
Es Spark para Nosql
Publicado: 2023-02-05Spark es una poderosa herramienta para trabajar con datos, especialmente con grandes conjuntos de datos. Está diseñado para ser rápido y eficiente, y admite una variedad de formatos de datos, incluidas las bases de datos NoSQL . Las bases de datos NoSQL se están volviendo cada vez más populares, ya que son adecuadas para manejar grandes cantidades de datos. Spark puede ayudarlo a consultar y manipular datos NoSQL de manera eficiente.
Para trabajar de manera efectiva, es fundamental administrar las bases de datos de su aplicación utilizando Apache Spark y NoSQL ( Apache Cassandra y MongoDB). El objetivo de este blog es brindar sugerencias para desarrollar aplicaciones Apache Spark utilizando backends NoSQL. Es un parque temático y TCP/IP Spark tiene atracciones tanto en CassandraLand como en MongoLand. Cuando intentamos consultar los datos del DOE, nuestra aplicación Spark comenzó a salirse de su eje. La lección aquí es que cuando consulta a Cassandra, las secuencias de teclas son importantes. CassandraLand también ofrece la montaña rusa Partitioner, que es una de sus atracciones más populares. Mientras los clientes disfrutan de su paseo en la montaña rusa, los operadores del paseo pueden rastrear quién ha subido cada día guardando su información.
En la lección uno, repasaremos la gestión de las conexiones de MongoDB. Cuando necesite actualizar la información sobre un parque, como el estado de membresía del nuevo parque del Departamento de Energía, puede usar los índices de mongo . Se deben usar MongoDB y Spark para garantizar que su conexión se administre correctamente, así como índices en casos específicos.
Apache Spark es un sistema de procesamiento distribuido popular que es de código abierto y está diseñado para su uso en grandes cargas de trabajo de datos. Esta función, además del almacenamiento en caché en memoria y la ejecución optimizada de consultas, permite consultas analíticas rápidas contra grandes cantidades de datos.
Con casi el mismo código, es más eficiente y versátil, lo que le permite procesar datos por lotes y en tiempo real al mismo tiempo. Como resultado, las herramientas de Big Data más antiguas se están volviendo cada vez más obsoletas debido a la falta de esta funcionalidad.
¿Qué tipo de base de datos es Spark?
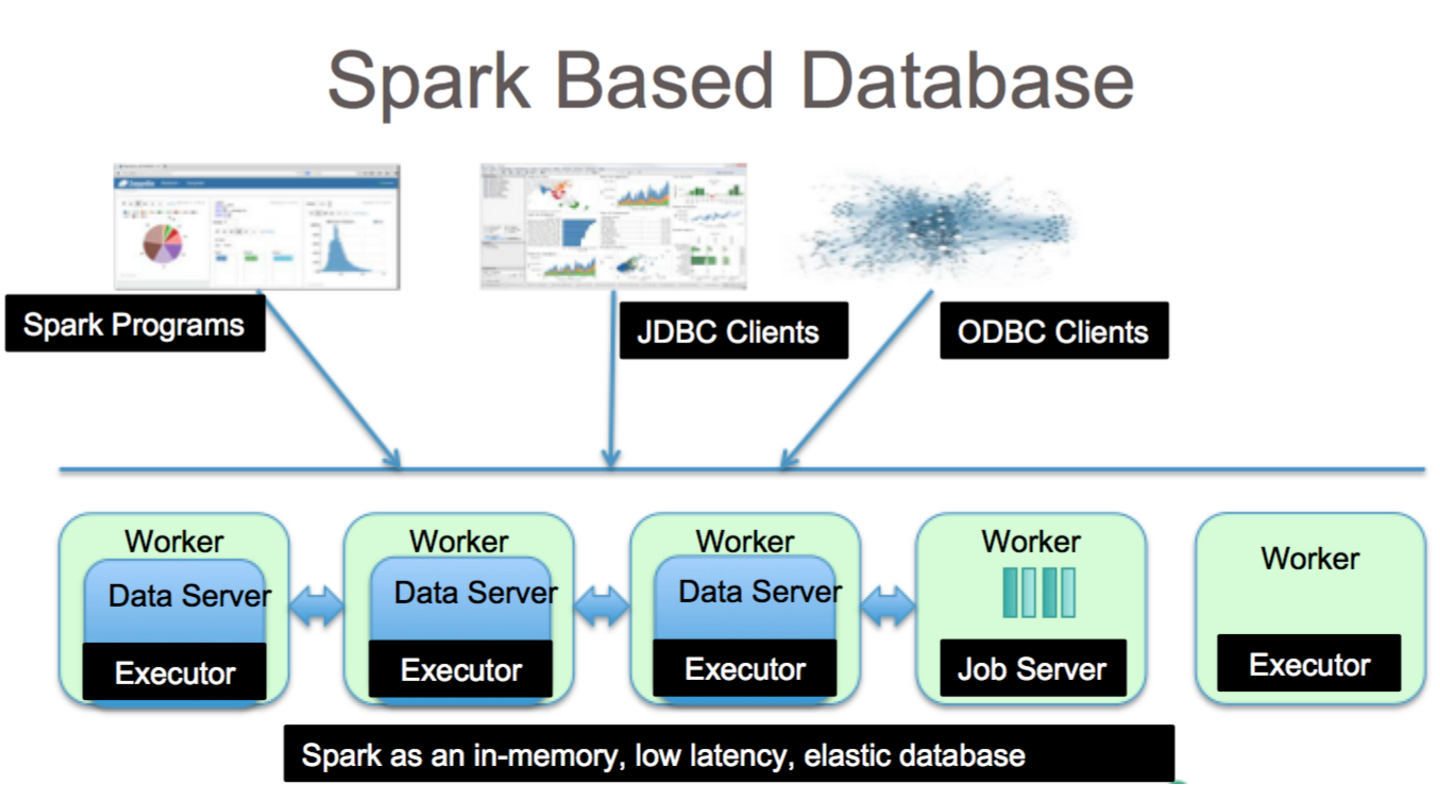
Apache Spark es un marco de procesamiento de datos que puede manejar datos de una variedad de repositorios de datos, incluidos (HDFS), bases de datos NoSQL y bases de datos relacionales.
Aunque ha habido numerosos ciclos de exageración para las bases de datos relacionales, seguirán siendo populares, independientemente de los últimos avances y el auge de las bases de datos NoSQL. Con el tiempo, se ha vuelto cada vez más difícil almacenar datos en bases de datos relacionales. En este artículo, veremos algunos de los avances significativos para aprovechar el poder de la base de datos relacional a escala global. Cuando se lanzó por primera vez, la interfaz entre Spark y Big Data Analysis era mínima. Muchas personas escribieron mucho código para ejecutar este programa, que era poderoso pero relativamente lento. Los usuarios podrán combinar estos dos modelos en la base de datos Spark SQL con facilidad. También acepta una amplia gama de formatos de datos de una variedad de fuentes.
El proyecto de código abierto Apache Spark es el más activo, con cientos de colaboradores contribuyendo. Además de ser un proyecto gratuito de código abierto, Spark SQL ha comenzado a ganar popularidad en las principales industrias. Además de Spark SQL, aproximadamente dos tercios de los clientes de Databricks Cloud (el servicio hospedado que ejecuta Spark) usan otros lenguajes de programación. Después de la conclusión de nuestro primer estudio de caso, demostraremos cómo aplicar databricks al caso en este estudio de caso práctico. Un Spark DataFrame es un conjunto de filas (tipos de fila) que se distribuyen con el mismo esquema. Cada columna del conjunto de datos está etiquetada con un nombre. La API de DataFrame permite a los desarrolladores integrar código procesal y relacional.

Spark también puede manejar funciones avanzadas como UDF. Una tabla en una base de datos relacional es análoga a un marco de datos en una base de datos de marcos de datos, pero hay más optimizaciones involucradas. Se pueden manipular de la misma manera que las colecciones distribuidas nativas (RDD) de Spark. En general, la consulta Spark SQL es más rápida que la consulta Shark y es más competitiva con Impulsa. En la Consulta 3a, donde la selectividad de la consulta hace que una de las tablas sea muy pequeña, hay una diferencia significativa entre Impala e Impala.
Es una herramienta fantástica para el análisis de datos con Spark SQL. Se puede acceder a la sintaxis de HiveQL, Hive SerDes y HiveDF a través de la sintaxis de HiveQL, así como a Hive SerDes y HiveDF. Ya se han implementado metastores de Hive , SerDes y UDF. A pesar de que Spark es una base de datos, también es una base de datos NoSQL. Como resultado, cuando crea una tabla administrada en Spark, podrá usar una variedad de herramientas compatibles con SQL para almacenar sus datos. Las expresiones SQL se pueden usar para acceder a tablas en Spark conectándose a JDBC a través de conectores de jdbc.org. Como resultado, también puede utilizar herramientas de terceros como Tableau, Talend y Power BI. La capacidad de usar Spark es ideal para el análisis de datos y es una herramienta útil para una amplia gama de industrias.
Spark Sql: lo mejor de ambos mundos
Cierra la brecha entre los dos modelos mencionados anteriormente, los modelos de procedimiento y relacional, al incluir dos componentes principales. Como resultado, puede ejecutar operaciones relacionales a gran escala en fuentes de datos externas y las colecciones distribuidas integradas de Spark mediante una API DataFrame.
¿Qué es chispa en la base de datos? Es un marco de código abierto que utiliza aprendizaje automático, procesamiento de consultas interactivo y cargas de trabajo en tiempo real. Esta empresa no cuenta con su propio sistema de almacenamiento; más bien, emplea análisis en otros sistemas de almacenamiento como HDFS, Amazon Redshift, Amazon S3, Couchbase y otros, además del suyo propio. Cuando se trata de procesamiento de datos estructurados, Spark SQL no es solo una base de datos; también es un módulo. La gran mayoría está escrita en DataFrames, que son las abstracciones de programación que funcionan junto con las consultas SQL.
¿Cuál es el tipo de SQL sql para "sparksql"? Hive SQL admite la sintaxis de HiveQL, así como Hive SerDes y UDF, lo que le permite acceder a los almacenes de Hive que se han creado previamente. El uso de metaalmacenes de Hive, SerDes y UDF existentes en Spark SQL no es difícil.
¿Mongodb puede ejecutar Spark?
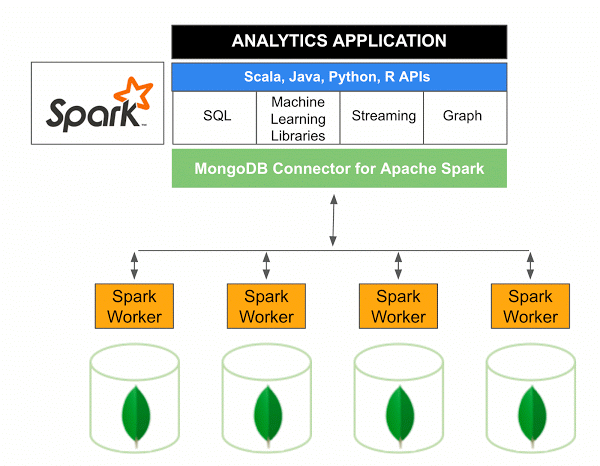
La versión 10.0 de MongoDB Connector para Apache Spark incluye compatibilidad con Spark Structured Streaming a través de la nueva Spark Data Sources API V2 , así como la implementación de la nueva Spark Data Sources API V2.
El conector MongoDB para Spark es un proyecto de código abierto que le permite escribir datos desde MongoDB y leerlos desde MongoDB usando Scala. Debido a los métodos de utilidad de los conectores, las interacciones entre Spark y MongoDB se simplifican, lo que lo convierte en una poderosa combinación para crear aplicaciones analíticas sofisticadas. Con sus funciones integradas de replicación y fragmentación, Spark se puede implementar en una variedad de cargas de trabajo que usan bases de datos MongoDB .
Spark: la forma rápida de crear aplicaciones ricas en datos
Con la ayuda de Spark, una poderosa herramienta, puede desarrollar rápidamente aplicaciones más funcionales. Al incorporar MongoDB, los desarrolladores pueden acelerar el proceso de desarrollo utilizando una única tecnología de base de datos. Además, Spark es nativo de la nube e incluye soporte para almacenes de datos NoSQL , lo que lo hace ideal para aplicaciones con uso intensivo de datos.