
Bases de datos NoSQL: fragmentación y replicación
Publicado: 2022-11-21Las bases de datos NoSQL se utilizan a menudo para el almacenamiento de datos a gran escala debido a su capacidad de escalar horizontalmente. Esto significa que pueden escalar agregando más nodos al sistema, en lugar de actualizar el hardware de un solo nodo. Una forma en que pueden lograr esta escalabilidad horizontal es a través de la fragmentación, que es un proceso de distribución de datos a través de múltiples nodos. La replicación es otra forma en que las bases de datos NoSQL pueden escalar e implica la creación de copias de datos en múltiples nodos.
Tanto en las bases de datos SQL como en las NoSQL, el concepto de fragmentación de la base de datos es fundamental para el escalado. La base de datos se divide en varios fragmentos (fragmentos) como sugiere el nombre.
También puede usar la replicación de datos NoSQL para asegurarse de no perder datos cuando un servidor falla copiando y almacenando sin problemas sus datos estructurados, no estructurados y semiestructurados. Puede obtener más información sobre las bases de datos NoSQL visitando esta página.
Una base de datos relacional se puede particionar utilizando el método Sharding, también conocido como partición horizontal. Amazon Relational Database Service ( Amazon RDS ) es un servicio de base de datos relacional administrado que facilita su uso en la nube al proporcionar una variedad de características.
Un método de replicación copia datos de varios servidores y los coloca en una ubicación donde se pueden encontrar. En la replicación, se crean copias maestras y esclavas, las copias maestras se convierten en copias autorizadas que manejan datos escritos y las copias esclavas se convierten en copias asíncronas que manejan datos escritos.
¿Nosql usa fragmentación?
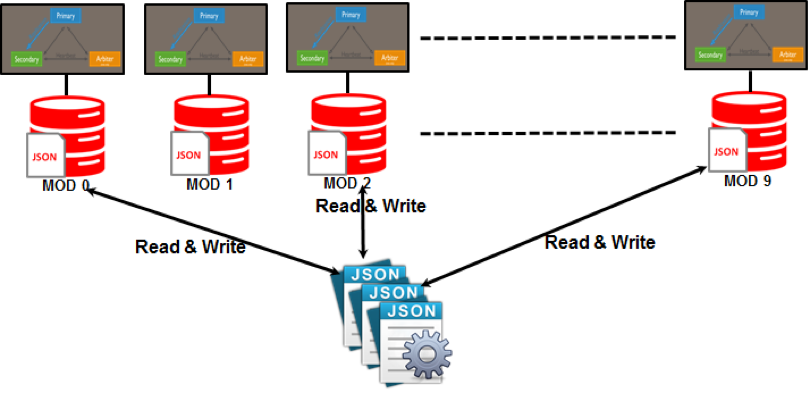
Los patrones de partición, como compartir, se utilizan en NoSQL. El particionamiento es un proceso que asigna cada partición a un servidor que probablemente sea independiente del resto de la red. Con este escalamiento horizontal, puede proporcionar a los usuarios globales acceso a un conjunto diverso de datos mientras mantiene el nivel de rendimiento lo más alto posible.
MySQL Cluster es la solución. MySQL Cluster es un conjunto de software que fragmenta automáticamente las tablas en los nodos y permite que las bases de datos se escalen horizontalmente en hardware básico de bajo costo para atender cargas de trabajo intensivas de lectura y escritura utilizando SQL, así como también directamente a través de API NoSQL. MySQL Cluster tiene el potencial de usarse para mucho más que solo cadenas de bloques. También se puede usar para escalar sus aplicaciones usando MySQL Cluster. La razón de esto es que MySQL Cluster es un sistema de programación. Como resultado, puede escalar sus aplicaciones decidiendo cuándo y cómo se generarán los fragmentos. Esta es una gran ventaja porque no necesita depender de la computación en la nube . Esto se debe al hecho de que los fragmentos se producen en los nodos donde se ejecuta la carga de trabajo. Como resultado, puede controlar cuánta simultaneidad se requiere. Como resultado, MySQL Cluster tiene un conjunto de funciones muy potente. Se puede utilizar para escalar sus aplicaciones y controlar cuánta concurrencia necesita.
¿Qué es fragmentación y replicación en Nosql?
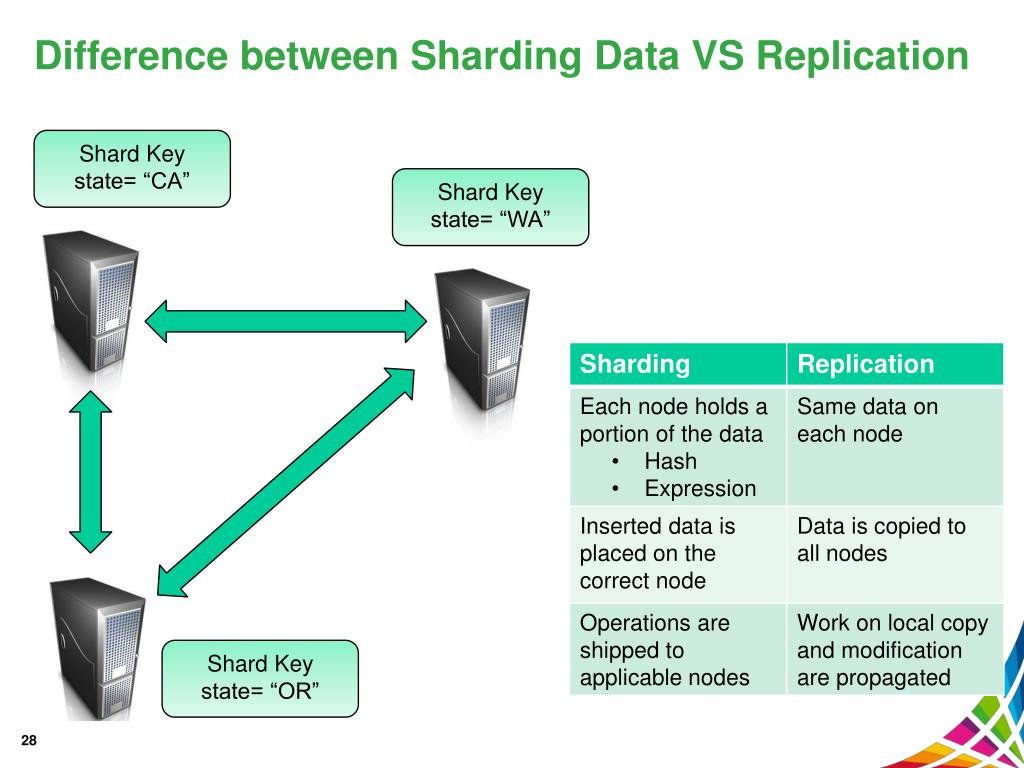
¿Cuál es la diferencia entre replicación y fragmentación? La replicación de datos es el acto de transferir datos desde el nodo del servidor primario a los nodos del servidor secundario . Como respaldo en caso de que falle el servidor principal, esto puede ayudar a garantizar que los datos estén disponibles. Esta función se puede usar para escalar servidores horizontalmente usando una clave de fragmento.
Las ventajas de la fragmentación
Cuando se trata de datos que deben particionarse pero carecen de los recursos para replicarlos, el espaciado puede ser beneficioso en una variedad de situaciones. Cuando necesita escalar las lecturas, la replicación es útil, pero las escrituras de datos se pueden manejar de manera más eficiente con la fragmentación. Elegir la clave de fragmento incorrecta puede tener un impacto negativo en el rendimiento del sistema.
¿Mongodb usa fragmentación?
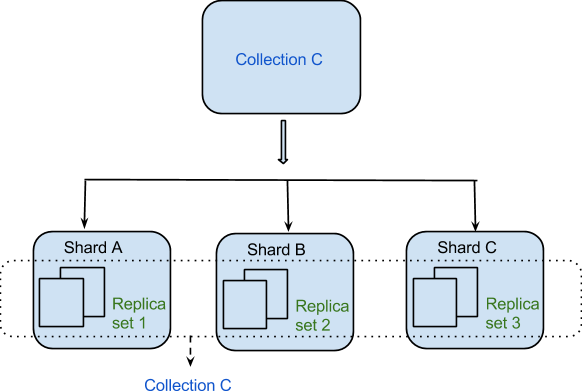
Los datos se distribuyen entre las máquinas de manera distribuida en virtud de Sharding. MongoDB emplea fragmentación para admitir implementaciones a gran escala que requieren un alto nivel de rendimiento. Puede ser difícil construir un servidor único para un sistema de base de datos con una gran cantidad de conjuntos de datos o una aplicación de alto rendimiento.
La estrategia más común para resolver problemas de fragmentación a distancia es abordarlo en su sentido más general. El nodo raíz del clúster tiene una cantidad predeterminada de fragmentos que se pueden dividir en función de su distancia desde el centro de datos del clúster. El nodo principal se denomina nodo raíz porque es el primer nodo que se crea en el conjunto de datos. Otro tipo de fragmento se denomina fragmento secundario. Una transacción a distancia o hash es posible. El valor de la clave hash de un fragmento específico determina la cantidad de datos que puede generar. La clave hash crea un identificador para cada dato en una transacción. Existen numerosas ventajas y desventajas para cada estrategia. Es más sencillo implementar Fragmentación de rango cuando el conjunto de datos es pequeño, a diferencia de un conjunto grande, y es más eficiente cuando es pequeño. Cuando el conjunto de datos es grande, el hashing es más eficiente. La reputación de velocidad de MongoDB se deriva del hecho de que admite la delegación de datos a otros servicios de MongoDB. Los fragmentos de conjuntos de datos se pueden distribuir entre varios servidores en MongoDB para mejorar la velocidad de procesamiento de datos. MongoDB admite múltiples opciones de replicación además de fragmentación. Como resultado, la replicación permite distribuir un conjunto de datos entre varios servidores para mantener la coherencia. La replicación de datos es necesaria si desea asegurarse de que la información sea siempre precisa y actualizada. Además, los clústeres dispersos en MongoDB pueden resultar útiles para mejorar el rendimiento. Sraving es una técnica para transferir grandes cantidades de datos de un servidor a otro de la misma manera que lo es la replicación. Una clave de fragmento es un elemento de datos que se puede copiar (o "fragmentos") de un servidor a otro. Los dos métodos principales para distribuir datos entre clústeres fragmentados en MongoDB están basados en rango y distribuidos. El hash se puede hacer usando un servidor encriptado. Al dividir las cosas, puedes lograr más de una cosa.

¿Debe fragmentar su Mongodb?
No es seguro si la fragmentación mejora o no el rendimiento en algunos casos, pero se ha demostrado que aumenta el rendimiento en algunos casos. Además, como resultado, la fragmentación presenta su propio conjunto de desafíos, como garantizar copias de seguridad y restauraciones sólidas. Antes de decidirse por una estrategia de fragmentación, debe pensar en los pros y los contras de hacerlo.
Fragmentación en Nosql
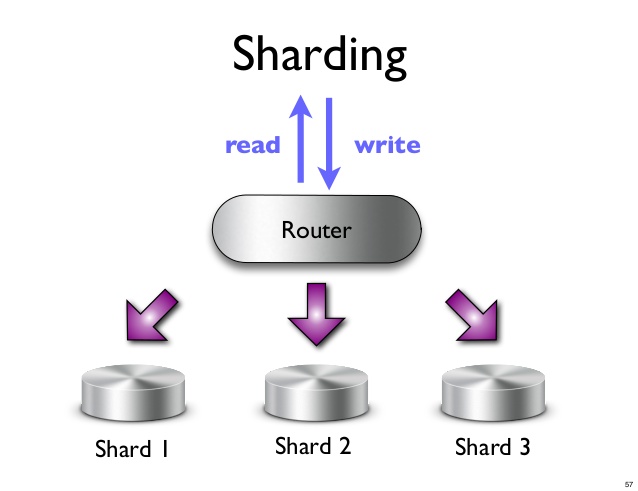
Un fragmento es una partición horizontal de datos en una base de datos o motor de búsqueda. Cada fragmento es una base de datos independiente o una instancia de motor de búsqueda. En una base de datos NoSQL, una colección de documentos se puede dividir en fragmentos, cada uno de los cuales se almacena en un servidor independiente.
Fragmentación frente a replicación
La distinción entre replicación y fragmentación es que la replicación es la duplicación de datos, mientras que la fragmentación es la división de datos en fragmentos discretos. En este caso, ha dividido su colección en varias partes en función de la fragmentación. La recuperación de su base de datos produce imágenes de todos sus conjuntos de datos.
Los beneficios de la fragmentación
Los datos se dividen en varias máquinas para aumentar el número de usuarios simultáneos y mejorar el rendimiento. Los datos se almacenan en particiones separadas en cada una de las máquinas.
Replicación en Nosql
Hay algunas formas diferentes de manejar la replicación en una base de datos NoSQL. Una forma es que la base de datos se replique automáticamente en un servidor secundario cada vez que se realice un cambio. Esto garantiza que siempre haya una copia de seguridad disponible en caso de que el servidor principal se caiga. Otra forma es replicar manualmente los datos en un servidor secundario de forma regular. Esto le da al administrador más control sobre cuándo ocurre la replicación, pero también significa que existe la posibilidad de que el servidor secundario no esté actualizado en caso de falla.
¿Qué es la fragmentación en la base de datos?
Sharding es un proceso de partición horizontal de datos en una base de datos. En fragmentación, una base de datos se divide en partes más pequeñas, llamadas fragmentos. Cada fragmento se almacena en un servidor separado. El proceso de fragmentación ayuda a mejorar el rendimiento de una base de datos mediante la distribución de la carga entre varios servidores.
Una sola pieza de datos se puede replicar en una sola transacción con la ayuda de la fragmentación. Como resultado de dividir un conjunto de datos en piezas más pequeñas y distribuirlas entre varios servidores, se puede aumentar la capacidad de almacenamiento general del sistema. En algunos casos, esto podría ser útil si los datos son grandes y requieren varios servidores para mantenerlos. Los envoltorios de datos externos también se utilizan para leer datos de servidores remotos, lo que brinda aún más flexibilidad al almacenamiento de datos.
¿Cuál es la diferencia entre particionar y fragmentar?
Partitioning y Sharding son dos enfoques para estructurar grandes colecciones de datos en pequeños fragmentos. Tanto la fragmentación como la partición significan que los datos se distribuyen en varias computadoras, pero son distintas. El procedimiento para particionar una instancia de base de datos implica agrupar subconjuntos de datos dentro de ella.
¿Qué base de datos es mejor para fragmentar?
La fragmentación de bases de datos es compatible con Cassandra, HBase, HDFS, MongoDB y Redis. Las bases de datos que no admiten de forma nativa PostgreSQL, Memcached, Zookeeper, MySQL y Sqlite se consideran bases de datos. La lógica de Jarryd debe estar presente en una aplicación si no tiene soporte integrado para bases de datos.
¿Es posible fragmentar en Sql?
Sin embargo, es posible implementar fragmentación basada en rango (esencialmente horizontal), de una manera que lo haga más transparente para la aplicación. La forma típica de hacer esto en SQL Server es a través de una vista dividida, pero este no tiene por qué ser el caso.