
カラムナ データベースの長所と短所
公開: 2022-11-19NoSQL データベースは、多くの最新のアプリケーションにとって優れた選択肢ですが、切り替える前に考慮すべき重要な点がいくつかあります。 重要な要素の 1 つは、リレーショナル データベースが必要かどうかです。 その場合、カラムナ データベースは適切な選択ではない可能性があります。 カラム型データベースは、大量のデータを迅速に分析する必要があるアプリケーションに適しています。 また、完全なリレーショナル モデルを必要とせず、より単純なデータ モデルで対応できるアプリケーションにも適しています。 ただし、カラム型データベースにはいくつかの欠点があります。 リレーショナル データベースよりも使用が難しく、必要なすべての機能がサポートされていない可能性があります。 カラムナ データベースがアプリケーションに適しているかどうかを判断する前に、長所と短所を理解しておいてください。
カラム型データベースは、行ではなく列ごとにデータを整理して保存します。 集計関数と操作を使用して、データ列を最適化します。 データベース列は、他のタイプのデータベースと比較して、スケーラブルであり、よく圧縮されます。 カラム型データベースでは、データの各行は、複数の列によって複数の列に分割されます。 カラムナ データベースは、ビッグ データ処理、ビジネス インテリジェンス (BI)、および分析に適しています。 行操作は、列操作よりもはるかに時間がかかります。 IoT レコードには、新しいレコードが一貫したストリームで到着するため、少数のデータ要素しか含まれない場合があります。 ビッグ データは、運用データベース システムの動作方法を変革する可能性を秘めています。
行と列の 2 種類のデータベース データベースは、SQL などの従来のデータベース クエリ言語を使用してデータをロードし、クエリを実行できます。 多くの場合、行データベースや列データベースなどのデータベース バックボーンは、共通データの抽出、変換、読み込み、ツール作成のエンジンとして機能します。
データベース管理システム (DBMS) の一種であるカラムナ データベースは、行ではなく列にデータを格納するデータベースです。 クエリの戻りを高速化するために、カラムナ データベースの列は、ハード ディスクから効率的に読み書きできます。
今日は、カラム型データベースでカラムがどのように機能するかを見て、従来の行指向のデータベース (MySQL など) と比較します。 この記事では、列型データベースとは何か、およびその利点と欠点について説明します。
NoSQL データベースの例は何ですか? Microsoft SQL Server は、Microsoft によって作成されたリレーショナル データベース管理システムです。
Mongodb は列指向データベースですか?
Mongodb はカラムナ データベースではありません。
分析クエリのクエリ パフォーマンスが向上するため、より一般的になってきています。 列データベースのデータは、データが列に格納されるため、データベース ベースのデータ ストアよりも効率的な方法で格納されます。 カラムナ データベースで実行される分析クエリには、パフォーマンス上の利点があります。 行指向のストレージと比較すると、列指向のストレージは、ストレージ スペースとクエリ パフォーマンスの点ではるかに効率的です。 データは列形式で格納されるため、データの読み取りと書き込みがより簡単になります。
Nosql データベースとは?
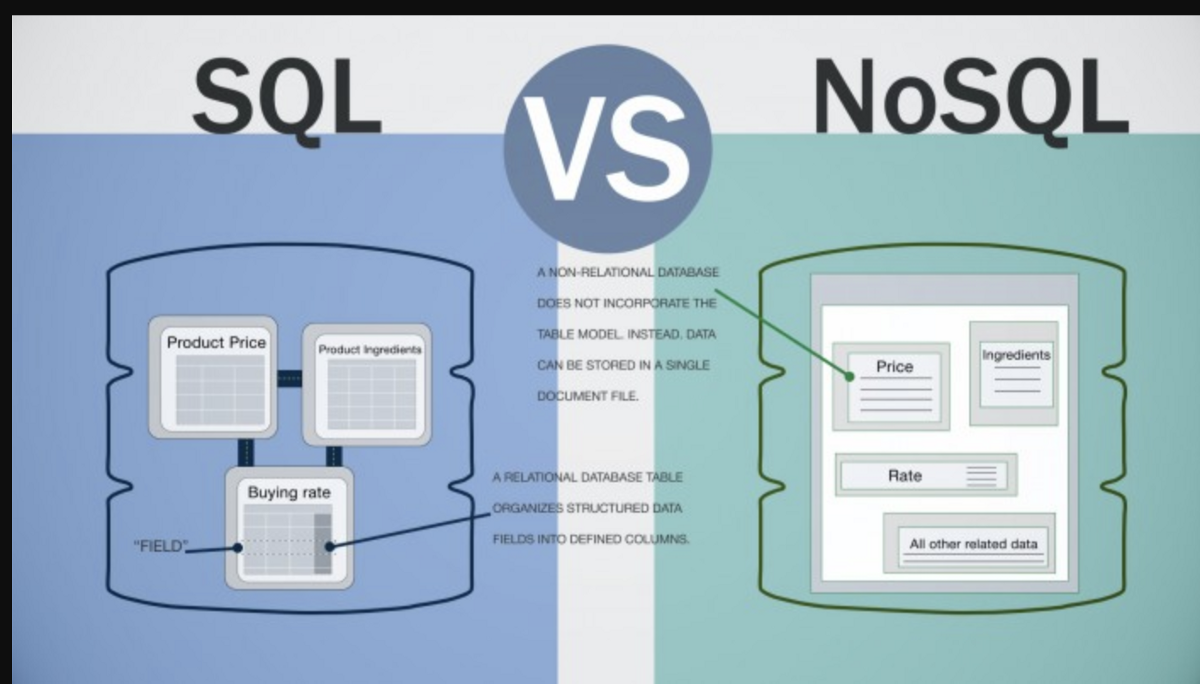
NoSQL データベースは、従来のリレーショナル データベース モデルを使用しないデータベースです。 代わりに、ドキュメント、グラフ、キー値、カラムナなど、さまざまなモデルを使用します。 NoSQL データベースは、多くの場合、リレーショナル モデルにはあまり適していない大量のデータの処理に適しています。
NoSQL システムは、SQL に基づいていないタイプのデータベースです。 データ モデリング チームが使用するデータ モデルは、リレーショナル データベース管理システムで使用される従来の行と列のテーブル モデルとは異なります。 NoSQL データベースは、互いに大きく異なるだけでなく、互いに大きく異なります。 ドキュメント データベースは通常、最も一般的なドキュメント タイプのスケールアウト アーキテクチャで実装されます。 e コマース プラットフォーム、取引プラットフォーム、モバイル アプリ開発はすべて、これらのプラットフォームが企業にどのように役立つかを示す例です。 MongoDB と Postgres を比較する主な目的は、主要な NoSQL データベースの詳細な比較を提供することです。 単一の列の値を集計する列データベースの機能は、特定の列を迅速に分析するのに理想的です。
データが書き込まれる方法は一貫性を維持するのが難しいため、さまざまなソースに依存する必要があります。 グラフ データベースは、データ要素間の接続をキャプチャして検索するために最適化されており、それらをキャプチャして検索します。 これらのメソッドを使用すると、SQL で複数のテーブルを結合することに伴うオーバーヘッドがなくなります。
MongoDB は通常、コレクションと呼ばれるコレクションにドキュメントを格納します。 何らかの側面で相互にリンクされた文書の集まりです。 コレクション内のデータは通常、データを格納するために複数のアプリケーションで使用されます。
MongoDB のデータは B ツリーに格納されます。つまり、バケットまたはレベルとして編成されます。 バケットは、ブラウザによって頻繁にアクセスされるデータのコレクションです。 より多くのバケットがあるため、レベルが大きくなります。 B-tree のデータは、キーで昇順にソートできます。
MongoDB はスケーリングが非常に簡単であるため、スケーリングのための優れたプラットフォームです。 クラスターの負荷が増加した場合は、サーバーを追加する必要がある場合があります。 さらに、MongoDB をクラスター化して、HA (高可用性) データを提供できます。
Nosql データベースが人気を集めている理由
多くの場合、NoSQL データベースの人気が高まっているという事実にもかかわらず、NoSQL データベースは依然としてリレーショナル データベースの代替手段です。 大規模なグラフや定期的に変更されるデータなど、リレーショナル データベースに格納できないデータは、特に魅力的です。
Nosql カラムナ データベースの例
カラムナ データベースは、行ではなく列にデータを格納するデータベース管理システム (DBMS) です。 列指向のシステムは、多くの場合、従来の行指向のシステムよりも分析ワークロードが高速です。
たとえば、列データベースには従業員データが格納され、各列には従業員 ID、名前、役職、給与などのデータが含まれます。 行指向のデータベースは、各行に従業員の ID、名前、役職、給与などを含む同じデータを格納します。
NoSQL は、高度に専門化されたシステムや時間のかかるシステムが不要になるため、リレーショナル データの分野における重要な進歩です。 ドキュメント、グラフ、列、および行値の NoSQL データベースは、4 つの主要なタイプです。 ドキュメント ストアには、複雑なデータ スキーマと連想キー ペアの両方が含まれています。 データベース列は、データを列に編成し、リレーショナル データベースと同じように機能します。 列データベースでは、水平から無限までのグリッド スケーラビリティが利用できます。 圧縮はよくできた保存方法であり、列ストアは多くの保存領域を提供します。 集計クエリの実行速度は、通常、リレーショナル データベースよりも高速です。
データ設計の水平方向の性質のため、OLTP アプリを列型ストアと組み合わせて使用することはできません。 ソリューションとしての列ストアは、非常に強力になる可能性がありますが、非常に制限される可能性もあります。 列は行よりも一貫性と分離の保証が少なくなりますが、各行は複数回書き直す必要があります。 NoSQL データベースは、ネイティブ セキュリティ機能がないため、オンライン攻撃に対してより脆弱です。 サイバーセキュリティが最優先事項である場合は、リレーショナル モデルを使用するか、スキーマを定義する必要があります。
Nosql データベース
NoSQL データベースは、従来のテーブルベースのリレーショナル データベース モデルを使用しない非リレーショナル データベースです。 NoSQL データベースは、ビッグ データやリアルタイム Web アプリケーションによく使用されます。
データベース NoSQL データベースは、従来のリレーショナル データベースにデータを保存しません。 ドキュメント タイプ、キー値タイプ、ワイドカラム タイプ、およびグラフ タイプが最も一般的です。 近年、データを保存するコストが劇的に低下したため、NoSQL データベースが開発されました。 大量の非構造化データを保存できるため、開発者は保存するデータの側面を選択できます。 ドキュメント データベース、キー値データベース、ワイド カラム ストア、およびグラフ データベースは、NoSQL データベースの例です。 結合が不要なため、クエリはより高速に実行されます。 財務分析やスマートな猫用トイレからの IoT 読み取りなどのデータ集約型のユース ケースを使用できますが、スマート フード パッケージなどの楽しくて面白いユース ケースなどのあまり深刻ではないアプリケーションも使用できます。
このチュートリアルでは、NoSQL データベースを検討すべき時期と理由について説明します。 さらに、NoSQL データベースに関する最も一般的な誤解のいくつかを見ていきます。 DB-Engines によると、MongoDB は世界で最も人気のある NoSQL データベースです。 このチュートリアルでは、コンピューターに何もインストールせずに MongoDB データベースにクエリを実行する方法を学習します。 データベース クラスタは、MongoDB データベースの一例です。 クラスターが作成されるとすぐに、Atlas はデータの保存を開始します。 Atlas Data Explorer、MongoDB Shell、または MongoDB Compass でデータベースを作成するには、手動または自動の 3 つのオプションがあります。
この場合、Atlas のサンプル データセットがインポートされます。 NoSQL データベースには、柔軟なデータ モデル、水平方向のスケーリング、超高速のクエリ、使いやすさに加えて、多くの利点があります。 データ エクスプローラーを使用して、新しいドキュメントの挿入、既存のドキュメントの編集、および削除を行うことができます。 集計フレームワークの使用は、データを分析するための非常に強力なツールです。 Atlas と Atlas Data Lake に保存されているデータをチャートで視覚化するのが最も簡単な方法です。
キー値データベースは、キーと値を含む複数のテーブルを持つ最も単純なタイプの NoSQL です。 キーはデータ アクセスにのみ必要なため、読み取りと書き込みが簡単になります。 ただし、データベース内の各キーは一意である必要があるため、このタイプのデータベースは大規模なデータ セットには適していません。
データは、列ベースのデータベースのキーと値を格納する列を含むテーブルに格納されます。 汎用性があるため、列ベースのデータベースは、列を持たないデータベースよりも長期間データを保存できます。
ドキュメント データベースは、列データベースとは対照的に、キーと値を格納する列を持つテーブルにデータを格納します。 一方、ドキュメントベースのデータベースは、電子メールと同様にデータをファイルに保存します。 ドキュメントは読みやすく理解しやすいため、データを簡単に検索して表示できます。
グラフベースのデータベースは、キーと値を持つ列を含むテーブルにデータが格納されるという点で、ドキュメント ベースのデータベースに似ています。 対照的に、データストレージの点でネットワークに似ているグラフは、グラフベースのデータベースに格納されます。 データノードを接続し、パターンを簡単に識別できます。
あらゆるニーズに対応する Nosql データベース タイプ
MongoDB などのドキュメント データベースは、情報を柔軟なモジュール形式で格納する必要があるアプリケーションに適しています。 MongoDB では、JSON、テキスト、および BSON がすべてサポートされています。 これにより、大量の非構造化データを保存するブログや Wiki などのアプリケーションに最適です。
Cassandra およびその他の列ベースのデータベースは、大量のデータを列形式で格納する必要があるアプリケーションに最適なオプションです。 HBase 内のテキストベースのストレージに加えて、Avro や Cassandra 独自のバイナリ形式などのデータ形式を使用できます。 リレーショナル データベースに収まらないデータを格納できる容量があるため、大量のデータを必要とするアプリケーションに適しています。
DynamoDB およびその他のキー値データベースは、通常、少量から中量のデータを保存するアプリケーションに適しています。 たとえば、DynamoDB は JSON およびバイナリ データ形式をサポートします。 これは、リレーショナル テーブルには小さすぎて頻繁にアクセスされるが特定の形式を必要としないデータを格納するアプリケーションや、頻繁にアクセスされるが特定の形式を必要としないデータを格納する必要があるアプリケーションにとって優れた選択肢となります。フォーマット。
Neo4j などのグラフ データベースに格納されているデータ項目の統合を必要とするアプリケーションに適しています。 たとえば、グラフ データベースでは、JSON、Atom、Graph などのデータ形式を使用できます。 複雑すぎてリレーショナル データベースに格納できないデータを格納する必要があるアプリケーションや、頻繁にアクセスされるが特定の形式で格納する必要がないデータを格納するアプリケーションに最適です。

オープンソースのカラムナ データベース
カラムナ データベースは、行ではなく列にデータを格納するタイプのデータベースです。 このタイプのデータベースは、従来の行ベースのデータベースよりも優れたパフォーマンスとスケーラビリティを提供できるため、データ ウェアハウジングおよび分析アプリケーションによく使用されます。
Apache Cassandra、Apache HBase、Apache Drill など、利用可能なオープン ソースの柱状データベースが多数あります。 これらのデータベースにはそれぞれ独自の長所と短所があるため、特定のニーズに適したものを選択することが重要です。
これらのデータベースは、高速で同時にスケーリングできるため、効率的な分析ワークフローに最適です。 行にデータを格納する代わりに、カラムナ データベースでは列が使用されます。 列ベースのストレージを使用すると、I/O の試行回数が大幅に減るため、データベース クエリのパフォーマンスが向上します。 これは、Amazon Redshift と Snowflake、およびその他のリレーショナル ウェアハウスを強化するために使用されています。 カラムナ データベースのスループットを向上させるために、低コストのハードウェア クラスターを使用してそれらをスケーリングします。 従来のデータベースでは、行はデータのさまざまなセクションに分割されています。 カラムナ データベースの最も関連性の高い要素には、数秒でアクセスできます。
データベースが大きい場合でも、これによりクエリ速度が向上します。 増加したデータの処理と保存のコストも上昇しています。 Parquet と ORC は、データベースの列に最も広く使用されている形式の 2 つです。 Parquet は、データのフラットな列をより効果的な方法で表示するために使用されます。 ORC は、Hadoop ワークロード用に特別に設計されたファイル形式で、大規模なストリーミング読み取り用に最適化されています。 ノーコード データ パイプラインである Hevo Data を使用すると、さまざまなデータベースのデータを 100 以上の他のソースと統合し、好みの BI ツールに読み込むことができます。 Apache Druid は、オープンソース ソフトウェア上に構築されたリアルタイム分析データベースであり、大規模なデータ セットに対して OLAP クエリをより高速に実行できます。
Apache Kudu オープンソースの分散型データ ストレージ エンジンは、大量の情報に対して高速な分析プロセスを実行するために使用されます。 MonetDB のストレージ モデルは垂直断片化に基づいており、そのクエリ実行アーキテクチャは最新のコンピューターに基づいています。 ClickHouse 分析レポート エンジンを使用すると、リアルタイムでレポートを生成できます。 BigQuery は、Dremel として知られる Google の分散クエリ エンジンの結果です。 Dremel のサーバーレス アーキテクチャは、分散コンピューティングを利用することで、テラバイト単位のデータを数秒で処理できます。 圧縮、ジャスト イン タイム プロジェクション、および水平および垂直パーティション分割は、列ベースのストレージの利点の一部です。 行指向のデータベースである列データベースでは、データを行に格納できます。
低コストのテクノロジーを備えたクラスターを利用してスケーリングし、スループットを向上させます。 カラムナ データベースは、ビッグ データ処理、ビジネス インテリジェンス (BI)、および分析のさまざまな目的に使用できます。 モノのインターネット (IoT) デバイスは、データ センターに大量のデータを格納します。
最も人気のある 3 つの列指向データ ストレージ データベース
Apache Cassandra は、さまざまな列指向のデータベースでよく知られているデータ ストレージ システムです。 Cassandra はサーバー側のオープン ソース プロジェクトであり、多くの汎用サーバーで大量のデータを処理できます。 一方、DynamoDB はNoSQL データベース モデルを採用しており、あらゆるタイプのデータを格納できます。 MariaDB は、リレーショナル モデルと SQL を保持しながら、分析クエリの生成をより迅速かつ簡単に行えるようにするため、多くのカラム型データベースで一般的な選択肢となっています。
最高のカラムナ データベース
個人の好みやニーズによって異なるため、この質問に対する決定的な答えはありません。 ただし、最も人気のあるカラム型データベースには、Amazon Redshift、Google BigQuery、Microsoft SQL Server などがあります。 これらのデータベースはすべて高度にスケーラブルであり、データ ウェアハウジングと分析ワークロードに優れたパフォーマンスを提供します。
列データベースのデータは、行ではなく列に格納されます。 従来の行データベースと比較して、列データベースには速度や効率など、さまざまな利点があります。 Sadas Engine は、オンプレミスとクラウドの両方で利用できる、最も強力で柔軟なカラム型データベース管理システムです。 ClickHouse は、使いやすいオープンソースのデータベース管理システムです。 世界最速のクラウド データ ウェアハウスである Amazon Redshift は、成長を続けています。 ClickHouse は、各クエリをできるだけ迅速に処理するために、利用可能なすべてのハードウェアを最大限に活用します。 Rockset の検索および分析エンジンは、ライブ ダッシュボード表示とリアルタイム アプリを強化します。
Vertica は、市場で最も高速でスケーラブルな高度な分析データベースです。 ANSI SQL 言語は、運用上のオーバーヘッドを排除しながら超高速でデータを処理できるため、ペタバイト分析に最適です。 大規模なオンデマンド分析により、クラウド データ ウェアハウスの代替手段よりも 3 年間の所有コストを 26% ~ 34% 削減できます。 会社が管理する暗号化キーを使用して、必要に応じて自宅でデータを暗号化するか、自由に暗号化を設定できます。 Greenplum Database は、分析、機械学習、および人工知能機能を提供するオープンソースの大規模並列データ プラットフォームです。 このツールは、ペタバイト規模のデータ ボリュームのリアルタイム データ分析を超高速で提供します。 Druid は、その中核となる設計により、データ ウェアハウス、時系列データベース、および検索システムからのアイデアを組み合わせて、高性能の分析データベースをリアルタイムで作成します。
Apache 2 は、このプロジェクトのソース コードです。 エンタープライズ オープン ソース データベースである MariaDB Platform は、このソリューションの基盤です。 このプラットフォームは、幅広いトランザクション、分析、およびハイブリッド ワークロードをサポートできます。 MariaDB は、使用するハードウェアの種類に応じて、コモディティ ハードウェアまたはパブリック クラウドにデプロイできます。 世界中の学生、教師、研究者、起業家、中小企業、多国籍企業が MonetDB コミュニティに参加できます。 完全マネージド型の CrateDB 向けにデータベースをサービスとして提供します。 テーブル ストレージを使用すると、手動でシャーディングする必要がなくなるため、データのスケールアップが容易になります。
geo 冗長ストレージを使用して、リージョンの保存データが 3 回レプリケートされます。 従来のアプリケーションを移植したり、Kudu のシンプルなデータ モデルを使用して新しいアプリケーションを構築したりするのは簡単です。 Parquet では、列ごとに圧縮スキームを指定できます。また、必要に応じて新しい圧縮スキームを追加できるように、将来的にも保証されています。 ハイパーテーブルは、名前が示すように、スケーラビリティの問題を独自の条件で解決するように設計されています。 列指向のDBMS InfiniDBに基づく OLAP ワークロードをサポートするように設計されています。 ビッグデータと複雑なポリゴン操作における QikkDB のパフォーマンスは比類のないものです。 qikkDB データベースは、次の機能を備えて構築されています。 これは、インメモリ コンピューティング エンジンを備えた高性能のクロスプラットフォームの履歴時系列列データベースです。
ストリーミング プロセッサおよびプログラミング言語である Q は、リアルタイムで自分自身を表現できるようにすることを目的としています。 ソート インデックス、ビットマップ インデックス、および逆インデックスは、プラグインできる 3 つのインデックス作成テクノロジです。 このプロジェクトでは、Apache バージョン 2.0 がライセンスされています。
列指向のデータベースは未来です
近年、多数のデータベースが列を中心に設計されています。 これらのデータベースはデータを行と列に格納するため、使用と管理が簡単です。 MariaDB、CrateDB、ClickHouse、Greenplum Database、Apache Hbase、Apache Kudu、Apache Parquet、Hypertable、MonetDB など、いくつかの列指向のデータベースを利用できます。 ドキュメント、グラフ、および列データは、NoSQL データベース モデルを使用して DynamoDB 内で生成できます。 ドキュメント ストア データベースの背後にある企業である MongoDB は、列ストア インデックス作成のリリースを発表しました。これにより、開発者は分析クエリをアプリケーションに組み込むことができます。
列指向データベースの例
カラムナ データベースは、行ではなく列にデータを格納するタイプのデータベースです。 このタイプのデータベースは、従来の行ベースのデータベースよりも優れたパフォーマンスとスケーラビリティを提供できるため、データ ウェアハウジングおよび分析アプリケーションによく使用されます。 カラムナ データベースの 1 つの例は、Apache HBase です。
データベースの操作は、通常、列が行に情報を分散するという点で、他のデータベースの操作とは異なります。 大規模なデータ セットを分析する機能は、カラムナ データベースにとって特に魅力的です。 近年、NoSQL データベースを使用するドキュメント ストアの人気が高まっています。 グラフ データベースは高度にネットワーク化されたデータを非常に正確にマッピングできるため、使用する人が増えるにつれてますます人気が高まっています。 長い間、カラム型データベース管理システムが使用されてきました。 利用可能な実装がまだいくつかあるという事実にもかかわらず、いくつかのシステムが開発されています。 通常、トランザクション アプリケーションへのアクセスは、他のアプリケーションへのアクセスとは異なります。 このタスクは、従来のデータベースよりもカラムナ データベースで実行するほうがはるかに遅くなります。
列指向データベースの人気が高まっている理由
Cassandra、MariaDB、CrateDB などの列指向データベースは、大量のデータを処理するアプリケーションのデータ ストレージ ソリューションとして人気を集めています。 同じテーブル (列ファミリー) の複数の行を含むデータベースにデータを格納できるため、データの格納が容易になり、パフォーマンスが向上します。
MariaDB、CrateDB、ClickHouse、Greenplum Database、Apache Hbase、Apache Kudu、Apache Parquet など、いくつかの列指向のデータベースを利用できます。 これらのデータベースはすべてオープン ソースであり、さまざまなアプリケーションで使用されています。