
Bases de datos NoSQL: tabla grande
Publicado: 2023-01-04Las bases de datos NoSQL son cada vez más populares debido a su flexibilidad, escalabilidad y rendimiento. Una base de datos NoSQL no requiere un esquema predefinido y puede almacenar datos en cualquier formato. Esto lo hace ideal para aplicaciones que necesitan almacenar grandes cantidades de datos que cambian constantemente. La tabla grande es un tipo de base de datos NoSQL diseñada para almacenar grandes cantidades de datos. La mesa grande es utilizada por muchas organizaciones grandes, como Google, Facebook y Amazon. Big table es altamente escalable y puede manejar miles de millones de filas y millones de columnas. La tabla grande también es muy rápida y puede proporcionar acceso a los datos en tiempo real.
Google ha lanzado una serie de actualizaciones generalmente disponibles para su servicio de base de datos Cloud Bigtable . Como resultado de las nuevas actualizaciones, ahora hay disponible hasta cinco veces más espacio de almacenamiento por nodo. Google también agregó capacidades mejoradas de escalado automático que permiten que un clúster de base de datos crezca o se reduzca automáticamente según sus necesidades. Una nueva métrica de utilización de la CPU y el enrutamiento de grupos de clústeres permiten una mayor visibilidad de cómo se utilizan los recursos de una aplicación. Debido a la separación de cómputo y almacenamiento, cada tipo de recurso se puede escalar por sí solo en Bigtable. Los usuarios ahora pueden administrar fácilmente las implementaciones de alta disponibilidad y mejorar la administración de la carga de trabajo gracias a las nuevas capacidades.
NoSQL es una opción popular para almacenar grandes cantidades de datos. Este tipo de base de datos se está volviendo cada vez más popular entre las empresas web de hoy. Los defensores de las soluciones NoSQL dicen que ofrecen una escalabilidad más sencilla y un mayor rendimiento que las bases de datos tradicionales.
Bigtable es un tipo de servicio de base de datos NoSQL que pueden utilizar tanto los desarrolladores como los administradores de bases de datos. BigQuery es un híbrido porque utiliza dialectos SQL y se basa en la tecnología de procesamiento de datos de Google, Dremel.
¿Es Bigtable Sql o Nosql?
No hay una respuesta definitiva a esta pregunta, ya que depende de cómo se defina cada término. Sin embargo, si tomamos una definición amplia de SQL como cualquier base de datos que usa un lenguaje de consulta estructurado y NoSQL como cualquier base de datos que no usa un lenguaje de consulta estructurado, Bigtable se consideraría una base de datos NoSQL.
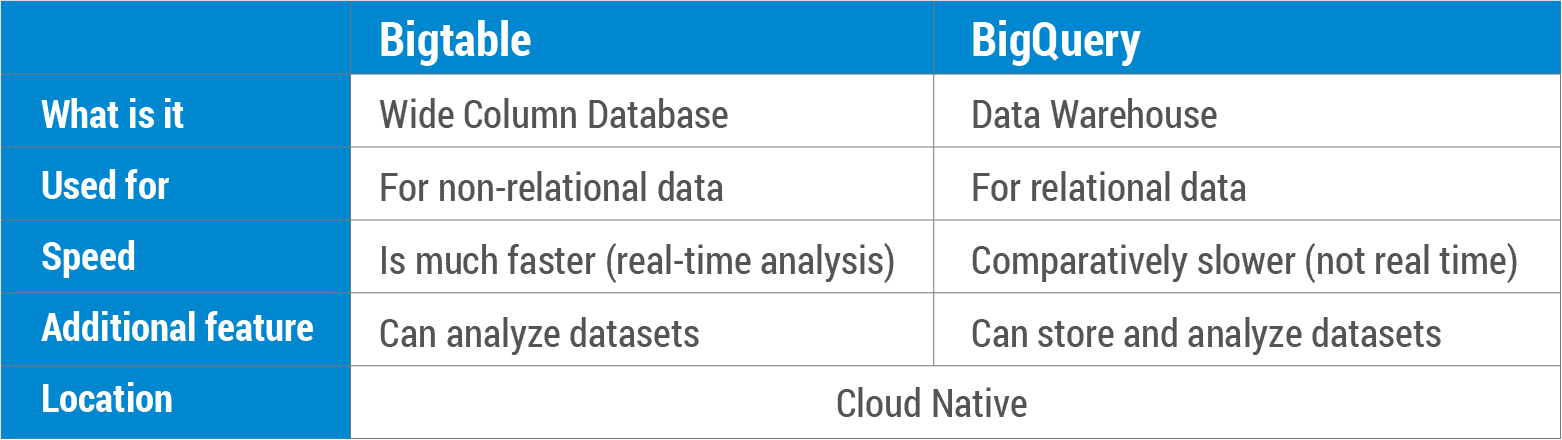
¿Qué es una comparación entre Bigtable y BigQuery? Bigtable es una base de datos NoSQL que le permite almacenar datos de manera segura y escalable. BigQuery es un almacén de datos relacional que almacena grandes cantidades de datos en una base de datos SQL. Bigtable se ha integrado en los productos de Google, como Analytics, Finanzas, Búsqueda personalizada, Earth y Writely, para sus operaciones diarias. Bigtable, una base de datos NoSQL de datos mutables , funciona bien con escenarios OLTP. BigQuery es un almacén de datos SQL relacional que se puede usar para aplicaciones OLAP. Tanto Bigtable como BigQuery son nativos de la nube, con acuerdos de nivel de servicio líderes en la industria. Además, ofrecen copia de seguridad automática (con replicación), así como escalabilidad infinita, fragmentación automática y recuperación automática de fallas (con replicación).
BigQuery, en lugar de una base de datos NoSQL, no hace esto.
¿Qué tipo de base de datos Nosql es Bigtable?
Cloud Bigtable es una base de datos NoSQL que se puede usar para analizar datos y ejecutar operaciones. Es una alternativa a HBase, que es un sistema de base de datos en columnas que utiliza HDFS. Las aplicaciones con un ancho de banda de menos de 10 MB son adecuadas para Cloud Bigtable, que puede admitir un alto nivel de rendimiento y escalabilidad.
Las bases de datos Big Table, como se las conoce, son un subconjunto de las bases de datos NoSQL. Bigtable, una aplicación de Google, es similar a Kleenex. Las bases de datos de Bigtable son el estándar de la industria para la imitación y la inspiración. Si bien el artículo se refiere principalmente a Bigtable, también analiza otras bases de datos NoSQL. Bigtable fue diseñado principalmente para uso interno de Google, sin acceso externo. Bigtable se introdujo en Google en 2004 y desde entonces ha sido utilizado por más de 60 aplicaciones de Google. Una implementación de Bigtable requiere un servidor maestro para realizar un seguimiento de las tabletas en un grupo de otros servidores.
Apache Software Foundation ha contribuido a una serie de excelentes iniciativas técnicas, particularmente en el campo de las bases de datos. Accumulo y HBase emplean los mismos principios de diseño que Google Bigtable, pero en un formato disponible comercialmente. Actualmente, Apache HBase ejecuta el sistema de mensajería de Facebook y está estrechamente integrado con Hadoop, lo que le permite procesar grandes conjuntos de datos. La base de datos Hypertable se basa en Bigtable, que es una base de datos tabular simple. Hypertable se ejecuta de la misma manera que lo hacen Hadoop y HFS. Baidu, uno de los motores de búsqueda más importantes de China, es uno de los principales patrocinadores de Hypertable. Los clientes incluyen sitios de subastas en línea como eBay, Groupon y Rediff.com, así como minoristas fuera de línea como Lowe's y TJ Maxx.
Hadoop es una plataforma de software de código abierto que permite a los usuarios almacenar y procesar cantidades masivas de datos de manera eficiente. Esto habilita las bases de datos NoSQL, que pueden reducir la cantidad de datos necesarios para almacenar en servidores individuales. Una base de datos NoSQL, por otro lado, no requiere un esquema fijo porque está basada en la escalabilidad. Debido a esto, son una excelente opción para almacenar cantidades masivas de datos de forma distribuida.
¿En qué tipo de almacén de datos Nosql cae Bigtable?
Una de las pocas características que están disponibles en el mercado genérico. En su nivel más básico, Bigtable es una base de datos NoSQL que abarca una amplia gama de columnas.
¿Es la base de datos columnar de Bigtable?
Las tiendas de columnas anchas, como Bigtable y Apache Cassandra, no son columnas en el sentido tradicional del término porque no usan estructuras de datos en columnas en absoluto en los dos niveles.
¿Es Bigtable una base de datos no relacional?
No hay una respuesta definitiva a esta pregunta, ya que depende de cómo se defina una "base de datos no relacional". Bigtable es un almacén de datos orientado a columnas, que algunas personas consideran un tipo de base de datos NoSQL. Sin embargo, tiene soporte para transacciones e indexación, que normalmente se asocian con bases de datos relacionales. Entonces, realmente depende de cómo defina una base de datos no relacional.
La declaración CREATE EXTERNAL TABLE se puede usar para crear una tabla en BigQuery especificando una tabla de la que extraer datos. La opción uri se puede usar para especificar una tabla de la que extraer datos. El esquema de la tabla incluye el nombre de la tabla, el tipo de tabla, los nombres de las columnas y los tipos de datos, así como el esquema de la tabla de la opción bigtable_options.
Si usa MySQL, la herramienta de importación de BigQuery se puede usar para importar datos de una tabla de MySQL automáticamente a BigQuery. Se ingresa un nombre de tabla y una familia de columnas en la herramienta, que importa los datos a una tabla de BigQuery.
Al usar la consola de Google Cloud, debe ingresar manualmente el nombre de la tabla y los parámetros de calificación de la familia de columnas. Es posible importar datos de una variedad de fuentes en la plataforma Google Cloud, incluidos MySQL, PostgreSQL, MongoDB y Redis.
Características clave de Bigtable
¿Cuáles son algunas características de Bigtable?
La velocidad de lectura y escritura de Bigtable, su escalabilidad masiva y la capacidad de manejar grandes cantidades de datos son solo algunas de sus muchas características. Además, debido a que Bigtable es una base de datos NoSQL, no se admiten las consultas SQL. Esto elimina la necesidad de realizar operaciones SQL en bases de datos separadas.
¿Es Bigtable una base de datos?
Bigtable no es una base de datos relacional. Es un sistema de almacenamiento distribuido para administrar datos estructurados que está diseñado para escalar a un tamaño muy grande: petabytes de datos en miles de servidores básicos. Google usa Bigtable para potenciar muchos de sus servicios a gran escala, como Google Analytics y Google Maps.
Cloud BigTable proporciona un conjunto único de funciones, lo que le permite escalar a más de 100 000 columnas y miles de millones de filas. Admite el almacenamiento de aproximadamente petabytes y terabytes de datos. En comparación con BigTable, tiene una latencia muy baja, pero también tiene el potencial de almacenar una gran cantidad de datos. BigTable puede almacenar datos estructurados en columnas, lo que le permite manejar servicios web y datos de búsqueda en Internet de la empresa. Los algoritmos de compresión también se utilizan para aumentar la capacidad del sistema. BigTable tiene servidores back-end impactantes que ofrecen mejores beneficios que la instalación de HBase autoadministrada que se incluye con BigTable. Las filas de BigTable comparten el mismo borde, por lo que también se denominan bloques.
Estos dispositivos, a los que se hace referencia como "tabletas", lo ayudan a administrar su carga de trabajo de consultas. Colossus, el sistema de archivos basado en la nube de Google, se utiliza para almacenar todas las tabletas. Todas las operaciones de escritura en BigTable se almacenan en el registro compartido de Colossus, al igual que los archivos SSTable. Las siete capacidades clave de BigTable son fundamentales para que una empresa tenga éxito. BigTable tiene el potencial de personalizar, acelerar y automatizar su vida de varias maneras. las filas y las columnas son las dos dimensiones de los datos en BigTable. Cada fila contiene un identificador o índice único al que se puede acceder utilizando la clave de fila única.
Cada una de las columnas de una familia tiene una columna de calificación. El uso de unidades de calificación de columnas, como claves de fila, ayuda en la identificación de columnas. Cuando se trata de bases de datos, BigTable se conoce como escasa. Cada una de las versiones de marca de tiempo de BigTable está representada por una celda, que es una de las dimensiones dentro de la estructura del mapa 3D. Esta poderosa base de datos, que puede personalizarse y depende de la velocidad, puede usarse para potenciar aplicaciones y sitios web móviles. Si piensa en el pasado, puede averiguar qué interacciones produjeron los mejores resultados. Le ayudará a implementar más análisis de datos y conducirá a un mejor servicio al cliente.
Google Cloud Bigtable, una base de datos NoSQL de código abierto, está integrada con la nube de Google. El hecho de que sea compatible con tantos ecosistemas de big data y Hadoop existentes significa que puede usarse para datos no estructurados o datos que necesitan baja latencia.
Bigtable: una excelente opción para aplicaciones con uso intensivo de datos
Bigtable, un servicio de base de datos NoSQL, se usa para grandes cargas de trabajo analíticas y operativas. Como resultado, es una excelente opción para aplicaciones de uso intensivo de datos y en tiempo real. Además, debido a que está orientado a columnas, es ideal para almacenar datos en tres dimensiones.
Bigtable vs mongodb
Existen algunas diferencias clave entre Bigtable y MongoDB. Primero, Bigtable es una base de datos orientada a columnas, mientras que MongoDB es una base de datos orientada a documentos. Esto significa que en Bigtable, los datos se almacenan en columnas, mientras que en MongoDB, los datos se almacenan en documentos. En segundo lugar, Bigtable no admite índices secundarios, mientras que MongoDB sí. Esto significa que si desea consultar datos en Bigtable, debe conocer la columna específica que desea consultar. En MongoDB, puede consultar cualquier campo en un documento. Finalmente, Bigtable está diseñado para escalar horizontalmente, mientras que MongoDB está diseñado para escalar verticalmente. Esto significa que en Bigtable, puede agregar más máquinas a su clúster para aumentar la capacidad, mientras que en MongoDB, puede agregar más RAM y CPU a su servidor para aumentar la capacidad.
Cloud Bigtable de Google: no solo para Big Data
Bigtable sigue siendo un componente de la infraestructura de Google, ya que se creó en 2007. Aunque Cloud Bigtable es ideal para almacenar grandes cantidades de datos con baja latencia, no es ideal para datos que no requieren un acceso frecuente. Cloud Bigtable, por ejemplo, no sería una buena opción para un lago de datos.
Base de datos de BigTable
Una base de datos bigtable es una base de datos que utiliza una estructura de datos bigtable . Una bigtable es un sistema de almacenamiento distribuido para datos estructurados que está diseñado para escalar a un tamaño muy grande.
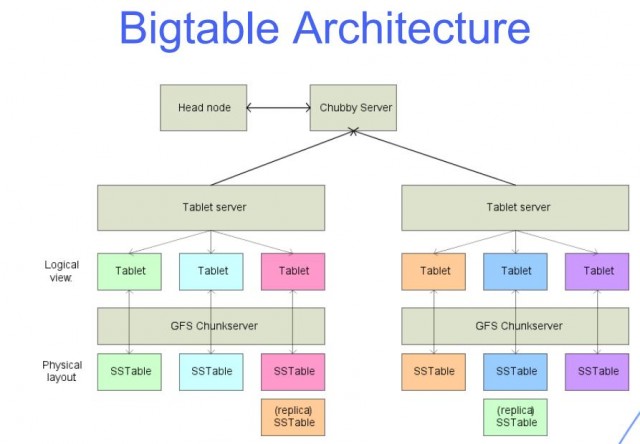
Una tabla grande es aquella que tiene muchas filas y columnas y, por lo general, está escasamente poblada. Bigtable es ideal para grandes conjuntos de datos debido a su baja latencia y alta densidad. Esta fuente de datos es ideal para las operaciones de MapReduce porque admite un alto rendimiento de lectura y escritura con baja latencia y es ideal para grandes conjuntos de datos. Los datos de una tabla de Bigtable se fragmentan en bloques de filas contiguas, cada una de las cuales se denomina tableta, para reducir la carga de consultas. El formato SSTable se utiliza para almacenar las tabletas de Google en Colossus, el sistema de archivos de la empresa. Cada tableta está vinculada a un nodo específico en la instancia de Bigtable, que también se conoce como nodo. Agregar nodos a un clúster puede aumentar la capacidad del clúster para manejar varias solicitudes simultáneas.
Cada fila contiene una combinación de la familia de columnas, el identificador de columna y la marca de tiempo, esencialmente una matriz de entradas de claves/valores. La gran mayoría de las veces, Bigtable convierte todos los datos en cadenas de bytes sin procesar. Debido a que Bigtable almacena las mutaciones secuencialmente y las compacta solo una vez cada pocos meses, las mutaciones ocupan más espacio de almacenamiento cuando se cambian a una fila. Bigtable comprime datos usando un algoritmo inteligente y emplea tecnología de compresión. Debido a que las deleciones son un tipo especializado de mutación, requieren espacio de almacenamiento adicional a corto plazo. Los métodos de almacenamiento patentados de Google le permiten resistir la prueba del tiempo para datos más allá del rango de la replicación HDFS de tres vías estándar. Los usuarios pueden acceder a sus tablas de Bigtable usando las funciones que les asigna su proyecto de Google Cloud y la Administración de acceso e identidad (IAM). La mayoría de los datos de Google Cloud se cifran en reposo mediante los mismos sistemas de administración de claves reforzados que usamos en nuestros datos cifrados. Se puede usar una copia de seguridad para guardar una copia del esquema y los datos de la tabla, así como para restaurar la copia de seguridad en una nueva tabla más adelante.
Bigtable es un sistema de almacenamiento distribuido bien diseñado capaz de almacenar hasta petabytes de datos. Debido a que es fácil de usar, es una excelente opción para el almacenamiento de datos a gran escala .

El poder de la nube Bigtable
La base de datos de Cloud Bigtable tiene la capacidad de albergar decenas de miles de filas y columnas y se puede acceder a ella desde cualquier parte del mundo. Como resultado, es muy adecuado para el almacenamiento de datos a gran escala. Cloud Bigtable ahora está disponible en Google Cloud a partir del 6 de mayo de 2015. Esto ha resultado en más de 10 EXAbytes de datos servidos y más de 5 mil millones de solicitudes procesadas por segundo desde entonces. Como resultado, Cloud Bigtable todavía está en uso y es una herramienta valiosa para el almacenamiento de datos.
Bigtable contra Cassandra
Cada nodo se elige para operaciones de lectura y escritura utilizando su propio método. En Cassandra, se identifica una clave de partición, mientras que en Bigtable, se usa una clave de fila. El cliente inspecciona primero la política de equilibrio de carga de Cassandra.
Se distribuyen sistemas de bases de datos como Bigtable y Cassandra. Crean almacenes multidimensionales de clave-valor que pueden procesar decenas de miles de consultas por segundo (QPS). El objetivo de este documento es explicar las diferencias y similitudes entre los dos sistemas de bases de datos. Bigtable contiene muchas de las funciones principales descritas en Bigtable. El documento describe un sistema de almacenamiento distribuido para datos estructurados. Cuando Bigtable identifica la asignación de rangos como necesaria para un conjunto de datos, los rangos de datos para un nodo de procesamiento son fáciles de cambiar porque la capa de almacenamiento está separada de la capa de procesamiento. Además, Bigtable permite la replicación asincrónica entre clústeres distribuidos geográficamente en topologías de hasta cuatro.
Cassandra proporciona tolerancia a fallas, que se correlaciona con el nivel de consistencia. Con una estrategia de topología de replicación de datos configurable, puede definir la replicación geográfica. En la mayoría de las topologías de centros de datos múltiples, QUORUM (o LOCAL_QUORUM) es la configuración predeterminada. Se requiere que la mayoría de un nodo de réplica responda al nodo coordinador para que esta configuración de nivel se considere exitosa. Las réplicas de datos en Cassandra se pueden mejorar en términos de tolerancia a fallas mediante el uso de configuraciones de centros de datos y bastidores. La topología determina qué nodos son necesarios para garantizar la coherencia durante las operaciones de lectura y escritura. La instancia de Bigtable puede tener uno o más clústeres, o puede tener una colección de hasta cuatro clústeres replicados.
Bigtable y Cassandra funcionan como tiendas de columna ancha NoSQL. La clave de fila determina el orden en que se muestra la clasificación de datos globales de una tabla en Bigtable. En Bigtable, los nodos se usan para equilibrar la responsabilidad de los rangos clave, lo que comúnmente se conoce como tabletas. El servicio de Bigtable no aplica los tipos de datos de columna que envía el cliente. La familia de columnas de Bigtable selecciona qué columnas de una tabla deben almacenarse y recuperarse de una a la siguiente. Cada tabla debe tener al menos una familia de columnas, pero las tablas suelen tener más (el número máximo de columnas que puede tener una tabla es 100). Una clave de fila se encuentra en una celda y un nombre de columna se encuentra en la otra.
Cassandra y Bigtable usan diferentes métodos para elegir el nodo de procesamiento para las operaciones de lectura y escritura. En Cassandra, se distingue la clave de partición, mientras que en Bigtable, se usa la clave de fila. Al crear una política de varios clústeres, una política de equilibrio de carga que tenga en cuenta los centros de datos proporciona los beneficios de la conmutación por error. Ambas bases de datos se han optimizado para una escritura rápida y utilizan un proceso similar para hacerlo. Ambas bases de datos almacenan datos en archivos SSTable, que son archivos inmutables. En Cassandra, se deben contactar varias réplicas antes de que el coordinador informe al cliente que se ha completado la escritura. Debido a que cada clave de fila en Bigtable solo se asigna a un nodo, se requiere una respuesta de ese nodo para confirmar que la escritura se realizó correctamente.
Como resultado de la fusión de SSTable, ambas bases de datos pueden excluir celdas. Al devolver datos a Cassandra, la cláusula WHERE en una consulta CQL restringe el número de filas. Solo se debe consultar el nodo a cargo del rango de claves cuando se usa Bigtable. Los resultados de lectura de un nodo se pueden limitar de varias formas. Durante una fase de compactación, Bigtable y Cassandra almacenan datos en SSTables, que se fusionan regularmente. Bigtable no limita la cantidad de versiones de marca de tiempo para cada celda, pero otros tamaños de fila sí lo pueden hacer. La replicación proporcionada por Colossus garantiza una alta durabilidad de los datos.
La interfaz de línea de comandos de Bigtable, así como sus bibliotecas de clientes para una variedad de lenguajes de programación comunes, complementan las capacidades de Cassandra. Cada nodo de Bigtable debe servir una serie de SSTables que contengan datos almacenados en esas tablas. Ya no necesita calcular réplicas de almacenamiento en Bigtable como lo haría en Cassandra al determinar el tamaño del clúster. Las instancias de Bigtable generalmente almacenan datos en unidades de estado sólido (SSD) o discos duros (HDD). A diferencia de Cassandra, que se basa en la teoría de que no hay pérdida de densidad de almacenamiento para lograr la tolerancia a fallas, la carga de trabajo no pierde densidad. Es sencillo escalar una instancia de Bigtable hacia arriba o hacia abajo según sea necesario para cumplir con los requisitos de la carga de trabajo mientras se mantiene el mínimo esfuerzo y tiempo de inactividad. Una instancia puede tener solo cuatro clústeres, pero se pueden agrupar en cualquier región de nube admitida del planeta.
Para crear una métrica para QPS pernode, Google recomienda usar el rendimiento de Bigtable con consultas y datos representativos. Bigtable incluye componentes administrados para funciones comunes de administración de Cassandra. Una tabla que forma parte del clúster se crea como una copia restaurable de la tabla en una copia de seguridad de bigtable. El precio de una copia de seguridad es más bajo que el de Cloud Storage o no consume recursos del nodo. Otra opción es usar una exportación de datos administrada a Cloud Storage para hacer una copia de seguridad de Bigtable. Bigtable administra las tareas comunes de mantenimiento interno de Cassandra, como parches del sistema operativo, recuperación de nodos, reparación de nodos, monitoreo de compactación de almacenamiento y rotación de certificados SSL con facilidad. Los paneles están prediseñados para realizar un seguimiento de las métricas de rendimiento y utilización en los niveles de instancia, clúster y tabla en la página de la consola de Google Cloud de Bigtable. Puede utilizar el panel de supervisión para realizar ajustes de rendimiento avanzados.
SQL se usa en Bigtable, al igual que el acceso de clave de fila a los datos en una base de datos NoSQL. Los nodos se distribuyen por la red y se utilizan chismes para mantener la coherencia de la red. Con este sistema, se aumenta la capacidad de almacenamiento de datos y se mantiene la disponibilidad sin un solo punto de falla.
Bigtable, por otro lado, es más escalable y proporciona un mayor nivel de disponibilidad que Cassandra. Bigtable también es más fácil de usar que otros lenguajes de programación, lo que lo convierte en una excelente opción para conjuntos de datos con menos recursos.
¿Google todavía usa Bigtable?
Google Analytics, indexación web, MapReduce y muchas otras aplicaciones de Google, como Google Maps, Google Books, My Search History, Google Earth, Blogger.com, Google Code hosting, lo utilizan para generar y modificar datos almacenados en Bigtable, Google Maps , Google Libros, Mi búsqueda
¿Google usa Cassandra?
La topología de DataStax Astra Cassandra as a Service se implementó en Google Cloud con el sistema operativo TensorFlow, así como con el sistema operativo Apache Cassandra en tres zonas de Google Cloud.
¿Es Bigtable lo mismo que Hbase?
Una marca de tiempo de Bigtable se almacena en microsegundos, mientras que una marca de tiempo de HBase se almacena en milisegundos. Esta distinción puede ser útil cuando se usa la biblioteca de cliente de HBase para Bigtable y se buscan marcas de tiempo invertidas.
¿Para qué sirve Bigtable?
La base de datos Bigtable NoSQL es una base de datos de columnas anchas que es ideal para usar en una base de datos NoSQL. El sistema está optimizado para proporcionar baja latencia, una gran cantidad de lecturas y escrituras y alto rendimiento a escala. El uso de casos de tabla generalmente se limita a una escala o rendimiento específico que requiere una latencia alta, como Internet de las cosas (IoT), AdTech, FinTech, etc.
BigTable Vs Bigquery
Existen algunas diferencias clave entre bigtable y bigquery. Bigtable está diseñado para ser una base de datos escalable orientada a columnas, mientras que bigquery está diseñado para ser una base de datos escalable y relacional. Bigtable no admite SQL, mientras que bigquery sí. Bigtable no se usa tanto como bigquery, pero tiene algunas ventajas sobre bigquery, como poder escalar a una mayor cantidad de columnas y filas.
Google ha logrado un progreso significativo en el almacenamiento en la nube de datos masivos a lo largo de los años. Bigtable es un servicio de base de datos NoSQL totalmente administrado a escala de petabytes que se basa en la administración de bases de datos orientadas a objetos (OOPA). BigQuery se crea con Bigtable y Google Cloud Platform, así como con el sistema de base de datos Dremel de Google. Hay tres diferencias principales entre BigQuery y Bigtable. Una solución de Big Data como servicio (BaaS) es una que proporciona Google Cloud BigQuery. BigQuery es utilizado por productos de Google como Analytics, Finanzas, Búsqueda personalizada, Earth, Orkut y Writely. Cuando se utiliza el procesamiento de datos ultrarrápido de BigQuery, se pueden procesar 35 000 millones de filas en cuestión de segundos.
Una base de datos NoSQL es un acrónimo de un servicio de base de datos; en otras palabras, no es una base de datos relacional. Las columnas de teclas pueden tener varios tamaños y las barras de teclas se pueden desplazar horizontalmente. Los elementos de datos individuales con una mayor capacidad de almacenamiento de 10 megabytes pueden afectar el rendimiento. Si necesita una solución de almacenamiento integral para objetos no estructurados (por ejemplo, archivos de video), es probable que el almacenamiento en la nube sea una mejor opción. Es una excelente opción para consultas que requieren un escaneo de tabla o para ver una gran base de datos de una sola vez. Es imposible que un objeto cargado cambie durante su vida útil en BigQuery y sus datos siempre son inmutables. Las tablas dentro de una tabla grande almacenan datos escalables que se han ordenado en mapas de claves/valores ordenados por clave, fila y marca de tiempo.
Con Integrate.io, puede automatizar un proceso de integración de datos y ETL para vincular sus fuentes de datos y almacenes de datos en la nube. La plataforma de integración incluye más de 100 integraciones prediseñadas, incluido BigQuery, y una interfaz de arrastrar y soltar que hace que administrar sus procesos de integración sea más fácil que nunca. Comuníquese con nuestro equipo de expertos en datos para analizar su situación o para comenzar una prueba piloto de 14 días de la plataforma Integrate.
Google BigQuery se destaca en términos de características, a pesar de que MySQL todavía se usa ampliamente. Esto es especialmente cierto para las funciones que se usan comúnmente en las aplicaciones comerciales, como la importación y exportación de datos, el análisis de datos y la federación de datos. MySQL, por otro lado, solo tiene 28 funciones, lo que significa que es posible que no pueda satisfacer las necesidades de muchas empresas. Google BigQuery está basado en la nube, lo que permite acceder a él desde cualquier ubicación con conexión a Internet. MySQL, por otro lado, se ejecuta en una arquitectura cliente-servidor y no está disponible en la nube.
¿Cuál es la diferencia entre Bigquery y Bigtable?
Bigtable es una base de datos NoSQL de columna ancha que está optimizada para lecturas y escrituras intensas. A diferencia de BigQuery, que es un almacén de datos empresarial para grandes cantidades de datos relacionales, Oracle Data Warehouse funciona como un servicio de eliminación de duplicados.
¿Bigquery está basado en Bigtable?
Bigtable, un servicio de consultas basado en la nube desarrollado en colaboración con Google y Microsoft, y el sistema Dremel de Google para consultas ad hoc pronto siguieron, respectivamente.
¿Cuándo debo usar Bigtable?
Bigtable es ideal para aplicaciones que requieren alto rendimiento y escalabilidad cuando manejan datos clave/valor, con no más de 10 MB de datos por valor. Los puntos fuertes de Bigtable están en las operaciones por lotes de MapReduce, el procesamiento/análisis de secuencias y el aprendizaje automático.
Servicio escalable de base de datos Nosql
Un servicio de base de datos nosql escalable es un tipo de base de datos que puede manejar datos a gran escala. Es un servicio basado en la web que se puede utilizar para almacenar y administrar grandes cantidades de datos. Este tipo de base de datos está diseñado para ser escalable de modo que pueda manejar datos a gran escala.
Este tutorial asume que tiene un entorno Node.js en funcionamiento. He creado una carpeta llamada nodejs-dynamodb-sample para descomprimir los archivos de DynamoDB. La página de GitHub del proyecto es https://www.gofundme.com/adamfowleruk/nodesurvey.html. La aplicación de muestra utiliza DynamoDB para buscar y recuperar datos de películas. Para almacenar datos en S3, usaremos el servicio de administración de acceso e identidad (IAM) de Amazon, y para acceder a DynamoDB en AWS, usaremos el servicio DynamoDB de Amazon. Para utilizar el servicio iADM de Amazon, primero debe registrarse y crear un usuario. Se puede agregar un título de película y un año a la sección POST/películas de su búsqueda.
Haga una lista de películas de un año determinado ingresando el campo ingresado con clave. Ahora puede crear su propia aplicación siguiendo este ejemplo básico. Si tiene la intención de usar sus tablas nuevamente, debe eliminarlas una vez que haya terminado de usarlas, lo que generará costos de servicio y alojamiento de AWS. En AWS, vaya a la consola de DynamoDB e ingrese la cantidad de almacenamiento que ha utilizado. Puede ver los elementos en una tabla haciendo clic en "Películas", mirar las métricas que ve en su aplicación y ver los costos mensuales estimados haciendo clic en la pestaña Capacidad. En mi página de GitHub, incluyo una muestra del código en este ejercicio: https://github.com/adamfowleruk/nodejs-dynamodb-sample.
Base de datos BigTable de Google Cloud
Google Cloud Bigtable es un servicio de base de datos NoSQL a escala de petabytes, rápido y completamente administrado que es ideal para grandes cargas de trabajo analíticas y operativas.
El almacén de datos de Google es más adecuado para aplicaciones que necesitan respuestas rápidas a las solicitudes de los usuarios.
En la base de datos Bigtable de Google, no existe una base de datos relacional. No se admiten consultas SQL, uniones ni transacciones de varias filas. Como resultado, si está buscando soporte de base de datos estándar, no puede esperarlo. Bigtable, por otro lado, no proporciona una gran cantidad de datos o análisis. La naturaleza optimizada de Bigtable se debe en parte a sus capacidades de análisis y manejo de datos de alto rendimiento. Datastore, por otro lado, está diseñado para permitir que los datos transaccionales de alto valor se sirvan a las aplicaciones. Como resultado, Datastore se adapta mejor a las aplicaciones que requieren respuestas rápidas a las solicitudes de los usuarios.