
Bases de datos NoSQL: bases de datos a escala web para grandes volúmenes de tráfico y grandes conjuntos de datos
Publicado: 2022-11-18Las bases de datos Nosql son bases de datos a escala web que pueden manejar un alto tráfico y grandes conjuntos de datos. Están diseñados para ser escalables y manejar cargas elevadas. Una base de datos nosql se puede escalar horizontalmente agregando más servidores al sistema. Esto permite que el sistema maneje más tráfico y almacene más datos.
El aumento de la demanda de aplicaciones complejas requiere una mayor flexibilidad. Es igualmente importante seleccionar almacenes de datos que sean fáciles de escalar y ejecutar de manera eficiente. El problema más importante es si las bases de datos 'ASL' o 'NoSQL' son mejores para ejecutar una aplicación. Las bases de datos SQL se han utilizado durante bastante tiempo, pero se sabe que las bases de datos NoSQL son más fáciles de escalar. Para las bases de datos NoSQL, se supone que la fragmentación debe realizarse en todas las operaciones. Un nodo se puede identificar mediante una función de calificación, que se espera de cada operación de datos en la base de datos. Debido a que los datos se almacenan en varias máquinas, es muy eficiente manejar operaciones de datos incluso en las máquinas más básicas.
Con esta función, se pueden usar máquinas básicas simples para escalar las tiendas NoSQL. NoSQL asume que el usuario puede planificar y estructurar los datos para que solo se recuperen del mismo nodo en un momento determinado para cualquier operación determinada. Además, se puede realizar la desnormalización de datos entre nodos (datos precocinados para el inicio). Hay un lugar para las uniones NoSQL, pero no espere que sean ricas en SQL u optimizadas. En la práctica, se supone que los datos siempre serán coherentes con las aplicaciones NoSQL. Existen numerosos sistemas NoSQL que proporcionan conmutadores para modificar la coherencia a lo largo del tiempo si la coherencia es importante. El objetivo de cualquier decisión de arquitectura, como el objetivo de evaluar el caso de uso, es seleccionar el almacén de datos apropiado.
Un grupo de recursos de escalamiento horizontal se puede expandir al agregarle más máquinas, mientras que un grupo de escalamiento vertical se puede expandir al agregarle más máquinas.
Las bases de datos SQL y las bases de datos NoSQL usan el escalado vertical debido a la forma en que se almacenan los datos (tablas relacionadas versus colecciones no relacionadas), mientras que las bases de datos NoSQL usan el escalado horizontal porque no usan tablas relacionadas.
El tipo de escalado admitido por NoSQL es horizontal.
Para escalar horizontalmente, MongoDB emplea un mecanismo integrado que le permite mover datos entre varios servidores. Este proceso se conoce como fragmentación y puede realizarlo presionando un botón de alternar en la página de configuración de la interfaz de usuario de Atlas. Aparte de eso, el proceso también se puede completar sin tiempo de inactividad.
¿Cómo funciona el escalado horizontal en Nosql?
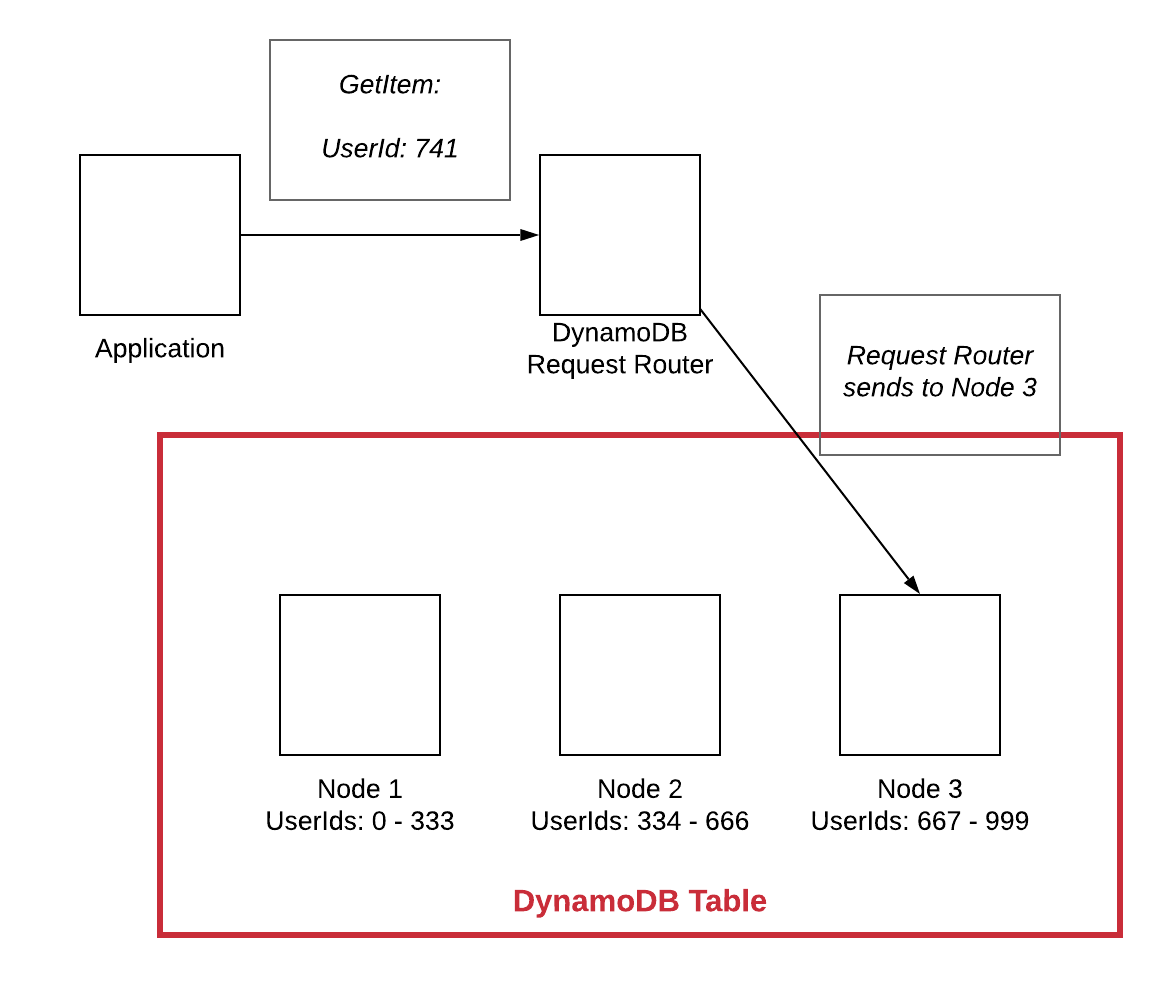
El escalado horizontal en una base de datos NoSQL significa que la base de datos se puede escalar agregando más máquinas al sistema, en lugar de hacer que una sola máquina sea más rápida o más poderosa. Esto permite que el sistema maneje más tráfico y datos sin tener problemas de rendimiento.
Las ventajas del escalado horizontal son numerosas: puede agregar fácilmente más servidores para manejar el aumento del tráfico y no tendrá que preocuparse por cargar filas de varios servidores al mismo tiempo. Como resultado, las bases de datos NoSQL son excelentes opciones para las empresas que desean almacenar datos bajo demanda mientras ahorran dinero en el almacenamiento de datos .
Las bases de datos Nosql son mejores para manejar grandes conjuntos de datos
Debido a las limitaciones de las bases de datos relacionales , no pueden manejar grandes conjuntos de datos. Las bases de datos NoSQL, como MongoDB, almacenan sus datos en un formato de documento autónomo, lo que le permite distribuir sus datos en varios nodos. Con esta función, la base de datos puede manejar grandes conjuntos de datos de forma rápida y sencilla.
¿Cómo puede Mongodb escalar horizontalmente?
MongoDB puede escalar horizontalmente usando fragmentación. La fragmentación es un proceso de división de datos en varios servidores. Cada servidor tiene su propia porción del conjunto de datos y los datos se distribuyen uniformemente entre los servidores. Cuando se realiza una solicitud, el servidor MongoDB determinará qué servidor tiene los datos que se solicitan y los recuperará de ese servidor. Este proceso permite a MongoDB escalar horizontalmente y manejar grandes cantidades de datos.
Cuando se trata de escalar la infraestructura, muchas empresas descubren que están pasando por un momento difícil. La plataforma de base de datos como servicio MongoDB admite una amplia gama de opciones de escalado y está integrada en su backend. La técnica de escalar horizontalmente se conoce como fragmentación (porque es la preferida). El término "escalado en niveles" se refiere a la capacidad de un solo servidor o clúster para escalar en dirección ascendente. Es un método de escalado horizontal que implica la distribución de datos a través de múltiples nodos. La plataforma MongoDB Atlas configura automáticamente una clave de fragmento, que aún depende de nosotros. Está claro que los conjuntos de réplicas y la fragmentación son similares, pero los conjuntos de datos no son los mismos.
Además, pueden causar problemas con grandes cantidades de transacciones de escritura para aplicaciones. MongoDB Atlas también admite el escalado horizontal y vertical. La implementación de un clúster fragmentado permite el escalado horizontal. En pocas palabras, el escalado vertical es tan simple como configurar un nivel de clúster. En el caso de un apagado completo, el clúster se puede pausar para mantener el clúster en 0, escalando efectivamente todo el clúster a 0 excepto el almacenamiento.
MongoDB es una excelente base de datos NoSQL, ya que es una aplicación moderna que necesita escalar horizontalmente para manejar grandes conjuntos de datos. MongoDB tiene una API simple que facilita a los desarrolladores el acceso y la manipulación de datos, y su almacenamiento sin esquema facilita el almacenamiento y la recuperación de datos. Además, debido a que MongoDB admite la replicación, los datos se pueden replicar fácilmente en varios servidores, lo que garantiza que permanezcan disponibles para uso futuro.
Escalabilidad de Mongodb
MongoDB es uno de los lenguajes de programación más elásticos. En una base de datos orientada a documentos como MongoDB, los datos se almacenan en documentos similares a JSON. El proceso de MongoDB se escala horizontalmente mediante el uso de fragmentación. Srave es una técnica de distribución de datos que utiliza varias colecciones y máquinas para distribuir datos entre bases de datos y máquinas.
¿Sql Db es escalable horizontalmente?
En el escalado horizontal, las bases de datos se agregan o eliminan para realizar una tarea específica, como aumentar o disminuir la capacidad o el rendimiento general. El escalado horizontal generalmente se implementa combinando datos de varias bases de datos estructuradas de forma idéntica y luego separándolos en tablas separadas.
Cada base de datos, todos los días, debe escalarse para manejar el volumen de datos generado. El escalado se clasifica en dos tipos: vertical y horizontal. La memoria de un servidor de 2 TB es suficiente para almacenar más datos. Es comprar un servidor grande a un precio extremadamente alto. La adición de más máquinas al servidor se conoce como escalamiento horizontal. Su objetivo es dividir el conjunto de datos en varios servidores o fragmentos. No tendría sentido tener un único punto de verdad basado en la desnormalización. Este enfoque tiene una desventaja: si el maestro no puede actualizar las réplicas esclavas mientras realiza una escritura, el maestro no actualizará las réplicas esclavas.

Una replicación es el acto de intercambiar datos entre nodos en un clúster. Al replicar datos, puede aumentar la disponibilidad y la recuperación de un servidor. Además, la replicación se puede utilizar para distribuir la carga entre varios clústeres de nodos. Una organización puede dividir horizontalmente sus datos en fragmentos más pequeños y distribuir esos fragmentos en varios nodos. La partición horizontal mejora el rendimiento. Hay varios tipos diferentes de clústeres de MongoDB , además de los clústeres de MongoDB predeterminados. El clúster de un solo nodo, en general, es el tipo de clúster más simple y es adecuado para pruebas y desarrollo. Un clúster de dos nodos es el tipo de clúster más común y es adecuado para aplicaciones de mediana a gran escala. Un clúster de tres nodos también es popular y es adecuado para aplicaciones a gran escala. En un clúster de dos nodos, por ejemplo, los datos se dividen en dos fragmentos separados en cada nodo. En este caso, cada nodo tiene una copia de los datos. Cuando la carga de un nodo crece, el otro nodo puede manejar la carga. Un clúster con equilibrio de carga es uno de los tipos más comunes de clústeres. Un clúster de tres nodos se compone de tres centros de datos separados, cada uno de los cuales contiene tres fragmentos separados. Si la carga de un nodo aumenta, los otros dos nodos pueden asumir el control. Un clúster equilibrado es uno de estos clústeres. La base de datos MongoDB es una base de datos moderna basada en documentos con capacidades de escalado horizontal: replicación y partición horizontal (o fragmentación). El proceso de escalado horizontal de una base de datos implica agregar más instancias o nodos para hacer frente a una mayor demanda. Cuando necesite más capacidad, simplemente agregue más servidores al clúster. Además, los servidores suelen ser más pequeños y menos costosos que los que se utilizan para la informática de escritorio. Es un proceso de copia de datos entre nodos en un clúster. La partición de datos los divide horizontalmente en fragmentos más pequeños y los distribuye a través de múltiples nodos en un sistema distribuido. Hay varios tipos de clústeres de MongoDB, cada uno con un conjunto distinto de características. Los clústeres de tres nodos también son comunes, aunque no son tan efectivos como un clúster de cuatro nodos.
Escalar horizontalmente con una base de datos relacional
Una base de datos SQL tradicional normalmente no puede escalar horizontalmente porque necesita albergar más servidores, pero aún podemos agregar réplicas de otras máquinas. El registro de escritura anticipada se utiliza para propagar todas las operaciones de escritura desde el servidor principal a otras máquinas. Debido a la flexibilidad de la sintaxis de consulta, las bases de datos relacionales no pueden escalar horizontalmente. Para garantizar que no se obtengan partes de sus datos hasta que ejecute su consulta, SQL le permite agregar tantas condiciones y filtros a sus datos que es imposible que su base de datos prediga qué partes se recuperarán. Como resultado, la base de datos puede volverse lenta cuando intenta procesar grandes cantidades de datos. Debido a que las bases de datos relacionales pueden escalar horizontalmente, pueden ayudar a cubrir áreas donde Spark suele ser menos efectivo, ya sea actuando como un medio de almacenamiento para Spark Streaming o cálculos por lotes. La plataforma SQL en la nube no admite estas configuraciones de forma nativa, pero se pueden implementar mediante herramientas de la industria como ProxySQL. Sin embargo, el concepto subyacente de Cloud SQL no está diseñado para este tipo de escenarios.
¿Por qué Nosql es escalable horizontalmente?
Las bases de datos NoSQL pueden escalar horizontal o verticalmente según sus requisitos. Puede manejar situaciones de alto tráfico fragmentando su base de datos NoSQL, agregando más servidores al proceso. Las bases de datos NoSQL son la opción preferida para conjuntos de datos grandes y que cambian con frecuencia porque pueden escalar horizontalmente en lugar de verticalmente.
Debería poder manejar bases de datos muy grandes , con tasas de solicitud muy altas, con una latencia muy baja. La escalabilidad y la disponibilidad son requisitos críticos para sitios web de gran volumen como eBay, Amazon, Twitter y Facebook. Cuando tiene la capacidad de ejecutar varias instancias en un servidor al mismo tiempo, la escala horizontal es ideal.
Debido a su escalabilidad y flexibilidad, las bases de datos NoSQL están ganando popularidad en comparación con las bases de datos SQL. Además, funcionan mejor en comparación con las bases de datos basadas en tablas para datos no estructurados, que pueden ser difíciles de procesar y almacenar.
Cómo escalar la base de datos Nosql
No existe una respuesta única para esta pregunta, ya que la mejor manera de escalar una base de datos NoSQL depende de las necesidades específicas de la aplicación y los datos que se almacenan. Sin embargo, algunos consejos sobre cómo escalar una base de datos NoSQL incluyen agregar más nodos al clúster para aumentar la capacidad y el rendimiento, usar fragmentación para distribuir datos en múltiples nodos y replicar datos en múltiples nodos para garantizar una alta disponibilidad.
Se cubren varios puntos importantes a medida que Rahim Yaseen de Couchbase nos guía a través de ellos. Las organizaciones se esfuerzan por administrar, almacenar y monetizar sus enormes cantidades de datos. Una decisión importante de la base de datos es si escalar horizontalmente o no. El registro se distribuye a las cabinas de facturación en fragmentación manual. Esto se logra gracias a un esquema bien definido y predefinido. Como parte de la partición automática, tendría que ir a cada stand para averiguar quién se registró con un apellido que comienza con S. Las bases de datos de documentos tienen patrones de acceso que requieren que los usuarios naveguen a otro documento a través de una clave específica y accedan a los datos a través de un único llave. A medida que crece el tamaño de un conjunto de datos distribuidos, se vuelve cada vez más difícil indexarlo y consultarlo.
No tiene sentido utilizar una técnica de reducción de mapas porque todos los nodos de la consulta deben participar en ella. A medida que aumenta el volumen de datos, la ampliación del modelo RDBMS se vuelve cada vez menos factible. En el caso de un gran conjunto de datos, es probable que la falla de una arquitectura de escalamiento vertical sea un punto de falla muy grande. Internet es un ejemplo de un clúster de ultraescala sin nada compartido.
Bases de datos Nosql: el futuro de la escalabilidad
Debido a que los datos se envían a través de múltiples máquinas en las bases de datos Nosql, son extremadamente escalables. Como resultado, en lugar de comprar máquinas costosas que requieren equipo especializado, podemos agregar potencia de CPU fácilmente. Además, las bases de datos Nosql pueden contener una gran cantidad de datos sin límite, lo que lo convierte en un sistema de gestión de datos muy versátil.
¿Puede la base de datos Sql escalar horizontalmente?
Sí, las bases de datos SQL pueden escalar horizontalmente. Esto significa que se pueden distribuir en varios servidores, cada uno de los cuales maneja una parte de los datos totales. Esto permite una mayor escalabilidad que la que podría proporcionar un solo servidor.
¿Por qué las bases de datos Sql no son escalables horizontalmente?
Debido a la flexibilidad de la sintaxis de consulta, es imposible escalar horizontalmente en una base de datos relacional . Como resultado de SQL, puede agregar cualquier cantidad de condiciones y filtros a sus datos que evitan que el sistema de la base de datos sepa qué partes se devolverán hasta que se complete la consulta.
¿Por qué Sql escala verticalmente?
El objetivo del escalado vertical es aumentar el consumo de energía y la capacidad de RAM de los sistemas existentes, esencialmente aumentando los recursos disponibles. El escalado vertical no solo es más fácil, sino que también es menos costoso. El problema tampoco requiere una solución a largo plazo.