
Bases de datos NoSQL: alta disponibilidad y escalabilidad a través de la replicación
Publicado: 2022-11-19Hay muchos tipos diferentes de bases de datos NoSQL, cada una con sus propias capacidades y características. Sin embargo, una característica común de muchas bases de datos NoSQL es la capacidad de replicar datos en varios servidores. La replicación es el proceso de copiar datos de un servidor a otro para que los datos estén disponibles en varios servidores. La replicación puede proporcionar una mayor disponibilidad y rendimiento al permitir que los datos se lean desde varios servidores. Las bases de datos NoSQL suelen utilizar un modelo de replicación maestro-esclavo, en el que un servidor se designa como maestro y todos los demás servidores son esclavos. El servidor maestro mantiene una copia de los datos y replica los cambios en los esclavos. Los esclavos se pueden usar para leer datos, pero todas las escrituras deben pasar por el maestro. Una ventaja de la replicación es que puede ayudar a mejorar el rendimiento mediante la distribución de lecturas en varios servidores. La replicación también puede mejorar la disponibilidad al proporcionar múltiples copias de datos en caso de que falle un servidor. Las bases de datos NoSQL suelen ofrecer alta disponibilidad y escalabilidad debido a su capacidad para replicar datos en varios servidores.
Del mismo modo, la replicación de datos NoSQL es una característica robusta que le permite copiar y almacenar sin problemas datos estructurados, no estructurados y semiestructurados, así como evitar la pérdida de datos cuando un servidor falla. Obtenga más información sobre las bases de datos NoSQL en este sitio.
Se lleva a cabo tanto la replicación maestro-esclavo como la ejecución de esclavos, y la replicación maestro-esclavo designa un nodo como la copia autorizada que puede manejar escrituras y lecturas. Un proceso de replicación de igual a igual permite que los nodos se escriban entre sí, y cada nodo copia los datos al siguiente.
La replicación de MongoDB se refiere a la creación de un conjunto de réplicas que comparte un conjunto de datos común con otras instancias de MongoDB . El conjunto de réplicas contiene una serie de nodos que contienen datos, y el nodo que es un árbitro es opcional. Hay seis nodos en un entorno de soporte de datos, con un miembro designado como nodo principal y los otros miembros clasificados como nodos secundarios.
En general, un experimento o procedimiento que arroja más de una cierta cantidad de resultados es un éxito; en este caso, la replicación del ADN se copia o replica. El acto de replicar algo se conoce como replicación.
¿Qué es la replicación de datos Nosql?
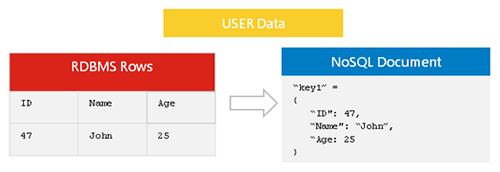
La replicación de datos Nosql es el proceso de copiar datos de una base de datos Nosql a otra. Esto se puede hacer por una variedad de razones, como crear una copia de seguridad o distribuir datos entre varios servidores. La replicación de datos Nosql generalmente se realiza de forma asíncrona, lo que significa que la copia de los datos no tiene que ser una réplica exacta de los datos originales.
Durante muchos años, la replicación de datos ha sido un componente esencial de la infraestructura de datos de cualquier organización. Un sistema de replicación de datos protegerá sus datos al garantizar una alta disponibilidad, copias de seguridad y recuperación ante desastres. Además, la replicación ayuda a la capacidad de la organización para mejorar la consistencia y precisión de los datos. Es un método para mejorar la confiabilidad de los datos a través del proceso de replicación. Al replicar los datos, puede asegurarse de que estén siempre disponibles, respaldados y en caso de desastre. Al replicar los datos, también puede mejorar su consistencia y precisión. Al diseñar una infraestructura de datos, es fundamental considerar la replicación de datos.
¿Qué es fragmentación y replicación en Nosql?
¿Cuál es la diferencia entre fragmentación y replicación? El nodo del servidor principal copia los datos de los nodos del servidor secundario como parte de la replicación de datos. Al hacerlo, puede aumentar la disponibilidad de los datos y convertirlos en una copia de seguridad de emergencia en caso de que falle el servidor principal. Gestiona el escalado de servidores en superficies horizontales utilizando una clave de fragmento.

¿Las bases de datos Nosql tienen redundancia de datos?
Cuando hay un volumen de datos significativo y se puede tolerar la redundancia de datos , la base de datos NoSQL se adapta mejor a tipos específicos de aplicaciones y casos de uso selectivo.
¿Se puede fragmentar Nosql?
La partición por un patrón de microservicios se usa en entornos NoSQL. El patrón implica dividir cada partición en varios servidores, que pueden o no estar ubicados en la misma ubicación en todo el mundo. Este escalado horizontal funciona bien para personas de todo el mundo que desean acceder a diferentes partes del conjunto de datos y lograr un alto rendimiento.
¿Qué es la replicación en una base de datos?
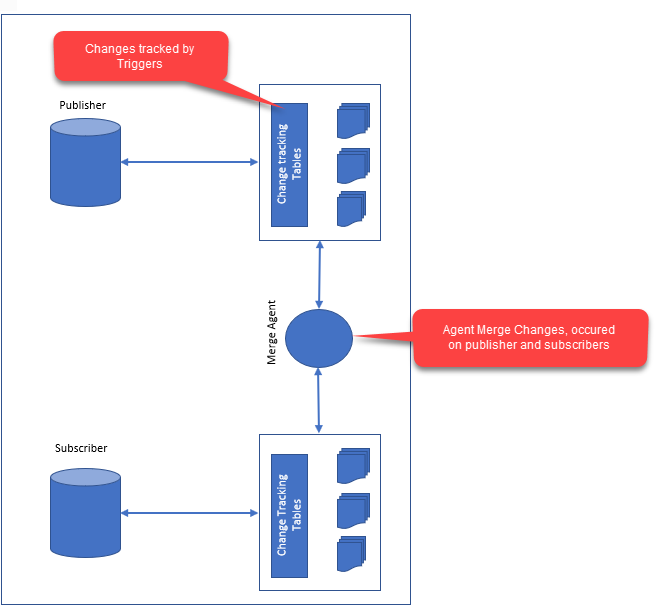
La replicación en una base de datos es el proceso de copiar datos de una base de datos de origen a una base de datos de destino. Las dos bases de datos pueden estar en el mismo servidor o en servidores diferentes. La replicación se puede utilizar para crear una copia de seguridad de los datos, distribuir datos a varios servidores o permitir que varios usuarios accedan a los datos.
La integridad y el rendimiento de los datos son aspectos críticos de la replicación de datos en la actualidad . Reescribir datos puede ser tan simple como enviarlos a un suscriptor o tan complicado como realizar varios experimentos a la vez. La forma más común de replicación es la replicación de instantáneas. Cuando hay una gran cantidad de datos o si el suscriptor es remoto, le envía el conjunto de datos completo. Es una forma de replicación más avanzada que la replicación transaccional. En algunos casos, envía modificaciones de datos solo al suscriptor o los datos, lo que puede ser beneficioso en archivos pequeños o locales. Esta es una técnica de replicación más compleja. Los elementos se pueden modificar tanto en el publicador como en el suscriptor, lo que puede ser útil en situaciones en las que los datos son grandes o el publicador y el suscriptor son remotos. La replicación de datos heterogéneos es así posible para acceder a una variedad de productos de bases de datos. Esto es especialmente útil para datos que son grandes y tienen varios tipos de máquinas, como editores y suscriptores.
¿Qué se entiende por replicación en Mongodb?
Una replicación MongoDB es un método para replicar el conjunto de datos de varios servidores MongoDB. Puede lograr esto mediante el uso de un conjunto de réplicas. Un conjunto de réplicas es una colección de instancias de MongoDB que sirven el mismo conjunto de datos de MongoDB y están asociadas con el mismo proceso.
Al crear un conjunto de réplicas, el nodo principal se elige automáticamente. Cuando esté disponible, el nodo secundario será el nodo principal, con la designación de conjunto de réplicas más alta. El conjunto de replicación de MongoDB especifica las funciones de los nodos principal y secundario y, si ambos nodos están disponibles, MongoDB configura automáticamente el nodo principal. Es una colección de instancias de MongoDB que son idénticas en términos de conjuntos de datos y procesos. Los administradores de bases de datos pueden ofrecer redundancia de datos mediante la replicación de datos. Los datos están ampliamente disponibles. Un conjunto de réplicas es una colección de nodos MongoDB organizados en grupos para la replicación. Un conjunto de replicación debe tener al menos tres nodos MongoDB: uno de los tres nodos se considera el nodo principal responsable de recibir todas las operaciones de escritura. Cuando se crea el primer conjunto de réplicas, el nodo principal se elige automáticamente.