
5 formas de optimizar su base de datos NoSQL
Publicado: 2023-01-12Las bases de datos NoSQL son cada vez más populares, ya que se consideran más escalables y flexibles que las bases de datos relacionales tradicionales . Hay varias formas de optimizar una base de datos NoSQL, que incluyen: 1. Diseñar el esquema cuidadosamente: esto es importante ya que un esquema bien diseñado puede ayudar a mejorar el rendimiento y hacer que los datos sean más manejables. 2. Indexación de datos: esto puede ayudar a mejorar el rendimiento de las consultas. 3. Uso del almacenamiento en caché: el almacenamiento en caché puede ayudar a mejorar el rendimiento al almacenar datos a los que se accede con frecuencia en la memoria. 4. Particionamiento de datos: esto puede ayudar a mejorar el rendimiento y la escalabilidad mediante la distribución de datos entre varios servidores. 5. Monitoreo del desempeño: Esto es importante para identificar cualquier cuello de botella y tomar medidas correctivas.
Jay Patel, un arquitecto de eBay, publicó recientemente un artículo sobre el modelado de datos utilizando el almacén de datos de Cassandra. Explica cómo diseñaron su modelo de datos usando Cassandra, cómo usaron columnas y familias de columnas, y cómo optimizaron los resultados de las consultas mediante la optimización de consultas. Una de mis ideas favoritas de su enfoque es que se puede aplicar a cualquier base de datos NoSQL. Antes de que pueda optimizar su modelo de datos, primero debe comprender cómo se accederá a él. Cuando comienza a notar que sus consultas tardan más, se da cuenta de que su base de datos relacional está experimentando problemas de rendimiento. Cuando los datos se normalizan, es menos probable que se produzcan uniones innecesarias o consultas n+1. Incluso si la desnormalización es posible con los almacenes de datos NoSQL, existen costos asociados con ella.
¿Qué es la optimización de consultas en Nosql?
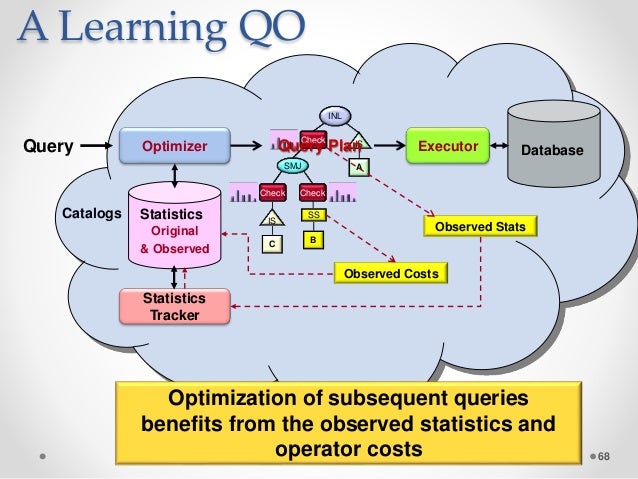
El objetivo de la optimización de consultas es encontrar el plan más eficiente. Al medir la eficiencia, se utilizan la latencia y el rendimiento. Una optimización basada en costos cuesta lo mismo que el costo de la memoria, la CPU y el espacio en disco. En el mundo NoSQL, la mayoría de las bases de datos ahora brindan soporte de lenguaje de consulta similar a SQL.
Una base de datos MongoDB es una base de datos NoSQL que también se conoce como base de datos de documentos. Esta base de datos fue diseñada de tal manera que sería más fácil de desarrollar que otras bases de datos relacionales. Usando la explicación () podemos ver cómo está funcionando nuestra consulta. Puede usar Explicar para crear un documento que incluya planes de consulta, etapas de consulta y más. Como resultado de este artículo, podemos comprender cómo el índice puede alterar las etapas de exploración de una colección específica. El propósito de este artículo es repasar los fundamentos de la optimización. Los detalles detallados de la optimización de la etapa de agregación se tratarán en artículos posteriores. Los negros sobresalen en los campos de la tecnología. Esta colección de recursos destaca algunas de las cosas que debemos saber.
¿Qué hace que Nosql sea rápido?
Las bases de datos Nosql están diseñadas para ser rápidas y escalables. Utilizan una variedad de técnicas para lograr esto, como la escala horizontal, la fragmentación y la desnormalización.
La gran mayoría de los sistemas noSQL son simplemente almacenamientos persistentes de claves o valores (como el Proyecto Voldemort). Si sus consultas son del tipo que requieren que busque un valor de clave dado, un sistema que pueda hacerlo tan rápido como debería hacerlo un RDBMS. Las bases de datos de documentos (como CouchDB) también son sistemas nosql populares. La desnormalización se usa mucho en estas bases de datos para estructurar la estructura de datos. De hecho, creo que el rendimiento de una aplicación se puede medir por la cantidad de partes que requiere para cumplir con un solo requisito. Cuando se usa NoSQL, el rendimiento de una base de datos NoSQL como djondb puede ser diez veces más rápido si solo necesita una inserción simple. El desarrollador podrá trabajar de manera más eficiente porque NoSQL le permite consumir menos datos.
El objetivo principal de las BASES DE DATOS NoSQL (sin límites) es mantener un alto nivel de escalabilidad. Debe considerar qué tipos de consultas está realizando, qué columnas usa en la tabla y qué implementación de su servidor está usando. Si crea más nodos a 1000000 rpm estables en 2 ms y usa menos código, obtendrá un nodo más rápido con una velocidad y un rendimiento más estables.
¿Qué hace que Nosql sea más rápido que Sql?
Este método implica la recopilación, consolidación y división de varias entidades de datos. Como resultado, una base de datos NoSQL realiza operaciones de lectura y escritura más rápido que una base de datos SQL.
Por qué las bases de datos Nosql están tomando el control
Además de una variedad de factores, las bases de datos NoSQL son cada vez más populares. Son fáciles de usar, capaces de manejar grandes cantidades de datos y se pueden adaptar para cumplir con los requisitos específicos de su aplicación. Tienen muchas ventajas además de ser flexibles y personalizables, lo cual es imposible de encontrar en otros tipos de bases de datos.
Ajuste del rendimiento de Nosql

El ajuste del rendimiento de Nosql se trata de asegurarse de que su base de datos Nosql se ejecute de la manera más eficiente posible. Hay algunas áreas clave en las que centrarse al ajustar su base de datos nosql: 1. Asegúrese de que su base de datos esté correctamente indexada. 2. Asegúrate de que tus consultas estén optimizadas. 3. Asegúrese de que sus datos estén correctamente normalizados. 4. Asegúrese de que su base de datos esté configurada correctamente. Al centrarse en estas áreas clave, puede asegurarse de que su base de datos nosql funcione al máximo rendimiento.
Cuando Mango tiene una carga alta, el script MangoNoSql realiza escrituras en segundo plano. La función Batch Write Behind le permite escribir detrás de escena. Cada tarea se ejecutará en paralelo con las demás, lo que enfocará los valores de puntos de un grupo. Si ha notado eventos de pérdida de datos NoSQL en su sistema, es una buena idea cambiar la configuración de rendimiento. Cuando presione el botón Respaldar ahora, se creará una cola de trabajos para respaldar el sistema ahora. Todos los valores de puntos que están listos para escribirse en una lista de memoria como parte de los módulos NoSQL se almacenan en mango. Después de eso, selecciona hasta 'Escritura por lotes detrás de inserciones por tarea' de la lista e inicia un hilo para insertar las inserciones.
Los pros y los contras de Nosql
Al desarrollar bases de datos NoSQL, es fundamental mantenerlas flexibles y rápidas. Tiene menos gastos generales porque tiene menos restricciones que SQL. El almacenamiento superficial NoSQL es flexible, lo que permite distribuirlo entre una variedad de objetos (documentos o pares clave-valor). Se considera que una base de datos NoSQL tiene un bajo nivel de dificultad en términos de desarrollo, funcionalidad y rendimiento. Es fácil de aprender y lo utilizan personas que prefieren almacenar datos que no se ajustan a los modelos de bases de datos tradicionales .
Optimización del rendimiento de Mongodb
MongoDB es un poderoso sistema de base de datos orientado a documentos de código abierto. Tiene una función de búsqueda basada en índices que hace que la recuperación de datos sea rápida y fácil. Sin embargo, como cualquier otro sistema de base de datos, el rendimiento de MongoDB se puede optimizar para garantizar que funcione sin problemas y de manera eficiente. Hay algunas cosas básicas que se pueden hacer para optimizar el rendimiento de MongoDB. Primero, es importante asegurarse de que los índices correctos estén en su lugar. Esto asegurará que los datos se puedan recuperar rápida y fácilmente. En segundo lugar, es importante mantener la base de datos bien organizada. Esto ayudará a mantener bajo el tamaño de los datos y facilitará la consulta. Finalmente, es importante monitorear la base de datos regularmente para asegurarse de que funcione sin problemas. Siguiendo estos sencillos consejos, es posible mantener MongoDB funcionando sin problemas y de manera eficiente.

Guy Harrison explica cómo usar la nueva canalización de agregación y agregación de ventanas en MongoDB 5.0 en esta publicación de blog. Data Lake se creó como resultado de la explosión de interés en Big Data y Hadoop. Se desarrolló el Data Lake, una alternativa moderna y más eficiente al Enterprise Data Warehouse (EDW). El blog de esta semana se centra en los índices de árbol B de MongoDB y en cómo crear índices concatenados para optimizar las búsquedas de claves múltiples. Además, al considerar, o usar, índices, consideramos algunas compensaciones.
¿Cuál es la mejora en el rendimiento en Mongodb?
Si conoce los patrones de consulta de MongoDB, puede mejorar el rendimiento de MongoDB al: almacenar los resultados de subconsultas frecuentes para reducir la carga de lectura; y detectar sus patrones de consulta MongoDB. Asegúrese de tener índices en cada campo que consulte regularmente. Si observa consultas lentas, puede usar sus registros para identificarlas.
¿Mongodb necesita mucha RAM?
MongoDB requiere 1 GB de RAM para ejecutarse en un solo activo. Si el sistema tiene que comenzar a intercambiar memoria en el disco, tendrá un impacto severo en el rendimiento y debe evitarse.
¿Mongodb tiene optimizador de consultas?
Cuando un índice está disponible en MongoDB, el optimizador de consultas determina qué plan de consulta es el más eficiente y lo almacena en caché. El número de "unidades de trabajo" (trabajos) realizados por el plan de ejecución de consultas se usa para determinar el plan de consultas más eficiente cuando el planificador de consultas examina los planes candidatos.
Herramienta de optimización de consultas de Mongodb
Mongodb proporciona una herramienta de optimización de consultas que permite a los usuarios mejorar el rendimiento de sus consultas. Esta herramienta proporciona una forma de visualizar el plan de ejecución de consultas y optimizar la consulta en función de los resultados. La herramienta también permite a los usuarios ver el plan de ejecución de consultas en una variedad de formatos, incluidos JSON, BSON y CSV.
MongoDB proporciona estadísticas de ejecución de consultas como parte de un sistema de inspección. Esta información puede ser utilizada por un desarrollador para optimizar una consulta. La pestaña Explicar plan, por ejemplo, permite a los usuarios ilustrar gráficamente las estadísticas del plan. Además de queryPlanner, executionStats y allExecutionPlans, los modos de verbosidad se pueden usar para explicar. MongoDB admite índices únicos, parciales, dispersos (no indexe documentos sin el campo de índice), ocultos (no vea los resultados del planificador de consultas) y de varias claves. En lugar de usar claves de prefijos de índice o órdenes de clasificación variables, se usa un índice compuesto para indexar. MongoDB optimiza el rendimiento de las consultas mediante el uso de dos índices o prefijos separados al conectar dos índices o sus prefijos.
La canalización de Mongod contiene una etapa que coincide con un campo que no está indexado. Es una solución simple reescribir la etapa de coincidencia para usar un campo ya existente e indexado. El optimizador busca unidades de trabajo que se deben realizar al realizar cada plan candidato. Cuando se ejecutan aplicaciones de lectura intensiva, se debe aumentar el tamaño de los conjuntos de réplicas y realizar la fragmentación. Se debe monitorear el estado y la duración de la replicación. Verdadero: actualice todos los documentos coincidentes de la manera más eficiente posible cuando use multi. Examine las métricas de bloqueo en un orden específico.
Un tiempo de bloqueo prolongado puede indicar que la estructura de consulta o la arquitectura del sistema no funcionan correctamente. El procesamiento por lotes mejora la eficiencia de los recursos. Los eventos en Kafka, por ejemplo, se pueden consumir en lotes en lugar de en fragmentos. Es imposible indexar una consulta en una colección fragmentada si el índice no contiene la clave de la colección. Al usar $planCacheStats, puede obtener una mejor comprensión de la información de caché en la etapa de agregación. También significa que el caché del plan solo tendrá un límite de tamaño de 0,5 GB, que es el mismo límite de tamaño que la versión anterior.
Almacenes de datos Nosql
En lugar de almacenar datos en tablas, las bases de datos NoSQL almacenan datos en documentos. Como resultado, los etiquetamos como "no solo SQL" y, por lo tanto, pueden clasificarse como modelos de datos flexibles mediante el uso de una variedad de métodos diferentes. Las bases de datos NoSQL se dividen en cuatro tipos: bases de datos de documentos puros, almacenes de valores clave, bases de datos de columnas anchas y bases de datos de gráficos.
El almacén de datos de Redis es un almacén de pares clave-valor en memoria de código abierto desarrollado por IBM. Se puede usar para almacenar datos de sesión para un acceso más rápido, además de almacenar en caché, poner en cola y poner en cola, y es menos costosa que las bases de datos tradicionales . Una base de datos NoSQL se usa con frecuencia como un aumento en lugar de un reemplazo de una base de datos relacional. Un tipo de persistencia subyacente tiene un conjunto diferente de características que uno que está almacenado en una base de datos relacional. PyMongo, que se crea con código Python, le permite interactuar con una o más instancias de MongoDB mediante una interfaz común. El ORM de Python construido alrededor de PyMongoEngine está diseñado específicamente para MongoDB. El objetivo de Graph Databases es proporcionar una descripción general completa de los almacenes de datos NoSQL y compararlos con otros tipos de almacenes de datos. La siguiente es una breve descripción de NoSQL y sus usos, así como una descripción del teorema de coherencia, disponibilidad y tolerancia a la partición (CAP). los datos de la sesión se pueden almacenar en la memoria más rápido que en una base de datos tradicional con almacenamiento persistente.
Las bases de datos NoSQL se benefician de las siguientes características: fácil escalado, alta disponibilidad y baja latencia de acceso a los datos. Las aplicaciones de bases de datos están diseñadas para procesar más tipos de datos que las bases de datos tradicionales. Simplifica el almacenamiento de datos con un modelo simplificado, lo que permite un procesamiento más rápido y eficiente. Además, son apropiados para el análisis de datos a gran escala. Las bases de datos NoSQL tienen una serie de ventajas sobre las bases de datos convencionales . Las ventajas de tenerlos son que pueden escalar, proporcionar altos niveles de disponibilidad y bajos niveles de latencia para el acceso a los datos.
Por qué las bases de datos Nosql están tomando el control
Existen numerosas ventajas en el uso de bases de datos NoSQL sobre las bases de datos relacionales tradicionales, y se están volviendo cada vez más populares. El diseño de ObjectStore, que permite un uso más eficiente de las técnicas de programación orientada a objetos, es una de las razones principales de esto. Las bases de datos NoSQL, además de su escalabilidad, también ofrecen una variedad de otras ventajas. Los datos se pueden manejar con facilidad porque son grandes y se pueden manejar en un corto período de tiempo. Para cualquier empresa que busque una base de datos de documentos confiable y escalable , MongoDB es una excelente opción. Además, es de uso gratuito y es una opción popular para empresas de todos los tamaños.
Índice de texto Mongodb
Los índices de texto de MongoDB admiten el procesamiento de texto específico del idioma, incluida la tokenización, la lematización y las palabras vacías específicas del idioma. Se pueden usar con cualquier campo que contenga texto basado en el idioma.
Crear índices de texto en MongoDB es tan simple como usar el método createIndex(). La función principal de un índice de texto es identificar cualquier elemento en una cadena o matriz de elementos en un texto. Los índices compuestos contienen claves de índice ascendente y descendente además de la clave de índice de texto. En este caso, busquemos dentro de la colección de publicaciones de estudiantes creando un índice de texto en el campo de título. MongoDB suma los resultados de cada campo de índice en el documento multiplicando su peso por el número total de coincidencias. El peso predeterminado de un campo de índice es uno, por lo que puede cambiarlo mediante el método createIndex(). Puede crear varios índices de texto utilizando el especificador comodín ($**).