
¿Cómo escalan las bases de datos Sql y Nosql?
Publicado: 2022-11-18Con la creciente popularidad de las aplicaciones web y la cantidad de datos que generan, la necesidad de bases de datos que puedan escalar rápida y eficientemente es más importante que nunca. Las bases de datos SQL y NoSQL son dos de las opciones más populares para los desarrolladores que buscan una solución de base de datos escalable. Las bases de datos SQL existen desde hace décadas y son la opción tradicional para muchas aplicaciones. Utilizan un esquema fijo, lo que significa que la estructura de la base de datos se define de antemano y todos los datos deben ajustarse a ese esquema. Esto puede hacer que sea más difícil trabajar con bases de datos SQL cuando los conjuntos de datos son grandes y complejos. Las bases de datos NoSQL, por otro lado, son relativamente nuevas y están diseñadas para trabajar con conjuntos de datos grandes y complejos. Tienen un esquema flexible, lo que significa que la estructura de la base de datos se puede cambiar según sea necesario. Esto puede facilitar el trabajo con las bases de datos NoSQL, pero también significa que es posible que no sean tan confiables como las bases de datos SQL. Tanto las bases de datos SQL como las NoSQL tienen sus pros y sus contras cuando se trata de escalabilidad. Las bases de datos SQL son más difíciles de trabajar pero son más confiables. Las bases de datos NoSQL son más fáciles de trabajar, pero pueden no ser tan confiables.
Se pueden aplicar diferentes técnicas y principios de escalado a una base de datos, dependiendo de su tipo. El escalado es fundamental tanto para las bases de datos NoSQL como para las que no son NoSQL, y el concepto de fragmentación de la base de datos es un componente crucial. Cuando los servidores están distribuidos, obtenemos los beneficios de poder almacenar más datos al mismo tiempo que heredamos los problemas de un sistema distribuido. Los ingenieros tendrían que escribir manualmente la lógica para manejar la fragmentación automática en una base de datos de mainframe porque no es compatible. Como solución, coloque un proxy, como un equilibrador de carga, frente al servicio de consultas y la base de datos. El proxy se puede reiniciar si el fragmento es demasiado grande, lo que permitirá que las consultas se ejecuten más rápidamente. Se supone ampliamente que escalar bases de datos NoSQL es un proceso altamente automatizado que solo ve el usuario final.
Una arquitectura maestro-esclavo se basa en transacciones únicas, mientras que una arquitectura basada en fragmentos se basa en transacciones aleatorias. Una consulta de lectura dirigida a los fragmentos esclavos reducirá la carga en el fragmento principal. Podemos replicar la base de datos a nivel del centro de datos para asegurarnos de tener una copia de seguridad. Los nodos pueden comunicarse entre sí mediante el intercambio de información. Es común que los nodos se comuniquen con un número predeterminado de otros nodos. Un nodo en Cassandra puede simplemente replicar sus datos en otros nodos porque los nodos se consideran iguales. El protocolo de chismes es un subconjunto de todo el concepto de nodos.
Puede renunciar a ciertas propiedades en una base de datos distribuida para obtener más de ellas. Casi siempre es fundamental replicar los datos para mantener la disponibilidad. Tendrá una ligera diferencia en la consistencia de su base de datos al principio, pero esto mejorará con el tiempo. Las bases de datos SQL se utilizan para datos de mayor precisión en los sistemas financieros, mientras que las bases de datos NoSQL se utilizan para datos menos importantes, como el recuento de visitas.
Los dos métodos para escalar una base de datos son el escalado vertical y el aumento de la CPU o RAM de su máquina de base de datos existente. Agregue más máquinas a su clúster de base de datos para manejar un subconjunto de los datos totales para escalar horizontalmente.
Las eras de Internet y la computación en la nube permitieron la creación de bases de datos NoSQL, lo que facilitó la implementación de una arquitectura escalable. Una arquitectura de escalamiento horizontal implica distribuir el almacenamiento de datos y el trabajo requerido para procesarlos en una gran cantidad de computadoras.
La capacidad de manejar grandes cantidades de datos también es ventajosa. Las bases de datos SQL se pueden escalar verticalmente, lo que le permite cargar un servidor más grande con más potencia de CPU, RAM y SSD.
¿Cómo escalan las bases de datos Nosql?
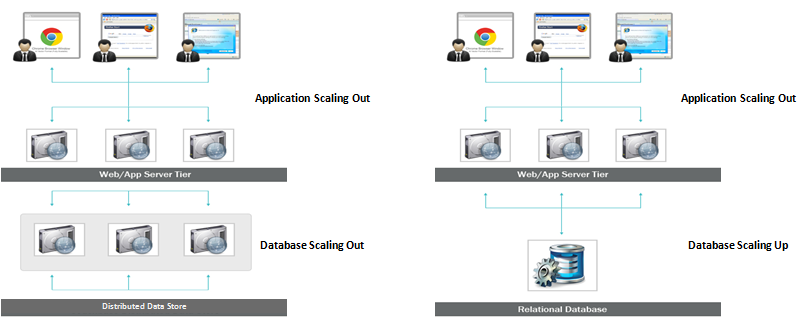
Debido a que las bases de datos SQL son escalables verticalmente, puede aumentar la carga en un solo servidor aumentando la RAM, SSD o CPU en una base de datos SQL. Las bases de datos NoSQL, por otro lado, son escalables horizontalmente, lo que significa que pueden manejar un mayor tráfico más fácilmente al agregar más servidores.
Rahim Yaseen de Couchbase nos guía a través de algunos puntos críticos a medida que avanzamos. Una gran cantidad de datos está inundando las organizaciones y están buscando formas de administrarlos, almacenarlos y explotarlos. La decisión clave en la gestión de bases de datos es si escalar horizontal o verticalmente. La fragmentación manual, en la que cada registro se asigna a una cabina diferente, permite que el registro se distribuya entre varias cabinas de facturación. Como hay un esquema bien definido y predefinido, funciona. Si tuviera marcación automática, necesitaría ir a cada cabina y buscar personas cuyo apellido fuera S. Una base de datos de documentos tiene varios patrones de acceso directo clave que requieren acceder a los datos directamente a través de una sola tecla y navegar a otro documento a través de una clave relacionada. La indexación secundaria y la consulta son dos desafíos importantes cuando se trata de datos distribuidos.
Debido a que cada nodo debe participar en la ejecución de la consulta para ejecutar la consulta, no es necesario utilizar una técnica de reducción de mapa. A medida que crece el volumen de datos, la ampliación al estilo RDBMS se vuelve cada vez menos práctica. Es casi seguro que una falla de una arquitectura de escalamiento vertical subyacente a un gran conjunto de datos resulte en un gran punto de falla. Como ejemplo clásico de un clúster de ultraescala sin nada compartido, Internet es uno.
Una base de datos NoSQL se puede escalar horizontalmente para satisfacer las necesidades de una amplia gama de usuarios. Es posible utilizarlos en cualquier máquina, sin necesidad de hardware especializado. Como resultado, NoSQL es una excelente opción para los sistemas que requieren la capacidad de escalar rápidamente o sin conocimientos extensos.
¿Cómo escalan las bases de datos Sql?
Una escala es un número que tiene un valor a la derecha del punto decimal. Hay una precisión de 5 en este número, por ejemplo, y una escala de 2. En SQL Server, los tipos de datos numéricos y decimales pueden alcanzar una precisión máxima de 38 bits. El máximo predeterminado de SQL Server en versiones anteriores era 28.
En este artículo, proporcionaré algunas ideas básicas y consejos sobre cómo escalar las bases de datos relacionales tradicionales. Está ampliamente aceptado que el escalado debe realizarse verticalmente (en un único servidor de base de datos) utilizando un mejor hardware. Siempre es fundamental equilibrar la eficiencia y la funcionalidad al seleccionar los tipos de datos. La normalización y desnormalización de datos son dos formas fundamentales de pensar en los tipos de datos óptimos. Al analizar grandes cantidades de datos, el preprocesamiento de datos puede resultar beneficioso. Cuando se utilizan índices adecuados en las tablas, el rendimiento puede mejorar considerablemente. Debemos saber exactamente cómo nuestro planificador de consultas maneja nuestras consultas para asegurarnos de que realiza el trabajo correctamente.
Cuando observamos la estructura de nuestros datos, podemos determinar si agregar índices o reescribir nuestra consulta. Los cuatro niveles básicos de aislamiento definidos en el estándar SQL:1992 afectarán en gran medida la forma en que usamos nuestro sistema de base de datos . Antes de decidir si la compresión en la capa de aplicación proporcionará el beneficio deseado, primero debe examinar cómo se almacenan los datos y si se requiere compresión. Dado que insertar una columna en una ubicación específica lleva mucho tiempo, es preferible insertar una nueva columna al final de la tabla. Es posible que el capó de una base de datos ya esté repleto de datos comprimidos. Podemos escalar horizontalmente para operaciones de escritura agregando más servidores, pero también podemos usar réplicas de solo lectura para expandir nuestra capacidad. El particionamiento con esteroides nos permite almacenar partes de la tabla de la base de datos (fragmento) en diferentes servidores.
Sharding es el proceso de almacenamiento de datos en bases de datos. Se puede utilizar otra extensión de base de datos, como TimescaleDb o PostGIS, para mejorar la eficiencia del procesamiento y el almacenamiento de datos. Es posible transferir datos de un sistema a otro y procesarlos allí. También podemos enviarlo a una base de datos analítica, como Hadoop o Clickhouse. La distribución Apache Spark es un software de cómputo en clúster distribuido gratuito y de código abierto que se puede usar para el cómputo de datos a gran escala. Otras formas de mover datos incluyen copiar la base de datos, extraer datos mediante SQL, etc. Si elige proveedores de la nube como AWS o Azure, debe tener en cuenta que no admiten bases de datos SQL administradas.
Esta limitación se magnifica cuando se trata de grandes conjuntos de datos que se distribuyen en varios nodos. MySQL Cluster divide estos conjuntos de datos en partes manejables y los distribuye a los nodos en paralelo. Si la base de datos tiene una instantánea en cualquier momento, no necesitará esperar a que una consulta arroje un resultado. Como resultado, puede utilizar esta ventaja de escalabilidad para analizar grandes conjuntos de datos en tiempo real o procesar datos de forma masiva. MySQL Cluster es una excelente opción para cargas de trabajo que requieren una operación simple debido a su facilidad de uso, lo que le permite ahorrar dinero y tiempo al mismo tiempo que conserva las mismas funciones que una base de datos relacional tradicional. MySQL Cluster es una excelente opción para las empresas que desean escalar sus bases de datos horizontalmente sin sacrificar el rendimiento. En lugar de un sistema de base de datos relacional tradicional, las empresas pueden ahorrar dinero y tiempo utilizando MySQL Cluster.

Los Estados Unidos De América Es Un País Fundado Sobre La Idea De La Libertad La Tierra De Los Libres
¿Es Nosql o Sql más escalable?
En la mayoría de los casos, las bases de datos SQL se pueden escalar verticalmente. Un solo servidor se puede actualizar con más capacidad de CPU, RAM o SSD para manejar más tráfico. Las bases de datos NoSQL se pueden escalar horizontalmente. Al fragmentar, puede aumentar la cantidad de servidores en su base de datos NoSQL, lo que le permite manejar más tráfico.
Las aplicaciones requieren más escalabilidad a medida que se vuelven más complejas. También se deben considerar los almacenes de datos que se pueden escalar de manera eficiente y sencilla. La distinción principal entre los dos es si la base de datos debe ser 'ASL' o 'NoSQL'. Las bases de datos SQL existen desde hace mucho tiempo, mientras que las bases de datos NoSQL son bien conocidas por su facilidad de escalabilidad. Cada operación en una base de datos NoSQL requiere el uso de fragmentación. Cada operación de datos debe incluir un método de calificación, que identifica el nodo donde residen los datos. Los datos se almacenan en varias máquinas, lo que facilita las operaciones de datos incluso en máquinas de baja potencia.
Para facilitar el escalado de las tiendas NoSQL , se utilizan máquinas básicas simples. Basado en NoSQL, el usuario asume que planificará y estructurará los datos de tal manera que todos los datos requeridos para una operación específica puedan obtenerse de una sola vez desde el mismo nodo. Los datos también deben normalizarse entre nodos (datos precocinados para la operación) para poder normalizarse. En NoSQL, puede unir archivos, pero no espere uniones de estilo SQL con estructuras optimizadas. Las aplicaciones en el mundo NoSQL creen que la consistencia de los datos está asegurada a lo largo del tiempo. Tiene sentido que los sistemas NoSQL proporcionen conmutadores para realizar cambios en la coherencia más allá de lo que se requiere. Un aspecto importante de cualquier decisión de arquitectura, como cualquier otro aspecto, es observar el caso de uso y seleccionar el almacén de datos adecuado.
Elegir la base de datos correcta es fundamental porque requiere una gran cantidad de usuarios. MongoDB, Apache HBase y Cassandra son bases de datos NoSQL que se pueden implementar más rápidamente que las bases de datos estándar . La razón de esto es que no se adhieren al modelo ACID, lo que puede resultar en un rendimiento más bajo. Las bases de datos NoSQL, por otro lado, son capaces de funcionar a altos niveles cuando es necesario. Al seleccionar una base de datos, asegúrese de que sea adecuada para sus necesidades.
¿Por qué usar bases de datos relacionales?
Tiene mucho sentido escalar su base de datos verticalmente porque está bien protegida y tiene baja latencia. Las bases de datos no relacionales, a diferencia de las bases de datos relacionales compatibles con ACID, carecen de consistencia y seguridad para el rendimiento y la escalabilidad. Una base de datos NoSQL es una excelente opción para el escalado horizontal porque no tiene límite en la cantidad de servidores y puede escalar rápidamente debido a su baja velocidad de procesamiento.
¿Por qué Sql no es escalable horizontalmente?
SQL no es escalable horizontalmente porque es un sistema de administración de bases de datos relacionales (RDBMS). Los RDBMS no están diseñados para escalar horizontalmente. Están diseñados para escalar verticalmente, lo que significa que están diseñados para escalar agregando más recursos (CPU, memoria, etc.) a un solo servidor.
¿Por qué Nosql es mejor para el escalado horizontal?
Una base de datos NoSQL se puede escalar horizontalmente. Además de manejar un mayor tráfico, la fragmentación le permite agregar más servidores a su base de datos NoSQL. No es ningún secreto que las bases de datos NoSQL son la opción preferida para conjuntos de datos grandes y que cambian con frecuencia porque sus capacidades de escalado horizontal superan sus capacidades de escalado vertical.
Cómo escalar la base de datos Nosql
escalar bases de datos nosql es un proceso de aumentar la capacidad de un sistema para manejar mayores cargas de trabajo mediante la adición de más recursos. El proceso de escalado de una base de datos nosql se puede dividir en dos enfoques principales: escalado vertical y escalado horizontal.
El escalado vertical es el proceso de agregar más recursos a un solo nodo en un sistema, como agregar más núcleos de CPU, memoria o almacenamiento. Este enfoque se puede utilizar para aumentar la capacidad de una base de datos nosql para manejar más datos o más usuarios.
El escalado horizontal es el proceso de agregar más nodos a un sistema. Este enfoque se puede usar para aumentar la capacidad de una base de datos nosql para manejar más datos o más usuarios agregando más nodos al sistema y distribuyendo la carga de trabajo entre los nodos.
Si tiene un entorno Node.js en funcionamiento, podrá completar este tutorial. Creé una carpeta llamada nodejs-dynamodb-sample que contiene los archivos de DynamoDB que importé. Consulte mi página de GitHub para obtener un enlace a la muestra. La aplicación de muestra está disponible para buscar y recuperar datos de películas de DynamoDB. En este artículo, utilizaremos el servicio de administración de acceso e identidad (IAM) de Amazon para almacenar datos en S3 y acceder a DynamoDB en Amazon Web Services (AWS). Primero debe registrarse y crear un usuario para utilizar el servicio IAM de Amazon. Puede crear una nueva cuenta POST /movies ingresando el título y el año de una película.
Si desea realizar un seguimiento de las películas de un año específico, ingrese un campo con clave. A continuación, puede pasar a la creación de su propia aplicación basada en esta. Si no elimina sus tablas después de que se hayan utilizado, corre el riesgo de incurrir en costos de alojamiento y servicio de AWS. Cuando visita la consola de DynamoDB en Amazon Web Services, puede ver cuánto almacenamiento tiene en AWS. Puede ver los elementos en una tabla en la tabla Elementos, acceder a las métricas desde su aplicación y ver el costo mensual estimado haciendo clic en "Películas". El código para este ejercicio se puede encontrar en mi página de GitHub, https://github.com/adamfowleruk/nodejs-dynamodb-sample.
Los pros y los contras de las bases de datos Nosql y Sql
Por una variedad de razones, las bases de datos NoSQL han surgido como una alternativa a las bases de datos SQL tradicionales . El proceso de escalado es en gran medida invisible para el usuario final porque está diseñado teniendo en cuenta la escala. Como resultado, son ideales para aplicaciones que requieren un alto rendimiento o una baja latencia. Las bases de datos NoSQL son más adecuadas para datos no estructurados, como documentos, mientras que las bases de datos SQL son más adecuadas para transacciones de varias filas. En general, hay una diferencia en cómo se manejan las transacciones en cada tipo de base de datos. Las bases de datos SQL se distinguen por filas de tablas para transacciones, mientras que las bases de datos NoSQL se distinguen por documentos para transacciones. Si bien esta diferencia no siempre es obvia, puede ser significativa en ciertos casos.
¿Cómo escala Nosql horizontalmente?
Las bases de datos Nosql están diseñadas para ser escalables, lo que significa que pueden manejar cantidades crecientes de datos y tráfico sin ralentizarse. Una forma de lograr esto es escalando horizontalmente, lo que significa agregar más servidores al sistema según sea necesario. Esto contrasta con el escalado vertical, lo que significa agregar servidores más potentes.
Las bases de datos Nosql son más fáciles de escalar horizontalmente
Debido a que las bases de datos NoSQL no tienen esquemas, es más fácil escalar horizontalmente porque los objetos se pueden almacenar en diferentes servidores sin tener que unir filas. La base de datos del sistema se carga desde varios servidores como parte del escalado horizontal.
Diferencia entre Sql y Nosql
Las bases de datos SQL son bases de datos relacionales que utilizan un lenguaje de consulta estructurado para almacenar y recuperar datos. Las bases de datos NoSQL son bases de datos no relacionales que no utilizan un lenguaje de consulta estructurado y suelen ser más escalables y eficaces que las bases de datos SQL.
Los lenguajes de consulta estructurados (SQL) se encuentran entre los lenguajes de programación más utilizados y populares para los sistemas de administración de bases de datos relacionales . Los datos almacenados y recuperados en modelos NoSQL que no sean formularios tabulares son más fácilmente accesibles. Ambos productos se enumeran con una comprensión completa de sus ventajas y desventajas para brindarle una imagen clara de sus ventajas y desventajas. SQL es el lenguaje de programación más popular para RDBMS y se usa para almacenar datos no estructurados, semiestructurados y estructurados, mientras que NoSQL es el lenguaje de programación más popular para almacenar datos estructurados, no estructurados y semiestructurados. Dependiendo de sus requisitos y del proyecto en el que esté trabajando, cuál es mejor es una buena opción. Hay una distinción entre los dos tipos: el primero se centra en consultas complejas con coherencia de datos y propiedades ACID, mientras que el segundo está basado en objetos y puede manejar una amplia gama de tipos de datos.