
Introducción al motor Hasura GraphQL para API dinámicas con PostgreSQL
Publicado: 2019-11-07En general, en los últimos años, las API REST han sido criticadas por ser inflexibles al tratar con requisitos tecnológicos que cambian rápidamente. En retrospectiva, muchos creen que GraphQL se creó para hacer frente a esta necesidad de flexibilidad y eficiencia adicionales en el desarrollo de API. Por lo tanto, mitigando las deficiencias de las API REST. Como resultado de la transición de Facebook de las aplicaciones HTML5 a configuraciones más sólidas y nativas, GraphQL ha aumentado en popularidad y adopción en los últimos cinco años por una buena razón. En este blog, profundizaremos en el fenómeno GraphQL, PostgreSQL y luego tendremos una introducción completa al motor Hasura GraphQL. En un fragmento, la relación y el ecosistema del motor Hasura GraphQL-PostgreSQL.
GraphQL: una rebelión de Facebook
Si bien muchos creen que GraphQL se creó como una rebelión contra las API REST, esto podría estar más lejos de la verdad. Irónicamente, fue creado para satisfacer simplemente una necesidad interna en Facebook. Diseñado originalmente y de código abierto por el equipo de Facebook, GraphQL a menudo se confunde con una tecnología de base de datos. Esencialmente, a pesar de la idea errónea, GraphQL es técnicamente un lenguaje de consulta para API y no para bases de datos. En consecuencia, reduce la complejidad de la creación de API, abstrayendo todas las solicitudes a un único punto final. A diferencia de las API REST tradicionales, GraphQL es declarativo, lo que significa que se devuelve todo lo que se solicita. Aunque para obtener un poco más de contexto, tendremos que dar un paso atrás y volver a visitar las API REST.
La arquitectura REST
Por lo general, las API son reglas, rutinas o protocolos que especifican cómo deben interactuar los componentes del software. La transferencia de estado representacional (REST) es básicamente una arquitectura de diseño de API normalmente aprovechada en la implementación de servicios web donde todo se considera un 'recurso'. Desafortunadamente, la metodología RESTful se limitó consistentemente a tratar con recursos únicos. Por lo tanto, si se necesitaran datos y provinieran de dos o más recursos, por ejemplo, publicaciones y usuarios, se requerirían varios viajes de ida y vuelta al servidor para recopilar todo lo necesario. Además, REST enfrentó problemas con la obtención de "superior" y "inferior". Todo esto no era ideal, especialmente con la aparición de más aplicaciones basadas en datos que manejan grandes conjuntos de datos que combinan recursos relacionados. Lo que podría explicar el predicamento al que se enfrentó Facebook.
Por lo tanto, la necesidad de una arquitectura API que adopte un enfoque más flexible y progresivo.
La creación de una alternativa
Alternativamente, GraphQL no piensa en los datos en términos de URL de recursos, claves secundarias o tablas, sino en términos de un gráfico de objetos y los modelos que utilizan NSObjects o JSON. Específicamente, GraphQL no necesita puntos finales dedicados por caso de uso, ya que se pueden representar diferentes capacidades y casos de uso en un solo "Gráfico". Con el lenguaje de consulta GraphQL, puede describir exactamente cómo debería ser la respuesta, por lo que no se necesitan viajes de ida y vuelta adicionales al servidor. Como lenguaje de consulta de capa de aplicación, está diseñado para interpretar una cadena de un servidor/cliente y devolver esos datos en un formato estable, comprensible y predecible. Es simplemente una herramienta para consolidar mejor los datos.
Simplicidad, Estabilidad y Eficiencia.
La verdad es que no todos los proyectos requieren GraphQL a pesar de su esquema bien definido, por lo que sabemos con certeza que no nos excederemos. Sin embargo, si tenemos un producto empresarial que se basa en datos de múltiples fuentes, por ejemplo, MySQL, Postgres y otras API, entonces GraphQL es la mejor opción. GraphQL se enorgullece de su simplicidad, especialmente en lo que respecta a la recuperación de datos, ya que los datos se recopilan bajo un punto final o llamada común. Esencialmente, dado que los clientes obtienen exactamente lo que necesitan, esto reduce efectivamente el tamaño de cada solicitud realizada por el cliente, lo que da como resultado aplicaciones de alto rendimiento. Dado que GraphQL unifica los datos que, de lo contrario, requerirían múltiples puntos de conexión, facilita las recuperaciones repetidas complejas y, por lo tanto, mejora la eficiencia de las consultas. En consecuencia, con su simplicidad viene más estabilidad de back-end, planificación, construcción, ejecución y operación continua a lo largo del tiempo.
Ventajas de GraphQL
En pocas palabras, GraphQL permite la extracción de datos con consultas fácilmente comprensibles, permite el desarrollo rápido de aplicaciones ligeras y rápidas porque se accede a los datos de forma más directa en lugar de a través de un servidor. Además, permite la recuperación de varios recursos con una consulta sin usar varias URL o encadenar recursos, mientras usa un punto final para todos los datos. Recuerde, los datos se definen en el servidor con un esquema basado en gráficos, por lo que se entregan como un paquete en lugar de múltiples llamadas. Esto permite un impulso operativo en la agregación de respuestas de API durante el desarrollo de API.
Esto, a su vez, reduce la carga de los equipos de desarrollo front-end, facilita el control de versiones de la API, simplifica el mantenimiento y ahorra demandas de transferencia de datos. Además, permite una mayor previsibilidad al recibir datos, admite la obtención de datos declarativos y mitiga la obtención excesiva y la obtención insuficiente. Esencialmente, la obtención excesiva ocurre cuando un cliente descarga más información de la que realmente se requiere en la aplicación, mientras que la obtención insuficiente implica que un punto final específico no ha proporcionado suficiente información, lo que requiere que el cliente realice solicitudes adicionales para obtener lo que necesita.
Técnicamente, GraphQL es un contenedor que se puede definir, lo que significa que no tiene que reemplazar por completo un sistema REST. Básicamente, esto significa que GraphQL es compatible con los sistemas con los que son compatibles las API centradas en REST. Además, GraphQL permite un desarrollo continuo e independiente de front-end y back-end. Esto se debe a que una vez que el esquema está bien definido, los equipos que trabajan tanto en el front-end como en el back-end son conscientes de la estructura definitiva de los datos. Todos estos beneficios son vistos como ventajosos por muchos ingenieros full-stack. Por último, GraphQL tiene una capacidad asombrosa para la introspección y la autodocumentación exhaustivas.

Casos de uso de GraphQL en el desarrollo de API
Considerado extremadamente poderoso, GraphQL es utilizado por desarrolladores de pila completa que buscan una legibilidad estable con velocidad e indexación rápidas. Específicamente, GraphQL es útil en el desarrollo de API que requiere un alto rendimiento de datos. De hecho, minimiza la cantidad de datos necesarios para la transferencia a través de una red. Esto es muy beneficioso para usuarios móviles, dispositivos de baja potencia y redes descuidadas. Cuál es una de las razones iniciales por las que Facebook diseñó GraphQL. Contrariamente a lo que se cree, GraphQL no solo es aplicable en enormes bases de datos complejas, sino que puede crear bases de datos relativamente simples con mayor eficiencia.
Además, se puede aplicar en una variedad de marcos y plataformas front-end únicos, lo que proporciona un panorama heterogéneo mantenido con una API para adaptarse a todos los requisitos del usuario. Además, facilita el desarrollo rápido de funciones, ya que aumenta drásticamente la velocidad de las funciones para los equipos de desarrolladores de pila completa. Lo hace al reducir la comunicación requerida entre los equipos mientras se desarrollan nuevas funciones, ya que los desarrolladores front-end pueden realizar solicitudes de API, por ejemplo, para introducir nuevas funciones o cambiar las existentes sin tener que esperar a que los desarrolladores back-end entreguen. Este resumen rápido de GraphQL debería ser suficiente por ahora a medida que avanzamos en nuestra introducción al motor Hasura GraphQL. Aunque toquemos PostgreSQL para un poco más de contexto.
¿Qué es PostgreSQL?
Como sistema gratuito de gestión de bases de datos relacionales impulsado por la comunidad, PostgreSQL no es propiedad de ninguna empresa. Considerado el RDBMS más potente y consistente internamente disponible, Postgres se escribió en C y es compatible con varios lenguajes de programación, como C/C++, JavaScript, Java, Python, R, Go, Lisp, .Net, etc. Cada vez más preferido entre la mayoría Desarrolladores de pila completa, PostgreSQL tiene más funciones que su hermana MySQL, ganando popularidad debido a sus características, escalabilidad y rendimiento. PostgreSQL es popular en proyectos donde los requisitos giran en torno a procedimientos complejos, diseños intrincados, integración a medida e integridad de datos.
Ventajas de Postgres para desarrolladores Full-Stack
En general, las funciones como la búsqueda de texto completo, las columnas JSON y la replicación lógica le dan a Postgres la ventaja sobre MySQL. Esto es óptimo para las demandas de rendimiento de las bases de datos comerciales típicas al tiempo que permite la consolidación de varios sistemas de bases de datos en uno solo con menos gastos generales y costos. Además, sus funciones más recientes para el almacenamiento de valores clave (tipos de columna JSON / JSONB) lo convierten en una alternativa adecuada a las bases de datos NoSQL. Además, admite la agrupación en clústeres o una arquitectura maestro-esclavo, lo que lo hace ideal para entornos similares a la nube. Además, su popular extensión de contenedor de datos externos permite consultar fuentes externas directamente desde PostgreSQL cuando sea necesario. Específicamente, es más adecuado para sistemas que requieren la ejecución de consultas complejas, almacenamiento de datos y análisis de datos dinámicos.
De hecho, PostgreSQL admite mejor ciertas características que MySQL no admite. Por ejemplo, verifique las restricciones, los tipos de datos enriquecidos (como arreglos, mapas, JSON), soporte geoespacial más enriquecido (PostGIS) y soporte de texto completo más enriquecido. Además, admite la creación de índices sin bloqueo, índices parciales, expresiones de tablas comunes y funciones de análisis más dinámicas. No obstante, PostgreSQL ofrece soporte SLL nativo para conexiones para el cifrado de comunicaciones cliente/servidor, así como una mejora integrada denominada SE-PostgreSQL que proporciona controles de acceso adicionales basados en la política de SELinux.

Con muchas características enriquecidas para productos de nivel empresarial, PostgreSQL es apropiado para sistemas grandes donde los datos requieren autenticación y las velocidades de lectura/escritura son fundamentales para el éxito del proyecto. Además, también es compatible con múltiples potenciadores de rendimiento que normalmente están disponibles en soluciones propietarias. Estos incluyen: simultaneidad sin bloqueos de lectura, servidor SQL y compatibilidad con datos geoespaciales, por mencionar algunos.
Otra ventaja principal de la arquitectura Postgres es su extensibilidad única. Permite a los usuarios agregar funciones como tipos de datos, métodos de acceso a índices, lenguajes de programación de servidor, contenedores de datos externos (FDW) y extensiones cargables sin cambiar el código del sistema central. Aprovecha una moderna arquitectura de procesador multinúcleo, lo que permite que su rendimiento crezca casi linealmente a medida que aumenta la cantidad de núcleos. Esto es importante. Por lo general, las funciones como la búsqueda de texto completo, las columnas JSON y la replicación lógica dan a Postgres la ventaja sobre MySQL. Esto es óptimo para las demandas de rendimiento de las bases de datos comerciales típicas al tiempo que permite la consolidación de varios sistemas de bases de datos en uno solo con menos gastos generales y costos. Además, sus funciones más recientes para el almacenamiento de valores clave (tipos de columna JSON / JSONB) lo convierten en una alternativa adecuada a las bases de datos NoSQL. Además, admite la agrupación en clústeres o una arquitectura maestro-esclavo, lo que lo hace ideal para entornos similares a la nube. Además, su popular extensión de contenedor de datos externos permite consultar fuentes externas directamente desde PostgreSQL cuando sea necesario. Específicamente, es más adecuado para sistemas que requieren la ejecución de consultas complejas, almacenamiento de datos y análisis de datos dinámicos.

Contras de PostgreSQL
En general, si le gustan los estándares ANSI SQL, considere PostgreSQL, aunque si prefiere los estándares ODBC, opte por MySQL. Desafortunadamente, Postgres ocasionalmente se queda corto en rendimiento con entornos de producción en vivo y "siempre activos". Una desventaja adicional con Postgres es el hecho de que su replicación se implementa a nivel del motor de almacenamiento. Esto lo hace más costoso que la replicación de MySQL, que es más madura e implementada en el "nivel del motor de consulta".
Introducción al motor Hasura GraphQL
Dado que hemos cubierto brevemente el desarrollo de API GraphQL y PostgreSQL, deberíamos tener suficiente contexto para una introducción al motor Hasura GraphQL. Básicamente, Hasura es simplemente un motor GraphQL para PostgreSQL RDBMS, que proporciona una forma simplificada de arranque y gestión del desarrollo de la API GraphQL. En retrospectiva, Hasura es actualmente la única solución disponible que agrega instantáneamente GraphQL-as-a-Service a las aplicaciones basadas en PostgreSQL existentes. Esencialmente, eludir la tarea que requiere mucho tiempo de escribir el código de back-end que procesa GraphQL.
Hasura simplificado
Tomemos un minuto para simplificar más Hasura. Básicamente, las API son interfaces que le permiten solicitar información (una consulta) y, por lo tanto, responder enviando datos JSON o XML. Esa base de datos normalmente se aloja y se obtiene de un servidor. Aquí es donde entra Hasura para simplificar las cosas. En retrospectiva, el motor Hasura GraphQL es un servidor que maneja sus consultas GraphQL sobre una base de datos de Postgres. Esto reduce efectivamente el tiempo que tarda su aplicación en estar lista para la producción, lo que le permite crear, ver y modificar tablas de su base de datos con facilidad con solo unos pocos clics. En consecuencia, esto permite a los desarrolladores de pila completa crear aplicaciones GraphQL escalables en PostgreSQL en un tiempo más corto. Esto ahorra a los desarrolladores semanas de codificación inicial y puede evitar que los errores problemáticos de fuga de datos lleguen a producción.
¿Qué problema está resolviendo Hasura en el desarrollo de API?
En general, Hasura simplifica la gestión del ciclo de vida de las API durante el uso de producción a gran escala, especialmente para las API complejas. Sobre todo, el motor GraphQL atrae a desarrolladores de pila completa que están atrasados con proyectos de desarrollo de API empresariales que utilizan bases de datos PostgreSQL existentes. Idealmente, dado que GraphQL permite ciclos de desarrollo de API ultrarrápidos, Hasura proporciona una forma simplificada para que las organizaciones se muevan gradualmente a GraphQL, sin afectar las aplicaciones, bases de datos o usuarios existentes. Además de su peso ligero y alto rendimiento, el motor viene con una interfaz de usuario de administración, lo que le permite explorar sus API de GraphQL y administrar el esquema y los datos de su base de datos de manera visual.
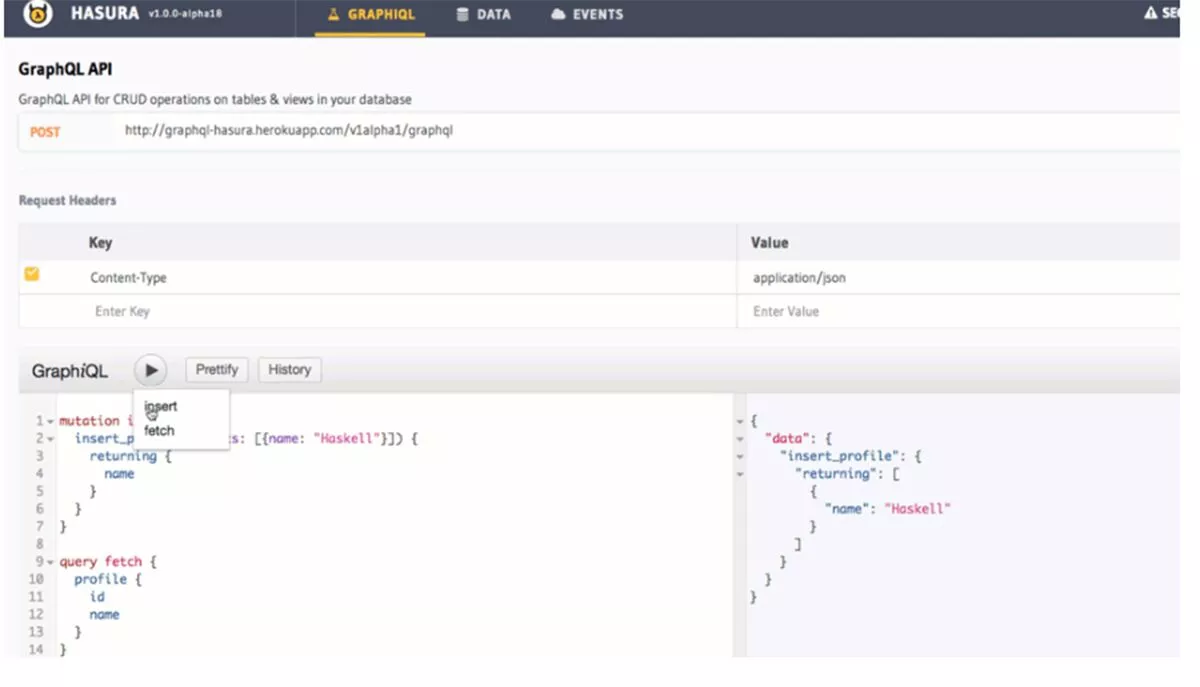
Ventajas de Hasura
En primer lugar, Hasura tiene un modelo sólido y estable para gestionar los cambios o “migraciones” de la base de datos. Esto es ventajoso ya que la gestión del esquema de la base de datos suele ser complicada. Por ejemplo, tareas como; seguimiento de cambios a lo largo del tiempo y asociación de cambios de esquema con mejoras de API (gestión de esquemas). Además, los trabajos de rutina, como el mantenimiento de scripts que pueden implementar una base de datos nueva o revertir cambios, pueden resultar tediosos y causar errores difíciles de diagnosticar o interrupciones. Como nota al margen positiva, los componentes de migración de la base de datos de Hasura son SQL simple, por lo tanto, portátiles fuera del conjunto de herramientas de Hasura. En general, Hasura tiene excelentes funciones de administración de esquemas y no necesita escribir código para manejar conexiones de socket web.
En segundo lugar, el motor Hasura GraphQL facilita la obtención de los datos necesarios con una sola consulta. Lo hace permitiéndole agregar vistas como relaciones a tablas u otras vistas. Además, permite escribir resoluciones personalizadas con unión de esquemas e integración de funciones sin servidor o API de microservicios que se activan en eventos de la base de datos. Esto puede resultar útil y facilita la creación de aplicaciones de 3 factores. De hecho, Hasura es un motor extremadamente ligero. En retrospectiva, consume solo hasta 50 MB de RAM incluso cuando atiende más de 1000 solicitudes por segundo. ¡Un brillante retorno de la inversión!
Específicamente, Hasura facilita aún más la autorización y autenticación detalladas de nivel de datos de API. Permite la conexión a un proveedor de autenticación preferido ya sea a través de webhook, JWT, Auth0 o implementaciones personalizadas. Y así, la especificación de roles para los usuarios, definiendo quién puede acceder a diferentes datos, por ejemplo, administrador, usuarios anónimos, etc. Generalmente, su sistema de control de acceso granular se basa en la estructura de la tabla de la base de datos similar al esquema GraphQL. Además, las reglas de permisos personalizadas se definen estrictamente en función de las operaciones y los valores de la base de datos.
Por último, Hasura admite brillantemente la paginación eficiente con un modelo de límite/compensación similar a SQL simple. Por ejemplo, utiliza el modelo de control de acceso para restringir el número de filas devueltas para una consulta determinada. Su modelo permite la sintonía de límites por rol. Por ejemplo, los usuarios que imponen una tasa de solicitud mucho más alta están limitados a límites de fila más pequeños. Esto evita estresar la base de datos y el motor GraphQL. Además, en particular, Hasura no lo restringe solo a GraphQL. Todavía puede ejecutar REST u otros microservicios que no sean de GraphQL en las tablas de Postgres que administra Hasura. Esto es posible con la combinación automática de esquemas de Hasura. Esto permite la fusión de un servicio GraphQL que no es de Hasura y un back-end para un único esquema unificado, que combina nuevas API administradas por Hasura con API y datos heredados.
Casos de uso de Hasura
Adecuado para entornos de alto rendimiento, Hasura Engine ofrece velocidad mientras automatiza la implementación de GraphQL-Postgres en las bases de datos existentes. En consecuencia, esto proporciona a las empresas que ya utilizan Postgres una forma menos estresante e incremental de pasar a GraphQL al vincular las tablas existentes en un "gráfico". Hasura se encarga de manera eficiente de la combinación de esquemas, lo que le permite aplicar fácilmente una lógica comercial personalizada. Con los esquemas remotos de GraphQL, Hasura se puede aprovechar como una puerta de enlace para la lógica comercial personalizada, lo que le permite escribir en los servidores de GraphQL en su idioma favorito y luego exponer los datos a un único punto final. Además, Hasura tiene una gran sintaxis para consultas y mutaciones con consultas en vivo integradas llamadas suscripciones en GraphQL.
Las pocas limitaciones de Hasura
Desafortunadamente, el modelo de sistema de control de acceso de Hasura no funcionará completamente para todas las aplicaciones. Por ejemplo, no es totalmente compatible con la autorización de acceso a la API a nivel de parámetros de entrada individuales. Sin mencionar el hecho de que está restringida a la base de datos Postgres que requiere migración en la mayoría de los casos. Aunque insignificantes, los mensajes de error que devuelve la API de GraphQL para solicitudes mal formadas son bastante hostiles en Hasura. De lo contrario, hay poco que Hasura no pueda hacer, como hemos visto en esta introducción a Hasura GraphQL Engine.
Conclusión
En conclusión, a medida que GraphQL crezca, simplificará aún más el desarrollo de API dentro de las empresas para construir a escala web. Con la adopción rápida a gran escala de GraphQL en un conjunto diverso de industrias, Hasura tiene el potencial de automatizar aún más la creación y administración de API con las tecnologías de elección estándar de la industria, GraphQL y Postgres. Hasura simplifica la creación de backends GraphQL CRUD (Crear, leer, actualizar y eliminar). Más importante aún, Hasura es, con mucho, la mejor y única opción si está comenzando desde cero con una API centrada en GraphQL y Postgres, sin escribir código de back-end. Para cualquier consulta o consulta sobre las posibilidades empresariales de GraphQL y Hasura, no dude en comunicarse con nosotros. Eso es todo para nuestra introducción a Hasura GraphQL Engine.