
Cómo mantener relaciones entre datos en una base de datos NoSQL
Publicado: 2022-11-23Las bases de datos NoSQL son cada vez más populares a medida que la cantidad de datos que se generan continúa creciendo a un ritmo exponencial. Sin embargo, todavía hay mucha confusión sobre cómo funcionan estas bases de datos y cómo mantener las relaciones entre los datos en un entorno NoSQL. En una base de datos SQL tradicional, los datos se almacenan en tablas y las relaciones se mantienen a través de claves externas. En una base de datos NoSQL, los datos a menudo se almacenan en documentos, que son similares a los objetos en un lenguaje de programación orientado a objetos. Los documentos se pueden anidar, lo que significa que las relaciones se pueden mantener sin necesidad de claves externas. Hay varias formas diferentes de mantener las relaciones entre los datos en una base de datos NoSQL. La forma más común es utilizar documentos de referencia. Un documento de referencia es un documento que contiene una referencia a otro documento. Por ejemplo, si tiene una colección de publicaciones de blog, cada publicación podría tener una referencia al documento del autor. Otra forma de mantener las relaciones entre los datos en una base de datos NoSQL es usar documentos incrustados. Un documento incrustado es un documento que se almacena dentro de otro documento. Por ejemplo, si tiene una colección de publicaciones de blog, cada publicación podría tener un documento incrustado que contenga la información del autor. La ventaja de usar documentos de referencia o documentos incrustados es que es más fácil actualizar los datos en el futuro. Por ejemplo, si desea cambiar el autor de una publicación de blog, solo necesita actualizar el documento del autor. No es necesario actualizar cada entrada de blog individual. La desventaja de usar documentos de referencia o documentos incrustados es que puede hacer que los datos sean más difíciles de consultar. Por ejemplo, si desea encontrar todas las publicaciones de blog escritas por un autor en particular, deberá consultar el documento del autor para cada publicación. Esto puede ser ineficiente si tiene una gran cantidad de documentos. Si está trabajando con una base de datos NoSQL, es importante comprender cómo mantener las relaciones entre los datos. Los documentos de referencia y los documentos incrustados son dos de las formas más comunes de hacer esto.
La implementación de NoSQL en una base de datos orientada a documentos es insuficiente o inexistente para el desarrollo de relaciones entre objetos. En esta publicación de blog, le mostraremos cómo delegar la administración de objetos/relaciones a una base de datos. Las relaciones de objetos se crean utilizando la llamada API REST. En este ejemplo, usaremos el verbo PUT para conectar a un cliente con un problema. Cuando una relación se representa de esta manera, siempre está presente una matriz de objetos. Podrá ver los cambios en el documento original después de cada referencia a un objeto (es decir, una relación). Debido a que la base de datos registra el uso de cada relación, también podemos ver dónde se usa un documento específico en una relación. Con las consultas de ejemplo que se muestran a continuación, puede encontrar la presencia de referencias implícitas a un documento mediante una consulta especial: referencedby=true.
Hay relaciones entre varios documentos en MongoDB, lo que denota su relación lógica. Usando enfoques referenciados e integrados, se pueden modelar las relaciones. Veamos el caso de almacenamiento de direcciones para usuarios con relaciones N:N en el siguiente ejemplo.
Las relaciones de muchos a muchos (N:M) son más difíciles de implementar que las relaciones de uno a muchos porque no hay un solo comando en una base de datos relacional para hacerlo. Cuando se implementan en MongoDB, son de la misma manera. MongoDB no le permite crear ningún tipo de relación por defecto.
Las bases de datos no relacionales , también conocidas como "NoSQL", suelen ser bases de datos solo de SQL. Su capacidad para retener información es muy diferente. Una base de datos no relacional generalmente almacena datos en un formato no tabular, lo que la hace más adaptable a las necesidades de las estructuras de datos modernas, como las bases de datos SQL y NoSQL.
¿Puede una base de datos Nosql ser relacional?
Las bases de datos NoSQL no son bases de datos relacionales, lo que significa que pueden tener estructuras diferentes a las bases de datos SQL (como filas y columnas) y pueden adaptarse para satisfacer las necesidades del usuario más fácilmente.
Los sistemas de bases de datos como relacionales y NoSQL se implementan comúnmente en aplicaciones nativas de la nube. Su arquitectura y prácticas de almacenamiento de datos difieren, y también difiere su acceso a la información y los datos. Una base de datos sin SQL almacena datos no estructurados o semiestructurados en pares o documentos que no tienen formato. Se prefieren los almacenes de datos NoSQL cuando los servicios de alto volumen requieren tiempos de respuesta inferiores a un segundo. Si está buscando un sistema coherente para un elemento que se está actualizando actualmente, espere esa respuesta hasta que todas las réplicas se actualicen correctamente. Incluso si la respuesta no es la más reciente, cada nodo devolverá una respuesta instantánea. Si falla un nodo de datos replicado, la tolerancia de partición garantiza que el sistema seguirá funcionando.
Se prefiere la base de datos como servicio (DBaaS) sobre otros tipos de servicios de datos para aplicaciones nativas de la nube. Estos servicios se pueden utilizar para proporcionar seguridad, escalabilidad y supervisión. Puede configurar una máquina virtual de Azure e instalar una base de datos de su elección encima para cada servicio. Un microservicio nativo de la nube puede aprovechar las bases de datos relacionales o NoSQL según los requisitos del usuario. La plataforma de base de datos como servicio (DBaaS) de Azure incluye cuatro bases de datos relacionales administradas. No hay necesidad de contenerse cuando se trata de modelos justo a tiempo y de pago por uso. La base de datos insignia de Microsoft, SQL Server, está disponible, así como una serie de alternativas de código abierto.
Al seleccionar la cantidad de núcleos de procesamiento, memoria y almacenamiento necesarios, puede aprovisionar una base de datos de Azure en menos de un minuto. Microsoft se compromete a mantener Azure como una plataforma abierta, por lo que la empresa ofrece versiones administradas de bases de datos populares de código abierto. El nivel de cómputo sin servidor suspende automáticamente las bases de datos durante los períodos inactivos, lo que permite que solo se deduzcan los cargos de almacenamiento. Oracle adquirió Sun Microsystems y la versión administrada de MariaDB se creó como una bifurcación de MySQL. Azure Database for MariaDB es un servicio de base de datos completamente administrado que se proporciona como parte de la nube de Azure. El servicio se basa en el motor del servidor de la edición comunitaria de MariaDB. Puede manejar cargas de trabajo de misión crítica proporcionando un rendimiento predecible y escalado dinámico.
La herramienta de interfaz de línea de comandos o el Servicio de migración de datos de Azure son formas excelentes de migrar bases de datos de Postgres. Además de la compatibilidad con la agrupación en clústeres activa/activa a nivel global, CosmosDB admite escrituras y lecturas, lo que le permite configurar cualquiera de las regiones de su base de datos para hacerlo. El sistema de base de datos CosmosDB se puede usar para migrar bases de datos existentes de Mongo, Gremlin o Cassandra con cambios mínimos de código o datos. Azure Table Storage se puede transferir fácilmente a CosmosDB Table API para los servicios que lo consumen. La figura 5-13 contiene cinco modelos de coherencia bien definidos para Azure Cosmos DB. Estas opciones simplifican la gestión de las compensaciones entre consistencia, disponibilidad y rendimiento. La siguiente tabla muestra los niveles de consistencia para cada uno.
Jeremy Likness, administrador de programas de Microsoft, brindó una excelente explicación de los cinco modelos. Una nueva tecnología de base de datos conocida como NewSQL combina escalabilidad distribuida con garantías ACID para crear una base de datos orientada a objetos. Cuando los entornos de nube son efímeros, tiene sentido que las bases de datos newSQL prosperen como resultado de la presencia de máquinas virtuales subyacentes que se pueden reiniciar o reprogramar en cualquier momento. La cifra anterior incluye proyectos de código abierto creados por Cloud Native Computing Foundation. A diferencia de otras cargas de trabajo, que usan una construcción de servicio, un cliente puede enviar una sola solicitud de DNS a un grupo de procesos de base de datos NewSQL idénticos. Podemos escalar sin afectar la disponibilidad de las instancias de aplicaciones existentes si desacoplamos las instancias de bases de datos de las direcciones de los servicios asociados con ellas. Una solicitud específica a un servicio siempre producirá el mismo resultado, independientemente de cuántas solicitudes se envíen al mismo tiempo.
Debido a sus muchas ventajas, las bases de datos NoSQL se están volviendo rápidamente más populares. La capacidad de escalar horizontalmente, manejar más datos, almacenar datos de manera más flexible e integrarse con otros sistemas son todas ventajas de la computación en la nube. Hay una serie de ventajas de las bases de datos NoSQL sobre las bases de datos relacionales tradicionales .
¿Puede Mongodb ser relacional?
Además de ser un sistema de base de datos no relacional bien establecido con mayor flexibilidad y escalabilidad horizontal, MongoDB tiene algunas ventajas sobre las bases de datos relacionales, como la integridad referencial y la concurrencia.
¿Es Snowflake una base de datos relacional?
No sorprende que Snowflake sea una poderosa base de datos relacional. Puede usarlo con todos los principales modelos de datos relacionales, incluidos los tres estándar (tablas, relación y unión) y el modelo de copo de nieve más inusual. La base de datos también es compatible con la transmisión en tiempo real, la indexación de objetos y la aceleración de consultas, así como con todas las funciones modernas de bases de datos relacionales que se encuentran en las bases de datos modernas . ¿Es relacional o no? Esta base de datos es una base de datos relacional.
¿Qué base de datos Nosql no admite relaciones o uniones?

Hay algunas bases de datos nosql que no admiten relaciones ni uniones, incluidas MongoDB, Cassandra y Hbase. Si bien estas bases de datos no son tan populares como algunas de las otras, muchas organizaciones todavía las utilizan.
Oracle NoSQL Database no admite el operador de unión general que se usa en las bases de datos relacionales tradicionales. Sin embargo, proporciona un tipo especial de combinación para tablas con la misma jerarquía. Como resultado, la ejecución de uniones es muy simple porque solo las filas coubicadas pueden coincidir.
Relación de entidad en Nosql
Una relación de entidad en nosql es una relación entre dos o más entidades en una base de datos nosql. Esta relación puede ser de uno a uno, de uno a muchos o de muchos a muchos.
Diagramas Er para bases de datos de documentos
Sin embargo, puede usar los principios de modelado ER para construir un diagrama ER para una base de datos orientada a documentos de manera similar. Cree un modelo de datos que pueda usarse para almacenar sus documentos. Los tipos de documentos que desea almacenar, los campos y las propiedades de cada documento y el modelo en su conjunto deben incluirse en este modelo de datos. Se requiere un diagrama de entidad para crear su modelo de datos. El siguiente diagrama demostrará la estructura de datos en su almacén de documentos. Luego, utilizando el diagrama de relaciones, cree un modelo de datos. El siguiente diagrama muestra la relación entre las entidades dentro de su modelo de datos.
Relación de muchos a muchos en Nosql
Una relación de número a muchos es aquella en la que dos entidades pueden estar vinculadas por múltiples instancias de la misma entidad. Hay algunos ejemplos de la vida real: los médicos pueden tratar a muchos pacientes y al mismo tiempo tener muchos médicos.
Quiero implementar una estructura de taxonomía (términos geográficos) para mi aplicación node.js con una base de datos NoSQL. La idea detrás de las etiquetas geográficas era identificar a las personas que nacieron en ciertas ciudades o pueblos con esos términos, filtrarlos más tarde y etiquetarlos. John Doe nació en Blackburn (Lancashire) en 1957, Paul Brown en Liverpool en 1960 y Georgia Doe en Wirral en 1982. Si solo hay algunos elementos de estructura en el país que siguen a los modernos, se filtrarán de manera que no son posibles Soy un novato en el mundo NoSQL (no he diseñado ninguna base de datos NoSQL, por lo que tengo un serio desafío de diseño por delante). Creo que hay varias opciones para solucionarlo.

Notación de pata de gallo: la relación de muchos a muchos
Por lo general, verá la notación de pata de gallo en una base de datos cuando represente gráficamente varias relaciones. Las relaciones entre tablas se representan mediante una serie de líneas, según esta notación. Los orígenes de un gráfico (esquina superior izquierda) generalmente comenzarán con una línea que baja a la tabla denominada "extranjera" (porque ahí es donde está el origen). A continuación, las líneas irán a la tabla relacionada, seguida de la tabla secundaria.
Documentación Nosql
La documentación Nosql es un proceso o un conjunto de reglas que se utilizan para escribir código Nosql . Es un estilo de codificación que está diseñado para hacer que el código nosql sea más legible y fácil de entender.
Las bases de datos NoSQL, a diferencia de las bases de datos relacionales tradicionales, no almacenan datos en un formato fijo. Los tipos más comunes son documentos, valores clave, columnas anchas y gráficos. A fines de la década de 2000, una disminución significativa en los costos de almacenamiento condujo al desarrollo de bases de datos NoSQL. Los desarrolladores pueden usar estas herramientas para almacenar cantidades masivas de datos no estructurados, lo que les permite trabajar en una amplia gama de proyectos. Las bases de datos de documentos, las bases de datos de valores clave, los almacenes de columnas anchas y las bases de datos de gráficos son algunas de las bases de datos NoSQL más comunes. Debido a que no se requieren uniones, las consultas son más rápidas. Los casos de uso más comunes incluyen aplicaciones críticas (p. ej., datos financieros) y más divertidas (p. ej., almacenamiento de lecturas de IoT de una caja de arena inteligente para gatos).
En este tutorial, veremos cómo funciona una base de datos NoSQL y por qué es beneficiosa para una variedad de aplicaciones. Además, veremos algunos conceptos erróneos comunes sobre las bases de datos NoSQL y sus aplicaciones. Según DB-Engines, MongoDB es la base de datos no relacional más utilizada del mundo. No necesita ningún software en su computadora para consultar una base de datos MongoDB en este tutorial. Un clúster es una colección de bases de datos donde se almacenan bases de datos MongoDB . Se puede acceder al almacén de datos de Atlas cuando tiene un clúster. Hay tres tipos de bases de datos que puede crear: manualmente en Atlas Data Explorer, en MongoDB Shell o en MongoDB Compass, según su lenguaje de programación preferido.
Este ejemplo mostrará cómo importar el conjunto de datos de muestra de Atlas. Una base de datos NoSQL puede proporcionar una serie de ventajas a los desarrolladores, como modelos de datos flexibles, escalado horizontal, consultas ultrarrápidas y facilidad de uso. Puede insertar nuevos documentos, editar los existentes y eliminar documentos en el Explorador de datos. Usando el marco de agregación, puede analizar sus datos de una manera muy poderosa. Puede ver fácilmente los datos de Atlas y Atlas Data Lake en gráficos.
Consulta Nosql
Las bases de datos NoSQL se utilizan a menudo cuando la escalabilidad es más importante que la coherencia de los datos. Las bases de datos NoSQL también se denominan a veces "no solo SQL" para enfatizar que pueden admitir lenguajes de consulta similares a SQL.
Anteriormente, los modelos de datos y los sistemas de consulta estaban estrechamente integrados. Ahora podemos crear sistemas de bases de datos que prioricen la productividad del desarrollador y comenzar a abstraer el método de consulta del modelo de datos para priorizar la productividad del desarrollador. SABRE, la primera base de datos comercial del mundo, fue fundada en 1994 por IBM y American Airlines para mejorar la eficiencia de los boletos aéreos. Las bases de datos NoSQL se han optimizado para la escalabilidad, el tiempo de actividad, la redundancia, la flexibilidad y la flexibilidad en los últimos años. Además de agregar map-reduce como opción en Riak y MongoDB, también lo agregaron a CouchDB y Riak. Esperábamos una consulta declarativa ad-hoc directa de SQL, pero resultó ser más un truco de secuencias de comandos. Si está creando un sistema de base de datos que se escalará fácilmente, la consulta no es su enfoque principal.
XQuery y Jsoniq son intentos de crear un lenguaje de consulta estándar que se puede usar para recuperar documentos jerárquicos en bases de datos de documentos. MarkLogic, una base de datos de documentos XML, emplea XQuery además de XQuery, mientras que ArrangoDB emplea su propio superconjunto ajustado para el modelado de datos. Ambos idiomas tienen una fuerte conexión con el formato de los datos almacenados en el disco y ambos se han utilizado comercialmente. Uno o ambos idiomas de consulta utilizados en una base de datos de documentos están relacionados con los idiomas de consulta utilizados en la base de datos. N1QL (o lenguaje de consulta que no es de primera forma), a diferencia de SQL, es de naturaleza supremamente similar a SQL. A pesar de que las relaciones no se hacen cumplir, colaboramos en documentos, sin importar si son formales o informales. Tanto Couchbase como Cassandra dedicaron mucho tiempo y esfuerzo a sus índices y análisis de consultas para poder consultar datos de esta manera sin necesidad de realizar búsquedas relacionales.
¿Se puede consultar en Nosql?
El nombre NoSQL no hace referencia a SQL. SQL no es el método preferido de escritura de consultas en No SQL. El software no almacena datos en formato relacional, sino de forma organizada.
¿Qué es el ejemplo Nosql?
Las bases de datos NoSQL basadas en columnas, como Cassandra, HBase e Hypertable, son comunes.
¿Es Nosql más fácil que Sql?
Las bases de datos SQL tienen la ventaja de procesar consultas y unir datos en tablas, lo que permite consultas más complejas en datos estructurados, como solicitudes ad hoc. La consistencia de una base de datos NoSQL entre productos, particularmente cuando se trata de grandes cantidades de datos, es una característica común en este tipo de base de datos.
Modelo de datos Nosql
¿Qué es un modelo de datos NoSQL? ¿Cuáles son los pros y los contras? No existe un sistema de administración de bases de datos relacionales (RDBMS), y este es un modelo que es imposible de replicar. Como resultado, no hay una forma explícita para que el modelo comprenda cómo se relacionan los datos, cómo se unen todos.
8 Patrones de modelado de datos en Redis cubre los fundamentos del modelado de datos en NoSQL, así como las mejores prácticas para comenzar. El libro examina ocho modelos de datos que los desarrolladores pueden usar para crear aplicaciones modernas sin las dificultades que pueden presentar las bases de datos tradicionales . Con NoSQL, puede combinar dos tablas o colecciones separadas para crear una sola tabla o colección. Como resultado, es más fácil encontrar todos los datos relevantes y comprender su relación. Cada tabla en NoSQL se puede ver por sí sola. Cuando desee modelar relaciones de uno a varios, incruste listas limitadas (como listas con tamaños conocidos) y listas ilimitadas por separado. El producto en este caso es el único, y las muchas reseñas, nombres de autores, fechas de publicación, calificación y comentarios son las 'muchas' variables.
El primer patrón es una relación de número de a muchos con lados ilimitados. El objetivo de una base de datos relacional es almacenar productos en tablas separadas. Debido a que los esquemas son tan flexibles y le permiten separar los campos de tipo según el tipo de colecciones, todos los esquemas de Redis Stack se pueden configurar con esta función. A medida que acumula y agrega datos de series temporales, el patrón de depósito reduce la sobrecarga. Un patrón de revisión se puede utilizar en una variedad de contextos donde se requieren datos en tiempo real. Estos patrones se pueden usar para eliminar las complicaciones asociadas con las operaciones JOIN en NoSQL. El patrón de árbol y gráfico es particularmente útil para una variedad de operaciones pesadas basadas en JOIN, como recursos humanos, CMS, catálogos de productos y redes sociales.
Este modelo no es compatible con un sistema de administración de bases de datos relacionales (RDBMS) porque se basa en un modelo que no es compatible con uno. El almacenamiento de datos se puede lograr de varias maneras, incluido el uso de disco, en memoria o ambos. Redis Launchpad tiene varias aplicaciones escritas con NoSQL y Redis.
Documento Aplicación Datos Nosql
Hay muchas razones para usar una aplicación de documentos para almacenar sus datos. En primer lugar, las bases de datos de documentos son muy flexibles y pueden almacenar datos fácilmente en una variedad de formatos. Esto significa que puede almacenar datos en formato JSON, XML o incluso binario si así lo desea. En segundo lugar, las bases de datos de documentos suelen ser más fáciles de escalar que las bases de datos relacionales tradicionales. Esto se debe a que se pueden fragmentar en varios servidores muy fácilmente. Finalmente, las bases de datos de documentos a menudo brindan un mejor rendimiento que las bases de datos relacionales para ciertos tipos de consultas.
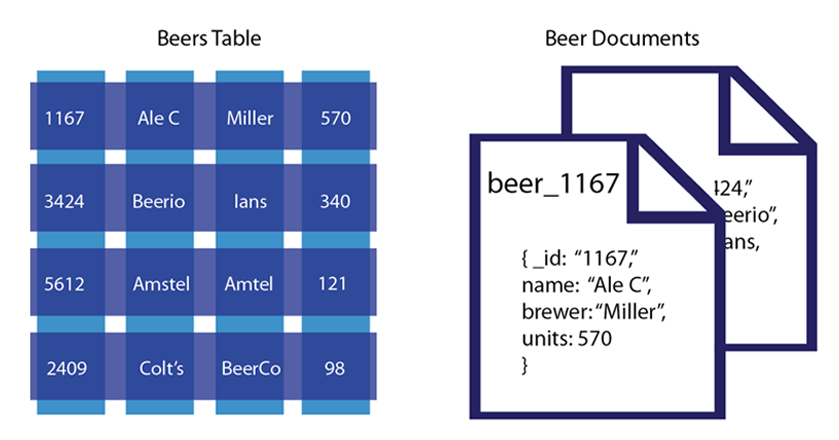
Los datos en las bases de datos orientadas a documentos se almacenan en formato JSON en lugar de en columnas/filas, como en otras bases de datos modernas. Este tipo de datos le permite manejar desafíos que son mucho más difíciles de dominar con RDBMS. Los almacenes de documentos permiten a los desarrolladores colaborar más rápido con software ágil al convertirlos en una solución natural y adaptable. El lenguaje de consulta expresivo y la función de índice multifacético facilitan la consulta de diversas maneras. Al utilizar transacciones ACID, puede conservar todas las garantías que está acostumbrado a tener en una base de datos relacional. Sus datos pueden volverse infinitamente escalables y resistentes como resultado de los sistemas distribuidos. Cada documento se aloja por separado y se distribuye más fácilmente entre servidores para garantizar que la ubicación de los datos no se vea afectada.
Las bases de datos de documentos, a diferencia de las bases de datos relacionales, utilizan modelos intuitivos y prácticos que se pueden leer más rápido. Debido a que la calidad de los datos será menor, habrá tablas menos rígidas. Debido a que no hay escalabilidad nativa, si desea particionar su base de datos relacional tradicional , tendrá que pagar costosos sistemas de escalabilidad vertical. Cada almacén de documentos en una base de datos orientada a documentos contiene campos para diferentes tipos de documentos y son opcionales. Si bien cada documento tiene la misma composición estructural, hay distintos campos en cada documento. Cada documento tiene su propia identificación única que se puede usar para agregar, cambiar, eliminar y consultar información. Generalmente se supone que la codificación de documentos incluye algún formato estándar o compresión de datos (o información) encapsulados.
Las bases de datos orientadas a documentos difieren de las bases de datos convencionales en que son mucho más flexibles y no requieren consistencia. En lugar de enviar datos a columnas dentro de la base de datos, los datos se recuperan directamente del documento. No es necesario agregar nuevos campos de información a cada conjunto de datos, solo los relevantes en el almacén de documentos.
La diferencia entre Mongodb y Sql
Es importante tener en cuenta que los documentos son distintos. No hay límite en el número de campos que se pueden incluir en un documento. Los tipos de documentos también pueden contener campos relacionados con ellos. Un documento, por ejemplo, podría representar a un cliente en una base de datos. El documento incluiría el nombre completo, la dirección y el número de teléfono del cliente. El historial de pedidos del cliente y el saldo de la cuenta también pueden incluirse en los campos.
La distinción entre MongoDB y SQL es que las bases de datos no son tablas y los documentos tampoco son tablas. MongoDB no tiene una colección de campos como SQL. Las colecciones de documentos, por otro lado, se componen de campos que están relacionados.