
テクニカル SEO の究極のガイド
公開: 2023-02-24検索エンジン最適化 (SEO) に関連して今年行ったことを 3 つ挙げてください。
これらの戦術は、キーワード調査、メタディスクリプション、バックリンクを中心に展開していますか?
もしそうなら、あなたは一人ではありません。 SEO に関して言えば、これらの手法は通常、マーケターが武器庫に追加する最初の手法です。
これらの戦略は、オーガニック検索でのサイトの可視性を向上させますが、採用すべき戦略はこれだけではありません。 SEO の傘下にある別の一連の戦術があります。
テクニカル SEO とは、サイト アーキテクチャ、モバイル最適化、ページ速度など、有機的な成長エンジンを強化する舞台裏の要素を指します。 SEO のこれらの側面は、最も魅力的ではないかもしれませんが、非常に重要です。
テクニカル SEO を改善するための最初のステップは、サイト監査を実行して自分の立ち位置を知ることです。 2 番目のステップは、不足している領域に対処するための計画を作成することです。 これらの手順については、以下で詳しく説明します。
プロのヒント: HubSpot の無料の CMS ツールを使用して、変換するように設計された Web サイトを作成します。

テクニカルSEOとは?
テクニカル SEO とは、サイトを検索エンジンがクロールしてインデックスしやすくするために行うあらゆることを指します。 テクニカル SEO、コンテンツ戦略、リンク構築戦略はすべて連携して機能し、ページが検索で上位にランクされるようにします。
テクニカル SEO vs. オンページ SEO vs. オフページ SEO
多くの人は、検索エンジン最適化 (SEO) を、オンページ SEO、オフページ SEO、およびテクニカル SEO の 3 つの異なるバケットに分類します。 それぞれの意味を簡単に説明しましょう。
オンページSEO
オンページ SEO とは、画像の代替テキスト、キーワードの使用、メタ記述、H1 タグ、URL の命名、内部リンクなど、検索エンジン (および読者!) にページの内容を伝えるコンテンツを指します。 すべてがサイト上にあるため、オンページ SEO を最大限に制御できます。
オフページSEO
オフページ SEO は、信頼度の投票を通じて、検索エンジンにあなたのページの人気と有用性を伝えます。最も顕著なのは、バックリンク、または他のサイトから自分のサイトへのリンクです。 バックリンクの量と質は、ページの PageRank を押し上げます。 すべてが同じであれば、信頼できるサイトからの関連リンクが 100 個あるページは、信頼できるサイトからの関連リンクが 50 個あるページ (または信頼できるサイトからの無関係なリンクが 100 個あるページ) よりも上位に表示されます。
テクニカルSEO
テクニカル SEO も自分でコントロールできますが、直感的ではないため、マスターするのは少し難しいです。
テクニカル SEO が重要な理由
SEO のこのコンポーネントを完全に無視したくなるかもしれません。 ただし、オーガニック トラフィックでは重要な役割を果たします。 あなたのコンテンツは最も詳細で、有用で、よく書かれているかもしれませんが、検索エンジンがそれをクロールできない限り、それを見る人はほとんどいません。
周りに誰もいない森の中で倒れた木のようなものです...音はしますか? 強力な技術的 SEO 基盤がなければ、あなたのコンテンツは検索エンジンにとって何の効果もありません。
 ソース
ソース
あなたのコンテンツをインターネットを通じて反響させる方法について話し合いましょう。
テクニカル SEO を理解する
テクニカル SEO は、消化しやすい部分に分解するのが最適な獣です。 あなたが私のような人なら、チェックリストを使ってチャンクで大きなことに取り組むのが好きです。 信じられないかもしれませんが、ここまで説明してきたことはすべて、5 つのカテゴリのいずれかに分類できます。各カテゴリには、実行可能な項目の独自のリストがあります。
これら 5 つのカテゴリと、技術的な SEO 階層におけるそれらの位置は、 Maslov の Hierarchy of Needsを連想させるこの美しいグラフィックによって最もよく示されていますが、検索エンジン最適化のためにリミックスされています。 (アクセシビリティの代わりに、一般的に使用される「レンダリング」という用語を使用することに注意してください。)
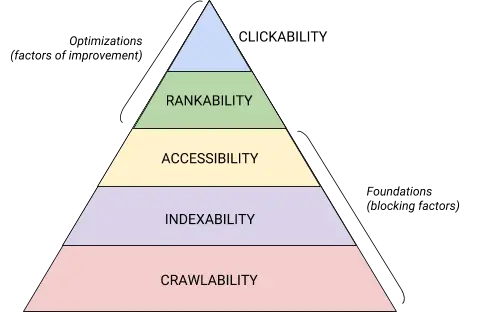 ソース
ソース
テクニカル SEO 監査の基礎
技術的な SEO 監査を開始する前に、いくつかの基礎を整えておく必要があります。
残りの Web サイト監査に進む前に、これらの技術的な SEO の基礎について説明しましょう。
優先ドメインを監査する
ドメインは、 hubspot.comのように、ユーザーがサイトにアクセスするために入力する URL です。 ウェブサイトのドメインは、人々が検索を通じてあなたを見つけられるかどうかに影響を与え、サイトを識別するための一貫した方法を提供します。
優先ドメインを選択すると、サイトの www または非 www バージョンを検索結果に表示することを好むかどうかを検索エンジンに伝えることになります。 たとえば、yourwebsite.comではなくwww.yourwebsite.comを選択できます。 これにより、サイトの www バージョンを優先するよう検索エンジンに指示し、すべてのユーザーをその URL にリダイレクトします。 そうしないと、検索エンジンがこれら 2 つのバージョンを別々のサイトとして扱い、SEO 値が分散してしまいます。
以前、Google は、希望する URL のバージョンを特定するよう求めていました。 これで、Google が検索者に表示するバージョンを識別して選択します。 ただし、ドメインの優先バージョンを設定したい場合は、canonical タグを使用して行うことができます (これについては後で説明します)。 いずれにせよ、優先ドメインを設定したら、すべてのバリアント ( www、非 www、http、および index.htmlを意味する) がすべてそのバージョンに永続的にリダイレクトされるようにします。
SSL を実装する
この用語は以前に聞いたことがあるかもしれませんが、それは非常に重要だからです。 SSL、または Secure Sockets Layer は、Web サーバー (オンライン リクエストの実行を担当するソフトウェア) とブラウザーの間に保護レイヤーを作成し、それによってサイトを安全にします。 ユーザーが支払い情報や連絡先情報などの情報を Web サイトに送信する場合、SSL で保護されているため、その情報がハッキングされる可能性は低くなります。
SSL 証明書は、「http://」ではなく「https://」で始まるドメインと URL バーのロック記号で示されます。

検索エンジンは安全なサイトを優先します。実際、Google は2014 年にSSL がランキング要素と見なされると発表しました。 このため、ホームページの SSL バリアントを優先ドメインとして設定してください。
SSL を設定したら、非 SSL ページを http から https に移行する必要があります。 難しい注文ですが、ランキングの向上という名目で努力する価値はあります。 必要な手順は次のとおりです。
- すべてのhttp://yourwebsite.comページをhttps://yourwebsite.comにリダイレクトします。
- それに応じて、すべての canonical タグと hreflang タグを更新します。
- サイトマップ ( yourwebsite.com/sitemap.xmlにあります) と robot.txt ( yourwebsite.com/robots.txtにあります)の URL を更新します。
- https Web サイト用に Google Search Console と Bing Webmaster Tools の新しいインスタンスをセットアップし、それを追跡して、トラフィックの 100% が移行されるようにします。
ページ速度を最適化する
Web サイトの訪問者が、Web サイトがロードされるのをどれくらい待つか知っていますか? 6 秒…それは寛大です。 一部のデータは、ページの読み込み時間が 1 秒から 5 秒に増加すると、直帰率が 90% 増加することを示しています。 1 秒も無駄にできないため、サイトの読み込み時間を改善することを優先する必要があります。
サイトの速度は、ユーザー エクスペリエンスとコンバージョンにとって重要であるだけでなく、ランキング要因でもあります。
これらのヒントを使用して、ページの平均読み込み時間を改善してください。
- すべてのファイルを圧縮します。 圧縮すると、画像、CSS、HTML、JavaScript ファイルのサイズが縮小されるため、使用するスペースが少なくなり、読み込みが速くなります。
- リダイレクトを定期的に監査します。 301 リダイレクトの処理には数秒かかります。 それを複数のページまたはリダイレクトのレイヤーに掛けると、サイトの速度に深刻な影響を与えます.
- コードを縮小します。 乱雑なコードは、サイトの速度に悪影響を与える可能性があります. 乱雑なコードとは、怠惰なコードを意味します。 それは文章を書くようなものです — おそらく最初のドラフトでは、6 つの文で要点を述べます。 2 番目のドラフトでは、3 で作成します。コードが効率的であるほど、ページの読み込みが速くなります (一般的に)。 クリーンアップしたら、コードを縮小して圧縮します。
- コンテンツ配信ネットワーク (CDN) を考えてみましょう。 CDN は、Web サイトのコピーをさまざまな地理的な場所に保存し、検索者の場所に基づいてサイトを配信する分散 Web サーバーです。 サーバー間の情報の移動距離が短くなるため、リクエスト側のサイトの読み込みが速くなります。
- プラグインを満足させないようにしてください。 古いプラグインには多くの場合、セキュリティの脆弱性があり、Web サイトのランキングを損なう悪意のあるハッカーの攻撃を受けやすくなります。 常に最新バージョンのプラグインを使用していることを確認し、使用を最小限に抑えます。 同様に、既製の Web サイト テーマには多くの不要なコードが含まれていることが多いため、カスタム テーマの使用を検討してください。
- キャッシュ プラグインを活用します。 キャッシュ プラグインはサイトの静的バージョンを保存してリピーターに送信するため、再訪問時にサイトをロードする時間が短縮されます。
- 非同期 (非同期) 読み込みを使用します。 スクリプトは、サーバーが Web ページの HTML または本文 (つまり、訪問者がサイトで見たいもの) を処理する前に読み取る必要がある命令です。 通常、スクリプトはウェブサイトの <head> (Google タグ マネージャー スクリプトと考えてください) に配置され、ページの残りのコンテンツよりも優先されます。 非同期コードを使用すると、サーバーは HTML とスクリプトを同時に処理できるため、遅延が減少し、ページの読み込み時間が長くなります。
非同期スクリプトは次のようになります。 < script async src =” script.js “></ script >
あなたのウェブサイトが速度部門で不足している場所を確認したい場合は、 Google のこのリソースを使用できます。
技術的な SEO の基礎が整ったら、次の段階であるクロール可能性に進む準備が整います。
クロール可能性のチェックリスト
クロール可能性は、技術的な SEO 戦略の基盤です。 検索ボットはページをクロールして、サイトに関する情報を収集します。
これらのボットがなんらかの理由でクロールをブロックされている場合、ページのインデックス作成やランク付けはできません。 テクニカル SEO を実装するための最初のステップは、すべての重要なページにアクセスしやすく、簡単にナビゲートできるようにすることです。
以下では、チェックリストに追加する項目と、ページがクロールできるようにするために監査する Web サイト要素について説明します。
クロール可能性のチェックリスト
- XML サイトマップを作成します。
- クロール バジェットを最大化します。
- サイト アーキテクチャを最適化します。
- URL 構造を設定します。
- robots.txt を利用します。
- ブレッドクラム メニューを追加します。
- ページネーションを使用します。
- SEO ログ ファイルを確認します。
1. XML サイトマップを作成します。
調べたサイト構造を覚えていますか? これは、検索ボットが Web ページを理解してクロールするのに役立つXML サイトマップと呼ばれるものに属します。 Web サイトの地図と考えることができます。 サイトマップが完成したら、 Google Search Consoleと Bing Webmaster Tools に送信します。 Web ページを追加および削除するときは、サイトマップを最新の状態に保つことを忘れないでください。
2. クロール バジェットを最大化します。
クロール バジェットとは、サイト検索ボットがクロールするページとリソースを指します。
クロールの予算は無限ではないため、最も重要なページを優先してクロールするようにしてください。
クロール バジェットを最大限に活用するためのヒントをいくつか紹介します。
- 重複ページを削除または正規化します。
- 壊れたリンクを修正またはリダイレクトします。
- CSS ファイルと Javascript ファイルがクロール可能であることを確認してください。
- クロールの統計情報を定期的に確認し、急激な低下や増加に注意してください。
- クロールを禁止したボットまたはページがブロックされることを意図していることを確認してください。
- サイトマップを最新の状態に保ち、適切なウェブマスター ツールに送信します。
- 不要なコンテンツや古いコンテンツをサイトから削除します。
- 動的に生成される URL に注意してください。これにより、サイトのページ数が急増する可能性があります。
3. サイト アーキテクチャを最適化します。
あなたのウェブサイトには複数のページがあります。 これらのページは、検索エンジンが簡単に見つけてクロールできるように編成する必要があります。 ここで、サイト構造 (Web サイトの情報アーキテクチャと呼ばれることが多い) の出番です。
建物が建築設計に基づいているのと同じように、サイト アーキテクチャは、サイト上のページをどのように編成するかです。
関連するページはグループ化されています。 たとえば、ブログのホームページは個々のブログ投稿にリンクしており、各投稿はそれぞれの作成者ページにリンクしています。 この構造は、検索ボットがページ間の関係を理解するのに役立ちます。
また、サイトのアーキテクチャは、個々のページの重要性を形成し、それによって形成される必要があります。 ページ A があなたのホームページに近いほど、ページ A にリンクするページが多くなり、それらのページのリンク エクイティが増えるほど、検索エンジンはページ A に与える重要性が高くなります。
たとえば、ホームページからページ A へのリンクは、ブログ投稿からのリンクよりも重要性を示します。 ページ A へのリンクが多いほど、そのページは検索エンジンにとってより「重要」になります。
概念的には、サイト アーキテクチャは次のようになります。ここでは、 About、Product、Newsなどのページがページの重要度の階層の最上位に配置されます。
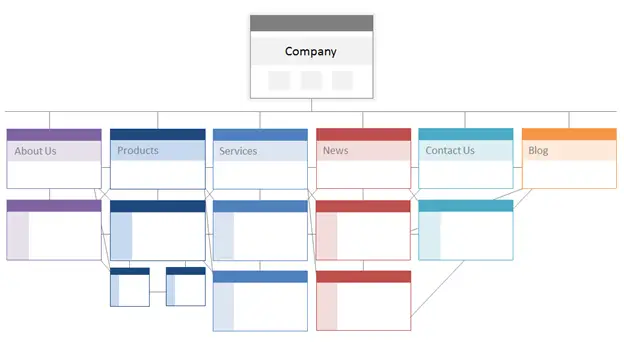
ソース
ビジネスにとって最も重要なページが、(関連性のある!) 内部リンクの数が最も多い階層の最上位にあることを確認してください。
4. URL 構造を設定します。
URL 構造とは、URL をどのように構成するかを指し、サイトのアーキテクチャによって決定される可能性があります。 接続については後ほど説明します。 最初に、URL には、 blog.hubspot.comなどのサブディレクトリや、 hubspot.com/blogなどのサブフォルダーを含めることができることを明確にしましょう。
たとえば、 How to Groom Your Dogというタイトルのブログ投稿は、ブログのサブドメインまたはサブディレクトリに分類されます。 URL はwww.bestdogcare.com/blog/how-to-groom-your-dogのようになります。 同じサイトの製品ページはwww.bestdogcare.com/products/grooming-brushになります。
URL でサブドメインまたはサブディレクトリを使用するか、「製品」と「ストア」を使用するかは完全にあなた次第です。 独自の Web サイトを作成する利点は、ルールを作成できることです。 重要なのは、これらのルールが統一された構造に従っていることです。つまり、別のページで blog.yourwebsite.com と yourwebsite.com/blogs を切り替えるべきではありません。 ロードマップを作成し、それを URL の命名構造に適用して、それに固執します。
URL の記述方法に関するその他のヒントを次に示します。
- 小文字を使用します。
- ダッシュを使用して単語を区切ります。
- 短く説明的なものにします。
- 不要な文字や単語 (前置詞を含む) を使用しないでください。
- ターゲットキーワードを含めます。
URL 構造を完成させたら、重要なページの URL のリストをXML サイトマップの形式で検索エンジンに送信します。 そうすることで、検索ボットにサイトに関する追加のコンテキストが提供されるため、クロール時にそれを把握する必要がなくなります。
5. robots.txt を利用します。
Web ロボットがサイトをクロールするとき、最初に /robot.txt をチェックします。これは、ロボット除外プロトコルとしても知られています。 このプロトコルは、サイトの特定のセクションやページを含め、特定の Web ロボットによるサイトのクロールを許可または禁止することができます。 ボットによるサイトのインデックス作成を防止するには、noindex robots メタ タグを使用します。 これらの両方のシナリオについて説明しましょう。
特定のボットによるサイトのクロールを完全にブロックしたい場合があります。 残念ながら、悪意のあるボットがいくつか存在します。ボットは、コンテンツをスクレイピングしたり、コミュニティ フォーラムにスパムを送ったりします。 この悪い動作に気付いた場合は、robot.txt を使用して Web サイトへの侵入を防ぎます。 このシナリオでは、robot.txt をインターネット上の悪意のあるボットからの力場と考えることができます。
インデックス作成に関しては、検索ボットがサイトをクロールして手がかりを収集し、キーワードを見つけて、Web ページと関連する検索クエリを照合できるようにします。 ただし、後で説明するように、不要なデータに費やしたくないクロール バジェットがあります。 そのため、検索ボットが Web サイトの内容を理解するのに役立たないページ (たとえば、オファーやログイン ページのサンキューページなど) を除外することをお勧めします。
いずれにせよ、robot.txt プロトコルは、何を達成したいかによって異なります。
6. ブレッドクラム メニューを追加します。
2 人の子供が家に帰る道を見つけるために地面にパンくずを落とした古い寓話ヘンゼルとグレーテルを覚えていますか? さて、彼らは何かに取り組んでいました。
パンくずリストはまさにその名の通り、ユーザーを Web サイトでの旅の最初に戻るように導く道のりです。 これは、現在のページがサイトの残りの部分とどのように関連しているかをユーザーに伝えるページのメニューです。
そして、それらはウェブサイトの訪問者だけのものではありません。 検索ボットもそれらを使用します。 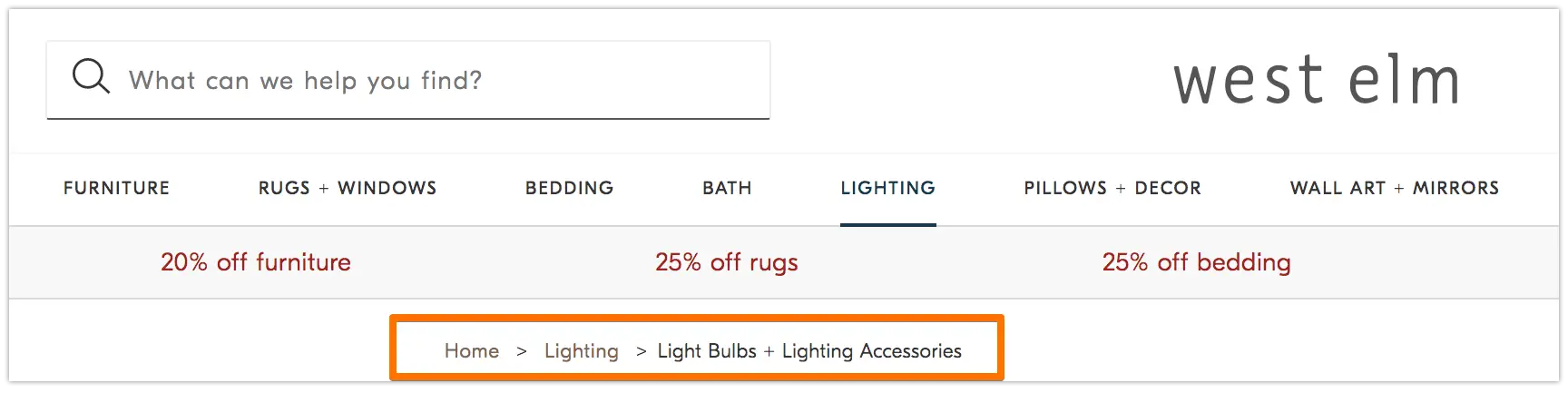
ソース
パンくずリストには次の 2 つが必要です。1) ユーザーが [戻る]ボタンを使用せずに Web ページを簡単にナビゲートできるようにすること、および 2) サイトをクロールしている検索ボットに正確なコンテキストを提供するために構造化されたマークアップ言語を使用することです。
ブレッドクラムに構造化データを追加する方法がわかりませんか? BreadcrumbList については、このガイドを使用してください。
7. ページネーションを使用します。
教師が研究論文のページに番号を付けるように要求したときのことを覚えていますか? いわゆるページネーションです。 テクニカル SEO の世界では、ページネーションの役割は少し異なりますが、それでも組織の一形態と考えることができます。
ページネーションでは、コードを使用して、個別の URL を持つページが互いに関連している場合に検索エンジンに通知します。 たとえば、チャプターまたは複数の Web ページに分割する一連のコンテンツがあるとします。 検索ボットがこれらのページを簡単に発見してクロールできるようにする場合は、ページネーションを使用します。
それが機能する方法は非常に簡単です。 シリーズのページ 1 の<head>に移動して、
rel="next"を使用して、検索ボットに 2 番目にクロールするページを指示します。 次に、2 ページ目では、前のページを示すためにrel="prev"を使用し、次のページを示すために rel="next" を使用します。

このように見えます…
1 ページ目:
<link rel="next" href="https://www.website.com/page-two" />
2 ページ目:
<link rel="prev" href="https://www.website.com/page-one" />
<link rel="next" href="https://www.website.com/page-three" />
ページネーションはクロールの検出に役立ちますが、Google では以前のようにページのバッチ インデックス作成をサポートしていないことに注意してください。
8. SEO ログ ファイルを確認します。
ログ ファイルはジャーナル エントリのようなものと考えることができます。 Web サーバー (ジャーナラー) は、サイトで実行するすべてのアクションに関するログ データをログ ファイル (ジャーナル) に記録して保存します。 記録されるデータには、要求の日時、要求されたコンテンツ、および要求元の IP アドレスが含まれます。 また、ユーザーの要求を満たす一意に識別可能なソフトウェア (検索ボットなど) であるユーザー エージェントを識別することもできます。
しかし、これはSEOと何の関係があるのでしょうか?
検索ボットは、サイトをクロールするときにログ ファイルの形で痕跡を残します。 ログ ファイルをチェックし、ユーザー エージェントと検索エンジンでフィルタリングすることで、クロールされたかどうか、いつ、何がクロールされたかを判断できます。
この情報は、クロール バジェットがどのように費やされているか、およびインデックス作成やボットへのアクセスに対してどのような障害が発生しているかを判断できるため、役に立ちます。 ログ ファイルにアクセスするには、開発者に問い合わせるか、Screaming Frog などのログ ファイル アナライザーを使用します。
検索ボットがサイトをクロールできるからといって、必ずしもすべてのページをインデックスに登録できるとは限りません。 テクニカル SEO 監査の次のレイヤーであるインデックス可能性を見てみましょう。
インデックス可能性のチェックリスト
検索ボットが Web サイトをクロールすると、トピックとそのトピックとの関連性に基づいてページのインデックス作成が開始されます。 インデックスに登録されると、ページは SERP でランク付けされる資格があります。 ページのインデックス登録に役立ついくつかの要因を次に示します。
インデックス可能性のチェックリスト
- 検索ボットによるページへのアクセスのブロックを解除します。
- 重複するコンテンツを削除します。
- リダイレクトを監査します。
- サイトのモバイル応答性を確認します。
- HTTP エラーを修正します。
1. 検索ボットによるページへのアクセスのブロックを解除します。
クロール可能性に対処するときは、このステップを処理する可能性がありますが、ここで言及する価値があります。 ボットが優先ページに送信され、ボットが自由にアクセスできるようにする必要があります。 これを行うために自由に使えるツールがいくつかあります。 Google のrobots.txt テスターは、許可されていないページのリストを提供し、Google Search Console の検査ツールを使用して、ブロックされたページの原因を特定できます。
2. 重複するコンテンツを削除します。
重複したコンテンツは検索ボットを混乱させ、インデックス可能性に悪影響を及ぼします。 正規の URL を使用して優先ページを確立することを忘れないでください。
3. リダイレクトを監査します。
すべてのリダイレクトが正しく設定されていることを確認します。 リダイレクト ループ、破損した URL、さらに悪いことに、不適切なリダイレクトにより、サイトのインデックス作成時に問題が発生する可能性があります。 これを避けるには、すべてのリダイレクトを定期的に監査してください。
4. サイトのモバイル対応を確認します。
あなたのウェブサイトがモバイル フレンドリーでない場合は、必要な場所から大きく遅れています。 早くも 2016 年に、 Google はまずモバイル サイトのインデックス登録を開始し、デスクトップよりもモバイル エクスペリエンスを優先しました。 現在、そのインデックス作成はデフォルトで有効になっています。 この重要な傾向に追いつくために、 Google のモバイル フレンドリー テストを使用して、ウェブサイトのどこを改善する必要があるかを確認できます。
5. HTTP エラーを修正します。
HTTP は HyperText Transfer Protocol の略ですが、おそらく気にする必要はありません。 あなたが気にかけているのは、HTTP がユーザーや検索エンジンにエラーを返したときと、それらを修正する方法です。
HTTP エラーは、サイトの重要なコンテンツから検索ボットをブロックすることで、検索ボットの作業を妨げる可能性があります。 したがって、これらのエラーに迅速かつ徹底的に対処することが非常に重要です。
すべての HTTP エラーは固有のものであり、特定の解決策が必要であるため、以下のセクションではそれぞれについて簡単に説明します。提供されているリンクを使用して、エラーの詳細または解決方法を確認してください。
- 301 パーマネント リダイレクトは、ある URL から別の URL にトラフィックを永続的に送信するために使用されます。 CMS ではこれらのリダイレクトを設定できますが、リダイレクトが多すぎると、リダイレクトを追加するたびにページの読み込み時間が長くなるため、サイトの速度が低下し、ユーザー エクスペリエンスが低下する可能性があります。 リダイレクト チェーンが多すぎると、検索エンジンがそのページのクロールをあきらめてしまうため、可能であればゼロ リダイレクト チェーンを目指してください。
- 302 一時リダイレクトは、トラフィックを URL から別の Web ページに一時的にリダイレクトする方法です。 このステータス コードによってユーザーは自動的に新しい Web ページに移動しますが、キャッシュされたタイトル タグ、URL、および説明は元の URL と一貫したままになります。 ただし、一時的なリダイレクトが十分に長く続くと、最終的には永続的なリダイレクトとして扱われ、それらの要素が宛先 URL に渡されます。
- 403 Forbidden Messages は、ユーザーが要求したコンテンツが、アクセス許可に基づいて、またはサーバーの構成ミスにより制限されていることを意味します。
- 404 エラー ページは、ユーザーが要求したページが削除されたか間違った URL を入力したために存在しないことをユーザーに伝えます。 訪問者をサイトに留まらせるために、ブランドに即した魅力的な 404 ページを作成することを常にお勧めします (上のリンクをクリックして、いくつかの良い例を参照してください)。
- 405 Method Not Allowed は、 Web サイト サーバーがアクセス方法を認識し、ブロックしたため、エラー メッセージが表示されたことを意味します。
- 500 内部サーバー エラーは一般的なエラー メッセージで、Web サーバーでサイトを要求元に配信する際に問題が発生していることを示します。
- 502 不正なゲートウェイ エラーは、 Web サイト サーバー間の通信ミス、または無効な応答に関連しています。
- 503 Service Unavailable は、サーバーが正常に機能している間、要求を満たすことができないことを示します。
- 504 ゲートウェイ タイムアウトは、サーバーが要求された情報にアクセスするための Web サーバーからタイムリーな応答を受信しなかったことを意味します。
これらのエラーの理由が何であれ、ユーザーと検索エンジンの両方を満足させ、両方がサイトに戻ってくるようにするには、エラーに対処することが重要です。
サイトがクロールされ、インデックスに登録されていたとしても、ユーザーやボットをブロックするアクセシビリティの問題は SEO に影響を与えます。 とはいえ、テクニカル SEO 監査の次の段階であるレンダリング可能性に進む必要があります。
レンダリング性のチェックリスト
このトピックに入る前に、SEO アクセシビリティとWeb アクセシビリティの違いに注意することが重要です。 後者は、視覚障害や失読症などの障害を持つユーザーが Web ページを簡単にナビゲートできるようにすることを中心に展開します。 オンライン アクセシビリティの多くの要素は、SEO のベスト プラクティスと重なっています。 ただし、SEO アクセシビリティ監査では、障害のある訪問者がサイトをよりアクセスしやすくするために必要なすべてが考慮されているわけではありません。
このセクションでは、SEO アクセシビリティ (レンダリング) に焦点を当てますが、サイトを開発および維持するときは、Web アクセシビリティを最優先に考えてください。
レンダリング性のチェックリスト
アクセスしやすいサイトは、レンダリングのしやすさに基づいています。 以下は、レンダリング性の監査のために確認する Web サイト要素です。
サーバーのパフォーマンス
上記で学んだように、サーバーのタイムアウトとエラーによって HTTP エラーが発生し、ユーザーとボットがサイトにアクセスできなくなります。 サーバーで問題が発生していることに気付いた場合は、上記のリソースを使用してトラブルシューティングを行い、解決してください。 タイムリーにこれを行わないと、検索エンジンがあなたのウェブページをインデックスから削除する可能性があります.
HTTP ステータス
サーバーのパフォーマンスと同様に、HTTP エラーは Web ページへのアクセスを妨げます。 Screaming Frog 、 Botify 、またはDeepCrawl などの Web クローラーを使用して、サイトの包括的なエラー監査を実行できます。
読み込み時間とページサイズ
ページの読み込みに時間がかかりすぎる場合、心配しなければならない問題は直帰率だけではありません。 ページの読み込み時間が遅れると、サーバー エラーが発生して、ボットが Web ページからブロックされたり、コンテンツの重要なセクションが欠落している部分的に読み込まれたバージョンがクロールされたりする可能性があります。 特定のリソースに対するクロール需要の量に応じて、ボットはページの読み込み、レンダリング、およびインデックス作成を試みるために、同等の量のリソースを消費します。 ただし、ページの読み込み時間を短縮するには、コントロール内ですべてを行う必要があります。
JavaScript レンダリング
Google は JavaScript (JS) の処理に苦労していることを認めているため、事前にレンダリングされたコンテンツを使用してアクセシビリティを改善することを推奨しています。 Google には、検索ボットがサイトの JS にアクセスする方法や、検索関連の問題を改善する方法を理解するのに役立つリソースも多数あります。
孤立したページ
サイトのすべてのページは、少なくとも1 つの他のページにリンクする必要があります。ページの重要度に応じて、できればより多くのページにリンクする必要があります。 ページに内部リンクがない場合、そのページは孤立ページと呼ばれます。 紹介のない記事と同様に、これらのページには、ボットがインデックスを作成する方法を理解するために必要なコンテキストが欠けています。
ページの深さ
ページの深さは、サイト構造内でページが何層下に存在するか、つまり、ホームページから何クリック離れているかを表します。 直観的な階層を維持しながら、サイト アーキテクチャをできるだけ浅く保つことが最善です。 多層サイトは避けられない場合があります。 その場合、浅いサイトよりもよく整理されたサイトを優先する必要があります。
サイト構造のレイヤー数に関係なく、製品ページや連絡先ページなどの重要なページは 3 クリック以内に収めてください。 製品ページがサイトの奥深くに埋もれているため、ユーザーやボットが発見するために探偵のように振る舞わなければならない構造は、アクセスしにくく、エクスペリエンスが低下します。
たとえば、ターゲット ユーザーを製品ページに誘導する次のような Web サイト URL は、サイト構造の計画が不十分な例です: www.yourwebsite.com/products-features/features-by-industry/airlines-case-studies/airlines -製品。
リダイレクト チェーン
あるページから別のページにトラフィックをリダイレクトすることを決定した場合、代償を払うことになります。 その価格はクロール効率です。 リダイレクトが適切に設定されていない場合、リダイレクトによってクロールが遅くなり、ページの読み込み時間が短縮され、サイトにアクセスできなくなる可能性があります。 これらすべての理由から、リダイレクトを最小限に抑えるようにしてください。
アクセシビリティの問題に対処したら、ページが SERP でどのようにランク付けされるかに移ることができます。
ランカビリティチェックリスト
次に、おそらくすでにお気づきの、より話題の要素、つまり、技術的な SEO の観点からランキングを改善する方法に移ります。 ページをランク付けするには、前に述べたオンページ要素とオフページ要素のいくつかが含まれますが、テクニカル レンズからのものです。
これらすべての要素が連携して、SEO に適したサイトを作成することを忘れないでください。 したがって、すべての要因を除外することはできません。 それに飛び込みましょう。
内部リンクと外部リンク
リンクは、検索ボットがクエリの全体スキームのどこにページが適合するかを理解し、そのページをランク付けする方法のコンテキストを提供するのに役立ちます。 リンクは、検索ボット (およびユーザー) を関連コンテンツに誘導し、ページの重要性を転送します。 全体として、リンクはクロール、インデックス作成、およびランク付け能力を向上させます。
バックリンクの質
バックリンク—他のサイトから自分のサイトに戻るリンク — は、あなたのサイトに信頼の票を投じます。 これらは、外部 Web サイト A があなたのページが高品質であり、クロールする価値があると信じていることを検索ボットに伝えます。 これらの投票が加算されると、検索ボットはサイトをより信頼できるものとして認識し、扱います。 大したことのように聞こえますよね? ただし、ほとんどの優れた機能と同様に、注意点があります。 これらの被リンクの質は非常に重要です。
質の低いサイトからのリンクは、ランキングに悪影響を与える可能性があります。 関連する出版物へのアウトリーチ、リンクされていない言及を主張する、関連する出版物を提供する、リンクされていない言及を主張する、他のサイトがリンクしたい役立つコンテンツを提供するなど、あなたのサイトへの質の高いバックリンクを得る方法はたくさんあります。
コンテンツ クラスタ
HubSpot の私たちは、コンテンツ クラスターへの愛情や、それらが有機的成長にどのように貢献しているかについて、恥ずかしがり屋ではありません。 コンテンツ クラスターは関連するコンテンツにリンクするため、検索ボットは、特定のトピックに関する所有するすべてのページを簡単に見つけ、クロールし、インデックスを作成できます。 それらは、トピックについてどれだけ知っているかを検索エンジンに示す自己宣伝ツールとして機能するため、関連する検索クエリのオーソリティとしてサイトをランク付けする可能性が高くなります.
調査によると、検索者はSERP の上位 3 つの検索結果をクリックする可能性が高いことが示されているため、オーガニック トラフィックの増加の主な決定要因はランク付け可能性です。 しかし、自分のサイトがクリックされる結果であることをどのように保証するのでしょうか?
オーガニック トラフィック ピラミッドの最後の部分であるクリック可能性で締めくくりましょう。
クリッカビリティチェックリスト
クリックスルー率 (CTR) は検索者の行動と関係がありますが、 SERP でのクリック可能性を向上させるためにできることがあります。 キーワードを含むメタ ディスクリプションとページ タイトルは CTR に影響を与えますが、ここでは技術的な要素に焦点を当てます。
クリッカビリティチェックリスト
- 構造化データを使用します。
- SERP 機能を獲得します。
- 強調スニペット用に最適化します。
- Google Discover を検討してください。
正直なところ、検索者はすぐに答えを求めているため、ランキングとクリック率は密接に関係しています。 検索結果が SERP で目立つほど、クリックされる可能性が高くなります。 クリック可能性を向上させる方法をいくつか見ていきましょう。
1. 構造化データを使用します。
構造化データは、スキーマと呼ばれる特定の語彙を使用して、検索ボット用に Web ページの要素を分類およびラベル付けします。 スキーマは、各要素が何であるか、サイトとどのように関連しているか、どのように解釈するかを明確にします。 基本的に、構造化データはボットに「これは動画です」「これは商品です」「これはレシピです」と伝え、解釈の余地はありません。
To be clear, using structured data is not a “clickability factor” (if there even is such a thing), but it does help organize your content in a way that makes it easy for search bots to understand, index, and potentially rank your pages.
2. Win SERP features.
SERP features , otherwise known as rich results, are a double-edged sword. If you win them andget the click-through, you're golden. If not, your organic results are pushed down the page beneath sponsored ads, text answer boxes, video carousels, and the like.
Rich results are those elements that don't follow the page title, URL, meta description format of other search results. For example, the image below shows two SERP features — a video carousel and “People Also Ask” box — above the first organic result.
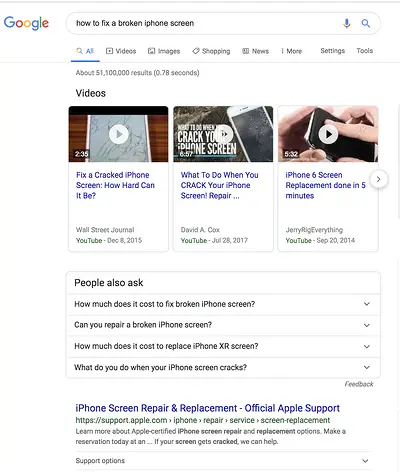
While you can still get clicks from appearing in the top organic results, your chances are greatly improved with rich results.
How do you increase your chances of earning rich results? Write useful content and use structured data. The easier it is for search bots to understand the elements of your site, the better your chances of getting a rich result.
Structured data is useful for getting these ( and other search gallery elements ) from your site to the top of the SERPs, thereby, increasing the probability of a click-through:
- Articles
- Videos
- レビュー
- Events
- How-Tos
- FAQs (“People Also Ask” boxes)
- Images
- Local Business Listings
- Products
- Sitelinks
3. Optimize for Featured Snippets.
One unicorn SERP feature that has nothing to do with schema markup is Featured Snippets, those boxes above the search results that provide concise answers to search queries.
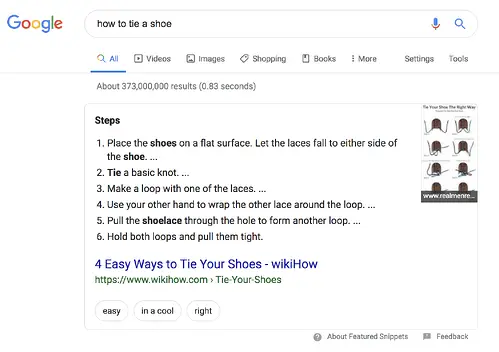
Featured Snippets are intended to get searchers the answers to their queries as quickly as possible. According to Google , providing the best answer to the searcher's query is the only way to win a snippet. However, HubSpot's research revealed a few additional ways to optimize your content for featured snippets .
4. Consider Google Discover.
Google Discover is a relatively new algorithmic listing of content by category specifically for mobile users. It's no secret that Google has been doubling down on the mobile experience; with over 50% of searches coming from mobile , it's no surprise either. The tool allows users to build a library of content by selecting categories of interest (think: gardening, music, or politics).
At HubSpot, we believe topic clustering can increase the likelihood of Google Discover inclusion and are actively monitoring our Google Discover traffic in Google Search Console to determine the validity of that hypothesis. We recommend that you also invest some time in researching this new feature. The payoff is a highly engaged user base that has basically hand-selected the content you've worked hard to create.
The Perfect Trio
Technical SEO, on-page SEO, and off-page SEO work together to unlock the door to organic traffic. While on-page and off-page techniques are often the first to be deployed, technical SEO plays a critical role in getting your site to the top of the search results and your content in front of your ideal audience. Use these technical tactics to round out your SEO strategy and watch the results unfold.
