
NoSQL データベースへの参加が複雑な理由
公開: 2022-11-19NoSQL データベースは、従来のリレーショナル データベースに代わるものとして人気が高まっています。 ただし、リレーショナル データベースの重要な機能の 1 つは、テーブル間で結合を実行できることです。 では、NoSQL は結合をサポートしていますか? 答えは、場合によります。 結合をサポートする NoSQL データベースもあれば、サポートしない NoSQL データベースもあります。 また、結合をサポートしている場合でも、結合の実装方法は大きく異なる可能性があります。 それでは、NoSQL データベースで結合がどのようにサポートされているかを詳しく見てみましょう。 結合をサポートしているものに移る前に、結合をサポートしていないものを調べることから始めます。
従来のリレーショナル データベースで使用される一般的な結合演算子は、Oracle NoSQL Database ではサポートされていません。 ただし、同じテーブル階層のメンバーであるテーブル間での一意の種類の結合の使用はサポートされています。 同じ場所にある行のみをリンクできるため、これらの結合は効率的に実行できます。
現在、Oracle NoSQL Database は、従来のリレーショナル データベースで使用される一般的な結合演算子をサポートしていません。
コレクションで結合操作を実行するために使用できる新しいルックアップ操作のおかげで、MongoDB 3.2 で MongoDB 結合を実行できるようになりました。
Mongodb サポートは参加しますか?
Mongodb は結合をサポートしていませんが、手動参照リンクはサポートしています。 $lookup 演算子を使用して、2 つのコレクションに対して左結合、右結合、または完全外部結合を実行できます。
MongoDB は左外部結合をサポートしていませんが、$lookup ステージを使用してサポートできます。 $lookup ステージを選択することで、どのコレクションをどのフィールドと結合させ、どのようにコレクションを比較するかを指定できます。 $lookup ステージを使用して、employees コレクション フィールドでフィールド employee_id および order_id を選択し、employee コレクションを orders コレクションと一緒にすることを指定することにより、同じコレクションの employee コレクションと orders コレクションを追加できます。 互いに同一の従業員 ID と注文 ID が返されます。
力を合わせる: 1 人の学生がどのように成績を上げたか
var grade は var grade を示します。 学生の成績を見つけるためのデータ。 grades.join 生徒; ・学生の成績を知るためのデータ 全学生におけるユーザ1の成績が返される。
リレーションと結合をサポートしていない Nosql データベースはどれですか?
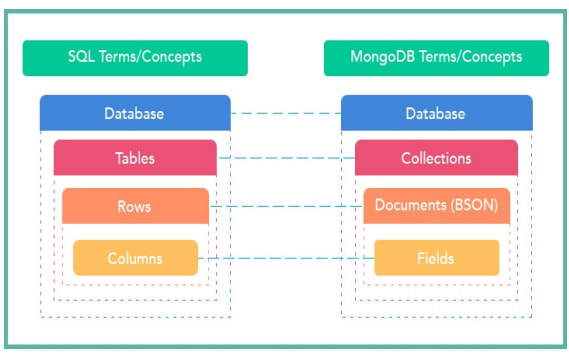
MongoDB は最も一般的な非リレーショナル データベースであり、結合をサポートしていません。
NoSQL データベースは、ドキュメントやキーと値のペアなどの非構造化形式でデータを格納するための優れたツールです。 リレーショナル データベースのデータは、構造化され正規化された方法で格納する必要があります。 適切に定義されたデータベースは、リレーショナル データベースと組み合わせて使用すると、場合によっては利点があります。 NoSQL データベースは、構造化されたデータ形式に準拠していないデータベースであり、そのように呼ばれます。 NoSQL データベースが水平方向にスケーリングできるのは、パーティション トレランスの基盤によるものです。 データベースは結合クエリの構造を指定しないため、結合クエリもあまり得意ではありません。 ノーコード データ パイプラインである Hevo Data は、NoSQL データベースやその他の種類のデータの統合とレプリケーションを可能にします。
ここには万能のソリューションはありません。検討している用途の特性に基づいて決定する必要があります。 以下は、リレーショナル データベースと NoSQL の間の決定に影響を与える主な要因の一部です。 大規模なデータベースでのデータ処理が必要な場合は、できるだけ早く NoSQL データベースを使用する必要があります。 NoSQL データベースでの書き込みは、可能な限り予測可能になる傾向があります。 したがって、すべてのノードがデータを受信するまで、アプリケーションは古いデータを読み取ることが期待できます。 RDBMS は、さまざまなクエリと結合機能、および複雑な結合をサポートしています。 データが使用されるのと同じ形式で格納されている場合は、NoSQL データベースを使用することをお勧めします。
一般に、リレーショナル データベースで大量のデータを処理するには、ハイエンドのハードウェアが必要です。 これは、分散データベースの実装に十分なデータ ボリュームがある場合にのみ有効です。 Hevo は、一般的に使用されるソース データベースとターゲット データベースからのデータの複製と読み込みを容易にする非コード データ パイプラインです。 このようなコピー操作に Hevo を使用すると、開発者やアナリストはコア ビジネス ロジックに集中しながら、可能な限り低い速度でコピー操作を行うことができます。 Hevo は素晴らしい人で、試してみたいと思っています。 Hevo スイートを 14 日間無料で試用して、知っておくべきことをすべて学ぶことができます。
MongoDB は、大量のデータを含む NoSQL データベースを使用する場合に最適です。 このプログラムを使用すると、さまざまなプログラミング言語、多数のデータ型、および堅牢な管理システムを使用できるなど、多くの利点があります。
使い始めたばかりの場合、MongoDB は優れた選択肢です。使い方が簡単で、プログラミングの知識があまり必要ないからです。 さらに、MongoDB は安価で広く利用できるため、MongoDB をホストするサーバーを簡単に見つけることができます。
一般に、大量のデータを処理できる NoSQL データベースに関しては、MongoDB が明らかに勝者です。
Mongodb が Join をサポートしないのはなぜですか?
MongoDB は NoSQL データベースであるため、結合をサポートしていません。 NoSQL データベースは、スケーラブルで大量のデータを処理できるように設計されています。 また、柔軟に設計されているため、特定のアプリケーションのニーズに合わせて簡単に変更できます。
MongoDB はオープンソースの NoSQL データベースであり、大量のデータを格納するために使用できます。 従来のデータベースではテーブルと行が使用されますが、MongoDB ではコレクションとドキュメントが使用されます。 キーと値のペアは、データベースの構成要素である MongoDB ドキュメントによって使用されます。 この記事では、このブログで説明した主要な Join および Lookup コマンドのタイプである MongoDB Join を使用します。 MongoDB 3.2 の新しい Lookup 操作は、コレクションに対して Join 操作を実行できます。 相関サブクエリの簡潔な構文は、MongoDB 5.0 以降で使用できます。 MongoDB 結合を使用する場合、いくつかの制限または制限があります。
次のスニペットは、次のドキュメントに基づいてコレクション、レストラン、および注文を作成します: 関心のあるコレクションを注文します。 レストランの名前と住所を入力してください。 各注文の名前は、それらの間の $in 配列の一致と一致する必要があります。 飲み物と飲み物は次の順序で記載されています。 出力は以下のとおりです。
Mongodb: 結合はありませんが、$lookup は回避策を提供します
MongoDB データベースは非リレーショナルであるため、結合をサポートしていません。 結合機能はリレーショナル データベースの一般的な機能ですが、MongoDB はそれをサポートすることを意図していません。 その結果、結合に高価なマシンを使用する必要がないため、データベースはより効率的かつ高速になります。 この関数により、MongoDB の $lookup (集約) 関数を使用してコレクションにドキュメントを含めることができます。 その結果、データがマージされると、関数はコレクションとの左結合を作成し、両方のコレクションからのデータをフィルター処理できるようにします。
Nosqlに当てはまらないのはどれ?
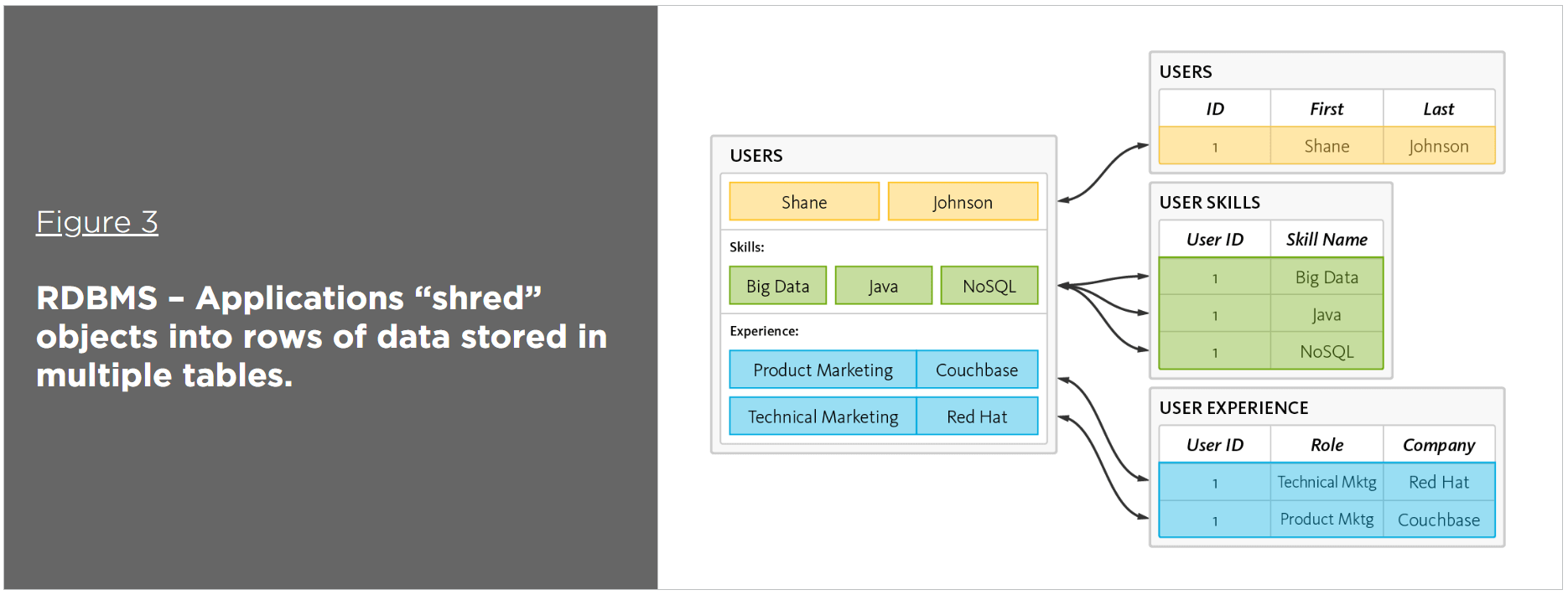
Nosql は、リレーショナル データベースの従来の表形式スキーマを使用しない非リレーショナル データベースです。 多くの場合、リレーショナル データベースには適していない大量のデータを格納するために使用されます。
それぞれの長所と短所に基づいて、どちらが最適なオプションであるかを判断する必要があります。 このタイプのデータベースでは、表形式ではなく非リレーショナルな方法でデータを管理できます。 NoSQL データベースは 4 つのタイプに分類できます。 ドキュメント データベースは、連想配列 (マップまたは辞書) を使用して作成され、データ モデルによって表された一連のキーと値のペアを表します。 それらをセッション管理とキャッシングに使用する Web アプリケーションでは、非常に便利です。 グラフ ストアは、ノードおよびエッジとしての機能に基づいて、データをノードおよびエッジとして編成します。 このようなモデルは、顧客関係管理システム、ロードマップ、予約システムなど、さまざまな業界で役立ちます。
NoSQL データベースの人気は、ビッグ データ、低コスト、シンプルなスケーラビリティ、およびオープン ソース機能を統合する能力に由来しています。 NoSQL データベースのセキュリティ機能は、機能が制限されているため制限されています。 好み、ビジネス要件、データの量、および種類はすべて、最適なデータベースに影響します。
ただし、NoSQL は、金融取引などの ACID プロパティを保証する必要があるアプリケーションでは使用しないでください。 このような場合は、SQL データベースへの移行を検討する必要があります。 ランタイムに柔軟性が必要な場合は、NoSQL を避ける必要があります。
Nosql データベース: 画一的なソリューションではない
NoSQL データベースは万能のソリューションではありません。 単一のサーバーに格納された厳格な集中型データ モデルに制約されないため、さまざまなサーバー サイズに分散できる異種のデータベース モデル タイプを接続できます。 NoSQL はトランザクションをサポートしていませんが、これはさまざまなアプリケーションで実装できないという意味ではありません。 NoSQL データベースを使用すると、表形式ストレージ以外の任意の形式でデータを保存および取得できるため、表形式ストレージ以外のさまざまな形式でデータにアクセスおよび保存できます。 データのフェッチまたは格納に外部テーブルは必要ありません。
同等の Nosql 結合
Nosql 結合同等物は、2 つ以上の nosql データ ソースからのデータを結合する方法です。 これは、データの 1 つのビューを作成するために複数のソースからのデータを結合する必要がある場合に便利です。 たとえば、顧客の注文を示すレポートを作成するために、顧客データベースと注文データベースのデータを組み合わせる必要がある場合があります。

どちらのタイプのデータベースも、正しく機能するために結合操作が必要です。 この記事では、MySQL リレーショナル データベースと NoSQL データベース (MongoDB) を比較します。 キーワード $lookup を使用して結合操作を実行するには、集約パイプラインを使用できます。 場合によっては、クエリで両方のデータベースを結合する必要があります。 MongoDB の集計パイプラインは、フィルタリング、並べ替え、グループ化などのさまざまな機能を 1 つのパイプラインで実行するために使用できるため、特に便利です。 通常の select ステートメントでは、選択する列の名前のみを記述します。 テーブルを結合するとき、SQL が理解するテーブルの列に使用される列を指定します。
$lookup 操作の結合段階で、場所に基づいてグループ化されるドキュメントの ID として「$location」を選択します。 次に、次のセクションで説明するように、関数 $avg と、集計する必要があるフィールドを指定します。 フィルタリング基準を使用するには、最初に $match ステージをパイプラインに追加する必要があります。
Postgres は結合に最適なデータベースです
結論として、PostgreSQL は他のどのデータベースよりも優れたパフォーマンスと安定性を備えています。
Mongodb が参加
MongoDB Join を使用すると、異なるコレクションのドキュメントを 1 つのクエリで組み合わせることができます。 これは、1 回の操作で複数のコレクションからデータを取得する必要がある場合に役立ちます。 たとえば、Join を使用してユーザー コレクションと投稿コレクションのデータを結合し、すべてのユーザーからのすべての投稿のフィードを作成できます。
MongoDB は公式には参加に対応していません。 これは、2 つのコレクションを一緒に接続できないということですか? これについてお答えいただければ幸いです。 この空間で参照を解決するには、2 つの方法があります。 独自の関数を作成して手動で問題を解決するか、自動化することができます。 あるいは、MongoDB は DBRef を使用できます。これにより、クライアントごとに関係を管理できます。 MongoDB の参照動作は、結合ではなく、遅延読み込みに非常に似ています。
mongodb.org Web サイトでスキーマ設計に関する講演を視聴できます。 MongoDB のような nosql データベースを使用する場合は、スキーマを実装する必要があります。 その結果、コレクションに対する SQL データベースの外観がますます少なくなります。 このパッケージを使用すると、サーバー側のコンポーネントを追加できます (これを行う他のフレームワークはわかりません)。 MongoDB には結合はありませんが、たとえば、他のコレクション内のドキュメントへの参照が必要です。 StackOverflow の使用は、この StackOverflow answer の手順に従うだけで簡単です。
Mongodb の速度にはいくつかの制限があります
その速度にもかかわらず、MongoDB にはいくつかの欠点があります。 制限の 1 つは、クロスリンクをサポートしていないことです。 その結果、集計データなどに関しては、個別に行う必要があります。 これはリレーショナル データベースよりも低速ですが、それでも非常に高速です。
Nosql データベース
Nosql データベースは、ほとんどのデータベースで使用されている従来のリレーショナル モデルを使用しないタイプのデータベースです。 代わりに、キー値ストア、ドキュメント ストア、またはグラフ ストアを使用します。 これにより、nosql データベースはリレーショナル データベースよりもスケーラブルで柔軟になります。
従来のデータベースに対する NoSQL データベースの主な利点は、柔軟性が高いことです。 NoSQL データベースは、通常複数行のデータを含むリレーショナル データベースとは対照的に、ドキュメントなどの単一のデータ構造にデータを格納します。 このデータベース設計は、大規模で通常は構造化されていないデータ セットを管理するためのスキーマを必要としないため、非常にスケーラブルです。 NoSQL データベースはデータを共有しないため、テーブルをリンクできません。 データ構造が多様であるため、NoSQL は、データ分析、ソーシャル ネットワーク、モバイル アプリなど、さまざまな分野で使用される可能性があります。 データベースの種類ごとに独自の特性セットの利点があるという事実にもかかわらず、ほとんどの企業は NoSQL データベースとリレーショナル データベースを使用しています。 ドキュメント データベースはデータをドキュメントとして保存するため、アプリケーションで使用するときにデータが整理されます。
ドキュメント データベースは、コンテンツ管理システムとユーザー プロファイルに頻繁に使用されます。 幅の広い列のデータベースの主な利点は、列にデータを格納し、ユーザーが必要なときにのみ特定の列にアクセスできることです。 これらのタイプのデータベースには、Apache Cassandra と Apache HBase が含まれます。 グラフ データベースは、グラフ内の要素間の接続のネットワークを管理および格納するために使用されます。 メモリベースのデータベースは、ディスクではなくデータを格納するため、より高速にアクセスできます。 アプリケーション全体に対して単一の共有データ ストアが不要になるため、マイクロサービスは実行可能なオプションです。 PaaS および NoSQL データベースは、さまざまなアプリケーションで IBM から入手できます。 IBM Data Management Platform for MongoDB Enterprise Advanced を IBM Cloud Pak for Data に無料で追加します。 このサービスは、Apache CouchDB、PouchDB、ライブラリ エコシステム、および一般的な Web およびモバイル開発スタックと互換性があります。
全体として、NoSQL データベースは、スケールとパフォーマンスの欠如によって妨げられてきました。 現在、これらの制限に対処し始めている革新的なスタートアップや主要なビジネスがあります。
スケールアウト データベースは、最も広く使用されているタイプの NoSQL データベースです。 このアーキテクチャにより、マスターレス コンピューティングが使用されているにもかかわらず、データの複数のコピーを複数のノード タイプに保存できます。 このテクノロジーは、ダウンタイムを回避する場合に不可欠な大規模なスケーラビリティを実現します。
この機能により、複数の場所にデータを保存でき、高可用性と災害復旧に不可欠です。 データ ウェアハウジングおよびマルチテナンシー環境を作成する場合も、データ レプリケーションが必要です。
NoSQL データベースのもう 1 つの重要な機能は、柔軟なデータ構造を作成できることです。 さらに、新しいデータ型を簡単に追加したり、それらを使用して簡単にデータを操作したりできます。 これは、データ ウェアハウジングと新しいアプリケーションの迅速な開発にとって重要です。
Nosql データベースの利点
NoSQL データベースに格納されるデータは、さまざまな方法で格納できるため、より一般的なタイプのデータベースになっています。 非構造化データだけでなく、あらゆるタイプのデータを保存するために使用できます。 大規模なデータ処理に関しては、従来のデータベースよりも効率的です。
NoSQL データベースでは、格納できるデータの種類に制限はありません。 さらに、データはファイルまたはグラフ データベースに保存できます。
Oracle Nosql データベース
Oracle NoSQL Database は、スケーラブルな分散型NoSQL データベース サービスであり、高パフォーマンス、高可用性、および自動シャーディングを提供します。 Oracle NoSQL Database は、Oracle Berkeley DB Java Edition に基づいており、データベースにアクセスするための単純な Java API を提供します。
Spring Data は、Oracle NoSQL SDK for Spring Data を使用して実装できます。 これを使用して、Oracle NoQL DatabaseクラスタまたはOracle NoQL Cloud Serviceに接続できます。 プロジェクトの phar.xml で maven 依存関係を使用すると、SDK にアクセスできます。 これらは、利便性のための最良のオプションの一部です。 www.oracle.com/nosql 次のメソッドを取得します: NosqlDbConfig。 エンティティ クラスは次のように定義できます。 Nosql 拡張機能のリポジトリを作成することをお勧めします。 アプリケーション クラスを作成することから始めることができます。 org.springframework.boot:spring-boot に依存関係をインストールする必要があります。
Mongodb の多くの利点
MongoDB は、フルテキスト ファイルと構造が埋め込まれたドキュメントを検索できる唯一のデータベースです。
Catch … Mongodb アグリゲーション
Mongodb の集約機能を使用すると、ドキュメントをグループ化して、データの分析を実行できます。 これは、データに関するさまざまな質問に答えるために使用できる強力な機能です。 たとえば、集計を使用して、すべての顧客の製品の平均価格を決定したり、場所ごとに顧客をグループ化したりすることができます。
MongoDB の集約フレームワークは、あらゆるタイプのデータを処理できます。 式演算子の名前は、引数の配列または単一の引数のいずれかで見つけることができます。 アキュムレータの最も一般的な用途の 1 つは、合計、最大値、最小値、および特殊な式でのその他の値の計算です。 一部のアキュムレータは、状態を維持しないため、他のステージで使用できますが、アキュムレータとしては使用できません。 $let 演算子は、var と式の 2 つの部分で構成されており、変数を割り当てて計算に使用することができます。 内部で定義されているが vars で変更された変数は、元の値のみが表示されるため、値を変更しません。 パイプラインを保存すると、後で Compass 内で再読み込みできます。
MongoDB Compass には、集約 Pipeline Builder などの集約用のツールがいくつか含まれています。 集約パイプラインは、問題を小さなチャンクに分割します。 パイプラインは、デバッグやプロトタイピングの段階でコメントするためにも使用できます。 パイプラインのパフォーマンスを向上させるには、ブロッキング ステージを慎重に設計する必要があります。 MongoDB 2.2 シェルには、aggregate() ヘルパーで完全に実装された集約フレームワークが含まれています。 MongoDB 1.14 には、MongoDB Aggregation Pipeline Builder が含まれています。 ステージは、$graphLookup、$bucket、$facet、$addFields、および $replaceRoot の追加により改善されました。 インポート/エクスポートは、Compass 1.15 (2018 年 8 月) で利用できる機能になりました。 2018 年 11 月に MongoDB 4.2 がリリースされ、2019 年 1 月に MongoDB 4.4 がリリースされました。
Mongodb: アグリゲーションの優れた選択肢
MongoDB データベースは、幅広いデータ型を処理できるため、データ集約に最適です。 Export Aggregation Results を使用すると、データ結果をさまざまな形式に簡単にインポートできます。 MongoDB は、大規模なコレクションを操作する場合は遅くなる可能性がありますが、インデックスのない $lookup を操作する場合は高速になる可能性があります。