
Hadoop HDFS y NoSQL: una poderosa combinación para Big Data
Publicado: 2023-01-05Hadoop es un marco de código abierto que permite el procesamiento distribuido de grandes conjuntos de datos en grupos de computadoras utilizando un modelo de programación simple. HDFS es el sistema de archivos distribuidos de Hadoop que proporciona una forma escalable y tolerante a fallas para almacenar datos. Las bases de datos NoSQL son una nueva clase de bases de datos que están diseñadas para proporcionar una alternativa escalable, flexible y de alto rendimiento a las bases de datos relacionales tradicionales.
La distinción principal entre Hadoop y HDFS es que Hadoop es un marco de código abierto para almacenar, procesar y analizar datos, mientras que HDFS es un sistema de archivos que permite a los usuarios acceder a los datos de Hadoop. Como resultado, HDFS es un módulo de Hadoop .
SQL y Hadoop pueden administrar datos de varias maneras. Se utiliza un marco Hadoop para ensamblar componentes de software, mientras que un marco SQL se usa para ensamblar bases de datos. Para big data, es fundamental considerar los pros y los contras de cada herramienta. La plataforma Hadoop solo almacena datos una vez, mientras que Hadoop almacena una cantidad mucho mayor de conjuntos de datos.
Hadoop no es una base de datos, sino una pieza de software que permite la computación paralela masiva. Esta tecnología permite que las bases de datos NoSQL (como HBase) distribuyan datos entre miles de servidores con poca degradación del rendimiento.
Hadoop no almacena datos de la misma manera que lo hace el almacenamiento relacional. Un servidor distribuido es una de las aplicaciones que más lo utiliza. Aunque es una base de datos Hadoop , no califica como una base de datos relacional porque almacena archivos en HDFS (sistema de archivos distribuido).
¿Cuál es la diferencia entre Nosql y Hdfs?
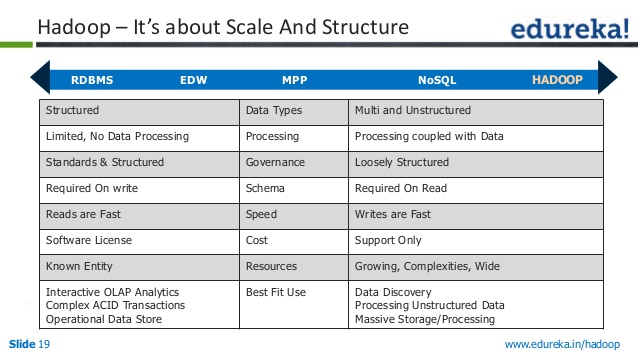
Es un sistema de archivos, y también se le conoce como sistema de archivos. Ya está claro que esta aplicación ofrece una serie de funciones. ¿De dónde sacas estas cosas de NOSQL? Podremos procesar grandes cantidades de datos en tiempo real usándolo porque no requiere que usemos bases de datos relacionales u otras características.
El administrador de almacenamiento HBase, que se ejecuta en Hadoop, proporciona lecturas y escrituras aleatorias de baja latencia. El sistema HBase emplea una función de fragmentación automática en la que las tablas grandes se distribuyen dinámicamente. Cada servidor de región es responsable de brindar servicio a un conjunto de regiones, y solo hay un servidor de región capaz de brindar servicio a una región (es decir, HMaster y HRegion son dos de los principales servicios proporcionados por HBase. El componente HRegion de la tabla HBase es responsable de manejar subconjuntos de los datos de la tabla. Cuando se inicia un servidor de región, se asigna a cada región. Como resultado, el maestro no participa en las operaciones de lectura y escritura.
Cuando se trata de manejar datos voluminosos y no estructurados, las bases de datos NoSQL como MongoDB y Cassandra se destacan sobre las bases de datos relacionales tradicionales. Las empresas con grandes cargas de trabajo de datos, como Big Data, prefieren usar estas herramientas para procesar y analizar rápidamente cantidades masivas de datos variados y no estructurados. MongoDB almacena datos en colecciones, mientras que Hadoop almacena datos en un sistema de archivos diferente conocido como HDFS. Es ventajoso tener una arquitectura diferente como resultado de esta diferencia. También es mucho más rápido consultar datos en MongoDB que buscar en archivos individuales. Además, debido a que mongodb está diseñado para entornos de alto volumen, es adecuado para manejar grandes volúmenes de datos a un costo relativamente bajo. Se recomienda que las empresas que requieren soluciones de Big Data utilicen bases de datos NoSQL. Tienen numerosas ventajas sobre las bases de datos tradicionales en términos de velocidad de procesamiento y análisis, y son muy adecuadas para el análisis y la gestión de datos a gran escala.
¿Es Hadoop una base de datos Nosql?
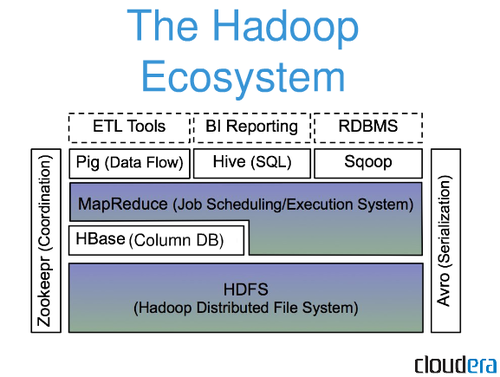
Hadoop no es un sistema de gestión de base de datos relacional tradicional. Es un sistema de archivos distribuido que ayuda a almacenar y procesar grandes conjuntos de datos en un grupo de servidores básicos. Hadoop está diseñado para escalar desde servidores individuales a miles de máquinas, cada una de las cuales ofrece computación y almacenamiento local.
El uso de datos a escala supermasivo está siendo revolucionado por las nuevas tecnologías. La infraestructura de big data tiene numerosos jugadores, incluidos Hadoop, NoSQL y Spark. Los DBA y los ingenieros/desarrolladores de infraestructura ahora trabajan para ellos para administrar sistemas complejos en una nueva generación de DBA e ingenieros de infraestructura. Debido a que Hadoop es un ecosistema de software en lugar de una base de datos, permite el cálculo de cantidades masivas de datos a un ritmo eficiente y efectivo. Los beneficios que proporciona para las cantidades masivas de datos que maneja han cambiado las reglas del juego para el procesamiento de big data. Una transacción de datos de gran tamaño, como una que tarda 20 horas en completarse en un sistema de base de datos relacional centralizado, se puede completar en solo tres minutos en un clúster de Hadoop.
Hay más de un lenguaje SQL para elegir. MongoDB, una base de datos de documentos puros, es un tipo de base de datos NoSQL; Cassandra, una base de datos de columna ancha, es otra; y Neo4j, una base de datos de gráficos, es otra. Esta característica fue creada por SQL- on-Hadoop . SQL-on-Hadoop es una nueva clase de herramientas analíticas que combina consultas SQL establecidas con marcos de datos de Hadoop. SQL-on-Hadoop permite que los desarrolladores empresariales y los analistas de negocios colaboren con Hadoop en clústeres de computación básicos al permitir que se ejecuten las consultas familiares de SQL. Las ventajas de SQL-on-hadoop. Las numerosas ventajas de SQL-on-Hadoop, además de su facilidad de uso, bien valen el tiempo y los recursos de los desarrolladores y analistas de datos empresariales. Para empezar, pueden trabajar con Hadoop en clústeres de computación básicos, lo que les permitirá comenzar rápida y fácilmente con el análisis de big data. SQL-on-Hadoop también les permite aprovechar las consultas SQL familiares, lo que les facilita el aprendizaje del análisis de big data. Además, SQL-on-Hadoop proporciona la funcionalidad de mapeo/reducción de Hadoop, así como las ricas capacidades de análisis de datos que proporciona.
Bases de datos Nosql en aumento
Como resultado, las bases de datos NoSQL son cada vez más populares debido a su escalabilidad, rendimiento de lectura/escritura y flexibilidad de datos. Hay varios buenos ejemplos de bases de datos NoSQL en el mercado, incluidos DynamoDB, Riak y Redis.
Hive es una base de datos NoSQL ligera y modular con excelentes métricas de rendimiento. Está escrito en el lenguaje de programación Dart puro y es popular entre los desarrolladores debido a su simplicidad.
¿Cuál es la diferencia entre Hadoop y la base de datos?

Si bien el RDBMS no almacena ni procesa datos, Hadoop almacena y procesa datos como un sistema de archivos distribuido. Un RDBMS, por otro lado, es una base de datos estructurada que almacena datos en filas y columnas y puede actualizarse con SQL y presentarse en una variedad de tablas.
La adopción de tecnologías y herramientas de big data ha crecido a un ritmo acelerado. Una distribución Hadoop de código abierto se ejecuta en un sistema de archivos distribuido y permite el intercambio y procesamiento de grandes conjuntos de datos. Un RDB es un sistema básico de administración de bases de datos que se utiliza en la forma más simple por todos los sistemas de administración de bases de datos como Microsoft SQL Server, Oracle y MySQL. A pesar de estar clasificado como una evolución, un RDBMS se parece más a cualquier otra base de datos estándar que a una empresa importante. No es una base de datos, sino un sistema de archivos distribuido que puede albergar y procesar grandes colecciones de archivos de datos. Aunque los sistemas como Hadoop pueden proporcionar un mejor rendimiento, existen algunos inconvenientes que rara vez se comentan. Debe pensar en cómo administrar su clúster de Hadoop, la seguridad, Presto o cualquier otra interfaz que use.
La mayoría de los sistemas de bases de datos relacionales, como SQL Server y Oracle, son mucho más fáciles de usar. La mayoría de las organizaciones enfrentan un problema importante al no tener suficientes personas capacitadas que puedan operar Hadoop de manera efectiva, así como un costo significativo de talento. Si tiene 10.000 empleados, necesitará una gran cantidad de datos para realizar un seguimiento de todos ellos. Esta información se puede almacenar de varias formas con Presto. Se puede usar una partición de fecha para almacenar la posición de una persona todos los días. El RDBMS, por otro lado, se puede utilizar como ejemplo de un modelo de datos. La única forma de utilizar este método es si ya tiene acceso a los datos del día anterior.
¿Cuál es la diferencia clave entre las bases de datos relacionales y Big Data?
La distinción principal entre las bases de datos relacionales y los grandes datos es que las bases de datos relacionales están optimizadas para almacenar datos estructurados, mientras que los grandes datos están optimizados para almacenar datos no estructurados y semiestructurados. Una base de datos relacional se modela según el modelo relacional, mientras que una base de datos de big data se modela según el modelo distribuido. Los datos estructurados se pueden almacenar y procesar en bases de datos relacionales de manera eficiente. La tabla contiene datos y permite el acceso y la recuperación del lenguaje de consulta estructurado (SQL). Big data se define como cualquier dato no estructurado o semiestructurado.

¿Cuál es la diferencia entre Hadoop y Mongodb?
Debido a que MongoDB se ejecuta en C, es mejor en la gestión de la memoria que cualquier otra base de datos. Hadoop es un conjunto de software basado en Java que proporciona un marco para almacenar, recuperar y procesar datos. Hadoop optimiza el espacio de manera más efectiva que MongoDB.
MongoDB era una base de datos NoSQL (no solo SQL) creada en C. Hadoop es una plataforma de software de código abierto compuesta principalmente de Java que permite el procesamiento de grandes cantidades de datos. Además, MongoDB Atlas incluye búsqueda de texto completo, análisis avanzado y un lenguaje de consulta intuitivo. Hadoop es eficaz para almacenar y procesar una gran cantidad de datos, pero lo hace en lotes pequeños. Hay una variedad de herramientas integradas de procesamiento de datos en tiempo real disponibles en MongoDB. Debido a sus conectores para herramientas externas como Kafka y Spark, MongoDB simplifica la ingesta y el procesamiento de datos. Las ventajas de Hadoop y MongoDB frente a las bases de datos tradicionales en el campo del big data son numerosas. Hadoop, un sistema de archivos distribuido, puede usarse para manejar archivos enormes. MongoDB es la única base de datos capaz de reemplazar a una base de datos tradicional en términos de rendimiento.
Rdbms vs Nosql vs Hadoop
Hay tres tipos principales de almacenes de datos: RDBMS, NoSQL y Hadoop. Cada uno tiene sus propias fortalezas y debilidades, por lo que es importante elegir el adecuado para sus necesidades.
RDBMS (Sistema de gestión de bases de datos relacionales) es el tipo más común de almacenamiento de datos. Es fácil de usar y fácil de escalar. Sin embargo, no es tan flexible como NoSQL o Hadoop y su mantenimiento puede ser más costoso.
NoSQL (Not Only SQL) es un tipo de almacén de datos más nuevo que se está volviendo más popular. Es más flexible que RDBMS y puede ser más escalable. Sin embargo, no es tan fácil de usar y puede ser más costoso de mantener.
Hadoop es un tipo de almacén de datos diseñado para big data. Es muy escalable y puede manejar una gran cantidad de datos. Sin embargo, no es tan fácil de usar como RDBMS o NoSQL, y su mantenimiento puede ser más costoso.
El enfoque de una empresa para almacenar, procesar y analizar datos se puede mejorar considerablemente con la plataforma Apache Hadoop . Un lago de datos puede ejecutar varios tipos de cargas de trabajo analíticas en el mismo hardware y software, así como administrar volúmenes de datos a gran escala. Los analistas ahora pueden interactuar de manera efectiva con los datos sobre la marcha utilizando herramientas como Apache Impala y Apache Spark. Hadoop, a diferencia del Sistema de administración de bases de datos relacionales (RDBMS), no tiene las mismas capacidades que una base de datos, sino que es más un sistema de archivos distribuido capaz de procesar cantidades masivas de datos. La cantidad de datos que se pueden procesar fácil y efectivamente se denomina Volumen de volumen de datos. En otras palabras, es el proceso de volumen total de datos durante un período de tiempo específico lo que se puede optimizar. Tiene la capacidad de almacenar y procesar datos de una amplia gama de fuentes y prepararlos para el análisis.
En una pequeña cantidad, el RDBMS solo podía administrar datos estructurados y semiestructurados. Hadoop es incapaz de manejar datos de una variedad de fuentes o cualquier estructura estructurada. El tiempo de respuesta, la escalabilidad y el costo son algunos de los otros factores importantes a considerar.
Por qué Rdbms sigue siendo el sistema de gestión de bases de datos más popular
El sistema de gestión de bases de datos más utilizado en el mundo es el RDBMS. Proporciona una amplia gama de características, además de ser extremadamente confiable. La base de datos relacional es la más adecuada para almacenar datos que se requieren para el acceso de múltiples usuarios.
Las bases de datos NoSQL están ganando popularidad en parte debido a sus ventajas de rendimiento sobre las bases de datos relacionales. También le permiten almacenar grandes cantidades de datos que no necesita compartir con varios usuarios.
Nosql de Hadoop
En un clúster de hardware básico, Hadoop almacena Big Data. Tiene la opción de cambiar cualquier función que no funcione o no satisfaga sus necesidades si es necesario. Por el contrario, un sistema de gestión de bases de datos NoSQL es un tipo de sistema de gestión de bases de datos que se utiliza para almacenar datos estructurados, semiestructurados y no estructurados.
¿Es Hdfs una base de datos?
El sistema de archivos HDFS es un sistema de archivos distribuido que se ejecuta en hardware básico. Se puede configurar un solo clúster de Apache Hadoop para admitir cientos (e incluso miles) de nodos que utilizan esta característica. Apache Hadoop, que también incluye MapReduce e YARN, se compone de varios componentes principales.
El sistema de archivos distribuidos de Hadoop (HDFS), que es un componente del sistema operativo Hadoop, proporciona acceso de alto rendimiento a los datos. El nodo de nombre principal de un clúster es responsable de realizar un seguimiento de dónde se almacenan los datos del archivo del clúster. Además de administrar el acceso a archivos, el nodo Nombre administra el acceso a archivos como lecturas, escrituras, creaciones, eliminaciones, etc. Yahoo introdujo el sistema de archivos distribuidos de Hadoop como parte de sus requisitos de motor de búsqueda y colocación de anuncios en línea. El protocolo HDFS expone un espacio de nombres del sistema de archivos para almacenar datos de usuario. Los DataNodes pueden comunicarse entre sí durante las operaciones normales de archivos porque se comunican entre sí. El sistema de archivos distribuidos de Hadoop (HDFS) es un componente de muchos lagos de datos de código abierto. eBay, Facebook, LinkedIn y Twitter utilizan HDFS para analizar grandes cantidades de datos. En el caso de una falla de nodo o hardware, se requiere la replicación de datos para que HDFS funcione correctamente.
Ejemplo de base de datos de Hadoop
Una base de datos de Hadoop es una base de datos que utiliza el sistema de archivos distribuidos de Hadoop (HDFS) para su almacenamiento subyacente. Las bases de datos de Hadoop generalmente se usan para almacenar grandes cantidades de datos que son demasiado grandes para caber en un solo servidor.
Un marco de código abierto para almacenar y procesar grandes conjuntos de datos de forma distribuida en hardware básico, Apache Hadoop se utiliza en una variedad de aplicaciones. Es una versión de código abierto del paradigma de Google que se utilizó en su artículo MapReduce de 2004. Repasaremos algunas de las preguntas más frecuentes de los principiantes en el ecosistema Big Data en este artículo. La plataforma Apache Hadoop se centra en el procesamiento de datos distribuidos en lugar del almacenamiento de bases de datos o el almacenamiento relacional. A pesar de la presencia de un componente de almacenamiento conocido como HDFS (Sistema de archivos distribuidos de Hadoop), que almacena los archivos utilizados para el procesamiento, HDFS entra en la categoría de una base de datos relacional. Hive, así como HiveQL, se puede usar para consultar el almacenamiento HDFS de HDFS, que está integrado en HDFS.
¿Qué es un ejemplo de Hadoop?
Las empresas de servicios financieros pueden utilizar Hadoop para evaluar el riesgo, crear modelos de inversión y crear algoritmos comerciales; Hadoop también se ha utilizado para ayudar en la creación y gestión de esas aplicaciones. Los minoristas utilizan esta tecnología para ayudarlos a comprender y atender mejor a sus clientes mediante el análisis de datos estructurados y no estructurados.
Los múltiples usos de Hadoop
Hadoop se puede usar para administrar datos en aplicaciones de datos grandes, como análisis de datos grandes, análisis de datos en tiempo real, investigación científica y almacenamiento de datos. Como resultado, es una plataforma versátil y adaptable ideal para una amplia gama de aplicaciones.
¿Es Spark una base de datos Nosql?
Un DataFrame NoSQL, según la documentación, es un formato de fuente de datos para Spark DataFrame. La poda de datos y el filtrado (inserción de predicados) están disponibles en esta fuente de datos, lo que permite que las consultas de Spark se ejecuten en cantidades más pequeñas de datos y solo se cargan los datos necesarios para el trabajo activo.
Se necesita mucho esfuerzo táctico para conectar una base de datos Apache Spark y NoSQL (Apache Cassandra y MongoDB) entre sí. Este blog trata sobre cómo crear aplicaciones Apache Spark en backends NoSQL. TCP/IP sPark es un popular destino de parque temático con una gran cantidad de atracciones en sus conocidas secciones CassandraLand y MongoLand. Cuando nuestra aplicación Spark buscaba datos del DOE, dio vueltas y se frustró. La lección aquí es que la secuencia clave de Cassandra es fundamental en el proceso de obtención de datos. CassandraLand también tiene una popular montaña rusa llamada Partitioner. Se alienta a los clientes de los paseos en montaña rusa a realizar un seguimiento de su historial de viajes para que los operadores puedan rastrear quién montó cada día. Mongo Lección 1: administrar las conexiones de MongoDB correctamente Al actualizar datos, como el estado de los nuevos miembros del parque del Departamento de Energía, los índices de Mongo pueden ser muy útiles. En el caso de actualizaciones específicas, MongoDB y Spark deberían garantizar una correcta indexación y gestión de la conexión.
Spark: el futuro de los grandes datos
Apache Spark, un sistema de procesamiento distribuido desarrollado en colaboración con Apache Software Foundation, es un sistema de procesamiento de big data basado en Hadoop. Un marco de código abierto que se puede utilizar para optimizar grandes conjuntos de datos y cerrar la brecha entre los modelos relacionales y de procedimiento. Además, Spark es compatible con MongoDB, lo que permite su uso para análisis en tiempo real y aprendizaje automático.