
Nosql データベースがビッグデータに適している理由
公開: 2022-11-19Nosql データベースは、多くの理由でビッグ データに適しています。 水平方向に拡張できるように設計されているため、サーバーを追加することでより多くのデータを処理できます。 また、可用性が高くなるように設計されているため、一部のサーバーに障害が発生しても実行し続けることができます。 また、高いスループットを処理できます。つまり、多くの読み取りと書き込みを処理できます。
NoSQL データベースの使用は、RDBMS の欠点に対応して、Amazon、Google、LinkedIn、Facebook などのインターネット企業の間で人気がありました。 データ処理要件が増大するにつれて、NoSQL は非構造化データを管理するための適応可能なクラウドベースのソリューションです。 FairCom のビジネス開発ディレクターである Esprdo de Oliveira 氏によると、NoSQL には従来のデータベースでは処理できない問題がいくつかあります。 これは、クラウド、Web、ビッグデータ、およびビッグ ユーザーでデータベース テクノロジを推進するために使用されます。 NoSQL データベースは、さまざまな方法でデータを格納するデータベースのサブセットです。 最も一般的なタイプは、グラフ、キーと値のペア、列、およびドキュメントです。 Amazon や eBay などのデータに大きく依存している企業は、変化するデータ モデルに最適な NoSQL や SQL などのデータベースを必要とし、より効率的に運用を管理できるようにしました。
リアルタイムのデータ ストレージと処理は、リレーショナル データベースよりもはるかに洗練された NoSQL データベースによって実現できます。 データの速度と種類の増加により、データベースのランドスケープは、データ速度の高速化、データの種類の拡大、およびデータの爆発的な量であふれています。これらはすべて、ビッグ データ アプリケーションに必要です。 HBase、Cassandra、Couchbase などの NoSQL データベースは、CAP の優先度 (Consistency-Availability-Partition Tolerance) の概念が NoSQLデータベースの概念です。
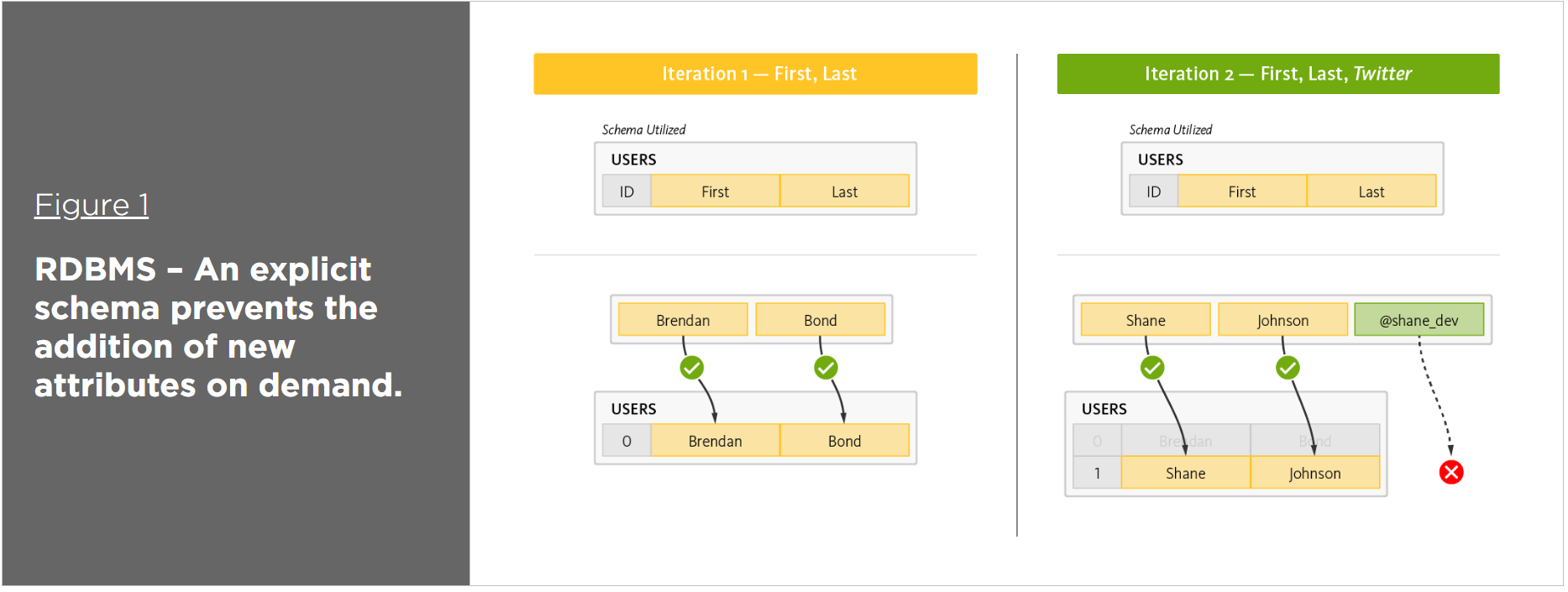
リレーショナル データベースでは、データベース スキーマは固定されています。 NoSQL データベースには一貫性がありません。 NoSQL データベースにはトランザクションはありません (単純なトランザクションのみをサポートします)。 リレーショナル データベースでは、トランザクション (および結合を伴う複雑なトランザクション) がサポートされています。
近年 NoSQL データベースの人気が高まっているのには理由があります。NoSQL データベースは理解しやすく、SQL データベースのような複雑なデータ モデルを必要としません。 さらに、NoSQL データベースでは、開発者がデータ構造を直接変更できることがよくあります。
開発者は、高速なクエリ結果、柔軟なデータ モデル、水平方向のスケーリング、合理化された開発プロセスなど、さまざまな方法で NoSQL データベースからメリットを得ることができます。 ドキュメント データベース、キー値データベース、ワイド カラム ストア、グラフ データベースは、NoSQL データベースのほんの一例です。
Nosql は大規模データに適していますか?
ビッグ データのストレージ ソリューションは、大量のデータを処理および分析するために処理および格納できることが重要です。 非リレーショナル データベースとも呼ばれる NoSQL データベースは、水平方向にスケーリングしながら大量のデータを処理するように構築されています。
MongoDB と Apache Cassandra と HBase が示すように、NoSQL データベースはこれまでにない成長を遂げてきました。 オープン ソース ソフトウェアと比較して、NoSQL は、大量の多様で構造化されていないデータの迅速な処理と分析を必要とするビジネスに適しています。 これらのデータベースは、応答性、スケーラビリティ、および可用性が従来の RDBMS 製品よりも優れています。 NoSQL データベースは、大量の構造化、半構造化、および非構造化データ ファイルとセットを、特にリアルタイムで保存および分析したい組織に好まれています。 クラスター内のデータが増大するにつれて、より多くの物理サーバーが必要になります。 NoSQL データベースは、効率的な水平スケーリング アーキテクチャを使用します。 NoSQL データベースは、オープンソースであるため、従来のデータベースよりもトランザクションあたりのコストが低くなります。 NoSQL と RDBMS、およびそれらの長所を組み合わせて使用すると、効率的なデータ管理システムを作成できます。
大規模データに最適なデータベースはどれですか?
ユーザーの特定のニーズ、保存されるデータの種類、予算など、さまざまな要因に依存するため、この質問に対する明確な答えはありません。 ただし、大規模なデータ セットに広く使用されているデータベースには、Apache Hadoop、Apache Cassandra、MongoDB などがあります。
Nosqlが優れている理由

現代のデータ管理に NoSQL が適している理由はたくさんあります。 まず、NoSQL データベースは、水平方向のスケーリング機能により、大規模なデータの処理に非常に優れています。 また、ビッグデータ ソリューションと簡単に統合することもできます。 次に、NoSQL データベースは従来のリレーショナル データベースよりも豊富なデータ モデルを提供するため、複雑なデータの処理に適しています。 最後に、NoSQL データベースは一般に、リレーショナル データベースよりもはるかに使いやすく、メンテナンスも少なくて済みます。
データは、すべてのデータ サイエンス サブフィールドの重要な要素です。 データベース管理システム (DBMS) にデータを格納する必要が生じる可能性が高くなります。 DBMS と対話および通信する場合は、その言語が必要です。 SQL (Structured Query Language) は、DBMS と対話するために使用される言語です。 データベースの分野で最近出現したもう 1 つの用語は、NoSQL データベースです。 非リレーショナル データベースなどの NoSQL データベースは、テーブルやレコードにデータを格納しません。 代わりに、データ ストレージ構造は、特定の要件を満たすように構成されます。
最も一般的な 4 つのタイプは、グラフ データベース、列指向データベース、ドキュメント指向データベース、およびキーと値のペアです。 MongoDB などのドキュメント指向データベースは、Python データベースの例です。 NoSQL データベースを使用すると、より簡単にデータ構造を作成できます。 一方、SQL データベースの構造はより厳密であり、データの種類はより少なくなります。 初心者として SQL を学びたい場合は、SQL から始めて、次に NoSQL に進みます。 これらの各プログラムには多数の長所と短所があり、データ、アプリケーション、および開発を容易にするものに基づいて、それらの長所と短所を検討する必要があります。 SQL が NoSQL やその書き方よりも優れていることは間違いありません。 データに耳を傾ければ、最善の決定を下すことができます。

ビッグデータの Sql と Nosql
また、複雑なクエリを処理する場合、SQL の方が速度と回復性が高いため、パフォーマンスが向上します。 ただし、RDBMS の標準構造を拡張したり、柔軟なスキーマを作成したりする場合は、NoSQL データベースが最適です。
データベースへの投資を最大限に活用するには、リレーショナル データベース (SQL) または非リレーショナル データベース (Nosql) のいずれかを選択することが重要です。 プロジェクトに必要なデータベースの種類について十分な情報に基づいて決定するには、まずこの 2 つの違いを理解する必要があります。 弾力性は NoSQL データベースの重要な要件であるため、NoSQL データベースはビッグ データにより適しています。 要件に応じて、キーと値のペア、ドキュメント ベース、グラフ データベース、またはワイド カラム ストアのいずれかになります。 その結果、各ドキュメントは独自の構造を持つことができるため、構造を定義せずにドキュメントを作成することができます。 NoSQL に関しては、特にビッグデータとデータ分析のコンテキストにおいて、多くの疑問があります。 NoSQL データベースの中には、セットアップと管理に社内の専門知識が必要なものもあれば、コミュニティ サポートに大きく依存しているものもあります。
一般的な規則として、NoSQL は SQL よりも高速ではありませんが、単一のデータ エンティティに対して読み取りまたは書き込み操作を実行する場合は、NoSQL の方が高速です。 NoSQL データベースは大量のデータを処理できるため、Google、Yahoo、および Amazon にとって理想的です。 既存のリレーショナル データベースは、データ処理に対する需要の増加に対応できませんでした。 NoSQL データベースは、必要に応じて成長し、より強力になる可能性があります。 このタイプのアプリケーションは、コンテンツ管理システム、ビッグ データ アプリケーション、リアルタイム分析など、特定のスキーマ定義を持たないアプリケーションに最適です。
Nosql は大規模なデータセットに適していますか?
非構造化データと半構造化データを分析ツールで使用できる形式に変換するのは、彼らの責任です。 これらの独特の要件により、MongoDB などの NoSQL データベース (非リレーショナル) は、大量のデータを保存するための強力な選択肢となっています。
Sql はビッグデータに適していますか?
Hadoop ベースの SQL-on-Hadoop エンジンを使用して、大規模なデータベースを処理できます。 ビッグ データは SQL システムには大きすぎるという神話は、今や反証されており、まったく真実ではありません。 実際、それは神話です。 SQL は、ビッグ データ システムを構築するための優れたフレームワークです。
ビッグデータと Nosql データベースはどのように同じですか?
この 2 つの用語は人によって意味が異なるため、この質問に対する答えは 1 つではありません。 ただし、一般に、ビッグ データ データベースと nosql データベースは、大量のデータを保持するように設計され、従来のリレーショナル データベース モデルに基づいていないデータ ストアを指すために、同じ意味で使用されることがよくあります。
オープン ソースとも呼ばれるデータベース NoSQLは、オープン ソース データベースに基づいています。 NoSQL データベースのカテゴリは、データベースのデータ モデルによって決まります。 各データ モデルは、1 つの Key-Value ストア、1 つのドキュメント、1 つの列 - 入力、および 1 つのグラフ データ モデルで構成されます。 モバイル データベースには、さまざまなデバイスや場所からアクセスできます。 一般的にマルチタスクの傾向もあります。 NoSQL データベースは柔軟性があり、スキーマが固定されていないため、ビッグ データの特徴であるさまざまなデータ特性に対処する際に、従来のデータベースよりも柔軟に対応できます。 データベースの ACID プロパティが原因で、完全なトランザクションが完了しないため、可用性が高くありません。
NoSQL はオープンソースであるため、経済的に実行可能です。 これらすべての利点と業界の台頭により、NoSQL データベースで作業できる人の数が増えるでしょう。 Craigslist は、世界 50 か国の 570 都市にサービスを提供する求人広告および求人情報 Web サイトです。 2001 年に設立されたオンライン教育プラットフォームである Coursera6 は、世界中の大学に教育の機会を提供しています。 NoSQL、Cassandra データベース、および従来のデータベースを使用して、過去 10 年間で 1,000 万人の学生に成長しました。
Nosql データベース: 人気が高まっている理由
NoSQL データベースの特徴は次のとおりです。 その設計により、大量のデータを処理できます。 それらは「スケール」として知られています。 データは、それらを使用してさまざまな方法で処理できます。 これらのデータベースのデータ量は、従来のデータベースよりも多くなります。
Nosql データ分析
NoSQL が「Not Only SQL」の略である理由を理解するのは簡単です。 この場合、データセット全体を単一の構造に含めることができるため、データは複数のテーブルに分割されません。 大量のデータを扱う場合、NoSQL データベースでのクエリ パフォーマンスは問題になりません。
Nosql 対 Sql: ビッグデータに最適なデータベースは?
ビッグデータ分析には NoSQL データベースが必要です。なぜなら、NoSQL データベースは優れた利点を提供するからです。 一方、SQL データベースは、長い間データ分析に使用されてきました。 Looker などのほとんどの BI ツールは NoSQL データベースのクエリ機能をサポートしていないため、これはオプションではありません。
データが非常に構造化されており、ACID 準拠が必要な場合は、SQL が最適なオプションです。 NoSQL は、データ要件を知らない人や構造化されていないデータを持っている人にとって有益かもしれませんが、知っている人にとっても有益です。 NoSQL データベースは、SQL データベースのように事前定義されたスキーマを必要としません。
この柔軟性は、複雑なデータ セットをスムーズに操作し、柔軟な意思決定を促進するために必要です。 さらに、MongoDB は強力なクエリ機能をサポートしており、大量のデータをすばやく分析して取得できます。 R 接続を使用すると、高度なデータ分析をすぐに実行できます。
Rdbms がビッグデータに適していない理由
ノーマライズをなくすことはできません。 データの自動シャーディングは、どのような状況でもほぼ不可能です (悪夢)。 高可用性システムの実装は困難です。
内部のすべての RDBMS (リレーショナル データベース管理システム) ツールは、ビッグ データにおけるその重要性を説明します。 スケーリングが難しいのはなぜですか? これにはいくつかの理由がありますが、主な理由は、私たちが不満を持っていることです。 データベースから目的の結果を抽出するために必要なクエリの複雑さを正確に判断することはできません。 データが弊社システムのメモリサイズよりも大きい場合、弊社では処理できません。 ビッグデータでは、洞察を生み出すために大量のデータをマージする必要があります。 データは複数の場所に保存されているため、RDBMS ツールは効率が悪く、この状況を処理できません。
シャーディングのため参加できません。 シャーディング手順を実行した後、単一のデータ フレームを複数のノードに分割できます。 サービスが常に利用可能な場合、そのサービスは「高可用性」であると見なされ、その特性の一部が満たされない場合、そのパフォーマンスはそれ自体で修正されます。 次のセクションで説明するように、高可用性の実現が非常に難しい理由はさまざまです。
Rdbmss がビッグデータを処理できない理由
ビッグ データは、従来の RDBMS ではサポートされていません。 システムは遅く、データの変動に対処できません。 Hadoop は大量のデータを格納するために使用できますが、この目的のために特別に設計されたわけではありません。