
Factores de decisión de fragmentos de bases de datos NoSQL
Publicado: 2023-02-13Cuándo particionar en una base de datos NoSQL es una decisión que debe tomarse en función de una serie de factores, incluidos, entre otros, el tamaño de los datos y la tasa de crecimiento, la carga y complejidad de las consultas, los requisitos de disponibilidad y escalabilidad y el modelo de datos. No existe una respuesta única para todos, y la decisión debe tomarse caso por caso. Sin embargo, hay algunas pautas generales que se pueden seguir. Si el conjunto de datos es pequeño y la carga de consultas no es demasiado pesada, es posible que la fragmentación no sea necesaria. En este caso, una sola instancia de base de datos NoSQL probablemente pueda manejar la carga. A medida que crece el conjunto de datos y aumenta la carga de consultas, es posible que sea necesario fragmentar para mantener un buen rendimiento. El modelo de datos también puede dictar cuándo fragmentar. Si los datos están estructurados de tal manera que se pueden dividir fácilmente en particiones separadas, la fragmentación puede ser una buena opción. Por otro lado, si el modelo de datos es complejo e interconectado, es posible que la fragmentación no sea posible o que no sea la mejor opción. Finalmente, se deben tener en cuenta los requisitos de disponibilidad y escalabilidad. Si los datos deben estar altamente disponibles y siempre accesibles, es posible que sea necesario fragmentarlos para proporcionar redundancia y eliminar los puntos únicos de falla. Si la escalabilidad es una preocupación importante, la fragmentación puede ayudar a distribuir la carga entre varios servidores.
¿Cuándo debo comenzar a fragmentar?
No hay una respuesta definitiva a la pregunta de cuándo comenzar a fragmentar. La decisión depende de una serie de factores, incluida la cantidad de datos que se almacenan, la velocidad a la que se agregan los datos, el crecimiento futuro previsto del conjunto de datos, el nivel deseado de rendimiento y los recursos disponibles. En general, se debe considerar la fragmentación cuando el conjunto de datos es demasiado grande o está creciendo demasiado rápido para ser administrado de manera efectiva por un solo servidor de base de datos.
Por qué fragmentar su Mongodb es esencial para grandes conjuntos de datos
¿Cuándo debo comenzar a fragmentar MongoDB? Cuando una sola base de datos puede manejar o almacenar una gran cantidad de datos en crecimiento, la reventa es una excelente opción. Un aumento de diez veces en la capacidad de almacenamiento de la base de datos mejora el rendimiento de una aplicación. También agrega complejidad a su sistema. ¿La fragmentación mejora el rendimiento? El uso de hashing para mejorar el rendimiento de la base de datos fue uno de los primeros métodos. El producto se ha convertido en uno de los mejores como resultado de los recientes avances tecnológicos. A pesar de que los datos son el activo más valioso de una empresa, las bases de datos ahora reciben más atención. ¿Por qué la fragmentación es mejor que la replicación? Si puede leer datos que no son los más recientes, la replicación puede ser beneficiosa para escalar las lecturas horizontalmente. En un grupo de datos compartidos, los datos se distribuyen en varios servidores con la ayuda de una clave compartida, lo que permite el escalado horizontal. Elegir la clave de fragmento correcta es fundamental. ¿Por qué fragmentamos MongoDB? Con MongoDB, las implementaciones con una gran cantidad de conjuntos de datos y operaciones de alto rendimiento pueden admitirse con fragmentación. Un sistema de base de datos que contiene grandes cantidades de datos o tiene una gran cantidad de usuarios simultáneos puede ser difícil de administrar en un solo servidor. Es posible que un servidor se quede sin recursos de CPU cuando se encuentran altas tasas de consulta. ¿Por qué es necesario fragmentar? La normalización se refiere a la partición de base de datos horizontal (por filas), mientras que la partición por épocas se refiere a la partición horizontal (por filas). Los fragmentos de datos se dividen en partes más pequeñas, más rápidas y más fáciles de administrar de bases de datos muy grandes de esta manera. es un ejemplo de cómo se pueden lograr los sistemas distribuidos ¿Qué db es el mejor para fragmentar? El uso de Sharding, también conocido como Particionamiento horizontal, como método de escalado es un enfoque común para las bases de datos. Amazon RDS es un servicio de base de datos relacional administrado basado en la nube que incluye numerosas funciones que simplifican la ejecución de la fragmentación en varias nubes.
¿Se necesita fragmentación en Nosql?
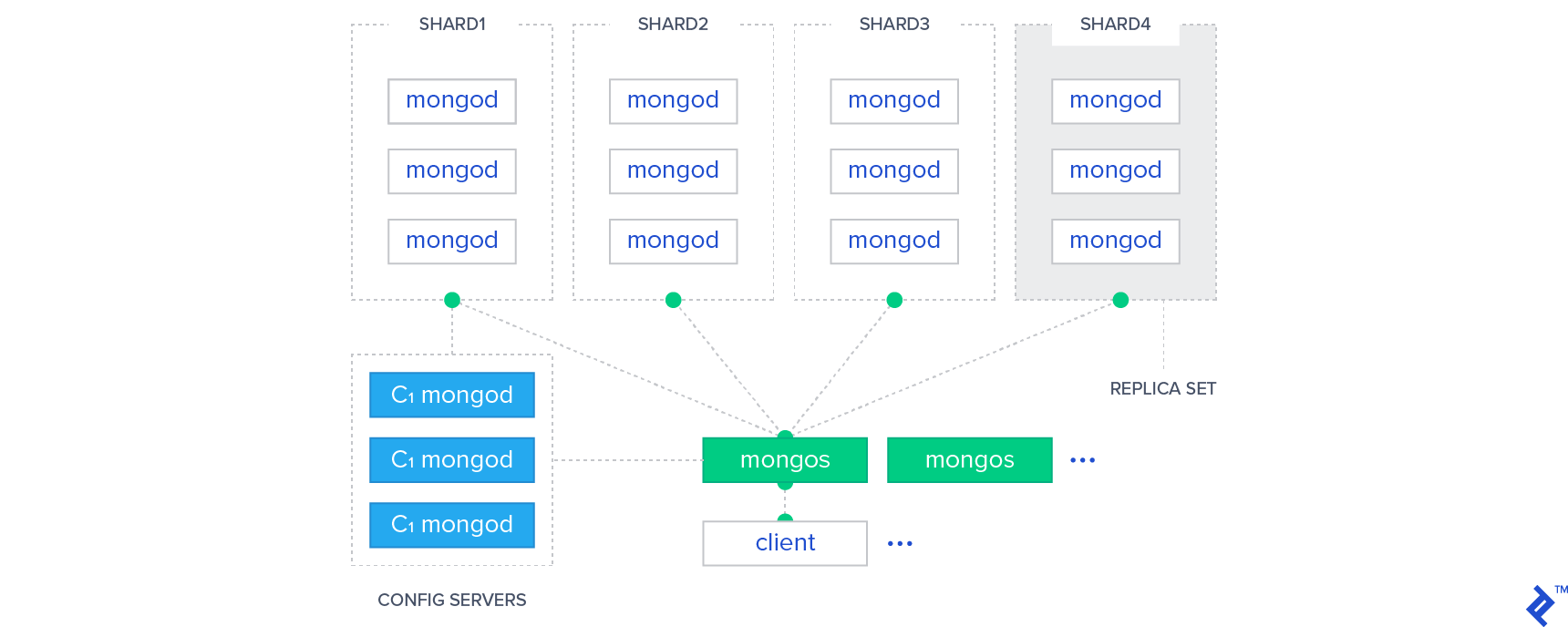
En NoSQL, el patrón Sharding se usa para particionar datos. El particionamiento es un método de colocar cada partición en servidores potencialmente separados que se encuentran dispersos por todo el mundo. La escalabilidad horizontal permite a las personas acceder al conjunto de datos en varios puntos del mundo sin ningún problema.
MongoDB tiene una herramienta importante en su base de datos conocida como Sharding. Se puede utilizar para aumentar el rendimiento mediante la distribución de grandes conjuntos de datos en varios servidores. Una parte de los datos en un servidor se identifica como una parte de los datos en otro servidor mediante una clave fragmentada. Como resultado, los datos se pueden copiar entre servidores sin tener que volver a indexarlos.
¿Es la fragmentación la solución adecuada para su base de datos?
Como resultado, si la base de datos única de su aplicación no puede manejar o almacenar una gran cantidad de datos en crecimiento, almacenarlos en una instancia de Sharding es una excelente opción. La presencia de Sharding mejora el rendimiento de la base de datos y escala la aplicación. Sin embargo, como resultado, existe cierta complejidad adicional en su sistema. Si aún no está seguro de si la fragmentación es la solución adecuada para usted, tenga en cuenta que MongoDB también admite escalado horizontal.
¿Cuándo debe fragmentar Mongodb?
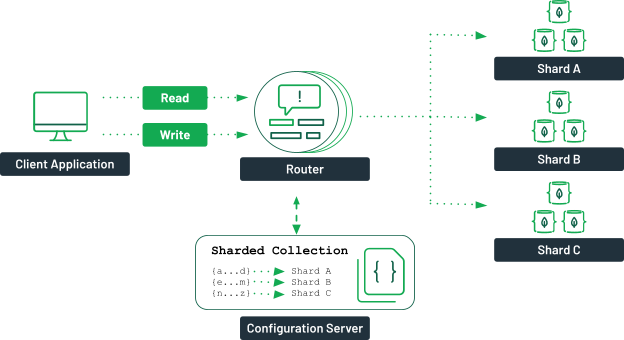
MongoDB debe fragmentarse cuando el tamaño de los datos excede la capacidad de un solo servidor y cuando se requiere un alto rendimiento de consulta.
Cuándo fragmentar su base de datos Mongodb
¿Debería considerar fragmentar su base de datos MongoDB? Debe considerar varios factores al decidir si usar o no un fragmento para su base de datos MongoDB. En primer lugar, si su aplicación MongoDB está experimentando altas tasas de consultas, es una buena idea usar fragmentación. Sraving también puede ayudar a expandir la base de datos si es necesario. Antes de decidir si usar la fragmentación, debe considerar los beneficios y costos de la misma. ¿Cómo se fragmenta MongoDB? Si planea fragmentar su base de datos MongoDB, le recomendamos que utilice Amazon Relational Database Service (Amazon RDS). Las características de Amazon RDS hacen que la fragmentación sea fácil de usar en la nube y también tiene el potencial de escalar.
¿Por qué fragmentaría una base de datos?
¿Qué es la fragmentación de la base de datos ? Un conjunto de datos de muestra se puede distribuir en varias bases de datos utilizando la técnica de intercambio de épocas, que luego se almacena en varias máquinas. La capacidad de almacenamiento total del sistema aumentará como resultado de la división de conjuntos de datos más grandes en fragmentos más pequeños y su almacenamiento en múltiples nodos de datos.
¿Es la fragmentación la respuesta a sus problemas de base de datos?
¿Por qué es necesario fragmentar una base de datos? La fragmentación es una gran solución cuando la única base de datos de su aplicación no puede manejar/almacenar una gran cantidad de datos en crecimiento. En general, al escalar la base de datos, puede mejorar el rendimiento de su aplicación. Además, agrega complejidad a su sistema. ¿Qué es un fragmento en una base de datos? El objetivo de la replicación de bases de datos es dividir una gran cantidad de conjuntos de datos en particiones o fragmentos. Cada nodo puede almacenar su propia fila de datos dentro de cada fragmento en forma de filas únicas, que se almacenan por separado unas de otras. Todos los fragmentos comparten el esquema o diseño de la base de datos original, pero los nodos que ejecutan los fragmentos difieren ligeramente. ¿Puedes usar un servidor sql para fragmentar? Usando fragmentos, un gran conjunto de datos se puede escalar y administrar de manera más efectiva. Existen numerosos métodos para dividir un conjunto de datos en fragmentos. Se puede usar una base de datos NoSQL o SQL para realizar Sharding. ¿Podemos fragmentar la base de datos MySQL? En un clúster, las filas de particiones (clústeres) se ejecutan automáticamente en los nodos, lo que permite que las bases de datos se escalen horizontalmente en hardware básico de bajo costo para manejar cargas de trabajo intensivas de lectura y escritura, así como API SQL y NoSQL directamente desde el servidor. ¿Solo es posible la fragmentación para la base de datos relacional? Uno de los métodos de escalamiento horizontal más populares para las bases de datos relacionales es el método Sharding de escalamiento horizontal. Amazon Relational Database Service (Amazon RDS) es un servicio de base de datos relacional administrado que simplifica la fragmentación en la nube debido a sus amplias funciones.

¿Por qué necesitamos Sharding en Mongodb?
El proceso de distribución de datos entre varias máquinas se conoce como hashing. Con MongoDB, las implementaciones con grandes conjuntos de datos y operaciones de alta velocidad pueden beneficiarse del uso de fragmentación. Un sistema de base de datos con una gran cantidad de datos o una aplicación que puede manejar una gran cantidad de solicitudes puede ser difícil de ejecutar en un solo servidor.
¿Necesitamos Sharding en Nosql?
La fragmentación de la base de datos es necesaria para escalar bases de datos SQL y NoSQL , que son bases de datos SQL y NoSQL. Estamos cortando la base de datos en varias partes (fragmentos) como su nombre lo indica. Cada fragmento tiene su propio índice, que se utiliza para determinar qué datos almacena.
Los beneficios de la fragmentación
El acto de distribuir datos entre múltiples servidores en un clúster se conoce como fragmentación. Es posible mejorar el rendimiento de una base de datos distribuyendo el trabajo que debe realizar entre varios servidores.
El servicio MongoDB utiliza una clave de fragmento para distribuir documentos de una colección a otra. MongoDB divide los datos en fragmentos, que se dividen en rangos que no se superponen según el intervalo de valores clave. El backend de MongoDB intenta distribuir esos fragmentos de manera uniforme entre los clústeres.
No existe una sola forma de usar Cassandra para la fragmentación. En Mongodb, cada nodo secundario almacena todos los datos del nodo principal, mientras que en Cassandra, cada nodo secundario conserva solo unas pocas particiones clave. Si se fragmenta Cassandra, puede alcanzar los mismos niveles de rendimiento que MongoDB sin necesidad de un nodo secundario.
¿Por qué necesitamos Sharding en bases de datos relacionales?
Debido a la mejor distribución de datos y cargas de trabajo en una arquitectura de base de datos bien diseñada, todos los fragmentos de base de datos se pueden distribuir por igual. Cada vez que una consulta pasa a través de un conjunto diferente de fragmentos, es consistente con la expectativa de rendimiento.
¿Qué base de datos es mejor para fragmentar?
La fragmentación de la base de datos es posible en Cassandra, HBase, HDFS, MongoDB y Redis. MySQL, PostgreSQL, Memcached, Zookeeper y Sqlite son solo algunas de las bases de datos que no admiten de forma nativa la fragmentación de PostgreSQL y MySQL. Cuando una base de datos no admite la lógica de fragmentación integrada, debe almacenarse en la aplicación.
Fragmentación en Nosql
Hay algunas formas diferentes de abordar la fragmentación en una base de datos NoSQL. El más común es usar una función hash para determinar en qué fragmento se debe almacenar un dato en particular. Esto se puede hacer a nivel de aplicación o a nivel de base de datos. Otro enfoque es utilizar la fragmentación basada en rangos, lo que implica almacenar datos en diferentes fragmentos en función del rango de valores en el que se encuentran. Esto se usa a menudo para cosas como datos de series temporales. También hay algunos otros enfoques menos comunes, pero estos son los dos más comunes.
Por qué la fragmentación es clave para escalar una base de datos de Cassandra
Al escalar una base de datos nosql, la clave es usar fragmentación. La base de datos se divide en varias piezas conocidas como losas, a las que luego se puede acceder desde varias máquinas. El sistema puede almacenar conjuntos de datos más grandes en fragmentos y grupos de nodos más pequeños, lo que aumenta la capacidad de almacenamiento total.
Sraving, específicamente, puede tomar la forma de fragmentación basada en claves y automatizar la distribución de datos a través de los nodos en Cassandra. En otras palabras, Cassandra puede manejar grandes conjuntos de datos sin necesidad de hardware o software adicional.
¿En qué categoría de bases de datos Nosql se recomienda no fragmentar datos?
No hay una respuesta definitiva a esta pregunta, ya que depende de las necesidades específicas de la aplicación. Sin embargo, generalmente se recomienda no fragmentar datos en almacenes de valores clave o bases de datos orientadas a documentos.
Nosql Sharding Vs Particionamiento
La partición y la fragmentación son métodos para dividir una gran cantidad de datos en subconjuntos más pequeños. La partición se diferencia de la fragmentación en que implica dividir los datos en varias computadoras en lugar de distribuirlos entre ellas. La función de partición de una instancia de base de datos se utiliza para dividir subconjuntos de datos entre ellos.
Escalando su base de datos con Sharding
Las bases de datos Nosql pueden escalar horizontalmente al replicar el esquema y dividirlo en fragmentos. Particionar bases de datos es el proceso de replicar el esquema y luego dividirlo en varias partes según un identificador clave en una instancia de servidor de base de datos separada para distribuir la carga. Cada tabla distribuida contiene una clave de fragmento.
Se pueden manejar grandes conjuntos de datos ingiriéndolos y almacenándolos en microservicios. Existen numerosas formas de dividir una gran cantidad de datos en partes pequeñas. Las bases de datos SQL y NoSQL se pueden utilizar para combinar y descartar datos.
Tanto las bases de datos SQL como las NoSQL se distinguen por su capacidad para gestionar la escala y la heterogeneidad de los datos, mientras que las bases de datos SQL se benefician de la capacidad de creación de particiones del motor de la base de datos. Shrsiting es un método eficiente para administrar sus datos, independientemente de si necesita escalar hacia arriba o hacia abajo.
¿Cuál es una forma en que una base de datos Nosql distribuida generalmente fragmenta datos?
Hay algunas formas diferentes en que una base de datos NoSQL distribuida puede fragmentar datos, pero un enfoque común es usar una función hash. Esta función se utiliza para determinar en qué nodo de la base de datos se debe almacenar un dato. Cuando ingresa una nueva pieza de datos, la función hash se usa para determinar en qué nodo debe almacenarse. Si el nodo ya está lleno, los datos se envían al siguiente nodo de la base de datos.
El fragmento en una base de datos
¿Qué es un fragmento en una base de datos?
El fragmento de un servidor de base de datos es un subconjunto de datos que se almacena en ese servidor. Una colección de datos, conocida como fragmento, se compone de partes iguales. Debido a que los conjuntos de datos más grandes se pueden almacenar en múltiples servidores más pequeños, los clientes pueden acceder a ellos más rápidamente.
Fragmentación de Mongodb
La fragmentación de Mongodb es un proceso de distribución de datos en varias máquinas. Es una forma de escalar una base de datos mongodb dividiendo los datos en partes más pequeñas y distribuyéndolos en varios servidores. Esto permite escalar horizontalmente la base de datos, lo que significa que se pueden agregar más servidores al sistema según sea necesario para acomodar el aumento del tráfico.
Fragmentación de su base de datos
Hay una variedad de tipos de sharding disponibles, que incluyen rangos/dinámicos, algorítmicos/hash, basados en entidades/relaciones y basados en geografía. La distribución de los datos en rangos y la asignación de servidores a cada uno de ellos se realiza mediante fragmentación dinámica . El servidor se mueve a diferentes regiones a medida que se agregan datos a la matriz, según el tamaño de la matriz. La fragmentación algorítmica/hash divide los datos en depósitos y asigna un servidor a cada depósito. Si los datos se agregan al depósito, se le asigna un valor hash al servidor. Un método de fragmentación basado en relaciones divide los datos en entidades y las relaciones entre entidades. Cada entidad tiene una lista de todas las entidades a las que se conecta. La fragmentación basada en la geografía divide los datos en regiones, asigna a cada región un servidor y luego divide los datos en regiones.
Estrategia de partición de rango clave
Una estrategia de partición de rango de claves define cómo se distribuyen los datos en una tabla particionada en varias particiones físicas. El intervalo de claves se basa en los valores de una columna de partición y a cada partición se le asigna un intervalo de valores en función de las claves de partición. Esta estrategia se usa a menudo para distribuir datos de manera uniforme entre varios servidores o para garantizar que los datos se almacenen en la misma ubicación física.
Particionamiento por rangos: el enfoque del servicio de integración para la distribución de datos
El servicio de integración, que distribuye filas de datos en función de un puerto o conjunto de puertos que se definen como claves de partición, emplea la partición por rango para distribuir filas de datos. Los rangos de valores para cada puerto se especifican en el siguiente formato. Como resultado, el servicio de integración usa la clave y el rango para enviar filas a la partición adecuada.
El servicio de integración distribuye filas de datos en función de un puerto o conjunto de puertos que defina como la clave de partición mediante la partición de rango.
Cuando está cargando datos nuevos y eliminando datos antiguos, esta es una excelente manera de hacerlo. El proceso de partición de rango se hace más fácil. El despliegue de datos, por ejemplo, es una práctica común, manteniendo en línea los datos de los 36 meses anteriores.