
Diseño de una base de datos para datos de geolocalización: consideraciones clave
Publicado: 2022-12-29Los datos de geolocalización son un tipo de datos que incluyen información sobre la ubicación geográfica de un objeto específico. Para almacenar y administrar de manera efectiva los datos de geolocalización, es importante comprender cómo estructurar una base de datos para este tipo de datos. Hay algunas consideraciones clave a tener en cuenta al diseñar una base de datos para datos de geolocalización. La primera consideración es el nivel de granularidad en el que se almacenarán los datos. Por ejemplo, ¿los datos se almacenarán a nivel de país, de estado o de ciudad? El nivel de granularidad afectará el tamaño general de la base de datos y la complejidad de las consultas que se pueden ejecutar en los datos. La segunda consideración es el formato en el que se almacenarán los datos. Hay algunas opciones diferentes para almacenar datos de geolocalización, incluidos pares de latitud/longitud, GeoJSON y KML. Cada opción tiene sus propias ventajas y desventajas, por lo que es importante elegir el formato que mejor se adapte a las necesidades específicas de la aplicación. Finalmente, es importante considerar la estrategia de indexación que se utilizará para los datos. La indexación es importante por razones de rendimiento, pero también puede afectar la estructura general de la base de datos. Para los datos de geolocalización, una estrategia de indexación común es usar un índice quadtree. Teniendo en cuenta estas consideraciones, es posible diseñar de forma eficaz una base de datos para almacenar datos de geolocalización.
Varias empresas de tecnología dominantes están experimentando con bases de datos NoSQL en las áreas de servicios basados en la ubicación. Un lenguaje de consulta estructurado, como SQL, y una base de datos relacional, como MySQL, funcionan de manera opuesta. No hay características comunes en las bases de datos NoSQL y muchas de ellas no requieren esquemas de tabla fijos ni operaciones de combinación. MongoDB (código abierto), BigTable (propiedad de Google) y Google Earth (disponible a través de Google Earth) son solo algunas de las bases de datos NoSQL que pueden manejar datos espaciales. Cassandra (una base de datos NoSQL desarrollada por Facebook) y CouchDB (una base de datos NoSQL desarrollada por Facebook) también son plataformas de software de código abierto. Se puede utilizar Amazon SimpleDB, un servicio web. El marco NoSQL no es simplemente un contenedor de almacenes de datos; es una colección de ellos.
Una gran cantidad de desarrolladores utilizan tecnologías NoSQL para abordar problemas espaciales, en lugar de depender de una base de datos. En su lugar, utilizarán un servicio local o alojado. Espere más opciones para las bases de datos, no menos. Este es un agradecimiento a Paul Ramsey y sus estudiantes en Geog897g de Penn State por su aporte.
¿Cómo se estructuran las bases de datos Nosql?
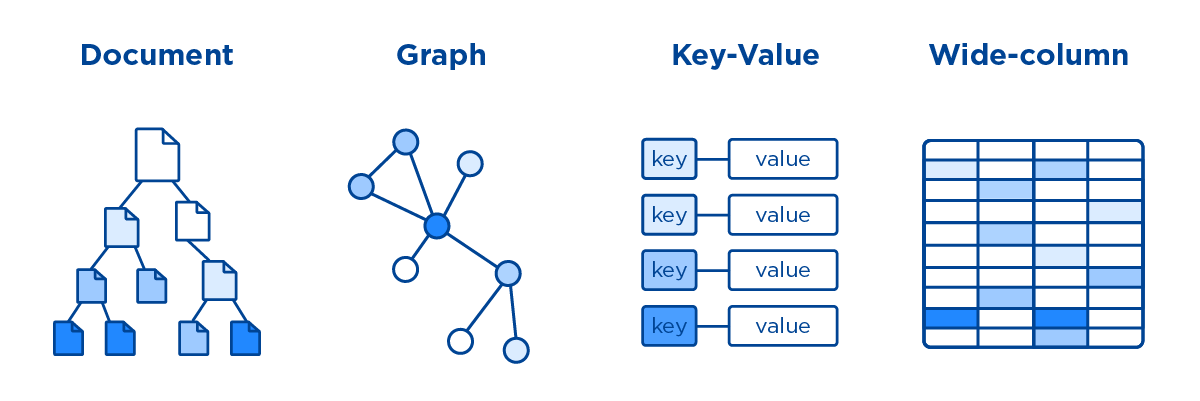
Las bases de datos SQL (también conocidas como bases de datos NoSQL) almacenan datos de manera diferente a las bases de datos tradicionales debido a su naturaleza no tabular. Una base de datos NoSQL se compone de varios tipos según su modelo de datos. Los tipos de documentos incluyen tablas, gráficos y columnas anchas, así como tipos de clave-valor.
A diferencia de las bases de datos relacionales tradicionales , las bases de datos NoSQL almacenan datos en un formato que es único para ellas. Los tipos de documento, clave-valor, columna ancha y gráfico son los más comunes. El costo de almacenar datos se ha reducido drásticamente durante la última década, lo que ha permitido que surjan las bases de datos NoSQL. Los desarrolladores pueden almacenar grandes cantidades de datos no estructurados porque pueden usar estos sistemas para una variedad de propósitos. Las bases de datos de documentos, las bases de datos de valores clave, los almacenes de columnas anchas y las bases de datos de gráficos son ejemplos de bases de datos NoSQL. Cuando no se requiere unirse, los tiempos de consulta mejoran. La variedad de casos de uso de las soluciones de IoT va desde los críticos (como los datos financieros) hasta los más divertidos y absurdos (como el almacenamiento de lecturas de IoT de una caja de arena inteligente para gatos).
En este tutorial, aprenderá a elegir y usar una base de datos NoSQL. Además, analizaremos en profundidad algunos conceptos erróneos comunes sobre las bases de datos NoSQL. Según DB-Engines, MongoDB es la base de datos no relacional más popular del planeta. El objetivo de este tutorial es enseñarle cómo consultar una base de datos MongoDB sin instalar nada en su computadora. Un clúster de MongoDB es una ubicación donde almacena sus bases de datos. La capacidad de almacenamiento de Atlas se puede aumentar una vez que se haya configurado para un clúster. Atlas Data Explorer, MongoDB Shell o MongoDB Compass son métodos posibles para crear una base de datos manualmente.
Como resultado, los datos de muestra de Atlas se importarán a este script. Las bases de datos NoSQL tienen una variedad de ventajas para los desarrolladores, incluida la capacidad de modelar y escalar datos en paralelo, consultar datos rápidamente y utilizar consultas ultrarrápidas. El Explorador de datos es la forma más conveniente de insertar nuevos documentos, editar documentos existentes y eliminar documentos. Puede analizar sus datos utilizando el marco de agregación, que es una de las herramientas más poderosas disponibles. Chart es una de las formas más sencillas de visualizar datos en Atlas y Atlas Data Lake.
Debido a la flexibilidad de las bases de datos NoSQL, pueden manejar datos no estructurados y semiestructurados. Esto permite un desarrollo más rápido e iterativo porque no es necesario reconstruir los datos en la base de datos. Las bases de datos NoSQL también se pueden escalar para manejar grandes cantidades de datos, ya que están habilitadas para la escalabilidad. Finalmente, la estructura de datos de las bases de datos NoSQL les permite manejar datos de una manera completamente nueva, que es única para ellos. Las bases de datos NoSQL son ideales para conjuntos de datos a gran escala porque se pueden modificar para cumplir con requisitos únicos.
¿Qué tipo de base de datos Nosql se utiliza para realizar un seguimiento de las relaciones entre entidades?
No hay una respuesta definitiva a esta pregunta, ya que depende de las necesidades específicas de la aplicación. Sin embargo, algunas de las bases de datos nosql más populares utilizadas para rastrear relaciones entre entidades incluyen MongoDB, Couchbase y Cassandra.
Cualquier sistema que funcione con bases de datos SQL alternativas se denomina NoSQL. A diferencia de las tablas tradicionales de filas y columnas utilizadas en los sistemas de administración de bases de datos relacionales, los modelos de datos utilizados en esta aplicación se componen de diferentes estructuras. Las bases de datos NoSQL son bastante diferentes entre sí. Las bases de datos de documentos con una arquitectura escalable se usan comúnmente para implementar las bases de datos de documentos más ampliamente adoptadas. Las plataformas de comercio electrónico, las plataformas comerciales y el desarrollo de aplicaciones móviles son solo algunos ejemplos de casos de uso. Examinamos MongoDB y PostgreSQL en detalle, comparándolos entre sí. Estos datos se pueden recopilar en segundos mediante el uso de una base de datos en columnas.
No pueden escribir datos de manera consistente debido a su método de escribir datos. Las bases de datos de gráficos están optimizadas para capturar y buscar conexiones entre elementos de datos como parte de sus capacidades de búsqueda y captura. Se pueden unir varias tablas en SQL de manera más eficiente utilizando estos métodos.
¿Qué tipo de base de datos Nosql es la más adecuada para almacenar datos con relaciones complejas?
Una base de datos de documentos es una base de datos sin esquemas, lo que le permite definir un esquema sin tener que seguirlo de antemano. Podemos almacenar datos complejos en formatos de documentos como XML y JSON usando este sistema.
¿Qué tipo de base de datos Nosql utiliza bordes y relaciones en su estructura?
Se utiliza una estructura gráfica dirigida para representar datos en una base de datos NoSQL de Graph Base. Un gráfico se compone de nodos y aristas. Un gráfico es una representación de un conjunto de objetos a los que algunos pares de objetos están vinculados por algún tipo de vínculo.
Nosql geoespacial
Los datos geoespaciales son datos que incluyen un componente geográfico, como la latitud y la longitud. Las bases de datos Nosql son adecuadas para almacenar y consultar datos geoespaciales. Muchas bases de datos nosql tienen soporte incorporado para operaciones y tipos de datos geoespaciales .
Los datos espaciales (archivos, bases de datos, servicios web) son un tipo de datos que almacenan información geográfica y se pueden utilizar en aplicaciones que reconocen la ubicación. Los datos de una capa espacial se pueden usar para representar una capa gráfica en un mapa, pero también se pueden usar para analizar ubicaciones y características geográficas. Era un tipo especial de sistema de administración de bases de datos que solo admitía objetos espaciales y era utilizado principalmente por analistas espaciales. Nos referimos a los datos espaciales como puntos, líneas y áreas de información cartográfica porque está diseñado para almacenarlos y manejarlos. En general, los profesionales gráficos utilizaron el software de creación de mapas de escritorio de ESRI para crear mapas (estáticos). Además de importar los datos, los desarrolladores web podrían consultarlos con una capa de aplicación de mapeo web con reconocimiento de ubicación utilizando una base de datos espacial. Al acceder a datos espaciales, lo más común es que los desarrolladores creen un mapa, ya sea en línea, en una aplicación móvil o en una computadora de escritorio.
Cuando comience a usar datos espaciales como un objeto más con coordenadas, notará lo bien que funciona con las bases de datos NoSQL. El uso de la computación basada en clústeres permite que los datos espaciales crezcan con el tiempo, con recursos de consulta fácilmente disponibles. Estas aplicaciones simplifican la ocultación de consultas espaciales más complejas que se utilizan comúnmente entre bastidores. Es común que las bases de datos espaciales simplemente calculen un rectángulo alrededor de cada una de las características en un conjunto de datos y lo usen como un índice aproximado para consultarlo. Usan el MBR para determinar qué tan cerca están las características, de modo que puedan ignorar las características que están demasiado separadas para ser importantes. Se pueden realizar solicitudes de documentos utilizando software NoSQL basado en N1QL/SQL, como Couchbase. Con la ayuda de los objetos geoespaciales, las aplicaciones posteriores se pueden conectar directamente a ellos.
El objetivo de este blog es demostrar cómo el lenguaje de programación R, así como el paquete de mapeo Leaflet, pueden solicitar datos y obtener resultados fácilmente. La verdadera batalla se libra en el exterior con consultas. Las aplicaciones GIS completas y las bases de datos espaciales también son capaces de generar grandes cantidades de datos. La especificación incluye muchos tipos y funciones diferentes para las características espaciales. Otra forma popular de unión espacial es la conexión de puntos, en particular, la agrupación de puntos en polígonos. El aspecto más difícil es diseñar un sistema basado en geometría computacional, lo que implica crear nuevas características. La importancia de la gestión de recursos no se puede exagerar porque hacerlo es difícil.

¿Cuál es la relación entre Nosql y los datos espaciales?
Debido a que NoSQL está diseñado para manejar cargas de trabajo de gran volumen, confiar en él para aplicaciones GIS siempre agrega una capa adicional de lujo debido a su naturaleza de computación distribuida. Cuando se utilizan clústeres, los datos espaciales crecen con el tiempo y los recursos de consulta se pueden expandir fácilmente.
Los beneficios de usar un índice geoespacial
Debe crear un índice espacial en MongoDB para usar datos espaciales en MongoDB. Este índice le permite consultar una colección de formas y puntos espaciales de manera más eficiente al utilizarlo como un índice de consulta espacial. Un índice geoespacial, que usa una variedad de criterios como la latitud y la longitud, se puede usar para ubicar todos los lugares en un documento. ¿Cuáles son los beneficios de usar un índice de mapeo? Un índice de mapa puede acelerar el proceso de localización de objetos en documentos porque puede utilizar un índice geográfico para localizarlos. El siguiente ejemplo sería un lugar para encontrar todos los restaurantes de tu ciudad. Debido a que un índice geoespacial se basa en la latitud y la longitud, es sencillo encontrar documentos que correspondan a sus criterios. De manera similar, el uso de un índice geoespacial puede ayudarlo a ubicar objetos que no necesariamente se encuentran en la misma área. Es posible que desee buscar todos los documentos con latitud y longitud que se encuentran dentro de un área geográfica específica. Es sencillo encontrar todos los documentos que necesita que tengan latitud y longitud según sus criterios utilizando un índice geoespacial. ¿Cómo se crea un índice geoespacial? Para crear un índice geoespacial, primero debe crear una colección de datos que contenga los datos que desea indexar. Se requiere un índice espacial, seguido de la colección. Como paso final, debe generar una consulta que utilice el índice geoespacial para ubicar objetos. ¿Cuáles son las cosas clave a tener en cuenta cuando se trabaja con psy GIS? Se deben seguir los siguientes consejos cuando se trabaja con datos espaciales. A la hora de buscar objetos en un documento, siempre es preferible utilizar un índice geoespacial. Cuando esté haciendo GIS, asegúrese de que sus documentos estén en el formato correcto. Al consultar objetos, siempre se deben proporcionar las coordenadas de referencia. Nunca es una buena idea asumir que un documento contiene información geográfica. Antes de usar el índice, siempre es una buena idea revisar el formato de los datos.
Almacenamiento de datos geoespaciales
El almacenamiento de datos geoespaciales se refiere al proceso de almacenamiento de datos digitales asociados con una ubicación física. Este tipo de datos se puede utilizar para crear mapas y otras visualizaciones que ayuden a las personas a comprender el mundo que les rodea. Hay una variedad de formas de almacenar datos geoespaciales, incluido el uso de bases de datos, archivos y servicios web.
Los datos geoespaciales de código abierto, como Internet de las cosas (IoT), la información geográfica voluntaria (VGI) y los datos geoespaciales abiertos, están creciendo en popularidad. El proceso de importación de bases de datos PostgreSQL/PostGIS se simplifica con HOGS, una utilidad de línea de comandos. Fue desarrollado con el objetivo de demostrar el rendimiento de un diseño de almacenamiento tradicional y un almacén de documentos NoSQL. Aunque la promesa de velocidad de NoSQL puede parecer atractiva, también hay inconvenientes. Como resultado, para comprender si realmente podemos abandonar los principios de los sistemas de administración de bases de datos relacionales (RDBMS), primero debemos considerar esto. HOGS es una utilidad de línea de comandos de código abierto que utiliza la biblioteca GDAL/OGR de código abierto para automatizar la importación de datos geoespaciales heterogéneos a bases de datos a/postGIS. Los almacenes de documentos, las bases de datos de gráficos, las bases de datos orientadas a objetos y los almacenes de valores clave son ejemplos de almacenes de datos NoSQL.
Los almacenes de documentos almacenan datos como documentos en lugar de tablas en una base de datos relacional porque no tienen un esquema explícito. Debido a su facilidad de uso, se utilizan con frecuencia junto con conjuntos de datos de código abierto. El estándar GeoJSON, que utilizan tanto MongoDB como CouchDB, se usa para proporcionar capacidades espaciales. Amirian et al. estudie modelos orientados a documentos un 19 % más rápido que los modelos relacionales para datos espaciales de polígonos grandes. Amirian y sus colegas probaron tres estrategias de almacenamiento diferentes para " grandes datos geoespaciales " utilizando Microsoft SQL Server 2012, con aportes de los usuarios. El diseño del documento XML (almacén de documentos NoSQL) proporcionó el mejor rendimiento y escalabilidad durante su configuración.
Varios de los hallazgos de su investigación muestran que los modelos basados en documentos deben considerarse en una amplia gama de escenarios de flujo de trabajo. El uso de MongoDB para consultar puntos y combinar datos produce tres veces el rendimiento de PostGIS a seis veces la velocidad. A pesar de esto, PostgIS supera a MongoDB en más de 3 veces en consultas de radio cuando aumenta el radio de la consulta. A pesar de esto, los autores reconocen que las bases de datos NoSQL carecen de algunas capacidades similares a los RDBMS, pero afirman que esto cambiará en el futuro. Se eligió Python como lenguaje para implementar el sistema HOGS debido a su disponibilidad e integración multiplataforma con bibliotecas de código abierto como GDAL/OGR y GEOS, así como su integración multiplataforma. La base de datos se almacena de dos maneras diferentes: almacenamiento de características y conjunto de datos. Una tabla de funciones tiene filas para cada atributo, una columna de geometría y una columna de identificación de funciones; cada fila tiene una característica con un conjunto de datos.
Una columna contiene el id. Tanto la columna de Geometría como la de ID son columnas separadas que, además de la tabla, están organizadas en columnas. La distinción principal es que todos los atributos se almacenan en una sola columna de tipo jsonb. HOGS se puede usar para respaldar el control de versiones de conjuntos de datos mediante el uso de números de versión incrementales y marcas de tiempo asociadas. HOGS utiliza un diseño de almacenamiento basado en tablas tanto NoSQL como tradicional. Durante la fase de importación, los archivos de cada conjunto de datos se leen y analizan antes de escribirlos en una base de datos mediante una instrucción COPY. Debido a que cada archivo en una importación es su propio archivo, esta fase se puede ejecutar simultáneamente con otros archivos. La velocidad de importación, la velocidad de consulta y el tamaño de la base de datos se midieron para cada diseño de almacenamiento de datos.
La autoridad cartográfica noruega, conocida como N50, proporcionó un conjunto de datos abierto para cada punto de referencia. Un conjunto de datos a escala 1:50 000 del continente noruego contiene ocho subconjuntos de datos (colecciones de características) con varias capas topológicas. Después de extraer los datos en el conjunto de datos completo, hay 3415 archivos con un tamaño total de 7,9 GB. El método de importación basado en tablas es un 44 % más rápido que el método de importación jsonb. El diseño de la tabla tarda aproximadamente una hora y 19 minutos en importarse, mientras que el diseño de jstrelb tarda aproximadamente tres horas. Obtuvimos 840 geometrías de consulta de los registros de consulta de este sistema utilizando la velocidad de importación de diseño de tabla. Estos polígonos cubren el continente noruego en un rango de 1 a 100 metros.
Todas las métricas muestran que el diseño basado en tablas funciona mejor que el diseño NoSQL de estilo jsonb. Debido a la forma en que se almacenan los atributos y la cantidad de tablas utilizadas, esto podría ser un problema. Ambas bases de datos utilizan PostgreSQL/PostGIS, y ambas bases de datos utilizan tipos de geometría PostGIS. La principal diferencia entre las consultas de datos y los archivos jsonb es el tamaño de la tabla; la tabla común en los archivos jsonb es más grande que la tabla común en las consultas de datos. Muchos conjuntos de datos se pueden dividir en conjuntos de datos separados en función de los tipos de características que incluyen en ellos. En comparación con un diseño de tabla combinada de almacén de documentos NoSQL, descubrimos que un diseño tradicional de una tabla por conjunto de datos supera a un diseño de tabla combinada de almacén de documentos NoSQL para conjuntos de datos homogéneos. HOGS se puede automatizar y no presenta complejidad adicional al aprovechar GDAL/OGR en un sistema GDAL/OGR.
Parece más fácil trabajar con una sola tabla de varios conjuntos de datos con una combinación heterogénea de características, pero este tipo de diseño no funciona con otros paquetes GIS. El siguiente paso es establecer una configuración de referencia más completa, que incluye un conjunto más grande de conjuntos de datos. No se recomienda utilizar el tipo de datos jsonb en Postgres para almacenar conjuntos de datos homogéneos en el contexto de metadatos para datos geosincrónicos . Si los requisitos de espacio de almacenamiento para una única instancia de base de datos no superan los de otra instancia de base de datos, la declaración se mantiene en su lugar. Las tecnologías RDBMS tradicionales se pueden utilizar para almacenar y consultar de manera eficiente grandes cantidades de datos geoespaciales. El manual para MongoDB 2018. El tipo de datos JSONB en PostgresQL agiliza las operaciones, según Del Alba.
¿Crees que Nosql puede manejar datos de uso y cobertura del suelo? Nat Ecodin. Este libro fue publicado en 11:438 a 4426. Puede publicar este artículo siempre que siga la licencia Creative Commons (https://creativecommons.org/licenses/by/ 4.0/) en cualquier medio que desee. Según el autor, no hay intereses contrapuestos. A pesar de que los mapas publicados y las afiliaciones institucionales contienen reclamos jurisdiccionales, Springer Nature sigue siendo neutral.
Los muchos usos de Gis
Los sistemas de información geográfica (GIS) se pueden utilizar para una variedad de propósitos, incluido el mapeo de la escena del crimen, la investigación del cambio climático y la gestión de la tierra. Hay varios tipos de software GIS disponibles, cada uno de los cuales se adapta más a una tarea específica. ESRI, MapInfo y TopoGIS son ejemplos de paquetes de software GIS populares.