
Solr: una potente plataforma de búsqueda
Publicado: 2022-11-18Solr es una poderosa plataforma de búsqueda que le permite consultar grandes cantidades de datos muy rápidamente. Está construido sobre la biblioteca de búsqueda Apache Lucene y proporciona una API similar a REST para una fácil integración con su aplicación. Una de las características clave de Solr es su escalabilidad: puede manejar miles de millones de documentos y consultas con facilidad. Solr a menudo se describe como una base de datos NoSQL porque no utiliza el modelo de base de datos relacional tradicional. Sin embargo, es importante tener en cuenta que Solr no es una base de datos tradicional y no debe usarse como tal. Está diseñado para indexar y buscar, no para almacenar datos. Si necesita almacenar datos, debe usar una base de datos NoSQL como MongoDB o Cassandra.
Con Elasticsearch como el único proyecto de código abierto capaz de competir con Solr, Solr es uno de los dos motores de búsqueda de código abierto más populares del mundo. NoSQL significa Not Only SQL, lo que significa que utiliza lenguajes de consulta separados del SQL tradicional y no solo de bases de datos. A pesar de su excelente función de búsqueda de texto completo, Solr puede ser extremadamente útil en una base de datos NoSQL. Los datos de salud se extrajeron directamente de HBase a través de aplicaciones anteriores Explorys y Worklist. Solr le dio a Worklist tres funciones esenciales: era extremadamente fácil de usar y las funciones eran muy intuitivas. El proceso de filtrado y clasificación es muy eficiente. Debido a que el filtrado de Solr se basa en ID de documentos y almacenamiento en caché, puede calcular casi instantáneamente la cantidad de documentos que cumplen con los criterios de filtrado.
Solr es una excelente solución de base de datos NoSQL que se combina frecuentemente con otros servicios de big data. Brindamos comentarios inmediatos a nuestros usuarios mientras trabajaban en agregar y configurar filtros enviando el parámetrorows=0 a Solr. Es fundamental tener en cuenta algo más que mantener un esquema de Solr para crear un motor de búsqueda que sea bueno para la relevancia.
¿Se puede utilizar Solr como base de datos?
Sí, puede usar Solr como base de datos. Es un potente motor de búsqueda que se puede utilizar para indexar y buscar datos. Se puede utilizar para almacenar datos en un formato estructurado y recuperarlos rápidamente.
¿Está mal usar un índice de búsqueda como base de datos? En mi caso, tuve una idea similar para almacenar algunos elementos de datos básicos en Solr. Sin embargo, el proceso de actualización de Solr me hizo cambiar de opinión y debo admitir que me equivoqué. Si actualizó 2 versiones principales pero no volvió a indexar (por ejemplo, eliminó los documentos originales y luego los archivos de índice), el núcleo ya no se reconoce.
Algolia, Elastic Observability, Coveo y Yext son solo algunas de las alternativas populares a Apache Solr. Algolia es un motor de búsqueda de lenguaje natural que analiza y procesa las consultas de búsqueda en función de lo que sabemos sobre una persona o un tema en lenguaje natural. Elastic Observability es una plataforma de datos que proporciona información en tiempo real sobre datos y aplicaciones. Coveo, una plataforma de marketing de motores de búsqueda, le permite orientar y medir sus esfuerzos de marketing de motores de búsqueda. Al utilizar Yext, puede orientar y medir sus campañas de marketing de motores de búsqueda.
¿Cuáles son las bases de datos Nosql?
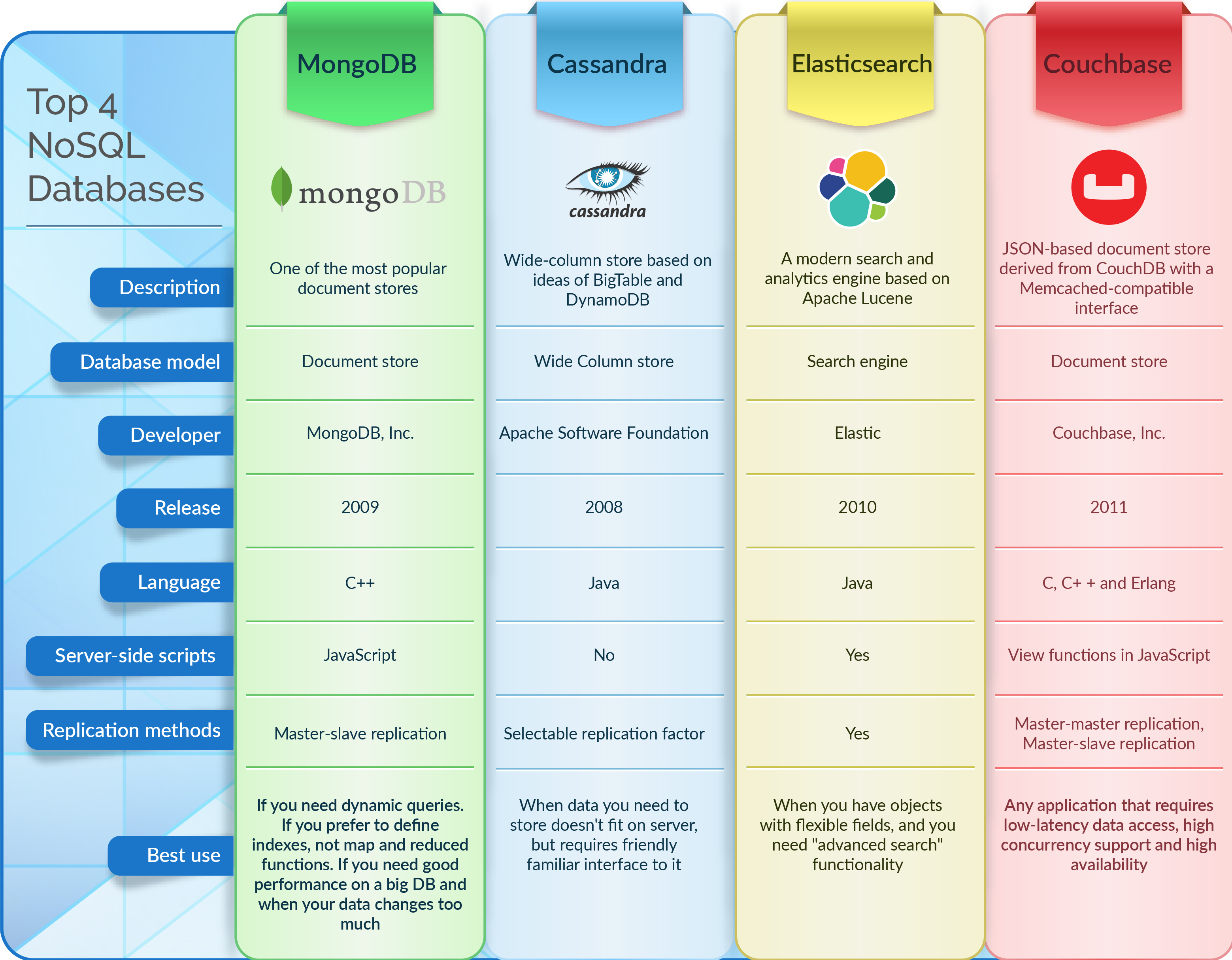
Las bases de datos Nosql son bases de datos que no utilizan el modelo de base de datos relacional tradicional. En su lugar, utilizan una variedad de modelos, que incluyen bases de datos de valores clave, documentos, columnas y gráficos.
Las bases de datos NoSQL basadas en documentos almacenan datos de la misma manera que lo hacen las bases de datos relacionales. El software de gestión de datos está diseñado para ser adaptable, escalable y capaz de responder a las necesidades de las empresas modernas de manera oportuna. Las bases de datos de documentos , los almacenes de clave-valor, las bases de datos de columnas anchas y las bases de datos de gráficos son solo algunos de los tipos de bases de datos NoSQL. La mayoría de las 2000 empresas más grandes del mundo están adoptando rápidamente bases de datos NoSQL para impulsar aplicaciones de misión crítica. En este contexto, cinco tendencias plantean desafíos técnicos que son demasiado difíciles de abordar para la mayoría de las bases de datos relacionales. Debido al modelo de datos fijos, las bases de datos relacionales son un impedimento importante para el desarrollo ágil. El modelo de aplicación define el modelo de datos de NoSQL.
Los datos deben modelarse en un modelo NoSQL independientemente de cómo esté estructurado. El formato JSON es el predeterminado para almacenar datos en una base de datos orientada a documentos. Los marcos ORM se pueden reducir de esta manera, lo que reduce los costos generales del desarrollo de aplicaciones. N1QL (pronunciado níquel) es un lenguaje de consulta de SQL a JSON que se lanzó como parte de Couchbase Server 4.0. La herramienta también admite agregación (GRUPO POR), clasificación (ORDENAR POR), uniones (IZQUIERDA EXTERNA / INTERNA) y una variedad de otras características. Una base de datos distribuida NoSQL con una arquitectura de escalamiento horizontal, sin un único punto de falla y ventajas operativas convincentes es una de las características más atractivas. A medida que se realizan más interacciones con los clientes en línea a través de la web y las aplicaciones móviles, la disponibilidad es un problema.
Las bases de datos NoSQL son fáciles de aprender y usar. Están destinados a almacenar información, escribir y leer libros. También son capaces de administrar y monitorear clústeres de diferentes tamaños en cualquier tamaño. La replicación integrada que se incluye en una base de datos NoSQL distribuida la proporciona la propia base de datos; no se requiere software adicional. Además, los enrutadores de hardware garantizan un acceso inmediato y constante a los datos críticos. Mientras los administradores de bases de datos investigan un problema, las aplicaciones no necesitan esperar a que la base de datos descubra un problema antes de realizar su propia recuperación. La tecnología NoSQL está ganando popularidad como plataforma para las aplicaciones web, móviles y de IoT actuales.
Hay numerosas razones por las que las bases de datos NoSQL son cada vez más populares. Se pueden escalar para satisfacer las necesidades de grandes organizaciones y son adaptables. Como ejemplo, considere a Ryanair y Marriott como clientes de MongoDB. Estas organizaciones, además de usar MongoDB para potenciar sus aplicaciones móviles y sistemas de reservas, también lo utilizan para potenciar sus sitios web. El sistema de gestión de contenido Presto de la empresa también está construido con NoSQL. El sistema ayuda en la gestión eficiente del contenido propietario de la empresa.
El futuro del trabajo El futuro del trabajo es remoto
¿Cuál no es una base de datos Nosql?
¿Cuál es la diferencia entre las bases de datos NoSQL y las que no son NoSQL? Microsoft SQL Server, el sistema de gestión de bases de datos relacionales de la empresa, es el producto principal.
A fines de la década de 2000, las bases de datos NoSQL lograron un enfoque en la escalabilidad, los resultados rápidos de las consultas y la simplificación de la programación. Las bases de datos NoSQL son fáciles de crear porque tienen un modelo de datos flexible, un modelo de datos escalable y una interfaz de usuario fácil de usar. Las bases de datos relacionales SQL (lenguaje de consulta estructurado) se construyen normalmente con esquemas rígidos, complejos y tabulares, así como con escalas verticales prohibitivamente grandes. La versión 4.0 de MongoDB incluía soporte para transacciones ACID de múltiples documentos, y su versión 4.2 agregó soporte para clústeres fragmentados. No hay modelos de datos en la lista. En la mayoría de las bases de datos NoSQL, las consultas se optimizan en lugar de la duplicación de datos. Además, algunos No.
Las bases de datos NoSQL admiten la compresión para reducir el espacio de almacenamiento. Las bases de datos de gráficos, por ejemplo, pueden ser útiles para analizar relaciones, pero pueden no ser las más convenientes para recuperar datos diarios. El uso de MongoDB u otra base de datos en su caso de uso se demostrará en el documento técnico Dónde usar MongoDB. Usar MongoDB Atlas como punto de partida es una de las formas más sencillas de aprender las bases de datos NoSQL. MongoDB University ofrece capacitación en línea completamente gratuita para ayudarlo a aprender MongoDB.
Sin embargo, existen algunos inconvenientes en las bases de datos NoSQL. Las bases de datos NoSQL, además de estar libres de ACID, no tienen las mismas propiedades que las bases de datos relacionales. Las transacciones en su aplicación pueden generar problemas si su sistema depende de ellas. Además, las bases de datos NoSQL no suelen proporcionar el mismo nivel de flexibilidad de tiempo de ejecución que las bases de datos SQL. Debe evitar el uso de bases de datos NoSQL si su aplicación necesita cambiar dinámicamente sus modelos de datos.
¿Cuál de las siguientes no es una base de datos?
Dado que todas las consultas, informes y tablas están relacionados con bases de datos, las relaciones no son objetos de base de datos; están relacionados con las matemáticas.
¿Mongodb es una base de datos Nosql?
El programa de gestión de bases de datos MongoDB NoSQL es de código abierto y de uso gratuito. El lenguaje NoSQL es una alternativa a las bases de datos relacionales tradicionales. Las bases de datos NoSQL son excelentes para la distribución de datos a gran escala. La información orientada a documentos se puede administrar, almacenar o recuperar utilizando MongoDB, que es una herramienta de administración de documentos.
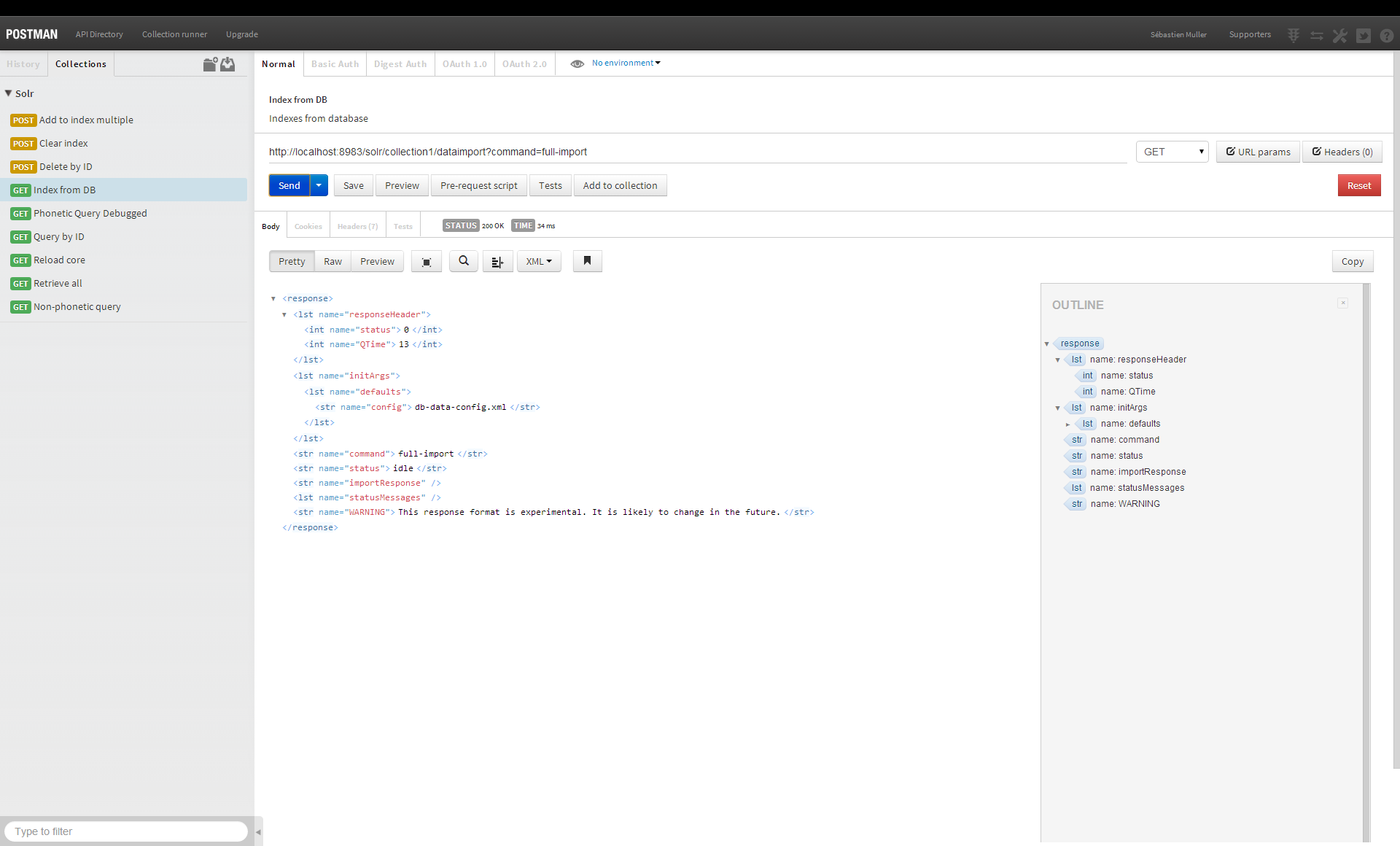
¿Cómo almacena datos Solr?
Apache Solr indexa los datos en el sistema de archivos local, como sugiere su nombre. Como resultado del HDFS (Sistema de archivos distribuido de Hadoop), los usuarios pueden disfrutar de una variedad de beneficios, incluido el almacenamiento distribuido a gran escala con capacidades redundantes y de conmutación por error. Apache Solr incluye soporte para HDFS.
A diferencia de muchos otros motores de búsqueda, Solr puede producir resultados inmediatos porque busca en un índice en lugar de buscar directamente en el texto. Al escanear el índice en la parte posterior de un libro, el índice se puede usar para recuperar páginas relacionadas con una palabra clave. Este índice se almacena en el directorio de datos como un índice en un directorio conocido como el directorio de datos. El motor de búsqueda de Solr funciona con Lucene, un motor de búsqueda de texto completo de código abierto. La relación entre Solr y Lucene es similar a la de un automóvil y su motor. Repasaremos las diferencias entre Lucene y Solr en detalle en este artículo.

Cómo usar campos almacenados en Sol
El formato de campo de un documento se utiliza en Solr. Un documento puede contener algún tipo de campo, que es simplemente una colección de datos. Cuando busca un documento usando Solr, los resultados incluirán las coincidencias para todos los campos en el documento que indexa.
Un campo almacenado es un campo que no necesita ser buscado pero aún debe mostrarse al buscar algo. En Solr, estos se conocen como campos almacenados. Solr indexa todos los campos almacenados como resultado de su algoritmo de indexación, por lo que cuando busca un documento, Solr devuelve resultados que incluyen todos los campos almacenados.
Existen numerosas ventajas en el almacenamiento de campos. Si desea mostrar el título de un documento en la lista de resultados, es posible que deba guardar el título como un archivo. Si desea poder encontrar todos los documentos que ha buscado alguna vez con la misma ID, puede realizar un seguimiento de la ID de un documento a través de múltiples búsquedas.
Los resultados de la búsqueda también se pueden mostrar almacenando campos. El título de un documento puede aparecer en la lista de resultados si está etiquetado. También es posible que desee mostrar el ID del documento para que pueda encontrarlo fácilmente al buscar el documento en varios sitios.
Las capacidades de Solr incluyen la capacidad de indexar datos y almacenarlos. Para indexar un documento, Solr primero debe crear una base de datos de todos los campos que contiene y luego se guardará la información sobre la posición de cada campo. Puede buscar y mostrar resultados a partir de este tipo de información.
Además de sus poderosas capacidades de búsqueda, Solr le permite usar poderosas aplicaciones de recuperación de documentos. Cuando proporciona datos a los usuarios en función de su consulta, se basa en su consulta.
Tutorial de base de datos Solr
Una base de datos solr es un tipo de base de datos que utiliza el software solr para indexar y buscar datos. Es una poderosa herramienta que se puede utilizar para indexar y buscar grandes cantidades de datos muy rápidamente.
Debido a que este tutorial se verificó con Solr 8, también puede funcionar con versiones anteriores. El campo id ya está predefinido en cada Lucene y Solr, por lo que debe entenderse qué tipos de campos puede indexar de la manera correcta. Los campos dinámicos se pueden crear sobre la marcha sin necesidad de predefiniciones, lo que le permite cambiarlos en cualquier momento. La biblioteca de Lucene que utiliza Solr para la búsqueda de texto completo emplea instantáneas de un punto en el tiempo que deben actualizarse regularmente para garantizar que se presenten nuevos detalles en las consultas. Solr, a diferencia del JSON o XML independiente del formato de datos, es independiente del formato de datos.
Cómo usar el motor de búsqueda Solr en Java
Se requiere el cliente Java para conectarse al servidor Solr, así que use el archivo org.apache.solr.client.solrjimpl. La clase que utiliza el protocolo HttpSolrServer se denomina HttpSolrServer. Esta clase usa Java Socket para comunicarse con el servidor Solr. Cuando crea una aplicación de servidor Solr, primero debe cargar las clases apropiadas. En Java, por ejemplo, se puede acceder a la función de búsqueda de Solr mediante el archivo org.apache.solr.client.solrj.impl. La clase org.apache.solr.client.solrj.request es el componente de la clase SolrServer. Esta clase crea una clase RequestHandler. Este potente motor de búsqueda le permite encontrar fácilmente la información que necesita. Para acceder al servidor Solr, utilice el cliente Java.
Solr contra Lucene
Cuando se trata de los proyectos Apache Solr y Lucene, se componen de los mismos componentes. Apache Solr, por otro lado, es un servidor independiente, aunque con muchas funciones avanzadas. Apache Lucene, por otro lado, es una solución basada en una biblioteca de Java que indexa (almacena) y busca datos.
Debido a su caché, Solr tiene una ventaja en el campo de datos estáticos, lo que puede facilitar la recuperación de resultados. Los datos de series de tiempo son procesados con frecuencia por Elasticsearch, que emplea sus filtros y capacidades de agrupación, además de los datos de series de tiempo.
Solr vs Elasticsearch
No hay una respuesta definitiva a esta pregunta, ya que depende de las necesidades y preferencias individuales. Sin embargo, algunas diferencias clave entre Solr y Elasticsearch incluyen:
-Solr se basa en un modelo de base de datos relacional tradicional, mientras que Elasticsearch utiliza un enfoque orientado a documentos.
-Solr suele ser más rápido para indexar y buscar grandes conjuntos de datos, mientras que Elasticsearch suele ser más escalable.
-Solr admite funciones de consulta más avanzadas, como uniones y objetos anidados, mientras que Elasticsearch tiene una sintaxis de consulta más simple.
Existe una gran comunidad de contribuyentes a ambas tecnologías y se encuentra disponible la asistencia de expertos. Elasticsearch se conocía anteriormente como Apache 2.0 y era de código abierto. A partir de 2021, con el lanzamiento de la versión 7.11, Elasticsearch será de uso gratuito bajo la Licencia pública del lado del servidor. Está diseñado para búsquedas de texto de nivel empresarial que requieren la recuperación de información y/o análisis. Las búsquedas de texto completo también son posibles en Elasticsearch, y se pueden leer documentos enriquecidos como PDF y Word. Elasticsearch requiere más memoria en montón que Solr (1 GB frente a 512 MB), pero estos valores predeterminados se pueden cambiar. La plataforma Elasticsearch permite una mayor automatización al combinar el reequilibrio de clústeres con la limpieza de datos, que por lo general no requiere intervención.
Sharding es un método de distribución de datos entre múltiples servidores que es compatible con Solr y Elastic. Tanto Solr como ElasticSearch son bases de datos de motores de búsqueda populares con grandes comunidades involucradas y capacidades similares. Elasticsearch es más fácil de usar que Solr, más fácil de escalar y tiene mejores capacidades de análisis y consulta. La biblioteca Apache Tika, que pueden utilizar ambas bases de datos, les permite realizar búsquedas de texto completo y leer documentos enriquecidos.
Uso de Apache Solr
Debido a que puede indexar y buscar documentos y archivos adjuntos de correo electrónico, así como también indexar y buscar múltiples sitios web, es una herramienta popular para sitios web y búsqueda empresarial.
Es una plataforma de búsqueda de código abierto que se utiliza para crear aplicaciones de búsqueda. Se basa en el popular motor de búsqueda de texto completo Lucene . Solr es una plataforma altamente flexible nativa de la nube que está lista para las operaciones empresariales. Las consultas paralelas se habilitaron en la versión más reciente de Solr, Solr 6.0, que se lanzó en 2016. La plataforma Solr nos permite escalar, distribuir y administrar índices para aplicaciones a gran escala (Big Data). Mientras trabaja con Solr, no necesita ser un programador con conocimientos de Java. En lugar de Lucene, proporciona un servicio muy simple y fácil de usar para crear un cuadro de búsqueda que incluye autocompletar.
Los muchos beneficios de Apache Sol
El motor de búsqueda Apache Solr es un motor de búsqueda popular entre organizaciones pequeñas y grandes. Este software es muy versátil, lo que permite su uso en una variedad de situaciones, incluido el análisis y la recuperación de datos. Solr es un servicio que ofrece capacidades de búsqueda empresarial, lo que lo convierte en una opción ideal para administrar grandes cantidades de datos.
Solución útil de base de datos Nosql
Hay muchas soluciones útiles de bases de datos NoSQL disponibles en la actualidad. Las bases de datos NoSQL suelen ser más escalables y de mejor rendimiento que las bases de datos relacionales tradicionales. También suelen ser más flexibles, lo que permite un modelado de datos y una evolución de esquemas más sencillos. Algunas bases de datos NoSQL populares incluyen MongoDB, Cassandra y HBase.
Los desarrolladores ya no utilizarán las bases de datos NoSQL en el futuro. El futuro está aquí, donde estas bases de datos serán una herramienta común para impulsar aplicaciones populares. Es posible que no sepa que algunas aplicaciones populares se ejecutan en bases de datos NoSQL y por qué NoSQL es ideal para estas aplicaciones. En 1996, Forbes fue la primera publicación de negocios en lanzar un sitio web. Forbes ha estado migrando su servicio a MongoDB Atlas para satisfacer las necesidades de sus 140 millones de usuarios en línea. Debido al impacto de la pandemia de COVID-19, la publicación se trasladó a una infraestructura en la nube y pudo hacer frente a los momentos difíciles. BangDB fue elegido por Accenture para ser la base de datos NoSQL para su aplicación de puntuación de clientes potenciales.
Facebook Messenger se ejecuta en la base de datos Cassandra NoSQL sin un solo punto de falla, lo que le permite escalar sus operaciones en múltiples plataformas. Bigtable es un componente de Google Mail que ayuda a Google Bigtable, una empresa en línea que impulsa una variedad de transacciones de Google Mail. La base de datos de Espresso garantiza que todas las aplicaciones de LinkedIn puedan funcionar con normalidad. Descarga BangDB gratis para ver si es la herramienta adecuada para ti.
Los beneficios de las bases de datos Nosql
Muchas bases de datos NoSQL se pueden usar para almacenar y modelar datos estructurados, semiestructurados y no estructurados en una base de datos, lo que las hace ideales para almacenar y modelar estructuras de datos y semántica. Pueden funcionar mejor y ser más estables que las bases de datos relacionales tradicionales, y pueden ser más fáciles de implementar para los desarrolladores. Con la creciente popularidad de las bases de datos NoSQL, es probable que sigan creciendo en popularidad.
mongodb »
MongoDB es un poderoso sistema de base de datos orientado a documentos. Tiene una función de búsqueda basada en índices que hace que la recuperación de datos sea rápida y fácil. MongoDB también ofrece una función de escalabilidad, lo que le permite manejar datos a gran escala.