
MapReduce: un modelo de programación para grandes conjuntos de datos
Publicado: 2023-01-08MapReduce es un modelo de programación y una implementación asociada para procesar y generar grandes conjuntos de datos con un algoritmo distribuido paralelo en un clúster.
Estamos transformando la forma en que trabajamos con cantidades masivas de datos utilizando nuevas tecnologías. Los almacenes de datos, como Hadoop, NoSQL y Spark, son algunos de los jugadores más destacados en el campo. Los DBA y los ingenieros/desarrolladores de infraestructura se encuentran entre la nueva generación de profesionales que se especializan en administrar sistemas con un alto nivel de sofisticación. En lugar de una base de datos, Hadoop es un ecosistema de software que permite la computación paralela en forma de archivos masivos. Esta tecnología ha brindado beneficios significativos en términos de soporte de las necesidades de procesamiento masivo de big data. Para una transacción de datos de gran tamaño, el clúster de Hadoop promedio puede tardar solo tres minutos en procesar una transacción de gran tamaño que normalmente tardaría 20 horas en un sistema de base de datos relacional centralizado.
Un clúster mapreduce es un clúster con un algoritmo paralelo y un modelo de programación que procesa y genera grandes conjuntos de datos de la misma manera que un clúster normal.
El ecosistema Apache Hadoop está diseñado para admitir la computación distribuida y proporciona un entorno confiable, escalable y listo para usar. El módulo MapReduce de este proyecto es un modelo de programación utilizado para procesar grandes conjuntos de datos que residen en Hadoop (un sistema de archivos distribuido).
Este módulo es un componente del ecosistema de código abierto de Apache Hadoop y se utiliza para consultar y seleccionar datos en el sistema de archivos distribuidos de Hadoop (HDFS). Los datos se pueden seleccionar para una variedad de consultas utilizando un algoritmo MapReduce que está disponible para realizar dichas selecciones.
Usando MapReduce, es posible ejecutar grandes tareas de procesamiento de datos. Puede crear programas MapReduce en cualquier lenguaje de programación, incluidos C, Ruby, Java, Python y otros. Estos programas se pueden usar simultáneamente para ejecutar programas MapReduce, lo que los hace muy útiles en el análisis de datos a gran escala.
¿Para qué se utiliza Mapreduce en Mongodb?
Los mapas en MongoDB son un modelo de programación de procesamiento de datos que permite a los usuarios realizar grandes conjuntos de datos y generar resultados agregados a partir de ellos. MapReduce es el método utilizado por MongoDB para reducir mapas. Esta función se divide en dos componentes: una función de mapa y una función de reducción.
Usando la herramienta MapReduce de MongoDB, es posible organizar y agregar grandes conjuntos de datos. Este comando, en MongoDB, hace uso de las dos entradas principales en MongoDB: función de mapa y función de reducción, para procesar una gran cantidad de datos. Para definir ejemplos, siga los pasos a continuación. Definiremos la función map, la función reduce y los ejemplos.
MapReduce comparará cadenas para ordenar la salida utilizando el método de clasificación predeterminado, independientemente de si está utilizando el método predeterminado o no. Para cambiar la forma en que se ordenan los datos, primero debe crear un algoritmo de ordenación y luego implementarlo usando la clase mapper.
SpiderMonkey es un motor de JavaScript ampliamente utilizado. Es bueno para aplicaciones a pequeña escala, pero tiene algunas limitaciones. SpiderMonkey no tiene un algoritmo de clasificación, por ejemplo. Como resultado, si desea utilizar Mapmapper para clasificar los datos, primero debe crear su propio algoritmo de clasificación e implementarlo en la clase Reduce.
A pesar de su popularidad, SpiderMonkey no utiliza un algoritmo de clasificación. Hay otras limitaciones para SpiderMonkey, pero esta es notable. SpiderMonkey, por ejemplo, no tiene un buen recolector de basura, por lo que si su programa comienza a ralentizarse, es posible que deba tomar algunas medidas para hacerlo más rápido.
¿Por qué usar una función Mapreduce?
Una función MapReduce puede ser útil en una variedad de situaciones. Este método se puede utilizar para el procesamiento de datos por lotes en algunos casos. También es útil si necesita que una sola aplicación o proceso maneje una gran cantidad de datos. También se puede usar una función MapReduce para procesar datos que se distribuyen en varios nodos en un sistema distribuido. Al utilizar la función MapReduce, los datos de los nodos se pueden combinar en una sola salida. Una aplicación MapReduce normalmente se usa para procesar grandes cantidades de datos, aunque puede ser necesaria para manejar cantidades muy grandes.
¿Por qué se llama Mapreduce?
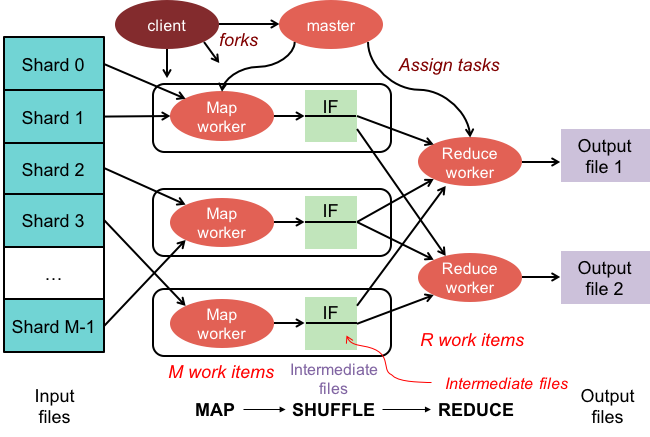
Hay algunas teorías sobre por qué se llama MapReduce. Una es que es un juego de palabras, ya que los algoritmos de reducción de mapa implican dividir un problema en partes más pequeñas (mapeo), luego resolver esas partes y volver a juntarlas (reducir). Otra teoría es que es una referencia a un documento escrito por empleados de Google en 2004 llamado "MapReduce: Procesamiento de datos simplificado en grandes clústeres". En el documento, los autores utilizan los términos "mapear" y "reducir" para describir las dos fases principales de su modelo de procesamiento propuesto.
Sin embargo, es importante tener en cuenta que el modelo MapReduce solo se usa de forma limitada. No es adecuado para grandes conjuntos de datos y se debe paralelizar para que funcione correctamente. Cuando se trata de abordar estos problemas, Apache Spark tiene una poderosa alternativa a MapReduce. El sistema informático de clúster Spark se basa en Hadoop y funciona como una plataforma informática de propósito general. Esta herramienta se puede utilizar para acelerar las tareas tradicionales de análisis de datos, como la extracción de datos y el aprendizaje automático, así como tareas de procesamiento de datos más complejas, como el almacenamiento de datos y el análisis de big data. Este software está construido usando Erlang, un lenguaje de programación que es escalable y tolerante a fallas. Puede manejar grandes cantidades de datos y puede ejecutarse en varias máquinas al mismo tiempo. Además, Spark emplea el paralelismo, lo que permite que varios nodos realicen la misma tarea al mismo tiempo. En general, tiene el potencial de automatizar tareas de análisis de datos a gran escala y hacerlas más escalables. Si necesita paralelizar su procesamiento y manejar grandes conjuntos de datos, es una excelente alternativa a MapReduce.
¿Cuál es la diferencia entre Mapreduce y la agregación?
Cuando se trabaja con Big Data, mapreduce es un método importante para extraer datos de una gran cantidad de datos. MongoDB 2.2, a partir de ahora, incluye el nuevo marco de agregación. En términos de funcionalidad, la agregación es similar a mapreduce, pero en el papel parece ser más rápida.
En este escenario, MongoDB Aggregation y MapReduce se ejecutan en contenedores Docker en una configuración Sharded. El rendimiento de la canalización del agregador es superior al de mapreduce porque permite una navegación más rápida y sencilla. Así es como funciona el problema: tweet cuenta pronombres suecos como "den", "denne", "denna", "det", "han", "hon" y "hen" (distingue entre mayúsculas y minúsculas) en un hashtag de Twitter. ¿Cuántos identificadores de Twitter tiene un usuario? Se han enviado más de 4 millones de tuits. En este experimento, primero crearemos una base de datos MongoDB y habilitaremos la fragmentación. Las transmisiones de Twitter se importaron a la base de datos y se ejecutaron consultas mediante MapReduce y Aggregation Pipeline.
Mapreduce: la herramienta definitiva de agregación de datos
Un programa mapReduce lee una lista de documentos de una colección y los procesa utilizando un conjunto de funciones predefinidas. La operación mapReduce genera un flujo de documentos listos para procesar que se procesarán en la etapa de reducción. Es posible combinar mapsreduce y aggregation en una variedad de situaciones. El operador de agregación $group es una herramienta que se puede utilizar para agrupar documentos en un solo campo. Cuando se combinan varios documentos con el operador de agregación $merge, se puede crear un nuevo documento. El operador de agregación $accumulator se puede usar para representar los resultados de múltiples operaciones de reducción de mapas en un solo documento.
Mapreducir en Mongodb
Mongodb mapreduce es una tecnología de procesamiento de datos para grandes conjuntos de datos. Es una poderosa herramienta para analizar datos y proporciona una forma de procesar y agregar datos de manera paralela y distribuida. MapReduce se ha utilizado ampliamente para el análisis de datos en una variedad de dominios, incluido el análisis del tráfico web, el análisis de registros y el análisis de redes sociales.

Al usar el comando mapReduce , puede ejecutar operaciones de agregación map-reduce en una colección. La función de mapa puede convertir cualquier documento en cero o en muchos otros. En las versiones de MongoDB que van desde la 4.2 hasta las anteriores, cada emisión puede contener solo la mitad del tamaño máximo del documento BSON. El código JavaScript de tipo BSON en desuso que se usa en MapReduce ya no es compatible y el código ya no se puede usar para sus funciones. MongoDB 4.4 ya no incluye el código JavaScript obsoleto de tipo BSON con alcance (BSON tipo 15). El parámetro scope especifica a qué variables puede acceder la función reduce. Para reducir las entradas, MongoDB limita el tamaño del documento BSON a la mitad de su tamaño máximo.
Los documentos grandes devueltos al servidor pueden devolverse y luego fusionarse en reducciones posteriores, lo que podría incumplir el requisito. MongoDB 4.2 es la versión más reciente. Esta opción se puede usar para crear una nueva colección fragmentada, así como map-reduce para crear una nueva colección con el mismo nombre de colección. La función finalizar recibe como argumentos un valor clave y el valor reducido de la función reduce. Hay tres opciones para configurar el parámetro de salida. Esta opción, además de crear una nueva colección, no funciona en miembros secundarios de conjuntos de réplicas. NonAtomic: la opción falsa solo se puede proporcionar si la colección que ya existe para pasar tiene la especificación explícita.
El uso de la función de reducción en los resultados del documento nuevo y existente si la clave en el nuevo documento es la misma que la clave en el documento existente. Map-reduce no funciona cuando el nombre de la colección es una colección no protegida existente que se ha configurado. En este caso, se impide que MongoDB bloquee su base de datos si nonAtomic es verdadero. Solo los miembros secundarios de los conjuntos de réplicas que usan esta opción pueden estar fuera del conjunto. No se requieren funciones personalizadas para reescribir la operación de reducción de mapa. El cust_id se utiliza para calcular el campo de valor del grupo $group stage mediante el método cust_id. La etapa $merge combina los resultados de la etapa $merge en la colección de salida mediante los operadores de canalización de agregación disponibles.
Como ejemplo, la etapa $out se puede usar para escribir la salida de la colección agg_alternative_1. Cada documento de entrada se puede procesar con la función de mapa. Cada artículo en el pedido está asociado con un nuevo valor de objeto que contiene tanto el recuento de 1 como la cantidad del artículo en el pedido. En reduceVal, el campo de conteo representa la suma de los campos de conteo generados por los elementos de la matriz. Si la función de finalización modifica el objeto de valor reducido para incluir un campo calculado denominado avg, el objeto modificado se devuelve al usuario. La etapa $unwind divide el documento en un documento para cada elemento de la matriz utilizando el campo de la matriz de elementos. La etapa $project remodela el documento de salida para reflejar la salida de mapreduce al incluir dos campos: id y valor.
Se sobrescribe el documento existente si no existe ningún documento existente con la misma clave que el nuevo resultado. Si especifica el parámetro out, mapReduce devuelve un documento como salida en el siguiente formato si desea escribir resultados en una colección. Se devuelve una matriz de documentos resultantes si la salida se escribe en línea. Cada documento contiene dos campos: el nombre del documento fuente y el nombre del documento receptor. Cuando el valor de la clave se ingresa en el campo -id, se crea un campo de valor para reducir o finalizar los valores de la clave.
¿Qué es emitir en Mongodb?
Como función de mapa, la función de mapa puede llamar a emits (clave, valor) en cualquier momento para generar un documento de salida que incluya la clave y el valor. Una sola emisión en MongoDB 4.2 y versiones anteriores solo puede contener la mitad del tamaño máximo de los archivos BSON de MongoDB. A partir de la versión 4.4 de MongoDB, se elimina la restricción.
Por qué Mongodb es la mejor opción para datos flexibles y escalables
Debido a la falta de un esquema rígido, MongoDB se asocia frecuentemente con NoSQL. Debido a su falta de esquema rígido, los datos se pueden almacenar en cualquier formato que sea conveniente para la aplicación. La flexibilidad de la base de datos brinda una ventaja importante cuando se amplía o reduce, ya que significa que los datos se pueden almacenar de una manera que se adapta a las necesidades de la aplicación.
Se puede usar un diagrama de datos con diagramas ER para visualizar las relaciones entre varios datos. El diagrama ER representa una serie de nodos que representan una colección de datos y las conexiones entre ellos sirven como un identificador.
Las relaciones no se aplican en MongoDB porque no es una base de datos relacional. El diagrama ER representa las relaciones que existen dentro de los datos y también ayuda a visualizarlas.
MongoDB es una excelente opción para datos que son flexibles y escalables. Su flexibilidad le permite almacenar datos de una manera que tenga sentido para una aplicación, y su escalabilidad le permite manejar grandes conjuntos de datos de forma rápida y sencilla.
Ejemplo de Map-reduce Mongodb
En MongoDB, map-reduce es un paradigma de procesamiento de datos para agregar datos de colecciones. Es similar a las funciones map y reduce en la programación funcional.
Las operaciones de reducción de mapa tienen dos fases:
1. La fase de mapa aplica una función de mapeo a cada documento de la colección. La función de mapeo emite uno o más objetos para cada documento de entrada.
2. La fase de reducción aplica una función de reducción a los documentos emitidos por la fase de mapa. La función reduce agrega los objetos y produce un solo objeto como salida.
Por ejemplo, considere una colección de artículos. Podemos usar map-reduce para calcular el número de palabras en cada artículo.
Primero, definimos una función de mapeo que emite un par clave-valor para cada documento, donde la clave es la identificación del artículo y el valor es la cantidad de palabras en el artículo.
A continuación, definimos una función de reducción que suma los valores de cada tecla.
Finalmente, ejecutamos la operación map-reduce en la colección. El resultado es un documento que contiene los datos agregados.
En Mongosh, hay una base de datos. El método mapReduce() es un contenedor alrededor del comando mapReduce. En esta sección se proporcionan varios ejemplos, como una alternativa de canalización de agregación sin una expresión de agregación personalizada. Los mapas se pueden traducir con expresiones personalizadas mediante Map-Reduce to Aggregation Pipeline Translation Examples. La operación de reducción de mapa se puede cambiar sin tener que definir funciones personalizadas mediante los operadores de canalización de agregación disponibles. La función de mapa se puede utilizar para procesar cada documento en la entrada. Cada artículo tiene su propio valor de objeto asociado con un nuevo valor que contiene el número 1, el número de cantidad del pedido y una lista de artículos.
Si la clave en el documento actual es la misma que la clave en el nuevo documento, la operación sobrescribe ese documento. Puede reescribir la operación de reducción de mapa utilizando operadores de canalización de agregación en lugar de definir funciones personalizadas. La etapa $unwind desglosa el documento por el campo de la matriz de elementos, lo que da como resultado un documento para cada elemento de la matriz. Cuando la etapa $project remodela el documento de salida, se refleja la salida map-reduce. Una operación sobrescribe un documento existente que tiene la misma clave que el nuevo resultado.
¿Qué es la función Mapper en Hadoop?
Como reductor, debe combinar los datos de los mapeadores para generar una respuesta unificada. La salida reducida se produce cuando se acepta como entrada un conjunto de salidas de mapa, cada una de las cuales representa un subconjunto del resultado generado.
Los mapeadores se utilizan para dividir los datos en fragmentos manejables y luego asignar cada fragmento a una tarea en función de su tamaño. Los datos de entrada son recibidos por la función mapper, donde hay parámetros que indican la tarea a realizar.
Una serie de elementos corresponde a los fragmentos de datos que el mapeador ha mapeado en la salida. Como resultado, la salida del mapa se reenvía al reductor, que la convierte en una salida de reducción.
Los errores también son manejados por la función de mapeador. Un mapeador devolverá una salida de error en este caso, que no es una salida de mapa. Debido a que el reductor no puede procesar estos datos, el mapeador devolverá un mensaje de error.
Ecosistema Hadoop
El ecosistema Hadoop es una plataforma para procesar y almacenar grandes datos. Consta de una serie de componentes, cada uno de los cuales tiene un papel específico que desempeñar en el procesamiento y almacenamiento de datos. Los componentes más importantes del ecosistema son el sistema de archivos distribuidos de Hadoop (HDFS), el marco MapReduce y la biblioteca común de Hadoop .