
Bases de datos NoSQL: una alternativa a las bases de datos relacionales tradicionales
Publicado: 2023-01-13Las bases de datos NoSQL son cada vez más populares como alternativa a las bases de datos relacionales tradicionales. Una base de datos NoSQL no requiere un esquema fijo y es fácil de escalar. Una cola es un tipo de almacén de datos NoSQL. Una cola es una estructura de datos que almacena datos en forma de primero en entrar, primero en salir (FIFO). Una cola se usa a menudo para almacenar datos que deben procesarse en un orden secuencial, como una lista de tareas que deben completarse. Una cola es un tipo de almacén de datos NoSQL porque no requiere un esquema fijo. Una cola se puede escalar fácilmente a medida que aumenta el número de tareas.
Si voy a usar MongoDB o RavenDB como cola de mensajes , ¿cuál preferiré? El objeto de mensaje puede enviarse a un servicio web a través del cliente y luego recuperarse por el servicio web. El servicio que realiza el trabajo puede seleccionar un tipo de mensaje en función de los criterios que puedan surgir. Puedo crear índices basados en los escenarios para acelerar las cosas. Si solo está creando una cola, debe considerar NoSQL para nada más que eso. Lo más probable es que tenga un mayor impacto en el rendimiento, la confiabilidad y la eficiencia si toma una decisión sobre qué implementación desea utilizar.
Las bases de datos NoSQL (también conocidas como SQL) almacenan datos de manera diferente a las bases de datos relacionales, además de no ser tabulares. Una base de datos NoSQL puede venir en una variedad de tipos diferentes según su modelo de datos. Los tipos de documentos, los tipos de clave-valor, los tipos de columna ancha y los gráficos son los más utilizados.
Datastore es una base de datos NoSQL altamente escalable que admite una amplia gama de aplicaciones. Como resultado, Datastore administra automáticamente la fragmentación y la replicación, lo que le permite usar una base de datos duradera y de alta disponibilidad que se escala automáticamente para manejar la carga de sus aplicaciones.
¿Qué es un almacén de datos Nosql?
Hay muchos tipos diferentes de almacenes de datos NoSQL, cada uno con sus propias fortalezas y debilidades. Los almacenes de datos NoSQL más populares son MongoDB, Cassandra y HBase.
Las bases de datos NoSQL basadas en documentos almacenan datos de manera más eficiente que las bases de datos relacionales. Están destinados a ser adaptables, escalables y capaces de responder rápidamente a los requisitos comerciales para la gestión de datos. Los tipos de bases de datos que comúnmente se conocen como NoSQL incluyen bases de datos de documentos puros, almacenes de valores clave, bases de datos de columnas anchas y bases de datos de gráficos. Las empresas de Global 2000 están adoptando rápidamente las bases de datos NoSQL para potenciar las aplicaciones de misión crítica. Esto se debe a cinco tendencias que presentan desafíos técnicos que dificultan el uso de la mayoría de las bases de datos relacionales. La gestión de bases de datos es una barrera importante para el desarrollo ágil porque carecen de la capacidad de admitir el modelo de datos fijos que es esencial para el desarrollo ágil. El modelo de aplicación define el modelo de datos en NoSQL.
Modelar los datos en NoSQL no es estático. El formato JSON es el formato predeterminado para almacenar datos en una base de datos orientada a documentos. Esto elimina la necesidad de marcos ORM y mejora el proceso de desarrollo. N1QL (pronunciado níquel), un poderoso lenguaje de consulta que extiende SQL a JSON, se lanzó como parte de Couchbase Server 4.0. Además, incluye soporte para declaraciones estándar SELECT / FROM / WHERE, así como agregación (GROUP BY), clasificación (SORT BY), uniones (LEFT OUTER / INNER) y otros. Debido a su arquitectura escalable y a que no existe un único punto de falla, las bases de datos distribuidas NoSQL tienen ventajas operativas convincentes. La disponibilidad se está convirtiendo en un problema importante a medida que más clientes interactúan con las empresas en línea y mediante aplicaciones móviles.
Las bases de datos NoSQL son fáciles de instalar, configurar y escalar. Con sus lecturas, escrituras y almacenamiento distribuidos, fueron diseñados para simplificar la lectura, la escritura y el almacenamiento. Pueden operar en una amplia gama de escalas, incluidas aquellas que administran y monitorean clústeres de diferentes tamaños. No hay necesidad de desarrollar software para replicar entre centros de datos; una base de datos NoSQL distribuida incluye replicación integrada entre centros de datos. Además, permite que las aplicaciones realicen su propia conmutación por error en lugar de esperar a que la base de datos detecte un problema y realice un proceso de recuperación basado en la base de datos. Las bases de datos NoSQL se utilizan cada vez más en aplicaciones web, móviles y de IoT debido a su facilidad de uso y de integración.
El almacenamiento de tablas es una solución excelente para los datos que no están almacenados en una base de datos relacional. El almacenamiento de tablas le permite almacenar datos en un contenedor que es lo suficientemente flexible para adaptarse al crecimiento de su aplicación. Se puede usar un sistema de almacenamiento de tablas para almacenar datos que son difíciles de almacenar en un modelo relacional, como datos de video o imagen.
Bases de datos Nosql de Azure: Documentdb, Graph y Keyvalue
Los tres tipos de bases de datos NoSQL en Azure son Azure DocumentDB, Azure Graph y Azure KeyValue. Con Azure DocumentDB, no es necesario administrar archivos de datos en el servidor ni recuperarlos de los archivos; es sin servidor, clave-valor y puede manejar hasta millones de solicitudes por segundo. Esta es una base de datos de gráficos que se puede usar para consultar y administrar datos en múltiples niveles en una aplicación. Azure Graph es una base de datos de gráficos que se puede usar para consultar y administrar datos en varios niveles de una aplicación. Le permite organizar y filtrar datos en las listas ordenadas y filtradas de Azure KeyValue.
¿Es una cola una base de datos?
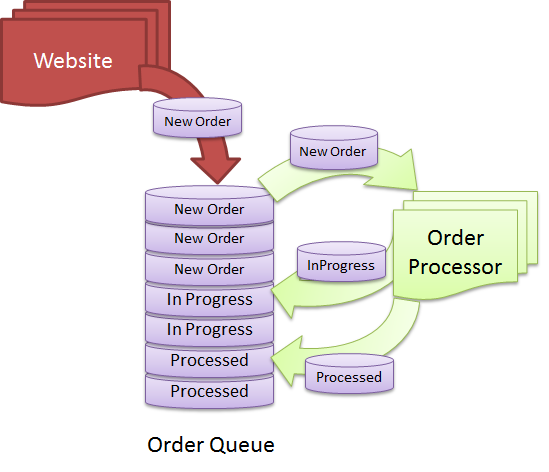
No hay una respuesta definitiva a esta pregunta, ya que depende de cómo defina una base de datos. En términos generales, una base de datos es una colección de datos que se organizan de una manera específica para que se pueda acceder a ellos y actualizarlos según sea necesario. Una cola es una estructura de datos que le permite almacenar y recuperar datos en un orden específico. Entonces, si considera que una cola es una colección de datos, entonces podría considerarse una base de datos. Sin embargo, si solo considera que una base de datos es una colección de datos a los que se puede acceder y actualizar, entonces una cola no se consideraría una base de datos.
¿Cuándo es el momento adecuado para utilizar una base de datos para un sistema basado en colas? Es fundamental mantener una cola ordenada y organizada para que todas las solicitudes se procesen lo más rápido posible. Hay una cola de mensajes diseñada para manejar este tipo de situaciones, lo que simplifica la eliminación o la puesta en cola de mensajes . Imagine que tiene cientos de solicitudes de creación de PDF en su base de datos en un momento dado. Es deseable poder procesar más solicitudes por segundo de forma continua. No es necesario conectar más trabajadores (procesos que manejan solicitudes) porque puede escalar su solución. Para recibir la solicitud, el trabajador deberá proporcionar un dato adicional.
Las colas de mensajes no requieren que el usuario realice ninguna transacción para garantizar que los mensajes se almacenen y procesen. En lugar de sondear manualmente los mensajes de una base de datos, las colas de mensajes se envían en tiempo real. Si se queda sin potencia de CPU mientras se conecta a demasiadas conexiones o realiza otras tareas que requieren una gran cantidad de CPU, puede usar más potencia de CPU para alimentar su servidor de cola de mensajes. En los casos en que se requiera una gran cantidad de mensajes asincrónicos, se recomienda encarecidamente una cola de mensajes. Si un trabajador muere mientras realiza una tarea, debe mantenerse en la cola hasta que se resuelva la solicitud. Cuando se recibe y procesa un mensaje, un trabajador envía un reconocimiento a la cola de mensajes para notificarles el progreso.

Una cola es una estructura de datos que puede almacenar una colección de elementos en un orden lógico. Los elementos colocados en una cola se procesan lo antes posible después de que se hayan agregado a la cola. Una cola puede ser útil cuando desea procesar elementos en un orden específico. Una declaración SELECT es un método que se puede usar para cambiar el contenido de una cola. Una instrucción SELECT es un método que le permite seleccionar elementos de una cola y enviarlos a otra ubicación si así lo desea. La declaración SELECT también se usa para enviar elementos desde otra ubicación a una cola adecuada , así como para insertarlos en una cola. Una instrucción INSERT, UPDATE, DELETE o TRUNCATE no puede intentar dirigirse a una cola. Si necesita procesar artículos en un orden específico, una cola es útil; sin embargo, no debe modificar los elementos de la cola.
La importancia de los sistemas de colas en los sistemas de bases de datos
Una base de datos con mecanismos de cola es una excelente adición a cualquier centro de datos. Es fundamental contar con la funcionalidad de DBMS para los sistemas de colas porque se pueden utilizar para una variedad de propósitos. Al integrar la funcionalidad de colas en un sistema de base de datos estándar , otras aplicaciones pueden obtener un mayor acceso a ellas. Con esta actualización, los sistemas de colas son más potentes y versátiles, y su utilidad y potencial aumentan.
¿Mongodb tiene una cola?
Una cola es una colección de documentos que se insertan en una base de datos MongoDB en orden ascendente según los datos de creación del documento o una clasificación de documentos según una prioridad determinada.
Si ya está usando MongoDB, puede usar este método para crear colas con una buena API. Si tiene un controlador MongoDB v3 o una base de datos más antigua, se recomienda la opción mongodb-[email protected] . Este paquete se clasifica como característica completa y estable. A pesar de su uso generalizado, hay muy pocos desarrollos nuevos en marcha con él. Háganos saber si tiene algún problema o si lo usa incorrectamente. Cada cola que cree será única. Se puede crear una colección de MongoDB llamada cambiar el tamaño de la cola de imágenes o notificar al propietario de la cola, y se pueden usar ambas.
Si no recibe un mensaje dentro de los 30 segundos posteriores a su recepción, se vuelve a colocar en la cola para que pueda recuperarse. Sondee su cola inactiva para ver si se han encontrado mensajes inactivos. Cuando devolvemos todos los mensajes de la cola original a la cola inactiva when.get(), la carga útil de la cola inactiva es el mensaje. Si un elemento se elimina de la cola pero no se acusa, se moverá a esta cola inactiva la próxima vez que intente salir. Si un elemento se elimina de la cola pero no se acusa, se moverá a esta cola inactiva la próxima vez que intente salir. Todavía se puede ver la cola haciendo ping en un mensaje para indicarle que está vivo y procesando la solicitud. El tiempo de visibilidad que pasa en la operación de ping también está determinado por el método // tiempo de visibilidad (en este caso, esta cola ha visto %d mensajes%d mensajes%d recuentos); // queue.ping(msg.ack, (err, id) = La cantidad de mensajes que han estado en la cola durante las últimas 24 horas, así como los mensajes actuales.
Podemos calcular el número de nuevos mensajes recibidos pero aún no activados. Debería ser posible get.total() si agrega up.size() +.inFlight() +.done() pero esto solo será aproximado porque las dos son operaciones diferentes que se usan para calcular el total. A veces, las estaciones son muy diferentes. Use la opción setInterval para limpiar su sistema regularmente. Console.log('Los mensajes procesados se han eliminado de la cola')*).
Cola Mongodb
Las colas de MongoDB (o colas de mensajes) proporcionan un mecanismo para almacenar mensajes de forma ordenada, primero en entrar, primero en salir. Los mensajes se pueden insertar en la cola en cualquier momento y se procesarán en el orden en que se reciben. Esto hace que las colas de MongoDB sean ideales para procesar tareas que deben realizarse en un orden específico o para tareas que pueden procesarse de forma asíncrona.
La misión de FloQast es permitir que los equipos de productos aceleren y automaticen el desarrollo de productos innovadores. Tradicionalmente, AWS SQS ha funcionado como nuestro servicio de cola de mensajes . Esto ha resultado en problemas en términos de mantener la viabilidad y la duplicación. En su lugar, hemos elegido MongoDB como nuestra cola de mensajes. En AWS Lambda, puede agregar mensajes fácilmente a cualquier cola. Elimina la necesidad de actualizar los servicios existentes para usar un Lambda separado. Cuando se accede a una cola, el servicio utiliza el método atomic findAndModify de MongoDB para obtener el primer elemento e invocar a Lambda según las instrucciones del desarrollador.
¿Qué es Change Stream en Mongodb?
En tiempo real, los desarrolladores de aplicaciones pueden ver cambios en los datos sin temor a seguir su oplog o tener que lidiar con la complejidad y los riesgos de estructuras de datos complejas. Una aplicación puede utilizar un flujo de cambios para suscribirse a todos los cambios en los datos de cualquier colección, base de datos o implementación y reaccionar ante ellos de inmediato.
Use disparadores para automatizar las operaciones de la base de datos
Mediante el uso de mecanismos de activación, puede automatizar las operaciones de la base de datos y hacer que su sistema sea más eficiente. Cuando se agrega, actualiza o elimina un documento de un clúster de MongoDB Atlas vinculado, los disparadores pueden manejar la lógica del lado del servidor. Podrá mantener su sistema funcionando sin problemas y, como resultado, automatizar las operaciones de la base de datos.
Base de datos de documentos Nosql
Una base de datos NoSQL, también llamada base de datos no relacional, es una base de datos que no utiliza la estructura tradicional de base de datos relacional basada en tablas. Las bases de datos NoSQL se utilizan a menudo para big data y aplicaciones web en tiempo real.
Una base de datos orientada a documentos es una forma moderna de almacenar datos en JSON en lugar de utilizar columnas y filas tradicionales. Estos datos semiestructurados se pueden utilizar para abordar problemas difíciles que, de lo contrario, requerirían un RDBMS. Los almacenes de documentos constituyen una solución natural y flexible que pueden utilizar los desarrolladores que desean trabajar más rápidamente con un software ágil. Puede consultar en una variedad de formas con el lenguaje de consulta expresivo y las capacidades de indexación versátiles. Una base de datos relacional tiene un conjunto de garantías con las que está familiarizado cuando ejecuta transacciones ACID. Tener sistemas distribuidos le permite escalar y proteger sus datos de una manera más eficiente y adaptable. Cada documento se distribuye en varios servidores en una unidad independiente, lo que reduce la necesidad de localidad de datos.
Las bases de datos de documentos son intuitivas y fáciles de usar, con velocidades de datos más rápidas que las bases de datos relacionales. La calidad de los datos será menor y las tablas serán rígidas. Debido a que no se puede realizar el escalado nativo, debe pagar costosos sistemas de escalado vertical si desea particionar su base de datos relacional tradicional. Es posible elegir entre una amplia gama de tipos de documentos en bases de datos orientadas a documentos; sin embargo, los campos que se encuentran en cada tienda pueden ser opcionales. Cada documento tiene la misma estructura, pero sus campos difieren. Cada documento tiene su propia ID única que se puede usar para agregar, cambiar, eliminar y consultar información. Por lo general, se piensa que la codificación de documentos es el proceso de convertir datos (o información) encapsulados en un formato estándar.
Una estructura de base de datos orientada a documentos es menos rígida y, por lo tanto, menos propensa a la incoherencia. Cuando consulta información directamente desde el documento en lugar de desde columnas dentro de la base de datos, los datos se almacenan más directamente en el documento. Los datos se pueden agregar al almacén de documentos con un solo campo que contiene campos de información relevantes para los datos.