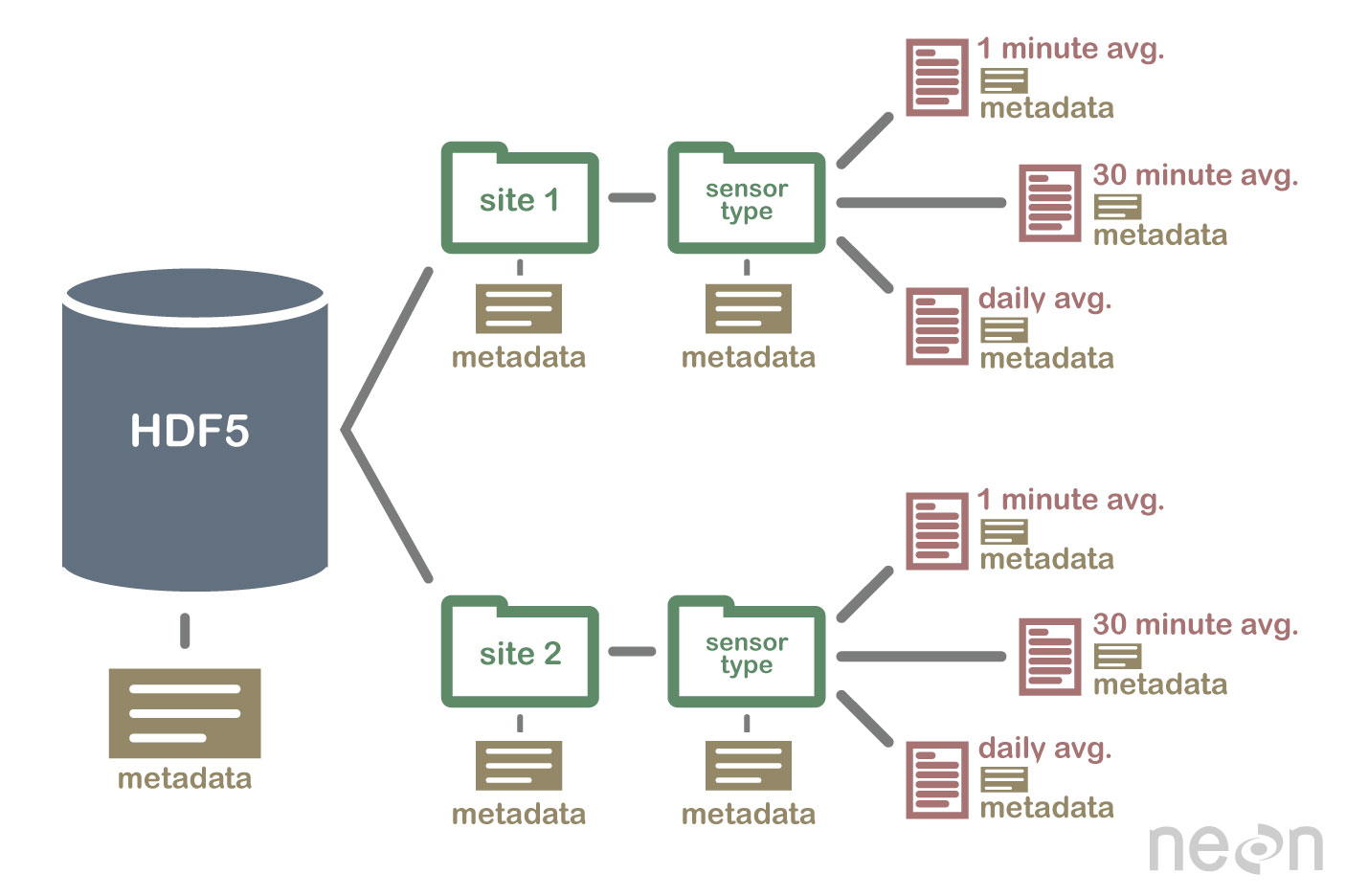
HDF5 はデータベースではありませんが、ファイル システムと同様に、データを階層構造に格納するために使用できます。 HDF5 は、テキスト、画像、バイナリ データなど、さまざまな形式でデータを格納するために使用できます。
階層形式 (HDF5) のデータは、科学研究に非常に役立ちます。 HDF5 ファイル システムは、非常に効率的であるという点でファイル システムに似ているため、優れた形式です。 この形式でエンコードされたデータに関しては、アクセスするのが難しい場合があります。 このガイドでは、Apache Drill を使用して HDf5 データセットに簡単にアクセスしてクエリを実行する方法について説明します。 Drill は、defaultPath オプションを介して個々の HDF5 ファイルにアクセスできます。 これは、クエリ時に table() 関数を直接実行するか、構成を介して実行することによって実現されます。 このクエリの結果は、次の表で確認できます。 その後、Drill は列を選択し、それらを個別にフィルター処理したり、フィルター処理したり、集計したり、クエリ可能な他のデータと組み合わせたりできます。
HDF5 仕様では、データ配列を格納するためのファイル形式が定義されています。 データ配列は、文字列、浮動小数点、複素数、整数データなど、あらゆるタイプのデータで構成できます。 配列には、任意のサイズのデータを含めることができ、任意の形状にすることができます。 HDF5 では、データセットを作成するために、最初にヘッダー ファイルを作成する必要があります。 ヘッダー ファイルには、データセットとメタデータに関する情報が含まれています。 ヘッダー ファイルには、データセットの名前とデータセットのバージョン番号という 2 つの重要な情報が含まれています。 データ配列は、データセットのデータを格納するために使用されます。 ブロックは、データ配列内のデータで構成されます。 データ配列では、データの各ブロックに連続したデータ セットが含まれます。 データセットのブロック数は、データセット内のバイト数によって決まります。 HDF5 仕様に従って、さまざまな方法でデータにアクセスできます。 インデックス作成方法は、データセット内のデータを取得するために最も一般的に使用されます。 これらのメソッドを使用すると、アクセスしたいデータ配列内のブロックの名前を入力して、データにアクセスできます。 構造メソッドを使用して、データセット内のデータにアクセスできます。 これらのメソッドを使用すると、データ配列の構造を使用してデータにアクセスできます。 次の例では、構造体メソッドのオフセットと長さの値を使用して、データ配列内のデータにアクセスできます。 データセットからデータを取得する別の方法は、関数メソッドを使用することです。 データのヘッダー ファイルで関数を選択することにより、いずれかの方法を使用してデータを取得できます。 データ配列にアクセスする方法は、配列のデータ配列要素としてヘッダー ファイルの値を定義することによって使用できます。 最後に、アクセス メソッドを使用してデータセット内のデータにアクセスできます。 これらの方法を採用することで、ヘッダーファイルに設定されたアクセス権を使用してデータにアクセスできます。 つまり、読み取り権限を使用すると、アクセスメソッドを介してデータ配列内のデータにアクセスできます。 HDF5 仕様を使用して、さまざまな方法でデータを作成および使用できます。 create メソッドは、データセットを作成するための最も一般的な方法です。 create メソッドを使用すると、データセットの名前とデータセットのバージョン番号を入力して、データセットを作成できます。 HDF5 仕様に加えて、データセットの使用はさまざまな方法で実現できます。 最も一般的に使用される方法。
Hdf5 はリレーショナル データベースですか?
HDF5 はリレーショナル データベースではありません。

Graphql は Nosql または Sql ですか?
GraphQL の主な目標は、型システムを使用してデータをより高速かつ効率的に返すことです。 SQL (構造化クエリ言語) は、表形式またはリレーショナル データベース システムにデータを格納するために広く使用されている古い言語です。 API を NoSQL データベースの上に構築する場合は、GraphQL を使用することをお勧めします。
Type Mismatch は、Herman Camarena と Roger Cochrane によって作成された GraphQL および NoSQL データベースです。 GraphQL を使用すると、NoSQL システムではなく型システムが導入され、NoSQL システムによってもたらされる柔軟性が失われる可能性があります。 GraphQL コレクションには、構造が一貫しており、いくつかの例外を含むさまざまなドキュメントが含まれています。 GraphQL には、バックエンドのタイプに一致する一連のデータ タイプが組み込まれているため、開発者は作成するデータ タイプを選択できます。 GraphQL は、その可能性を完全に実現するために、型の不一致の問題に対処する必要があります。 その機能に関しては、多くの利点があるため、低レベルのミスマッチ ソリューションを提供します。 このジョブは、StepZen の JSON2SDL などのツールを使用してますます自動化されています。
SQL は、より回復力があり効率的なアプリケーションを作成するために使用できる強力なツールですが、SQL は代替手段ではありません。 メンテナンスに関しては、一部のタスクがより困難になるため、これはマイナスの影響を与える可能性があります。
Graphql: あらゆるデータベースのクエリ言語
GraphQL クエリ言語を使用すると、クライアントとサーバーが相互に通信できます。 GraphQL インスタンスは、データ ソースまたは永続的な状態から変更を取得して永続化できます。 リゾルバーは、データへのアクセスと操作に使用される一連の任意の関数です。 API はさまざまなデータベースで利用でき、GraphQL はどのデータベースでも使用できます。 MongoDB データベースは、さまざまな種類のデータにとらわれない一般的なデータ ソース データベースです。
Nosql は B ツリーを使用しますか?
NOSQL データベースはリレーショナル モデルに基づいていないため、B ツリーを使用しません。 NOSQL データベースは、多くの場合、キーと値のペア、ドキュメント ストア、またはグラフ データベースに基づいています。
B ツリーは、MongoDB のデフォルトのインデックス構造です。 データ ストレージでは、B ツリーの方が効率的な方法です。 整数と文字列を一緒に使用すると、データを整理できます。 そのため、大量のデータを含むデータベースでは、それを使用することを検討する必要があります。 B ツリーは多くのスペースを占める可能性があるため、効率的なモデルです。 これは、大量のデータを保持する必要があるデータベースに役立ちます。 B ツリーは、特定の方法でデータを整理する必要があるデータベースにも適しています。
Bツリーを使用するデータベースは?
これは長い間存在しており、幅広いデータベースで使用できます。 NoSQL データベースは、B ツリー エンジンに加えて、B ツリー エンジンの上に構築できます。 たとえば、MongoDB は B ツリーのデータにインデックスを付けます。 DBMS のアルゴリズムは、リレーショナル データベースの場合と同じですが、いくつか例外があります。 文字列と整数を使用して、B ツリー内のデータを編成できます。
B ツリーを使用するデータベースはどれですか? 次の記事の Mysql は、Btree と B+tree の両方を採用しています。 SQL Server は、キーベースの永続データに基づくインデックスを BTree の形式で格納します。 その結果、このようなツリーの各ノードは 1 つのページとして表示されます。