
Bigtable de Google: el almacén de datos orientado a columnas más utilizado
Publicado: 2022-12-19Bigtable es un almacén de datos orientado a columnas creado por Google. Está diseñado para manejar grandes cantidades de datos con un alto grado de flexibilidad. Bigtable ha sido utilizado por Google durante más de una década y es la base de muchos de sus servicios, incluidos Gmail, Google Maps y YouTube. Si bien Bigtable no es el primer almacén de datos orientado a columnas, sin duda es el más utilizado y conocido.
En este artículo, examinaremos el modelo de almacenamiento NoSQL tridimensional desarrollado por Bigtable. Para verificar que está estructurado correctamente, primero veremos cómo se implementa en términos teóricos y luego usaremos el cliente Node.js para hacerlo. El modelo de almacenamiento en Bigtable difiere de la forma en que podría encontrarlo en una base de datos similar. Se pueden ordenar varias celdas en una combinación de fila/columna por una marca de tiempo por celda. En lugar de guardar celdas en un orden arbitrario, cada celda tiene el valor y una marca de tiempo para garantizar que las celdas se guarden en un orden ordenado. Para este ejemplo, usaremos Node.js y JavaScript simple para construir Google Cloud Bigtable. En este artículo, veremos cómo crear una nueva instancia de Bigtable usando el código.
Comenzamos creando un ambiente limpio, leyendo y escribiendo en él, y luego derribándolo. Al ejecutar código con el cliente de Bigtable de Node.js, el cliente de Bigtable de Node.js puede generar un error de Permiso denegado y generar un vínculo para habilitar la API de administración de Cloud Bigtable. También debe establecer una cuenta de servicio separada en su proyecto de GCP para manejar la función de administrador de Bigtable. Para crear una tabla de Bigtable, primero debemos crear una instancia de la base de datos y un grupo de tablas. Simplemente defina un ID de tabla y una familia de columnas en el cliente de Node.js para hacer esto, y estará listo para comenzar. Se pueden crear filas simples usando Bigtable en una base de datos. La única forma de consultar datos es usar la clave de fila para consultar una fila específica o un grupo de filas.
Aunque los tiempos de ingesta no tienen relación con el orden en que se almacenan las versiones, sí tienen un efecto sobre cómo se almacenan. No es necesario proporcionar la clave de fila completa; simplemente un prefijo es suficiente. Cuando necesite consultar varias filas de Bigtable, siempre aconsejo usar la transmisión. Cuando se usa la transmisión, Bigtable no tiene que almacenar en búfer los datos en el servidor antes de enviar las filas, lo que da como resultado un rendimiento más rápido. Los filtros se pueden usar para limitar las versiones de las celdas, devolviendo solo aquellas columnas con nombres de familia específicos o columnas con criterios de calificación específicos. Esto es especialmente útil si tiene muchas versiones para conservar, pero solo se requiere la más reciente para fines específicos. Los filtros se utilizan principalmente para reducir la cantidad de datos que se consultan y envían para mejorar el rendimiento de las consultas.
En otras palabras, Cloud Bigtable es una base de datos NoSQL diseñada para cargas de trabajo de análisis y operaciones. Este sistema de base de datos es un híbrido multiplataforma que usa Hadoop en lugar de HBase, que emplea una base de datos en columnas. Se puede usar una tabla grande en la nube para impulsar aplicaciones con alto rendimiento y escalabilidad, con una capacidad de menos de 10 MB.
Apache Cassandra, ScyllaDB, Apache HBase, Google BigTable y Microsoft Azure CosmosDB son ejemplos de tiendas de columna ancha.
Las tablas no son lo mismo que las bases de datos relacionales en términos de almacenamiento de clave/valor. Las transacciones solo se pueden realizar una vez y no se admiten las uniones.
¿Google Bigtable es una base de datos Nosql?
Google Bigtable es una base de datos NoSQL diseñada para almacenar y administrar grandes cantidades de datos. Bigtable es una base de datos orientada a columnas, lo que significa que los datos se organizan en columnas en lugar de filas. Esto lo hace ideal para almacenar datos que cambian constantemente, como registros web o datos de redes sociales. Bigtable también es altamente escalable, lo que significa que puede manejar fácilmente grandes cantidades de datos.
Esta base de datos NoSQL puede almacenar una amplia gama de tipos de datos y es extremadamente estable. También maneja tanto la fragmentación como la replicación, lo que garantiza que la base de datos esté altamente disponible y sea confiable. Muchas aplicaciones de Google lo utilizan, incluidos Google Analytics, indexación web, MapReduce y Google Maps, Google Books, My Search History, Google Earth, Blogger.com, Google Code Hosting y Google para aplicaciones que requieren una base de datos capaz de manejar una gran cantidad de datos. número de elementos de datos, Datastore es una excelente opción.
¿En qué orden se almacenan los datos en Bigtable?
No hay un orden específico en el que se almacenan los datos en bigtable. Los datos se almacenan en un orden aleatorio, lo que dificulta el acceso a datos específicos.
Bigtable de Google: no solo para almacenar datos
Los datos no se pueden colocar en ningún orden específico dentro de la igtable. Debido a que Bigtable es una base de datos orientada a filas, todos los datos dentro de una fila se organizan en columnas, seguidas de una columna. Debido a que los datos se almacenan en orden cronológico inverso, es simple y rápido solicitar el valor más reciente, pero es difícil y lento solicitar el más antiguo.
Sus datos se guardan en Colossus, el sistema de archivos interno de larga duración de Google, que se encuentra dentro de los centros de datos de Google, como resultado del uso de Colossus por parte de Bigtable. Bigtable es de uso gratuito y no necesita usar un clúster HDFS ni ningún otro sistema de archivos.
Se puede realizar una consulta a una fuente de datos externa sin crear una tabla permanente con el comando combine: Un archivo de definición de tabla con una consulta. Hay una definición de esquema en línea, así como una consulta. Un archivo de definición de esquema JSON con una consulta.
Bigtable Vs. Almacén de datos
Existen algunas diferencias clave entre Bigtable y Datastore. Primero, Bigtable es un almacén de datos orientado a columnas, mientras que Datastore está orientado a filas. Esto significa que en Bigtable, los datos se organizan en columnas, mientras que en Datastore se organizan en filas. En segundo lugar, Bigtable no tiene un concepto de transacciones, mientras que Datastore sí. Esto significa que en Bigtable, no puede revertir los cambios a un estado anterior, mientras que en Datastore sí puede hacerlo. Finalmente, Bigtable está diseñado para alto rendimiento y baja latencia, mientras que Datastore está diseñado para alta disponibilidad y escalabilidad.
¿Qué almacén de datos en la nube se puede usar para crear bases de datos en la nube de Google? Debido a que Bigtable admite cargas de trabajo grandes con cargas de trabajo back-end complejas, está diseñado para organizaciones y empresas más grandes. A diferencia de SQL, que utiliza un lenguaje de consulta GQL más restrictivo, los almacenes de datos realizan transacciones ACID en subconjuntos de datos conocidos como grupos de entidades (aunque el lenguaje de consulta GQL es mucho más abierto). Google Cloud Datastore y Google Cloud Bigtable son dos servicios distintos que tienen una serie de características distintas. Además, la información de la imagen a continuación puede ayudarlo a seleccionar el proveedor de servicios adecuado para usted. Las respuestas anteriores, así como lo que se analiza en el libro de texto de Coursea Google Cloud Platform Big Data and Machine Learning Fundamentals, me servirán como guía para este artículo.
¿Cuál es la diferencia entre Bigtable y Datastore?
¿Cuál es la diferencia entre almacén de datos y base de datos? Bigtable y el almacén de datos están diseñados para procesamiento y análisis de datos de gran volumen, respectivamente, mientras que el almacén de datos está diseñado para datos transaccionales de alto valor. El almacén de datos también se conoce como base de datos NoSQL porque no se adhiere al estándar SQL tradicional, lo que le permite retener datos de una manera más flexible y escalable. ¿Qué tipo de almacén de datos es Google Bigtable? El modelo de almacenamiento de Bigtable almacena datos en tablas escalables masivamente que se ordenan por mapas clave y de valor. Una tabla se compone de filas, cada una de las cuales describe una sola entidad, y columnas, cada una con su propio valor. ¿Está obsoleto el almacén de datos? Debido a que se lanzó la API v1beta3 de Cloud Datastore, ya no está disponible. No obstante, el producto Cloud Datastore es totalmente funcional y compatible.
Base de datos de BigTable
Bigtable es un sistema de almacenamiento distribuido para administrar datos estructurados que está diseñado para escalar a un tamaño muy grande: petabytes de datos en miles de servidores básicos. Bigtable es una base de datos orientada a columnas, lo que significa que los datos se almacenan por columna en lugar de por fila.
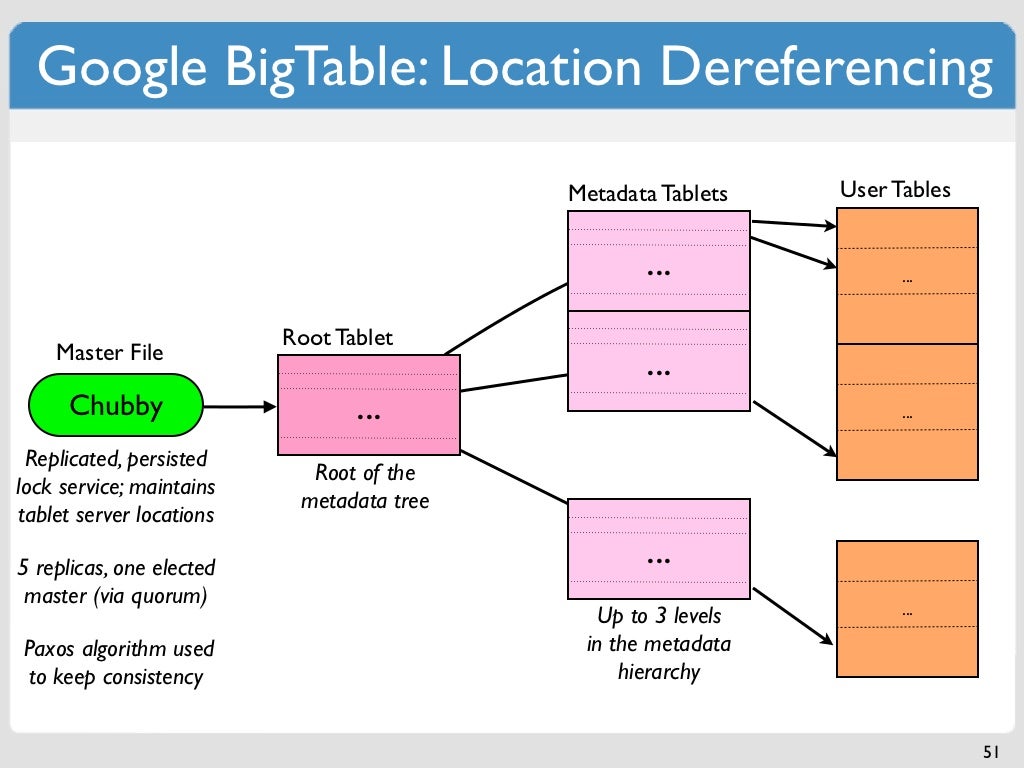
La tabla es una estructura escasa y densamente poblada con filas y columnas que pueden alcanzar miles de millones de filas. Una bigtable es una excelente opción para almacenar grandes cantidades de datos con baja latencia. Debido a que admite un alto rendimiento de lectura y escritura con baja latencia, es una fuente de datos adecuada para las operaciones de MapReduce. Cuando se usa una tabla de Bigtable, se divide en bloques de filas contiguas conocidas como tabletas para facilitar las consultas. En un sistema de archivos llamado Colossus, que utiliza Google, las tabletas se almacenan en formato SSTable. Un nodo de Bigtable es un subconjunto de cada tableta, que forma parte de la instancia de Bigtable. Agregar nodos a un clúster puede aumentar la cantidad de solicitudes simultáneas que puede manejar.

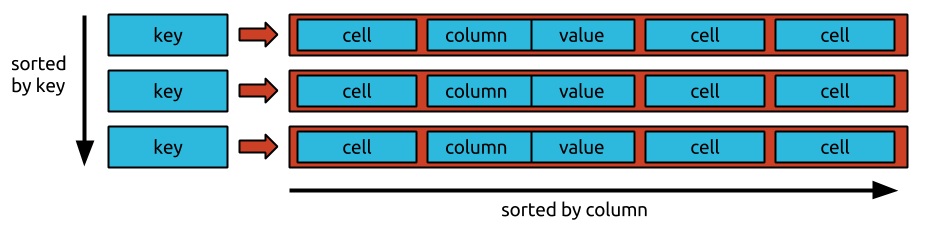
Una fila contiene un conjunto de entradas de clave o valor, que son una combinación de la familia de columnas, la marca de tiempo de la columna y la clave. Bigtable trata todos los datos de la misma manera: como cadenas de bytes sin procesar. Debido a que Bigtable almacena mutaciones secuenciales y las compacta periódicamente, la cantidad de mutaciones que se pueden almacenar en un momento dado requiere más espacio de almacenamiento. Bigtable comprime sus datos mediante un algoritmo sofisticado que está automatizado. Debido a que las deleciones son en realidad nuevos tipos de mutaciones, requieren más espacio de almacenamiento a corto plazo. Los métodos de almacenamiento patentados de Google le permiten lograr una durabilidad de los datos que supera la lograda por la replicación tridireccional HDFS estándar. Además de administrar el acceso a las tablas de Bigtable, puede administrar el acceso a otros servicios de Google Cloud asignando funciones a los usuarios en la sección Administración de acceso e identidad (IAM) de su proyecto de Google Cloud. De acuerdo con la política de encriptación predeterminada de Google Cloud, todos los datos en la nube se encriptan en reposo utilizando los mismos sistemas de administración de claves reforzados que usamos para nuestros datos encriptados. Con una copia de seguridad, puede guardar una copia del esquema y los datos de una tabla y luego restaurar esa copia de datos en una nueva tabla en el futuro.
Bigtable contra Cassandra
Cassandra y Bigtable usan diferentes métodos para determinar qué nodo de procesamiento debe realizar operaciones de lectura y escritura. En Cassandra, la clave de partición se denomina clave, mientras que en Bigtable, la clave de fila se denomina clave. El cliente debe revisar la política de equilibrio de carga para Cassandra como parte del proceso.
Una base de datos distribuida es aquella que es compartida por varias personas. Esta empresa incorpora almacenes clave-valor multidimensionales en su sistema, lo que le permite procesar decenas de miles de consultas por segundo (QPS). El objetivo de este documento es comparar y contrastar los dos sistemas de bases de datos. Las características clave de Bigtable incluyen: Se creó un sistema de almacenamiento distribuido para papel de datos estructurados. Si Bigtable determina que se requiere un reequilibrio de rango para un conjunto de datos, es sencillo para un nodo de procesamiento cambiar los rangos de datos porque la capa de almacenamiento está separada de la capa de procesamiento. Bigtable también se puede usar para admitir la replicación asíncrona en clústeres distribuidos geográficamente de hasta cuatro clústeres en topologías. La tolerancia a fallas de Cassandra está vinculada a su nivel de consistencia ajustable.
Al configurar una estrategia de topología de replicación de datos, puede definir la replicación geográfica. En general, se utiliza una configuración QUORUM (o LOCAL_QUORUM en algunos centros de datos). Para que se considere exitosa, la configuración del nivel de consistencia de una operación debe cumplirse con una mayoría de nodos de réplica que responda al nodo coordinador. Usando configuraciones de centro de datos y rack, las réplicas de Cassandra pueden soportar más estrés en comparación con las réplicas tradicionales. Al realizar operaciones de lectura y escritura, la topología determina qué nodos se necesitan para garantizar la coherencia. Una instancia de Bigtable puede contener un solo clúster o un grupo de hasta cuatro réplicas grandes. Bigtable y Cassandra son almacenes de datos NoSQL que son almacenes de columnas anchas.
La clave de fila de Bigtable se usa para clasificar los datos globales en una tabla por orden. Los nodos de Bigtable equilibran automáticamente la responsabilidad de los nodos para rangos clave, también conocidos como tabletas, como parte de la función Nodos de Bigtable. El servicio de Bigtable de un cliente no aplica los tipos de datos de columna que envía. En Bigtable, a cada columna de una tabla se le asigna un nombre de familia. A pesar de que las tablas suelen tener más familias de columnas (el número máximo de columnas por tabla es 100), cada tabla requiere al menos una familia de columnas. Una intersección de clave de fila se compone de dos celdas (una familia de columnas combinada con un calificador de columna). En Cassandra y Bigtable, existe un método para seleccionar el nodo de procesamiento para las operaciones de lectura y escritura.
En Cassandra, se identifica la clave de partición, mientras que en Bigtable, se usa la clave de fila. Una política de equilibrio de carga que tenga en cuenta los centros de datos, como una política de varios clústeres, ofrece la posibilidad de conmutación por error. Ambas bases de datos usan un método similar para terminar una escritura y han sido optimizadas para velocidad. Los datos se almacenan en las dos bases de datos a través de archivos SSTable que son inmutables. En Cassandra, el coordinador debe notificar al cliente que la escritura está completa antes de que respondan varias réplicas. Una escritura exitosa en Bigtable solo puede confirmarse mediante una respuesta de un nodo, ya que cada clave de fila se asigna solo a un nodo. Es posible que las celdas de cualquiera de las bases de datos no se incluyan en la SSTable fusionada.
Debido a la cláusula WHERE en una consulta CQL, es imposible devolver más de una fila en Cassandra. Solo se requiere consultar en Bigtable el nodo a cargo del rango de claves. En el nodo de procesamiento, es posible limitar la cantidad de datos que se pueden leer. Durante una fase de compactación, las SSTables se fusionan regularmente y los datos almacenados en Bigtable y Cassandra se almacenan en ellas. No hay reglas que rijan la cantidad de versiones de marcas de tiempo para cada celda, pero puede haber otros límites de tamaño de fila. El sistema de replicación de Colossus proporciona garantías de durabilidad de los datos. Bigtable, como Cassandra, tiene una interfaz de línea de comandos y bibliotecas de clientes para muchos lenguajes de programación comunes.
A cada nodo se le asigna un SSTable en Bigtable, y ese nodo sirve los datos almacenados en él. Cuando dimensiona un clúster de Cassandra, no necesita tener en cuenta las réplicas de almacenamiento como lo hace con Bigtable. Las unidades de estado sólido (SSD) o las unidades de disco duro (HDD) son los tipos de almacenamiento más utilizados para las instancias de Bigtable . Como lo demostró Cassandra, no hay pérdida de densidad de almacenamiento para lograr la tolerancia a fallas. Es posible escalar una instancia de Bigtable para cumplir con los requisitos de carga de trabajo con un esfuerzo mínimo y un tiempo de inactividad mínimo. Si bien solo hay cuatro clústeres, cada clúster se puede crear en cualquier región de nube compatible en todo el mundo. Google recomienda que pruebe el rendimiento de Bigtable con consultas y datos representativos para generar una métrica QPS por nodo.
Cassandra realiza una gran cantidad de funciones de administración mediante los componentes administrados de Bigtable. Las copias de seguridad de tablas grandes crean copias restaurables de la tabla, que se almacenan como objetos en el clúster. Las copias de seguridad consumen menos recursos de nodo y son menos costosas que el almacenamiento en la nube. Otro método para hacer una copia de seguridad de Bigtable es usar una exportación de datos administrada a Cloud Storage. Las tareas de mantenimiento interno, como la aplicación de parches del sistema operativo, la recuperación de nodos, la reparación de nodos, la supervisión de la compactación del almacenamiento y la rotación de certificados SSL, se manejan sin inconvenientes con el servicio de Bigtable. Los paneles están disponibles para monitorear el rendimiento y las métricas de uso en instancias, clústeres y niveles de tabla en la página de la consola de Google Cloud de Bigtable . Puede utilizar el panel de supervisión para realizar ajustes de rendimiento avanzados.
El artículo de Bigtable describe un sistema de almacenamiento de datos que admite un escalado horizontal masivo. Cada tabla en los datos se divide en varias particiones. Puede consultar la tabla utilizando una clave de fila o un rango de claves de fila. El artículo de Bigtable también describe un método para distribuir el trabajo de la tabla en un grupo de nodos. Apache Cassandra, una base de datos de código abierto, se basa en algunos de los conceptos del artículo de Bigtable. Los centros de datos utilizan una arquitectura de nodos distribuidos, en la que el almacenamiento se comparte entre los servidores que sirven los datos. El acceso al sistema de almacenamiento de datos de Bigtable se proporciona mediante la interfaz de línea de comandos de cbt y las bibliotecas del cliente. Bigtable incluye varios lenguajes de programación además de Python, lo que simplifica la integración con las aplicaciones.
Datastax Astra Cassandra de Google como servicio: fácil de implementar y escalar
DataStax Astra Cassandra como servicio de Google es una excelente opción para aprender sobre Cassandra. La interfaz de usuario del operador de Kubernetes simplifica la configuración, la administración y el escalado de su implementación de Cassandra.
Documentación de BigTable
La documentación de Bigtable es un gran recurso para aprender sobre esta poderosa herramienta. Brinda una descripción general de las características y capacidades de Bigtable, así como información detallada sobre cómo usarla. La documentación está bien organizada y es fácil de seguir, lo que la convierte en un recurso valioso para cualquier persona interesada en conocer esta poderosa herramienta.
Google Cloud Platform se encarga de alojar la base de datos Bigtable de Google. Es fácil de usar OpenTSDB 2.1 y posterior cuando se usa junto con el backend de Google. Todo lo que tiene que hacer es crear una instancia de Bigtable, configurar sus tablas TSDB usando el shell Bigtable HBase e iniciar los TSD. Los clientes de Bigtable se encuentran actualmente en versión beta y experimentan una variedad de cambios.
El diseño de datos eficiente de Bigtable
Bigtable también es adecuado para las operaciones de MapReduce. Debido a su diseño de datos eficiente, MapReduce puede manejar grandes volúmenes de datos en un corto período de tiempo.