
Base de datos NoSQL: Impala
Publicado: 2023-03-03NoSQL es un término utilizado para describir una base de datos que no utiliza la estructura de base de datos relacional tradicional. En cambio, las bases de datos NoSQL a menudo están diseñadas para proporcionar una solución más simple y escalable.
Impala es una base de datos NoSQL que fue diseñada para proporcionar una solución rápida y escalable para administrar grandes conjuntos de datos. Impala se basa en el modelo de datos de Google Bigtable y utiliza un formato de almacenamiento en columnas. Impala está disponible como proyecto de código abierto y cuenta con el respaldo de Cloudera.
Apache Impala es un motor de consulta SQL de código abierto que se instala en un clúster de Hadoop y realiza un procesamiento paralelo masivo (MPP) para los datos almacenados en el sistema. Desarrollado originalmente en 2012, el proyecto de código abierto se conoce como "Microsoft Formula 1".
La plataforma Impala permite a los usuarios realizar consultas SQL de baja latencia a los datos de Hadoop almacenados en HDFS y Apache HBase sin tener que mover o transformar los datos.
¿Está basado Impala Sql?
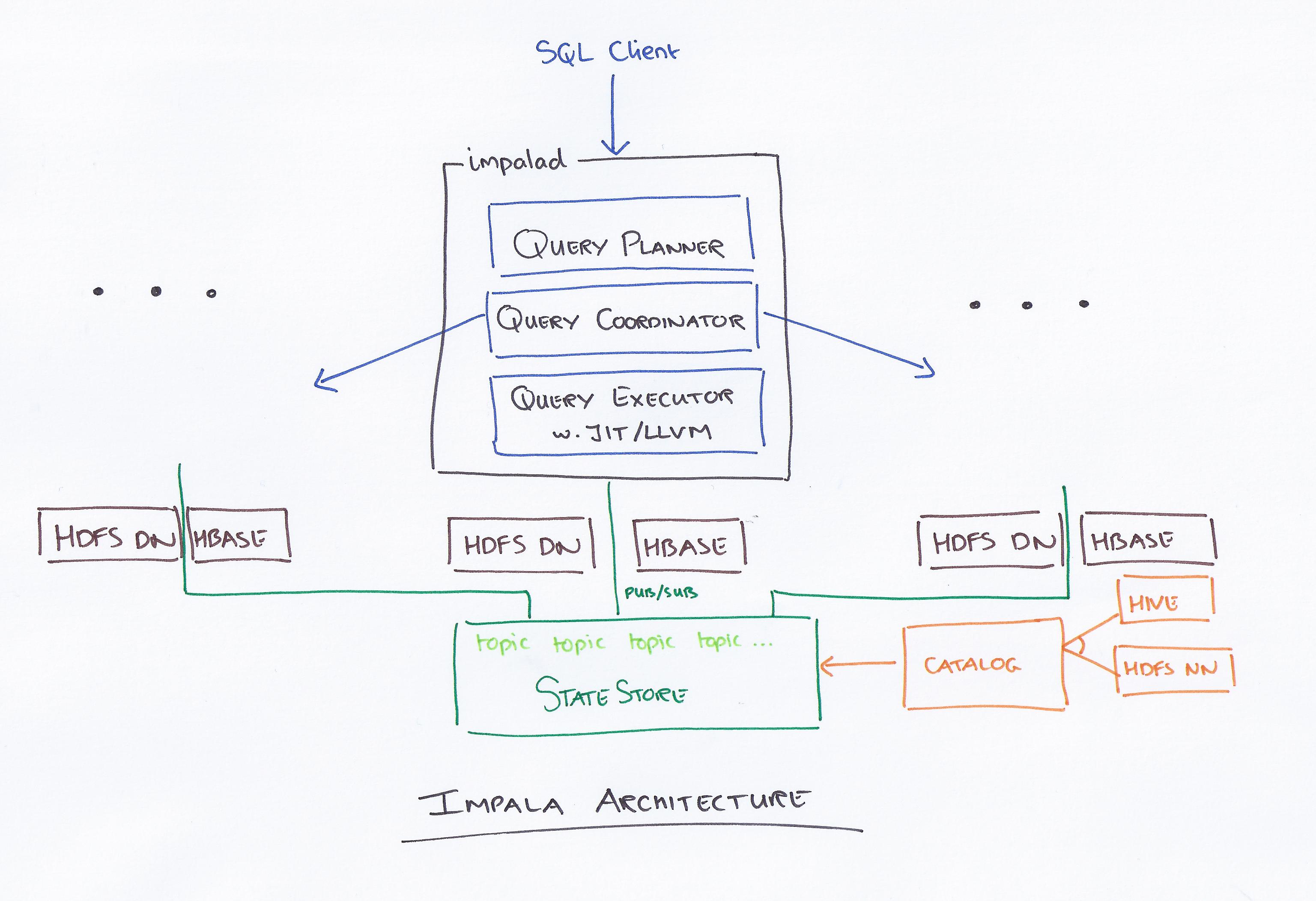
Impala es un motor de consulta basado en SQL que se ejecuta en Apache Hadoop. Permite a los usuarios consultar datos almacenados en HDFS y HBase usando SQL. Impala ofrece alto rendimiento y baja latencia en comparación con otros motores de consulta de Hadoop , como Hive y Pig.
La base de datos MPP analítica de Impala proporciona el tiempo de conocimiento más rápido de la industria. Está integrado con CDH y se puede acceder a través de Cloudera Enterprise. Las bases de datos MPP para Apache Hadoop, como Impala, usan HDFS para proporcionar un tiempo de conocimiento más rápido.
Impala es una base de datos
Es una base de datos que creo.
¿Es Impala una herramienta Etl?
Impala no es una herramienta ETL, es un motor de consulta SQL que se puede usar para realizar consultas SQL después de que los datos se hayan limpiado a través de un proceso.
¿Para qué se utiliza Apache Impala?
Usando consultas similares a SQL, podemos leer datos de una variedad de fuentes usando Impala. Apache Impala funciona mejor que Hive y otros motores SQL cuando se trata de acceder a los datos almacenados en el sistema de archivos distribuidos de Hadoop . Usamos Impala para almacenar datos en Hadoop HBase, HDFS y Amazon S3.
19 empresas que usan Apache Impala en sus paquetes tecnológicos
Apache Impala es un motor de procesamiento de datos popular para una variedad de grandes empresas. Según los informes, 19 empresas de tecnología, incluidas Stripe, Agoda y Expedia.com, utilizan Apache Impala. La plataforma Impala es flexible y eficiente, capaz de manejar grandes conjuntos de datos de manera rápida y efectiva. El uso generalizado de esta herramienta demuestra cuán útil es y cuán útil es en el procesamiento de datos.
¿Cuáles son las diferencias entre Sql Hive e Impala?
El objetivo de Hive es manejar consultas de ejecución prolongada que requieren múltiples transformaciones y uniones. Debido a su baja latencia y capacidad para manejar consultas más pequeñas, el motor de procesamiento de consultas de Impala es ideal para la computación interactiva. Spark admite consultas a corto y largo plazo, además de consultas a corto y largo plazo.
Hive es más adecuado para trabajos por lotes de larga duración
El propósito principal de las herramientas no es procesar lotes. Hive se adapta mejor al trabajo por lotes a largo plazo que Impulsa, que puede manejar conjuntos de datos más pequeños.
¿Es Impala una base de datos?
Un impala es una base de datos que almacena datos en formato de columnas. Está diseñado para ser escalable y proporcionar un alto rendimiento para grandes conjuntos de datos.
En la versión inicial de Impala, se admiten los siguientes tipos de datos de columnas principales: STRING, VARCHAR, VARCHar2, INT y FLOAT en lugar de number, y no se admite ningún tipo BLOB. Impala SQL-92 incluye algunas mejoras en los estándares de los estándares SQL, pero no los incorpora todos. Cuando los datos son demasiado grandes para producirlos, manipularlos y analizarlos en un solo servidor, Impala funciona mejor que otros almacenes de datos y tiene más capacidad de escalabilidad. No es necesario eliminar la ubicación original de los archivos de datos al cargar Impala porque es liviano. El primer paso para aprender sobre pruebas de rendimiento, escalabilidad y configuraciones de clústeres de múltiples nodos suele ser recopilar grandes cantidades de datos. Cloudera Impala está optimizado para la carga de datos y la lectura masiva en grandes conjuntos de datos, lo que le permite hacer más con menos. El tamaño de bloque de varios megabytes de HDFS permite que Impala procese cantidades masivas de datos en paralelo a través de múltiples servidores en red.
En lugar de planificar índices normalizados y el tiempo y el esfuerzo necesarios para crearlos, lo hará en Impala. El motor de consultas de Impala puede manejar grandes cantidades de datos que provienen de almacenes de datos. Analiza un clúster y distribuye tareas entre nodos para reducir la cantidad de recursos consumidos. La partición de un almacén de datos es un concepto familiar en Impala. El particionamiento reduce la E/S del disco y aumenta la escalabilidad de consultas en Impala. Se requieren archivos de datos ya que no podrá acceder a ninguna tabla integrada en Impala. INSERTAR es una de las opciones disponibles.
Para construir dos mesas de juguetes, use una declaración de valor. Si ha estado utilizando software orientado a lotes, puede probarlo. Puede incorporar la tecnología SQL-on-hadoop en su configuración de Apache Hive. Las tablas de Hive en Impala no se cargan ni se convierten de una manera que requiere mucho tiempo.
Impala: una poderosa herramienta de gestión de datos para Hadoop
La sintaxis SQL es familiar para los usuarios de Impala, que pueden consultar datos almacenados en HDFS y Apache HBase. De esta forma, se pueden utilizar Hadoop e Impulsa en lugar de las tradicionales bases de datos relacionales . Además, es una potente herramienta de gestión de datos gracias a sus características. Además, sus capacidades para grandes conjuntos de datos son impresionantes y puede manejarlos con gran facilidad.
Impala en grandes datos
Impala es un motor de consulta MPP SQL de código abierto que se ejecuta en Apache Hadoop. Proporciona consultas SQL rápidas e interactivas sobre los datos almacenados en HDFS y HBase. Impala está diseñado para mejorar el rendimiento de Apache Hadoop al proporcionar una interfaz SQL rápida e interactiva para los datos almacenados en HDFS y HBase.
Impala, liderado por Cloudera, es un nuevo sistema de consultas. Hadoop tiene HDFS y HBase, por lo que puede consultar datos grandes de nivel PB almacenados allí. Esta tecnología se basa en colmena y memoria para el cálculo, además de tener en cuenta el almacén de datos, y proporciona procesamiento por lotes en tiempo real y procesamiento concurrente múltiple. Un cliente envía una solicitud de consulta a un nodo dentro de una red Impalad, donde se devuelve una identificación de consulta para las operaciones posteriores del cliente. Durante el primer paso del proceso de creación del analizador, se genera un plan de ejecución independiente (plan de una sola máquina, plan de ejecución distribuida) y también se ejecutará SQL, como cambios en el orden de combinación, inserciones de predicados, etc. Todos los nodos guardan una copia de la información de metadatos más reciente para garantizar que no se quede fuera del circuito. Antes de usar Hadoop, Hive o Impurbia, primero debe instalar el software de procesamiento de datos necesario.

El archivo de configuración de Impala se puede cambiar. Cada nodo realiza un cambio de configuración en Impala. Todos los nodos son responsables de conectar el paquete de controladores MySQL a una base de datos. Los nodos cambian la ruta Java de Bigtop.
Una comparación de Hive e Impala
También hay algunas diferencias menores, además de estas tres principales. En Hive, hay un subconjunto de HiveQL, mientras que en Implicit, hay un subconjunto de HiveQL. Hive e Impala se utilizan para almacenamiento de datos y consultas interactivas, respectivamente. Hive, a diferencia de Impala, no está destinado a la informática interactiva.
¿Qué es Impala en Hadoop?
Impala es un motor de consulta SQL de código abierto para datos almacenados en un clúster de Hadoop. Está diseñado para proporcionar consultas SQL rápidas e interactivas sobre datos almacenados en HDFS, HBase o cualquier otra fuente de datos de Hadoop .
Impala emplea una amplia gama de componentes familiares de Hadoop . INSERT solo puede escribir datos del tipo que Impala puede leer, mientras que SELECT puede leer datos del tipo que Impala puede leer. Cuando se utiliza un formato de archivo Avro, RCFile o SequenceFile, los datos se cargan en Hive. Las estadísticas de tabla y las estadísticas de columna se pueden utilizar además de las estadísticas de tabla y columna. Todas las declaraciones DDL y DML se actualizan automáticamente utilizando el demonio catalogado en Impala 1.2 y versiones posteriores si se envían a través del demonio catalogado. El método INVALIDATE METADATA devuelve los metadatos de todas las tablas del almacén de metadatos a las que se ha accedido. Los archivos de datos se almacenan en directorios para una nueva tabla y se leen independientemente del nombre del archivo cuando se ejecuta Impala.
En general, Apache Hive funciona bien como plataforma de almacenamiento de datos, mientras que Impala se adapta mejor al procesamiento paralelo. Hive es tolerante a fallas, mientras que Impulsa no lo es.
apache impala
Apache Impala es un motor de consultas SQL rápido e interactivo para Apache Hadoop. Permite a los usuarios emitir consultas SQL de baja latencia a los datos almacenados en HDFS y Apache HBase sin necesidad de movimiento o transformación de datos.
El concepto de arquitectura de Impala le permite manejar consultas interactivas usando HDFS de manera más eficiente que cualquier otro motor de consultas. Hive es mucho más lento debido a sus operaciones de E/S de disco, pero Apache es mucho más rápido porque es un motor completamente diferente. No hay distinción entre Impulsa y Presto porque Impulsa usa una tecnología mucho más rápida y Presto emplea una arquitectura similar. Cuando se trata de archivos de parquet, Impala funciona mejor. Determine qué datos debe particionar en función de las consultas de sus analistas. Con Compute Stats Estadísticas, sus consultas serán mucho más fáciles, especialmente si involucran más de una tabla (joins). Tuvimos un bloqueo del servidor del catálogo de Impala cuatro veces por semana, y nuestras consultas tardaron demasiado en completarse.
Además, la cantidad de archivos que creamos afecta en gran medida el rendimiento de nuestras consultas. Como resultado, comenzamos a administrar nuestras particiones y fusionarlas en el tamaño de archivo óptimo de aproximadamente 256 MB. Se indica que cada partición solo tiene un archivo (a menos que su tamaño sea > 256 MB). El tipo de columna más apropiado debe elegirse entre todos los tipos de datos admitidos por Implícito. Para limitar el número de consultas simultáneas o la memoria Y a la que accede un usuario, utilice el control de admisión de Impala. Si una consulta dura más de 30 minutos, se considera muerta.
El mejor motor para Big Data: Impala
El motor Impala es un motor de procesamiento de datos de Hadoop diseñado específicamente para grandes clústeres. Utiliza mucha menos energía y consume significativamente menos recursos que el motor MapReduce estándar de Hadoop. Implicit emplea el sistema de archivos distribuido HDFS como su principal medio de almacenamiento de datos, confiando en la redundancia de HDFS para evitar cortes de hardware o red nodo por nodo. Los archivos de datos que representan datos de tablas se representan físicamente mediante formatos de archivo HDFS familiares y códecs de compresión.
Motor de consultas de procesamiento paralelo
Un motor de consultas de procesamiento en paralelo es un tipo de motor de base de datos diseñado para procesar consultas en paralelo. Esto se puede hacer usando múltiples procesadores, múltiples núcleos o múltiples máquinas. El procesamiento en paralelo puede mejorar en gran medida el rendimiento de un motor de consultas, especialmente para consultas complejas.
Se utiliza una computadora multiprocesador para transformar consultas complejas en planes de ejecución que se pueden ejecutar simultáneamente, lo que le permite procesar grandes cantidades de datos a la vez. Se requiere una ejecución eficiente, como un buen tiempo de respuesta de consulta o un alto rendimiento de consulta, para un alto rendimiento. Se logra mediante el uso de técnicas eficientes de ejecución en paralelo y optimización de consultas.
Procesamiento paralelo: ¿El futuro de Etl?
Una consulta de alto nivel se puede transformar en un plan de ejecución que puede ser ejecutado de manera eficiente por una computadora multiprocesador mediante el procesamiento de consultas en paralelo. El procesamiento paralelo emplea la técnica de combinar datos paralelos y distribuidos, así como las diversas técnicas de ejecución proporcionadas por el sistema de base de datos paralelo . El procesamiento de consultas en paralelo se implementa en ETL dividiendo el conjunto de registros en cada tabla de origen asignada para transferir en fragmentos del mismo tamaño y luego realizando el proceso de transformación de datos para cada tabla de origen en un ciclo, seleccionando los datos consecutivamente, fragmento por fragmento. .