
Master-Slave Vs Multi-Master Replication en bases de datos NoSQL
Publicado: 2023-01-13Hay muchos tipos diferentes de replicación que son compatibles con las bases de datos NoSQL. El tipo de replicación más común es la replicación Maestro- Esclavo . En este tipo de replicación, hay un servidor maestro que contiene todos los datos. Los servidores esclavos luego replican los datos del servidor maestro. Este tipo de replicación es muy simple y fácil de configurar. También es muy eficiente y proporciona un buen rendimiento. Otro tipo de replicación compatible con las bases de datos NoSQL es la replicación multimaestro. En este tipo de replicación, hay varios servidores maestros. cada servidor maestro tiene una copia de los datos. Luego, los servidores esclavos replican los datos de todos los servidores maestros. Este tipo de replicación es más complejo de configurar pero proporciona un mejor rendimiento y es más tolerante a fallas.
Además de la replicación de datos NoSQL, proporciona una característica robusta que le permite copiar y almacenar sus datos estructurados, no estructurados y semiestructurados en caso de un bloqueo del servidor. Descubra cómo utilizar bases de datos NoSQL en un sencillo proceso paso a paso.
Replicación de datos: debido a que los datos se replican de un servidor a otro, cada bit de datos se puede encontrar en varios servidores. Un proceso de replicación se divide en dos etapas: replicación maestro-esclavo y replicación consciente de esclavo. La replicación maestro-esclavo asigna a un nodo la autoridad para manejar las escrituras, mientras que la replicación compatible con esclavos permite que los esclavos lean y se sincronicen con el maestro.
MySQL incluye replicación asíncrona unidireccional, en la que un servidor actúa como fuente y otro sirve como réplica.
El factor de replicación (RF), como su nombre lo indica, es la cantidad de nodos en los que se replican los datos (filas y particiones). Múltiples nodos (RF=N) están conectados para transmitir datos. El RF de uno indica que solo hay una copia de una fila en un clúster y que no hay forma de recuperar los datos si el nodo falla o se ve comprometido.
¿Qué es fragmentación y replicación en Nosql?
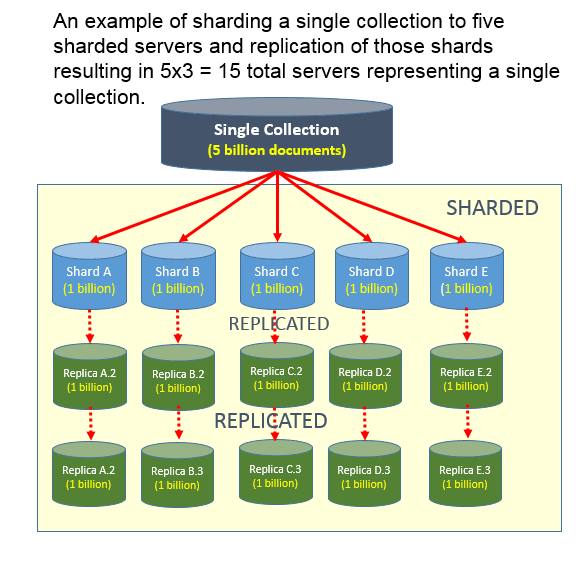
¿Cuál es la diferencia entre fragmentación y replicación? La replicación de datos ocurre cuando un nodo de servidor principal y un nodo de servidor secundario intercambian datos. Como respaldo en caso de falla del servidor principal, esto puede ayudar a aumentar la disponibilidad de los datos. La capacidad de escalar horizontalmente entre servidores se basa en el uso de una clave fragmentada.
Las bases de datos SQL le permiten dividir un conjunto de datos en tablas y luego crear una partición para cada tabla. Una base de datos NoSQL , como MongoDB, no tiene tablas sino una colección de documentos. El comando mongo shard se utiliza para fragmentar colecciones de MongoDB. Puede distribuir la carga entre varios servidores en un único entorno de fragmentación, lo que mejora el rendimiento. Cuando se trata de grandes conjuntos de datos, esto es especialmente cierto. Además, la fragmentación puede ayudar a administrar y proteger grandes conjuntos de datos al proporcionar integridad de datos. Además de escalar sus datos, Sharding es una herramienta fantástica para administrarlos de manera efectiva. Este patrón es ampliamente utilizado en bases de datos NoSQL debido a su facilidad de implementación y amplio soporte.
Por qué la fragmentación es mejor para la escritura de datos
En general, la replicación permite escalar horizontalmente las lecturas, pero no permite escalar datos en varios servidores con una sola clave, mientras que la fragmentación sí lo hace.
¿Qué tipo de datos admite Nosql?
Las bases de datos NoSQL son cada vez más populares porque admiten una amplia gama de tipos de datos. Esto incluye tipos de datos tradicionales, como números y cadenas, así como tipos de datos más nuevos, como JSON y XML. Las bases de datos NoSQL también admiten una amplia gama de lenguajes de programación, lo que las convierte en una buena opción para las empresas que utilizan varios lenguajes.
En una base de datos NoSQL, hay cuatro tipos: pares clave-valor, columnas, gráficos y documentos. Cada categoría tiene su propio conjunto de características y limitaciones. La base de datos MongoDB es una base de datos NoSQL popular . Esta es una base de datos de pares clave-valor que almacena ambos pares. Esta aplicación es fácil de usar, escalable y rápida. Las bases de datos orientadas a documentos son el foco de CouchDB. Esta aplicación es simple de usar y lo suficientemente flexible para adaptarse a múltiples usuarios. La base de datos CouchBase está orientada a columnas y se centra en las transacciones. La base de datos de Cassandra se basa en una arquitectura altamente orientada a columnas. El sistema de almacenamiento HBase es una solución de almacenamiento escalable, distribuida y a escala de petabytes para grandes conjuntos de datos. Es una base de datos de memoria distribuida que se ejecuta en Redis. Con Riak como almacén de datos, puede crear un sistema de alto rendimiento de código abierto. Neo4J, como base de datos de gráficos, se basa en una plataforma Java.
Por qué Nosql es la mejor opción para las empresas que necesitan escalar rápidamente
Para las empresas que necesitan escalar rápidamente, NoSQL es una buena opción porque tiene una arquitectura más flexible y se puede escalar horizontalmente. Además, las bases de datos NoSQL no son tan sensibles a los cambios de esquema como las bases de datos relacionales tradicionales.
La replicación de datos Nosql es
La replicación de datos Nosql es un proceso de copia de datos de una base de datos Nosql a otra base de datos Nosql. Esto se hace para mantener los datos seguros y garantizar que siempre estén disponibles en caso de falla.
Nosql vs. Rdbms: ¿Cuál es mejor para el rendimiento?
Hay un creciente cuerpo de investigación que muestra que las bases de datos NoSQL, como MongoDB, superan a los RDBMS tradicionales. La tecnología permite fragmentar y replicar los datos, lo que la hace ideal para aplicaciones que requieren un alto rendimiento y un acceso rápido a los datos. Aunque a veces los datos se pueden replicar, no siempre es posible.
Replicación maestro-esclavo en Nosql
La replicación maestro-esclavo es un tipo de replicación donde los datos se copian desde un servidor principal ("maestro") a uno o más servidores secundarios ("esclavo"). Los servidores esclavos se pueden usar para operaciones de lectura, pero todas las operaciones de escritura deben enviarse al maestro. Este tipo de replicación se usa a menudo en las bases de datos Nosql, ya que puede proporcionar una alta disponibilidad y escalabilidad. Por ejemplo, si el servidor maestro deja de funcionar, los esclavos aún se pueden usar para atender solicitudes de lectura. Y, si se necesita más capacidad de lectura, se pueden agregar servidores esclavos adicionales.
Los desafíos de la replicación maestro-esclavo
Puede ser difícil mantener datos en todos los nodos esclavos en el modelo de replicación maestro-esclavo. Si uno de los nodos esclavos deja de funcionar, los datos de ese nodo esclavo se perderán.
¿Qué modelo de replicación admite operaciones de lectura y escritura de bases de datos en todos los nodos?
El modelo de replicación que soporta las operaciones de lectura y escritura de la base de datos en todos los nodos es el modelo de replicación Maestro-Maestro . Este modelo permite que cada nodo actúe como maestro, lo que significa que cada nodo puede leer y escribir en la base de datos. Esto es beneficioso para las organizaciones que necesitan alta disponibilidad y redundancia, ya que todos los nodos pueden seguir funcionando incluso si uno de ellos deja de funcionar.

¿Qué modelo de aplicación admite operaciones de lectura y escritura de bases de datos en todas las notas?
Los RDBMS generalmente usan un modelo de esquema en escritura, en el que una estructura de datos se define con anticipación y todas las operaciones de lectura y escritura dependen de esa estructura.
Los cambios y actualizaciones de la base de datos pueden ocurrir en el modo de lectura y escritura
Los cambios y las actualizaciones pueden ocurrir en el modo de lectura/escritura cuando la base de datos se abre en el modo de lectura/escritura, que está controlado por OpenReadWrite() o OpenWrite. DatabaseReader es una clase que se puede usar para leer y escribir datos en una base de datos. Los datos se pueden escribir en una base de datos mediante el objeto DatabaseWriter.
¿Qué tipo de base de datos admite nodos que están conectados por relaciones?
Las relaciones se pueden almacenar y acceder en bases de datos de gráficos mediante relaciones estructuradas. Las relaciones son los aspectos más valiosos de las bases de datos de gráficos porque son algunos de los ciudadanos más valiosos. Los nodos se usan en bases de datos de gráficos para almacenar entidades de datos y los bordes se usan para conectar entidades.
Mongodb y Node.js: la combinación perfecta para trabajar con gráficos en Javascript
Si desea usar gráficos en JavaScript, debe usar MongoDB. MongoDB es la base de datos NoSQL más popular, mientras que Node.js también es un lenguaje de programación JavaScript popular.
¿Cómo funciona la replicación de bases de datos no relacionales?
En una instancia de replicación de datos NoSQL punto a punto, los datos se replican de una base de datos a otra según el concepto de que cada copia debe mantener su propia copia actualizada. La única vez que esto puede funcionar es si cada copia del esquema almacena el mismo tipo de datos en el mismo formato. El otro aspecto crítico de este método de replicación de datos es la restauración de la base de datos.
Los diferentes tipos de replicación
*br *Replicación de almacenamiento *br Es un tipo de replicación que almacena los cambios de datos de manera consistente. Un servidor de réplica de origen crea una instantánea de la base de datos con información de estado actual después de crear una. Luego, la instantánea se envía al servidor de réplica de destino. Después de la instantánea, el servidor de réplica de destino construye una nueva copia de la base de datos. Hacer referencia a la replicación transaccional en los datos Las transacciones se almacenan en datos que cambian con frecuencia y se pueden replicar mediante la replicación transaccional. Una transacción se procesa por lotes y se replica en un solo lote. Los cambios en los datos se replican mediante un proceso conocido como replicación. La replicación punto a punto se puede lograr mediante el uso de servidores. La replicación de datos punto a punto es un tipo de replicación de datos que pretende replicar datos que no se modifican con frecuencia. En la replicación de datos punto a punto, un grupo de nodos replica los datos. Cada nodo en un clúster tiene su propio modelo de datos. Los nodos del clúster no se reconocen entre sí.
Replicación de base de datos de documentos Nosql
Las bases de datos de documentos Nosql están diseñadas para proporcionar alta disponibilidad y escalabilidad mediante la replicación de datos en varios servidores. Esto permite que la base de datos continúe funcionando incluso si uno o más servidores fallan.
Gran base de datos Nosql
No hay una respuesta definitiva a esta pregunta, ya que depende de las necesidades específicas del usuario. Sin embargo, algunas de las grandes bases de datos nosql más populares incluyen MongoDB, Cassandra y Hadoop. Todas estas bases de datos están diseñadas para proporcionar escalabilidad y alto rendimiento, lo que las hace ideales para el procesamiento de datos a gran escala.
Una base de datos NoSQL como MongoDB, por ejemplo, es ideal para big data porque puede manejar grandes cantidades de datos de forma rápida y sencilla. Debido a que MongoDB es un MongoDB orientado a documentos, puede manejar enormes cantidades de datos. En otras palabras, MongoDB puede manejar datos en una variedad de formatos, incluidos JSON, BSON y JavaScript Object Notation (JSON). También hace que los datos sean fáciles de acceder y almacenar. Además, MongoDB es escalable, lo que significa que puede procesar grandes cantidades de datos.
¿Qué base de datos Nosql es mejor para Big Data?
Crean los formatos que las herramientas de análisis pueden usar para convertir datos no estructurados y semiestructurados en formatos que pueden usarse en sus aplicaciones. Los requisitos únicos para almacenar big data hacen que las bases de datos NoSQL (no relacionales) como MongoDB sean una excelente opción.
Por qué Mongodb es la mejor opción para almacenar Big Data
MongoDB es una excelente opción para almacenar y administrar grandes cantidades de datos. Las operaciones CRUD (crear, leer, actualizar, eliminar), el marco de agregación, la búsqueda de texto y la función Map-Reduce facilitan a los usuarios el acceso, la manipulación y el análisis de los datos.
¿Es el Big Data Nosql?
Si sus cargas de trabajo de datos están más enfocadas en el procesamiento y análisis rápidos de grandes volúmenes de datos variados y no estructurados, como Big Data, NoSQL es una mejor opción. Las bases de datos NoSQL no tienen las mismas restricciones en los tipos de datos que las bases de datos relacionales.
Por qué las bases de datos Nosql son el futuro de la gestión de datos
La base de datos NoSQL se está volviendo cada vez más popular como resultado de sus importantes ventajas de rendimiento sobre las bases de datos relacionales tradicionales. Es un habilitador de base de datos NoSQL que habilita ciertos tipos de bases de datos NoSQL, como HBase, lo que permite que los datos se distribuyan en miles de servidores sin reducir el rendimiento. La plataforma en la nube de Google (GCP) proporciona un conjunto diverso de servicios de base de datos, que son únicos en su capacidad para procesar conjuntos de datos dinámicos muy grandes sin necesidad de un esquema.
¿Las grandes empresas utilizan Nosql?
Tecnología de base de datos basada en Cloud Computing, Web, Big Data y Big Users. Al ofrecer NoSQL como alternativa al RDBMS tradicional, NoSQL se ha convertido en una opción viable para muchas empresas de Internet populares como LinkedIn, Google, Amazon y Facebook.
¿Es Nosql el futuro de las bases de datos internas de Instagram?
En este punto, parece que Instagram prefiere PostgreSQL como base de datos principal como backend principal, aunque esto puede cambiar. Cassandra, una base de datos NoSQL popular, puede o no ser la mejor opción para Instagram. Cassandra es una herramienta excelente para almacenar grandes cantidades de datos, pero tiene un historial de rendimiento deficiente.
Por el momento, es difícil predecir si Instagram usará o no bases de datos NoSQL como su base de datos principal. PostgreSQL y Cassandra son excelentes opciones, pero no pueden competir con SQL en términos de rendimiento.