
知っておくべきオープンソース LLM のトップ 5 [2023 年 12 月]
公開: 2023-12-19まとめ:
2023 年のトップ 5 のオープンソース大規模言語モデル (LLM) で AI イノベーションの最前線を探ります。Falcon の画期的な 180B パラメータから BLOOM の多言語能力まで、未来を形作る最先端の機能を詳しく掘り下げます。 Llama 2、GPT-NeoX-20B、MPT-7B の強みと潜在的なアプリケーションを発見し、進化する AI 環境で企業が安全に拡張できるようにします。
導入
人工知能 (AI) の世界は急速に変化しており、その変化の大部分は大規模言語モデル (LLM) と呼ばれるものによってもたらされています。 これらは単なる通常のツールではありません。 彼らはテクノロジーの新たな段階のリーダーのようなものです。 これらは、私たちの電話、コンピューター、その他のガジェットの使用方法を変える、本当にスマートなシステムだと考えてください。
企業は、プライバシーとセキュリティの懸念に対処するために、ChatGPT、Claude.ai、Phind などの外部チャットボット サービスに依存する代わりに、オープンソースの LLM (Large Language Model) ソフトウェアを選択する場合があります。 マシン上でオープンソース LLM を実行すると、機密データと機密情報が企業の管理下に留まり、外部エンティティにさらされるリスクが最小限に抑えられます。 このアプローチは、インタラクションが人間によってレビューされたり、将来のモデルのトレーニングに使用されたりするプラットフォームでは特に重要です。 オープンソース LLM ソフトウェアをローカルで活用することで、企業はより高いレベルのデータ セキュリティと機密性を維持し、外部アプリケーションに関連する潜在的なプライバシー問題に対処できます。
興味深いのは、これらの LLM の多くがオープンソースであることです。 これは、興味とある程度の技術スキルがあれば誰でも、それらを使用、変更、さらには改善できることを意味します。 それは、学ぶことができ、新しいトリックを教えてくれる超賢い AI の友達がいるようなものです。

2023 年のオープンソース LLM トップ 5
このブログでは、これらの素晴らしいオープンソース LLM を 5 つ紹介します。 それぞれが独自の方法で特別であり、AI の世界に新しいアイデアと能力をもたらします。
ファルコンLLM

Falcon LLM は、アブダビの Technology Innovation Institute (TII) によって開発された画期的な大規模言語モデル (LLM) です。 アプリケーションとユースケースを推進し、私たちの世界の将来の回復力を確保するように設計されています。 このスイートには現在、Falcon 180B、40B、7.5B、および 1.3B パラメーター AI モデルと、細心の注意を払って厳選された REFINEDWEB データセットが含まれています。 これらは共に、多様で包括的なソリューションを提供します。
ここでは、その主な機能、長所、潜在的な用途の包括的な内訳と、さらに詳しく調べるための関連情報源を示します。
主な特徴:
- 大規模なサイズ: 1,800 億のパラメータを備えた Falcon 180B は、他のいくつかのオープンソース LLM を上回る、優れた学習能力とパフォーマンス能力を誇ります。
- 効率的なトレーニング: 3.5 兆トークンの洗練されたデータセットでトレーニングされ、リソースの使用量を最適化しながら精度と品質を確保します。
- オープンソースの利用可能性: コードとトレーニング データは Hugging Face で公開されており、透明性とコミュニティへの貢献を促進します。
- 優れたパフォーマンス: Falcon は、さまざまなベンチマークで GPT-3 を上回るパフォーマンスを示しながら、必要なトレーニングと推論リソースが少なくなっているため、より効率的なオプションとなっています。
- 多様なモデル: TII は、180B、40B、7.5B、1.3B パラメータ AI モデル、長編小説執筆などの特定のタスクに特化したモデルなど、さまざまな Falcon バージョンを提供しています。
強み:
- 高品質のデータ パイプライン: TII の厳格なデータ フィルタリングと重複排除プロセスにより、Falcon の正確で信頼性の高いトレーニング データが保証されます。
- 多言語機能: Falcon は複数の言語を効果的に処理できますが、主に英語に重点を置いています。
- 微調整の可能性: Falcon は特定のタスクに合わせて微調整でき、パフォーマンスと適応性がさらに向上します。
- コミュニティ主導の開発: オープンソースの性質により、共同での改善や研究が可能になり、Falcon の開発が加速します。
潜在的な用途:
- 自然言語処理(NLP): Falcon は、テキストの要約、感情分析、対話の生成などのさまざまな NLP タスクで優れています。
- クリエイティブ コンテンツの生成: このモデルは、作家やアーティストが詩、台本、楽曲などのさまざまなクリエイティブ形式を生成するのを支援します。
- 教育と研究: パーソナライズされた学習体験、教育コンテンツの生成、研究サポートはすべて潜在的なアプリケーションです。
- ビジネスとマーケティング: Falcon は、インテリジェントなチャットボットを強化し、マーケティング キャンペーンをパーソナライズし、顧客データを効果的に分析できます。
追加リソース:
- Falcon LLM Web サイト: https://www.tii.ae/news/abu-dhabi-based-technology-innovation-institute-introduces-falcon-llm-foundational-large
- ハグフェイスファルコンモデルカード: https://huggingface.co/spaces/tiiuae/falcon-180b-demo
- TII Falcon ブログ投稿: https://huggingface.co/tiiuae/falcon-180B
- Falcon-180B に関する YouTube ビデオ: https://www.youtube.com/watch?v=9MArp9H2YCM
ラマ2

Meta AI と Microsoft によって開発されたオープンソースの大規模言語モデルである Llama 2 は、詩からコードに至るまで、多様なコンテンツの生成、質問への回答、言語の翻訳において優れた機能を発揮します。 推論とコーディングのベンチマークにおいて他の LLM よりも優れており、強化学習を通じて安全性を強調し、「責任ある使用ガイド」を提供します。 まだ開発中ですが、ユーザーは潜在的な不正確さ、偏った出力、および最適な使用のための技術的専門知識の必要性を認識する必要があります。 さまざまな分野に革命をもたらす Llama 2 の可能性を最大限に引き出すには、責任を持って利用することが最も重要です。
オリジナルの Llama を基盤として構築された Llama 2 は、いくつかの点で前作を上回っています。
- 多様なトレーニング: はるかに大規模で多様なデータセットでトレーニングされ、さまざまなタスクに対する理解とパフォーマンスの向上が保証されます。
- オープンな可用性: 前世代のアクセスが制限されていたのとは異なり、Llama 2 は、AWS、Azure、Hugging Face などのプラットフォーム上の研究、開発、さらには商用アプリケーションにもすぐに利用できます。
- 安全重視: メタは、誤った情報、偏見、有害な出力を最小限に抑えるための措置を講じることにより、安全性を優先してきました。
- 強化されたトレーニング: 70 億から 700 億の範囲のパラメーター数を備えたさまざまなバージョンで提供され、多様なニーズとリソースに対応します。
ラマ 2 対ラマ:
主な違いを理解するための簡単な比較を次に示します。
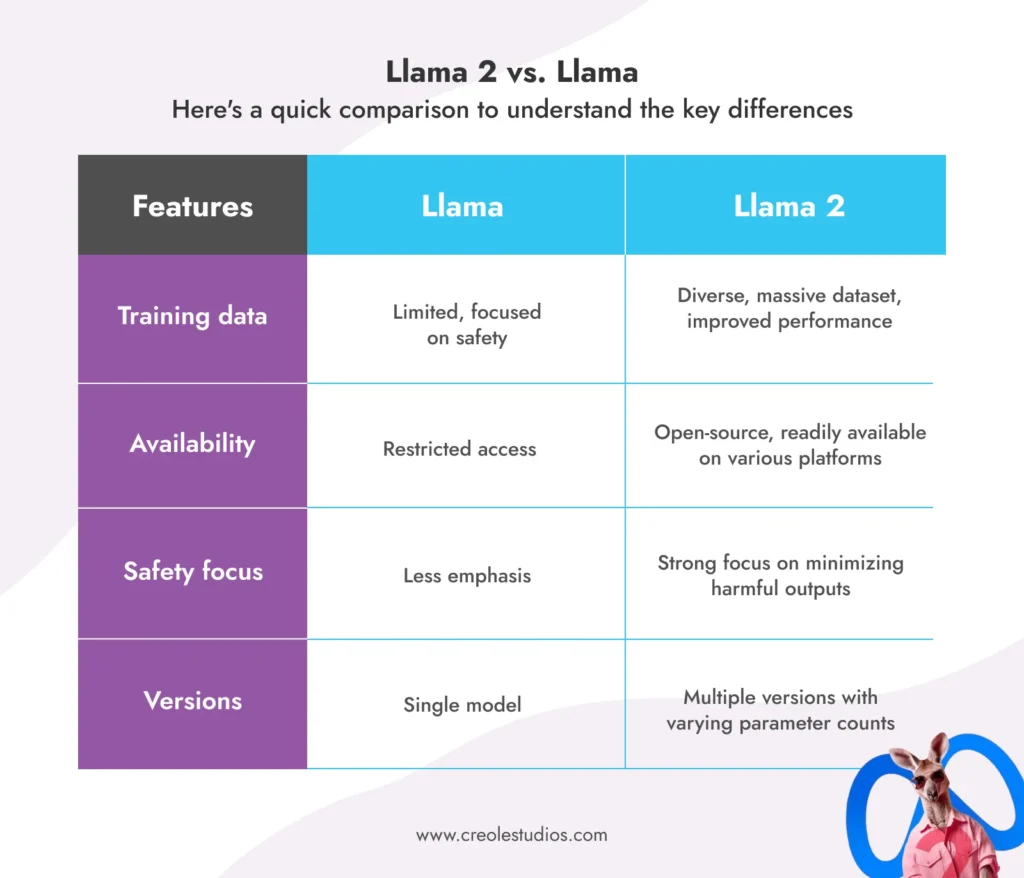
Llama 2 の潜在的な用途:
- チャットボットと仮想アシスタント: 対話機能の向上により、より自然で魅力的な対話が可能になります。
- テキストの生成とクリエイティブ コンテンツ: 詩、スクリプト、コードなどのさまざまなクリエイティブ形式を生成し、ライターやアーティストを支援します。
- コード生成とプログラミング: コード補完やバグ検出などのタスクで開発者を支援します。
- 教育と研究: 学習体験をパーソナライズし、教育コンテンツを生成し、さまざまなタスクで研究者を支援します。
- ビジネスとマーケティング: チャットボットを通じて顧客サービスを強化し、マーケティング キャンペーンをパーソナライズし、顧客データを分析します。
制限事項と考慮事項:
- すべての LLM と同様、Llama 2 はまだ開発中であるため、不正確または偏った出力を生成する可能性があります。
- 潜在的な誤用や偏見を避けるためには、責任を持って倫理的に使用することが重要です。
- バージョンが異なると必要な計算リソースも異なるため、適切なバージョンを選択することが重要です。
リソース:
- メタ AI LLAMA ウェブサイト: https://ai.meta.com/blog/large- language-model-llama-meta-ai/
- LLAMA2 に関するメタ AI ブログ投稿: https://ai.meta.com/blog/large- language-model-llama-meta-ai/
- ハグフェイス LLAMA2 モデルカード: https://huggingface.co/models?search=llama
ブルームLLM

グローバル コミュニティの協力的な取り組みから生まれた Bloom LLM は、オープンソース AI の分野で真の勢力となっています。 ここでは、その主な機能、潜在的なアプリケーション、およびそのユニークな点を包括的に説明します。
ブルームLLMとは何ですか?
BLOOM は大規模な多言語 LLM であり、1,760 億のパラメーターを誇り、46 の言語と 13 のプログラミング言語という驚異的な言語でトレーニングされています。 Hugging Face と 70 か国以上の研究者が参加する 1 年間にわたる共同プロジェクトを通じて開発された BLOOM は、オープンソース AI の精神を体現しています。
BLOOM の主な特徴:
- 多言語能力: 一般的な英語中心のモデルを超え、46 もの言語で一貫性のある正確なテキストを生成します。
- オープンソース アクセス: ソース コードとトレーニング データの両方が公開されており、透明性とコミュニティ主導の改善が促進されます。
- 自己回帰テキスト生成: テキスト シーケンスをシームレスに拡張して完成させるため、さまざまな創造的で有益なタスクに最適です。
- 膨大なパラメータ数: 1,760 億のパラメータを備えた BLOOM は、最も強力なオープンソース LLM の 1 つにランクされ、優れたパフォーマンスを提供します。
- グローバル コラボレーション: このモデルの開発は、AI テクノロジーの進歩における国際協力の力を実証しています。
- 無料のアクセシビリティ: Hugging Face プラットフォームを通じて誰でも BLOOM にアクセスして利用でき、最先端の AI ツールへのアクセスが民主化されます。
- 産業規模のトレーニング: 大量の計算リソースを使用して膨大な量のテキスト データをトレーニングし、堅牢なパフォーマンスを保証します。
BLOOM の潜在的な用途:
- 多言語コミュニケーション: テキストを翻訳し、言語固有のコンテンツを生成することで、異文化コミュニケーションを促進します。
- クリエイティブライティングとコンテンツ生成: 詩、台本、コード、楽曲などのさまざまな形式で作家やアーティストを支援します。
- 教育と研究: 学習体験をパーソナライズし、教材を作成し、さまざまな分野にわたる研究活動をサポートします。
- ビジネスとマーケティング: 多言語チャットボットで顧客サービスを強化し、マーケティング キャンペーンをパーソナライズし、データを効果的に分析します。
- オープンソース AI 開発: オープンソース AI のさらなる研究開発の基盤として機能し、コミュニティのイノベーションを促進します。
BLOOM のユニークな点は何ですか?
- 多言語重視: 主に英語に重点を置いた多くの LLM とは異なり、BLOOM の多言語機能は、グローバルなコミュニケーションと理解のための新たな可能性を開きます。
- オープン性と透明性: コードとトレーニング データへのパブリック アクセスにより、モデルの改善と利用に広範な参加が可能になります。
- 共同開発: グローバルなコラボレーションによるモデルの作成は、オープンソース AI が地理的および文化的障壁を埋める可能性を示しています。
制限事項と考慮事項:
- すべての LLM と同様、BLOOM はまだ開発中であるため、不正確または偏った出力を生成する可能性があります。 責任を持って倫理的に使用することが重要です。
- BLOOM を効果的に利用するには、ある程度の技術的な知識とその機能の理解が必要です。
- モデルのサイズが大きいため、特定のタスクには大量の計算リソースが必要になる場合があります。
リソース:
- BigScience BLOOM ウェブサイト: https://huggingface.co/bigscience/bloom-intermediate
- ハグフェイス BLOOM モデルカード: https://bigscience.huggingface.co/blog/bloom
- BLOOM に関する BigScience ブログ投稿: https://huggingface.co/bigscience/bloom
- GitHub 上の BLOOM モデル カード リポジトリ: https://github.com/bigscience-workshop/model_card
GPT-NeoX-20B

これは、注目を集めているもう 1 つのオープンソース LLM であり、驚くべき機能と可能性を示しています。 その主な機能、長所、および潜在的な用途の内訳は次のとおりです。

GPT-NeoX-20Bとは何ですか?
- EleutherAI によって開発された GPT-NeoX-20B は、テキストとコードの大規模なデータセットである Pile でトレーニングされた 200 億パラメーターの自己回帰言語モデルです。
- そのアーキテクチャは GPT-3 から借用していますが、パフォーマンスと効率を向上させるために大幅な最適化が行われています。
- GPT-NeoX-20B は、いくつかの分野で優れています。
- フューショット推論: 限られた例からの情報を理解し、適用する必要があるタスクで非常にうまく機能します。
- 長い形式のテキストの生成: 長いシーケンスであっても、一貫性があり文法的に正しいテキストを生成します。
- コードの生成と分析: コードを理解して生成し、開発者のさまざまなタスクを支援します。
GPT-NeoX-20Bの強み:
- オープンソース: モデルのコードと重みは公開されており、コミュニティの貢献と研究が奨励されています。
- 効率的なトレーニング: DeepSpeed ライブラリを利用して効率的なトレーニングを行い、他の LLM と比べて必要な計算リソースが少なくなります。
- 強力な少数ショット学習: データが限られたタスクで非常に優れたパフォーマンスを発揮し、多様なシナリオに適応できます。
- 長い形式のテキストの生成: 長いシーケンスであっても、一貫性があり文法的に正しいテキストを生成します。これは、クリエイティブな執筆やコンテンツの生成に最適です。
- コードの生成と分析: コードを理解して生成し、バグ検出、コード補完、その他のタスクで開発者を支援する可能性があります。
GPT-NeoX-20B の潜在的なアプリケーション:
- パーソナル アシスタントとチャットボット: 複雑な質問やリクエストを理解し、応答する能力を強化します。
- クリエイティブライティングとコンテンツ生成: 作家やアーティストが詩、台本、楽曲などのさまざまなクリエイティブ形式を生成できるように支援します。
- 教育と研究: 学習体験をパーソナライズし、教育コンテンツを生成し、さまざまな分野の研究をサポートします。
- ソフトウェア開発: コード補完、バグ検出、コード分析などのタスクで開発者を支援します。
- オープンソース AI 研究: オープンソース AI のさらなる研究開発の基盤として機能し、イノベーションを促進します。
制限事項と考慮事項:
- すべての LLM と同様、GPT-NeoX-20B はまだ開発中であるため、不正確または偏った出力を生成する場合があります。 責任を持って倫理的に使用することが重要です。
- その可能性を最大限に活用するには、ある程度の技術的な知識とその機能の理解が必要になる場合があります。
- モデルのサイズによっては、特定のタスクに大量の計算リソースが必要になる場合があります。
リソース:
- EleutherAI GitHub リポジトリ: これは GPT-NeoX-20B の公式リポジトリであり、ソース コード、トレーニング スクリプト、および事前トレーニングされたモデルを見つけることができます。 (出典: https://github.com/EleutherAI/gpt-neox)
- Hugging Face モデル カード: Hugging Face モデル カードは、GPT-NeoX-20B の機能、制限事項、ベンチマーク結果など、GPT-NeoX-20B の包括的な概要を提供します。 (出典: https://huggingface.co/EleutherAI/gpt-neox-20b)
- EleutherAI のブログ投稿: EleutherAI によるこのブログ投稿では、GPT-NeoX-20B を紹介し、そのアーキテクチャとトレーニング プロセスについて説明し、その潜在的なアプリケーションのいくつかに焦点を当てています。 (出典: https://www.opensourceforu.com/2022/04/eleutherai-releases-gpt-neox-20b-a-20-billion-parameter-ai- language-model/)
MPT-7B

MPT-7Bは MosaicML Pretrained Transformer の略で、MosaicML Foundations によって開発された強力なオープンソース LLM です。 70 億のパラメータを誇り、1 兆トークンの大規模なデータセットでトレーニングされているため、LLM 環境において有能な競争相手となっています。 以下に、その主な機能と潜在的なアプリケーションの内訳を、さらに詳しく調べるための関連情報源とともに示します。
主な特徴:
- 商用ライセンス: 多くのオープンソース モデルとは異なり、MPT-7B は商用利用がライセンスされており、企業がその機能を活用できるようになります。
- 広範なトレーニング データ: 1 兆トークンの多様なデータセットでの MPT-7B のトレーニングにより、さまざまなタスクにわたる堅牢なパフォーマンスと適応性が保証されます。
- 長い入力の処理: このモデルは、精度を損なうことなく非常に長い入力を処理できるため、長い文書の要約などのタスクに最適です。
- 速度と効率: MPT-7B は、迅速なトレーニングと推論のために最適化されており、現実世界のアプリケーションにとって重要なタイムリーな結果を提供します。
- オープンソース コード: モデルの効率的なオープンソース トレーニング コードは透明性を促進し、その開発に対するコミュニティの貢献を促進します。
- 比較優秀性: MPT-7B は、7B ~ 20B パラメーター範囲で他のオープンソース モデルと比較して優れたパフォーマンスを実証し、LLaMA-7B の品質にも匹敵します。
潜在的な用途:
- 予測分析: MPT-7B は大規模なデータセットを分析してパターンと傾向を特定し、ビジネス上の意思決定を通知し、運用を最適化します。
- 意思決定のサポート: このモデルは、分析されたデータに基づいて洞察と推奨事項を提供することで、複雑な意思決定プロセスを支援します。
- コンテンツの生成と要約: MPT-7B は、詩、スクリプト、コードなどのさまざまなクリエイティブなテキスト形式を生成したり、長い文書を効果的に要約したりできます。
- カスタマー サービス チャットボット: MPT-7B は、自然言語とコンテキストを理解することで、インテリジェントなチャットボットを強化し、カスタマー サービス エクスペリエンスを向上させることができます。
- 研究開発: このモデルは、データを分析し、仮説を生成し、創造的な探索を支援することにより、さまざまな分野での研究活動をサポートできます。
追加のリソース:
- MosaicML MPT-7B ウェブサイト: https://www.mosaicml.com/blog/mpt-7b
- ハグフェイス MPT-7B モデルカード: https://huggingface.co/mosaicml/mpt-7b
- MPT-7B に関する MosaicML ブログ投稿: https://www.mosaicml.com/blog/mpt-7b
Creole Studios でオープンソース LLM を活用する
オープンソースの大規模言語モデル (LLM) は AI を再構築し、ビジネスに柔軟性とイノベーションを提供します。 新しい技術ソリューションを作成し、開発コストを削減するのに最適です。 ただし、データのプライバシーや特定のビジネス ニーズに合わせたカスタマイズなどの課題は複雑になる場合があります。
Creole Studios は、これらの課題を解決するための理想的なパートナーです。 AI と機械学習に関する当社の専門知識は、お客様のビジネスがオープンソース LLM の可能性を最大限に効率的かつ安全に活用できるよう支援できることを意味します。 当社は、お客様固有の目標に合わせたオーダーメイドのソリューションを作成することに重点を置き、急速に進化する AI 環境においてお客様が確実に先を行くことができるようにします。
Creole Studios と提携して、オープンソース LLM の力で AI への取り組みを変革しましょう。