
Escalar una base de datos NoSQL: consejos y trucos
Publicado: 2022-11-18Las bases de datos NoSQL son cada vez más populares a medida que la cantidad de datos generados por las empresas continúa creciendo exponencialmente. Sin embargo, muchas organizaciones son reacias a cambiar a NoSQL porque temen que sea más difícil de escalar. Escalar una base de datos NoSQL en realidad no es tan diferente de escalar una base de datos relacional. La principal diferencia es que las bases de datos NoSQL están diseñadas para ser escalables horizontalmente, lo que significa que pueden escalar agregando más nodos al sistema. Esto contrasta con las bases de datos relacionales , que son escalables verticalmente, lo que significa que solo pueden escalar agregando más recursos a un solo servidor. Hay algunas cosas a tener en cuenta al escalar una base de datos NoSQL: 1. Asegúrese de que sus datos estén distribuidos uniformemente en todos los nodos. 2. Agregue nodos gradualmente para evitar sobrecargar el sistema. 3. Monitoree de cerca el desempeño del sistema para identificar cualquier cuello de botella. 4. Sintonice el sistema periódicamente para garantizar un rendimiento óptimo. Con estos consejos en mente, escalar una base de datos NoSQL no debería ser más difícil que escalar una base de datos relacional.
Existen numerosos métodos y principios para escalar una base de datos, dependiendo de su tipo. El escalado de las bases de datos NoSQL y sql depende del concepto de fragmentación de la base de datos. Los beneficios de poder almacenar más datos se acumulan cuando los servidores se distribuyen, pero también heredamos los problemas que conlleva la distribución. La fragmentación automática no es compatible con una base de datos monolítica y los ingenieros tendrían que escribir manualmente la lógica para manejarla. Para resolver este problema, se puede instalar un proxy, como un equilibrador de carga, frente al servicio de consultas y la base de datos. Podemos obtener consultas más rápidas cuando el fragmento es grande porque ese proxy se puede usar una vez más. Debido a que los usuarios finales no lo saben, el escalado de las bases de datos NoSQL es prácticamente invisible.
Cada fragmento es único, a diferencia de una arquitectura maestro-esclavo. Si hay consultas de lectura en el fragmento maestro, se enviará una solicitud a los fragmentos esclavos. A nivel del centro de datos, podemos replicar la base de datos para asegurarnos de tener una copia de seguridad. El Nodo es un nodo que puede comunicarse e intercambiar información con otros nodos. Cada nodo se comunica con un número fijo de otros nodos a través de un protocolo. Debido a que todos los nodos son iguales en Cassandra, un nodo puede replicar sus datos de uno a otro sin tener que preocuparse por perder datos. El protocolo de chismes es una de las muchas formas en que los nodos pueden compartir información.
Una base de datos distribuida puede tener una serie de ventajas además de obtener propiedades adicionales. Un componente crítico para garantizar la disponibilidad es la replicación de datos. Cuando utiliza la replicación asíncrona para su base de datos, no siempre será completamente consistente al principio, pero lo será más a medida que pase el tiempo. Las bases de datos SQL se utilizan en aplicaciones financieras que requieren datos de alta precisión, mientras que las bases de datos NoSQL se utilizan en aplicaciones menos importantes, como el recuento de visualizaciones.
El escalado vertical se refiere al proceso de aumentar gradualmente la carga de trabajo informática con el uso de actualizaciones de hardware. Pasar a una arquitectura distribuida y agregar más computadoras para resolver nuestro problema implica escalar, también conocido como escalado horizontal o scaling out.
NoSQL puede admitir el escalado basado en métodos horizontales.
MongoDB, como base de datos NoSQL, es escalable porque sus datos no se almacenan en bases de datos relacionales. Los datos se almacenan como documentos similares a JSON a los que se puede acceder fácilmente a través de una solicitud HTTP. La distribución de documentos se puede realizar horizontalmente en varios nodos utilizando este método.
¿Cómo se escala la base de datos Nosql?
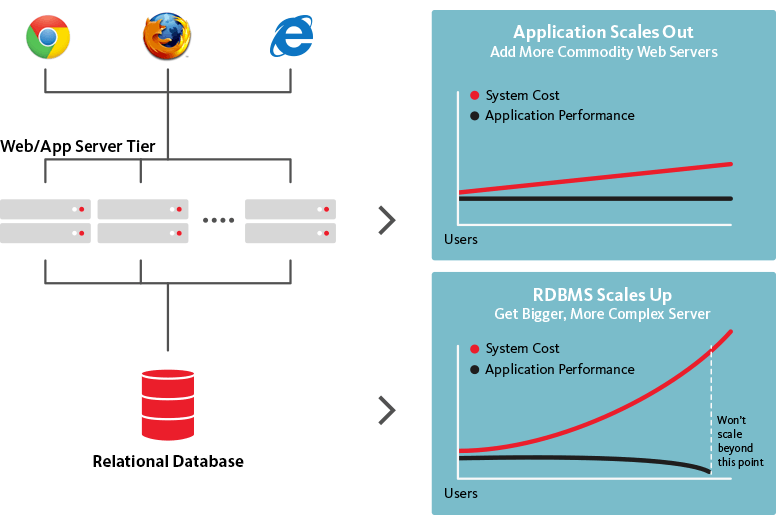
Las bases de datos NoSQL, por otro lado, son escalables horizontalmente, lo que significa que pueden manejar un mayor tráfico según sea necesario simplemente agregando más servidores a la base de datos. Debido a que las bases de datos NoSQL se pueden transformar en estructuras mucho más grandes y poderosas, es la opción lógica para grandes conjuntos de datos y bases de datos en constante evolución.
Para que este tutorial funcione, debe tener un entorno Node.js en funcionamiento. En esta publicación, descomprimiré los archivos de DynamoDB en una carpeta llamada nodejs-dynamodb-sample. Para obtener una versión detallada de esto, vaya a mi página de GitHub: https://www.gofundme.com/adamfowleruk/nodesurvey.html. La aplicación de muestra puede buscar y recuperar información de películas de DynamoDB. Almacenaremos datos en S3 en Amazon Web Services y accederemos a DynamoDB a través del servicio de administración de acceso e identidad (IAM) de Amazon. Para utilizar el servicio In-App Analytics de Amazon, primero debe registrarse y crear una cuenta. Tome nota del año y el título de cada película que desea PUBLICAR /películas.
Puede ingresar un campo con clave para buscar películas de un año determinado. Después de eso, puede diseñar su propia aplicación desde cero. Puede usar sus tablas hasta que las haya terminado, pero debe eliminarlas una vez que las haya usado. Visite la consola de DynamoDB en Amazon Web Services para ver cuánto almacenamiento ha utilizado hasta ahora. La pestaña "Películas" le permite ver los elementos en una tabla y las métricas de su aplicación, así como el costo mensual estimado por mes en la pestaña Capacidad. Este código se puede encontrar en mi página de GitHub: https://github.com/adamfowleruk/nodejs-dynamodb-sample.
MongoDB, Apache HBase y Cassandra son tres bases de datos NoSQL ideales para escalar horizontalmente. Debido a que sus estructuras de datos son más horizontales, esto facilita agregar más servidores al sistema, al mismo tiempo que elimina la necesidad de cambiarlos. Además, estas bases de datos son relativamente nuevas, por lo que todavía se están desarrollando y refinando, lo que significa que es probable que mejoren con el tiempo.
¿Por qué es fácil escalar Nosql?
Nosql es fácil de escalar porque está diseñado para ser escalable horizontalmente. Esto significa que puede escalar agregando más nodos a un clúster nosql . Nosql también es fácil de escalar porque puede manejar grandes cantidades de datos y un gran número de consultas por segundo.

Las aplicaciones requieren un alto nivel de escalabilidad para funcionar correctamente. Elegir almacenes de datos con una interfaz de usuario simple y eficiente es igualmente importante. El principal punto de discusión es si es mejor usar una base de datos 'ASL' o 'Nosql'. Las bases de datos NoSQL, a diferencia de las bases de datos SQL, son populares porque son fáciles de construir. Detener todas las operaciones en una base de datos NoSQL depende inherentemente de la fragmentación. En general, cada operación de datos requiere el uso de un operador calificador, que se puede usar para identificar un nodo con los datos. Los datos se almacenan en varias máquinas y esto hace que sea muy sencillo realizar operaciones de datos incluso en las máquinas más pequeñas.
Como resultado, las tiendas NoSQL pueden escalar para usar una máquina básica relativamente simple. Se supone que los usuarios planificarán y estructurarán los datos de tal manera que puedan obtenerse de una sola vez desde el mismo nodo para realizar una operación específica en la base de datos NoSQL. Desnormalizar los datos de esta manera también podría implicar que el nodo está listo para ejecutar datos precocinados. Las uniones en NoSQL son posibles, pero no son tan sólidas como las uniones SQL. En el mundo práctico de NoSQL, los diseñadores de aplicaciones creen que eventualmente se logrará la consistencia de los datos. Además de proporcionar interruptores para ajustar la coherencia entre diferentes sistemas NoSQL, muchos sistemas NoSQL proporcionan rutinas para que la coherencia parezca más destacada. Una parte importante de cualquier decisión de arquitectura es evaluar el caso de uso y elegir el almacén de datos adecuado en función de ese caso.
¿Todas las bases de datos Nosql son escalables?
Como resultado de la era de Internet y la computación en la nube, se han creado bases de datos NoSQL para facilitar la implementación de una arquitectura escalable. la escalabilidad se logra al combinar el almacenamiento de datos con el trabajo requerido para procesarlos en una gran cantidad de computadoras en una arquitectura escalable.
El sistema debe ser capaz de manejar bases de datos extremadamente grandes con una latencia muy baja y al mismo tiempo manejar tasas de solicitud muy altas. Cuando se trata de sitios web de gran volumen como eBay, Amazon, Twitter y Facebook, la escalabilidad y la alta disponibilidad son fundamentales. Puede ejecutar varias instancias de un servidor al mismo tiempo con escalado horizontal.
La base de datos de MongoDB es escalable tanto horizontal como verticalmente tanto en escala como en número de usuarios. En MongoDB, puede escalar su clúster vertical u horizontalmente agregando más recursos y dividiendo sus datos en partes más pequeñas. Como resultado, MongoDB es una opción popular para aplicaciones y almacenes de datos a gran escala .
Las mejores bases de datos Nosql para escalado rápido y alto volumen de datos
Se pueden escalar otras bases de datos NoSQL para satisfacer sus necesidades específicas, al igual que con otras bases de datos. MongoDB, por ejemplo, es un lenguaje de programación popular porque puede escalar rápidamente y manejar una gran cantidad de datos. Los almacenes de datos basados en Redis se utilizan ampliamente debido a sus capacidades en memoria y velocidad.
Escalado vertical Nosql
Las bases de datos Nosql son escalables horizontalmente, lo que significa que pueden manejar un mayor tráfico al agregar más nodos al sistema. Esto contrasta con el escalado vertical, donde el sistema se escala agregando más recursos a un solo nodo.
Cada base de datos debe escalarse para manejar el volumen de datos generado diariamente. El término “escalado” se clasifica en dos tipos: vertical y horizontal. Si desea almacenar más datos, debe invertir en un servidor de 2 TB. Un solo servidor es cada vez más caro y más grande. El proceso de agregar máquinas a un servidor da como resultado una escala horizontal. En este caso, los datos se dividen en un conjunto y se distribuyen en varios servidores o fragmentos. Debido a que sigue el modelo de desnormalización, no hay necesidad de un solo punto de verdad. Es posible que este enfoque no dé como resultado una actualización de la información cuando el maestro no puede realizar una escritura porque no actualiza la información en las réplicas esclavas cuando el maestro no puede realizar una escritura.
¿Qué es el escalado vertical en Sql?
El objetivo del enfoque de escalamiento vertical es aumentar la capacidad de una sola máquina aumentando los recursos del mismo servidor lógico. El software existente debe actualizarse con recursos como memoria, almacenamiento y potencia de procesamiento para que funcione de la mejor manera.
Cómo escalar la base de datos horizontalmente
¿Qué es el escalado horizontal y cómo funciona? Un método de escalado horizontal es aquel que requiere la adición de nodos adicionales para acomodar la carga. Esto es extremadamente difícil con bases de datos relacionales debido a la dificultad de distribuir datos relacionados entre nodos.
Además de agregar más instancias para compartir la carga, escalar horizontalmente (o escalar horizontalmente) implica aumentar la cantidad de instancias de una aplicación o servicio. Por el contrario, el escalado vertical requiere agregar más recursos a la instancia, como potencia de CPU y memoria. Debido a los protocolos subyacentes de HTTP, la mayoría de las aplicaciones web y las API, se pueden escalar fácilmente de forma independiente entre sí. Algunas bases de datos ahora le permiten sincronizar y compartir sus datos escritos entre varias instancias. Si el tráfico se enruta de esta manera, se dedican más recursos a los elementos solicitados con más frecuencia. Aunque los proxies inversos se usan comúnmente para manejar solicitudes HTTP, las bases de datos no siempre se usan para hacerlo. La mayoría de las bases de datos se pueden reenviar con software como nginx o HAproxy, los cuales se pueden hacer en el nivel de TCP.
Si su proxy puede entender cómo funcionan las conexiones a nivel de protocolo, puede determinar si una réplica de lectura no está sincronizada o no puede reaccionar incluso si la conexión de red está activa. La ruta se puede ajustar según la carga en la réplica, así como la cantidad de conexiones. Hay algunos servidores proxy que pueden realizar una variedad de funciones. Se han logrado algunos avances en los volúmenes persistentes y las reclamaciones, pero también existen dificultades inherentes si no selecciona una base de datos que valore cada instancia por igual. Debido a que los contenedores se están moviendo alrededor del clúster, reiniciar una de sus réplicas de lectura debería estar bien. Si esto le sucede a la base de datos principal , es poco probable que se emocione.