
Pig: una plataforma de alto nivel para Apache Hadoop
Publicado: 2023-02-22Pig es una plataforma de alto nivel para crear programas que se ejecutan en Apache Hadoop. El término “Pig” hace referencia a la capa de infraestructura de la plataforma, que consiste en un entorno de compilación y ejecución, así como un conjunto de operadores de alto nivel. La capa de infraestructura de Pig proporciona un conjunto de herramientas para que los desarrolladores creen, mantengan y ejecuten sus programas Pig. Pig es un proyecto de código abierto que forma parte del ecosistema Apache Hadoop . El modelo de programación de Pig se basa en el flujo de datos, lo que facilita la escritura de programas que procesan grandes cantidades de datos. Los programas Pig están compuestos por una serie de operadores que se ejecutan en un gráfico acíclico dirigido. Pig es una excelente opción para procesar grandes cantidades de datos porque es escalable, eficiente y fácil de usar.
Como solución NoSQL, necesita formas específicas y predefinidas de analizar y acceder a los datos. SQL (UNION, INTERSECT, etc.) es una expresión de consulta común que no se usa con mucha frecuencia en el mundo de los grandes datos. Debido a que Hive está optimizado para el procesamiento por lotes y de big data, es mejor tocar cada fila. Hive gasta mucho menos tiempo y dinero en operaciones que Hadoop, que tiene la ventaja de la escala. Incluso las consultas pequeñas en los sistemas de desarrollo pueden ser ÓRDENES de magnitud más lentas que las consultas similares en RDBMS. Hive no almacena en caché los resultados de las consultas. Volver a enviar una consulta repetida es una práctica común en MapReduce.
Hay dos tipos de Hive: 1) Hive no es una base de datos; más bien, es un motor de consultas que admite partes de SQL específicas para consultar datos b) Hive es una base de datos compatible con SQL c) Hive es una base de datos específica de SQL. Hive es un sistema de almacenamiento de datos basado en SQL para Hadoop que incluye Pig y Python, entre otras cosas; Hive se utiliza para almacenar datos de Hadoop .
¿Es Pig un Sql?
No hay una respuesta correcta o incorrecta a esta pregunta, ya que depende de la opinión personal. Algunas personas pueden creer que pig es un sql, mientras que otras no. En última instancia, depende del individuo decidir si pig es o no un sql.
Hoy, Apache Hive y Pig son dos términos que se están convirtiendo rápidamente en sinónimos de big data. Con estas herramientas, los desarrolladores y analistas de datos pueden usarlas para reducir la complejidad de MapReduce y al mismo tiempo conservar un alto nivel de integridad de los datos. Hive es una infraestructura de almacenamiento de datos que también se conoce como herramienta ETL (extracción, carga y transformación). Apache Hive, Pig y SQL son tres herramientas populares para el análisis y la gestión de datos. Debe saber qué plataforma será la mejor para sus necesidades y con qué frecuencia debe usarla. Veamos las tres formas diferentes de usar Hive, Pig y SQL en el contexto de estas tres tecnologías. SQL sigue siendo el rey de la gestión y el análisis de big data, a pesar del dominio de Apache Hive y Apache Pig. Debido a que cada uno realiza una función específica, sus requisitos se adaptan al negocio. Apache Pig se basa en scripts y requiere conocimientos especiales, mientras que Apache Hive es la única solución de base de datos nativa para el desarrollador.
El cerdo es un animal versátil con una gran flexibilidad. Pig, por ejemplo, puede procesar archivos de registro que contienen datos JSON o XML, lo que le permite leer los datos. También es posible almacenar datos de servicios web en Pig.
Los tipos de datos de mapas, tuplas y tipos de datos de bolsas se pueden usar indistintamente. Son capaces de manejar datos de cualquier fuente.
¿Es Pig una herramienta Etl?
No hay una respuesta definitiva a esta pregunta, ya que depende de cómo defina una herramienta ETL. En términos generales, una herramienta ETL es una aplicación de software que lo ayuda a extraer datos de una o más fuentes, transformarlos en un formato que sea compatible con su sistema de destino y cargarlos en ese sistema. Algunas personas dirían que pig es una herramienta ETL porque puede realizar todas estas funciones. Otros podrían argumentar que pig no es una herramienta ETL porque no está diseñada específicamente para la transformación de datos. En última instancia, la respuesta a esta pregunta depende de su propia definición de una herramienta ETL.

¿Cómo puede usar Pig para el procesamiento de Etl?
Una aplicación Pig se puede describir como un modelo de transacción ETL, que describe cómo un proceso extrae datos de un objeto y los transforma en un almacén de datos basado en un conjunto de reglas. Los usuarios definen las funciones definidas por el usuario (UDF) del cerdo para ingerir datos de archivos, flujos y otras fuentes.
¿Qué es la herramienta de cerdo?
Una plataforma o herramienta conocida como Pig procesa grandes conjuntos de datos. Esta biblioteca contiene un alto nivel de abstracción para procesar datos en el proceso MapReduce. Pig Latin es un lenguaje de secuencias de comandos de alto nivel que se utiliza en el proceso de codificación para desarrollar los códigos de análisis de datos.
¿Cuál es la diferencia entre cerdo y Sql?
SQL Pig Latin y Apache Pig son lenguajes de procedimiento. SQL es un lenguaje de secuencias de comandos de naturaleza declarativa. Depende totalmente de Apache Pig si se usa o no el esquema. Los datos se pueden almacenar sin necesidad de un esquema (los tipos de valor se almacenan en $, $, etc.).
¿El cerdo es parte de Hadoop?
Una aplicación Pig Hadoop es un lenguaje de programación de alto nivel que se puede utilizar para analizar conjuntos de datos masivos. El proyecto Pig Hadoop de Yahoo! fue uno de los primeros proyectos de Hadoop . En general, realiza una cantidad significativa de trabajo de administración de datos cuando se ejecuta Hadoop.
En el campo del análisis de grandes datos, Pig Hadoop es un lenguaje de programación de alto nivel. Para analizar datos usando Apache Pig, primero debemos escribir scripts usando Pig Latin. scripts que se transformarán en tareas de MapReduce . Esto se logra utilizando Pig Engine, una extensión de Apache Pig. Siguiendo los pasos a continuación, puede instalar Apache Pig en Linux/CentOS/Windows (a través de VM o Cloudera). El primer paso es descargar e instalar Apache Pig. El segundo paso es cambiar las variables de entorno de Apache Pig usando el archivo bashrc.
En el paso 3, determine la versión de Pig . Este archivo se puede guardar en otro directorio después de moverlo. El quinto paso es iniciar Grunt Shell (el script utilizado para ejecutar Pig Latin) haciendo clic en el comando Pig.
Por qué Pig Latin es el mejor lenguaje de secuencias de comandos de alto nivel para el análisis de datos
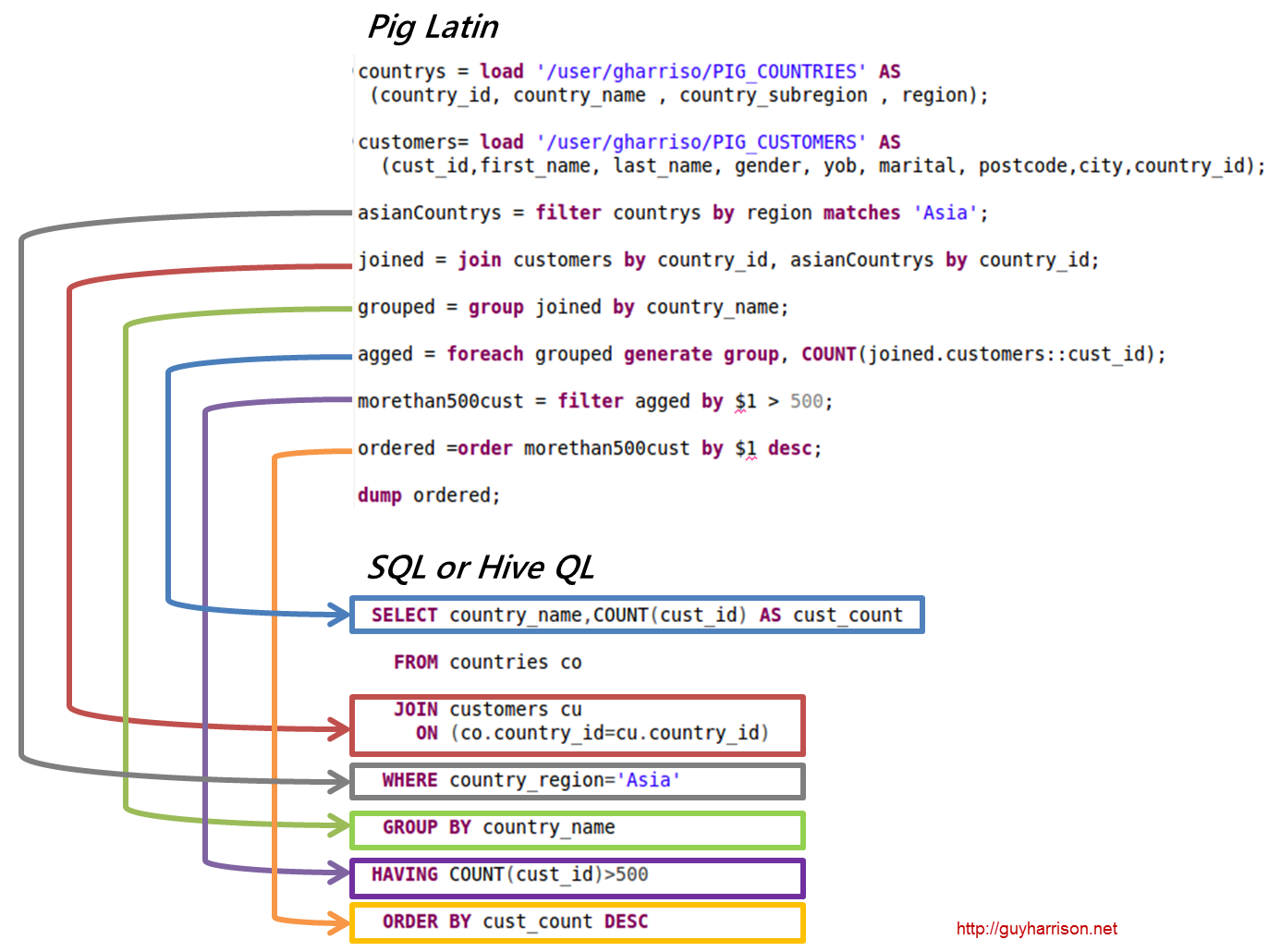
El código de análisis de datos de Pig Latin está escrito en un lenguaje de secuencias de comandos de alto nivel. Es un lenguaje similar a SQL que está destinado a procesar flujos de datos en paralelo.
Ejemplo de Apache Pig
Pig es una plataforma de alto nivel para crear programas que se ejecutan en Apache Hadoop. El idioma de esta plataforma se llama Pig Latin. Pig puede ejecutar sus trabajos de Hadoop en MapReduce, Tez o Spark. Pig Latin abstrae la programación del lenguaje Java MapReduce en una notación que facilita la programación de MapReduce. Por ejemplo, la siguiente instrucción Pig Latin es equivalente al código Java MapReduce anterior: A = LOAD 'mydata' USING PigStorage(',') AS (id:int, name:chararray, age:int, gpa:float); VOLCAR A;