
Los diferentes tipos de clústeres de computadoras
Publicado: 2023-02-16En informática, un clúster es un grupo de sistemas informáticos independientes que funcionan juntos de modo que, en muchos aspectos, pueden verse como un solo sistema. Los clústeres generalmente se implementan para mejorar el rendimiento y la disponibilidad en comparación con los de una sola computadora, mientras que, por lo general, son mucho más rentables que las computadoras individuales de velocidad o disponibilidad comparables. Existen diferentes tipos de clústeres de computadoras, incluidos los clústeres de computación de alto rendimiento, los clústeres de computadoras utilizados con fines comerciales y los clústeres de almacenamiento. En cada tipo de clúster, los sistemas componentes trabajan juntos para realizar una tarea o tareas comunes. Los clústeres de informática de alto rendimiento (HPC) se utilizan para aplicaciones científicas y de ingeniería que requieren una gran cantidad de potencia informática y/o almacenamiento de datos. Estos clústeres generalmente consisten en un grupo de computadoras básicas, conectadas por una red de área local (LAN) rápida. Las computadoras en un clúster HPC generalmente ejecutan el mismo sistema operativo (SO) o uno similar y tienen componentes de hardware iguales o similares. Los clústeres comerciales se utilizan para ejecutar aplicaciones comerciales que requieren un alto grado de disponibilidad y/o escalabilidad. Estos clústeres a menudo consisten en servidores que ejecutan una variedad de sistemas operativos y tienen una variedad de componentes de hardware. En muchos casos, los servidores de un clúster comercial también están conectados a una red de área de almacenamiento (SAN) para que puedan acceder a almacenes de datos comunes. Los clústeres de almacenamiento se utilizan para proporcionar un depósito de almacenamiento centralizado al que puede acceder un grupo de computadoras. Los clústeres de almacenamiento generalmente consisten en un grupo de servidores de almacenamiento que están conectados a una SAN. Los servidores en un clúster de almacenamiento generalmente ejecutan una variedad de sistemas operativos y tienen una variedad de componentes de hardware.
¿Qué es un clúster mongodb fragmentado y cuál es el punto de conectarse a uno en MongoDB? ¿Cómo me conecto a uno o simplemente me conecto al localhost? La medalla de oro se otorga en la insignia Noob 7461. Se produjeron diez insignias de plata y 23 insignias de bronce. Un clúster replicado se compone de diez servidores, uno para la interfaz mongos, tres para cada conjunto de réplicas y uno para cada conjunto de réplicas del servidor de configuración. En un sistema de replicación, un componente se duplica para que siempre haya una copia de seguridad si algo sale mal. Todos los fragmentos deben ser réplicas para poder fabricarlos.
Un clúster mongodb, por ejemplo, se usa comúnmente para describir un clúster fragmentado en MongoDB. Un mongodb fragmentado cumple las siguientes funciones: Escala lecturas y escrituras desde varios nodos. Debido a que cada nodo no maneja el conjunto de datos completo, solo puede particionar los datos en regiones en el fragmento.
Un clúster de base de datos , como sugiere el nombre, es una colección de bases de datos que puede ejecutar una instancia de un servidor de base de datos en ejecución. Postgres, que significa base de datos "predeterminada" en PostgreSQL, se incluirá como base de datos predeterminada en un clúster de base de datos después de que se haya creado.
Un clúster de MongoDB también se puede denominar "conjunto de réplicas" o "clúster fragmentado". En un conjunto de réplicas, varios servidores llevan copias de los mismos datos. Los nodos en un conjunto de réplicas suelen ser tres. Cuando una aplicación cliente realiza cualquier operación en un nodo, todas las lecturas y escrituras se envían a ese nodo; si algo sale mal, dos nodos secundarios lo protegen.
¿El clúster y la base de datos son iguales?
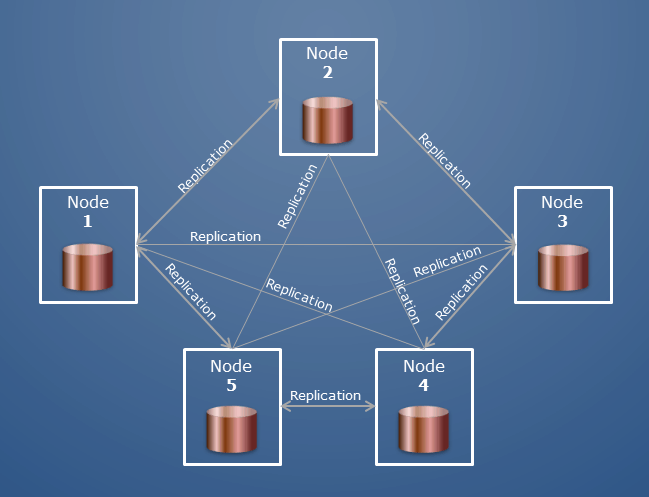
Hay varios clústeres de hosts que forman un clúster. Los hosts de un clúster fragmentado se clasifican en una variedad de funciones. Una base de datos es una colección de colecciones; en Oracle, sería equivalente a una base de datos y un esquema.
Un clúster de base de datos es una colección de servidores o instancias que conectan una base de datos con otra. Los servidores utilizan la agrupación de bases de datos por una variedad de razones, las principales son la redundancia de datos, el equilibrio de carga, la alta disponibilidad y la supervisión y automatización. Como resultado, si una computadora falla, todos nuestros datos estarán disponibles para otros, dándonos la ventaja de la redundancia de datos. Con la agrupación en clústeres, existe la oportunidad de automatizar muchos de los procesos de la base de datos y, al mismo tiempo, crear reglas para identificar problemas potenciales. En la arquitectura de clúster, todas las solicitudes se enrutan a varias computadoras, cada una de las cuales es capaz de manejar la solicitud y producirla para el usuario. Un clúster de conmutación por error o de alta disponibilidad replica los servidores y reconfigura el hardware para garantizar la disponibilidad del servicio. Estos tipos de clústeres son rentables para los usuarios de computadoras que dependen completamente de sus sistemas. El objetivo de los clústeres de alto rendimiento es aumentar la capacidad de la red y, al mismo tiempo, mejorar el rendimiento.
En un sistema distribuido Hadoop, los nodos actúan como centros de procesamiento y almacenamiento de datos. La distinción principal entre un clúster y un servidor es que el clúster emplea varios nodos que se comunican entre sí para realizar un conjunto de operaciones. Un clúster contiene una serie de nodos que realizarán un conjunto de operaciones. El sistema distribuido de Hadoop puede admitir hasta 10 000 bases de datos. Se pueden obtener resultados de consulta similares cuando los datos de varias tablas en la misma base de datos se combinan en una consulta de varias bases de datos en el mismo clúster.
Los beneficios de Clúster
Con un clúster, puede administrar fácilmente varias bases de datos al proporcionar un almacenamiento uniforme de tablas y columnas en todas ellas. Esto mejora el rendimiento y la integridad de los datos y, por lo tanto, hace que el sistema sea más eficiente.
¿Dónde está el nombre del clúster en Mongodb?
No hay una respuesta establecida para esta pregunta, ya que el nombre del clúster se puede encontrar en diferentes lugares según el tipo de clúster de MongoDB que se utilice. Por ejemplo, en un conjunto de réplicas, el nombre del clúster generalmente se almacena en la colección local.system.replset, mientras que en un clúster fragmentado generalmente se encuentra en la colección config.shards.
MongoDB Atlas es una oferta de base de datos como servicio NoSQL de MongoDB como servicio que está disponible en las nubes públicas de Microsoft Azure, Google Cloud Platform y Amazon Web Services. Puede crear un clúster de MongoDB en funcionamiento en cuestión de minutos usando su navegador web favorito haciendo clic en un enlace para configurarlo. No es necesario instalar software en su estación de trabajo para conectarse a la web a través de ella, y puede usar la interfaz web para hacerlo. Cuando los conjuntos de réplicas de MongoDB se utilizan junto con varios servidores de MongoDB, se garantiza la redundancia de datos y la alta disponibilidad. El clúster de MongoDB tiene capacidad de operaciones de lectura adicional, lo que le permite dirigir a los clientes a servidores adicionales. En una replicación, uno o más miembros del conjunto de réplicas se replican de forma asincrónica desde el registro de operaciones del nodo principal a los secundarios, lo que permite que el conjunto de réplicas funcione a pesar de cualquier falla potencial de sus miembros. En MongoDB, puede realizar operaciones de lectura y escritura adicionales además de los comandos estándar de entrada y salida.
En la mayoría de los casos, el nodo principal es el origen de todas las operaciones de lectura, pero se puede configurar el enrutamiento a los secundarios. El riesgo de datos potencialmente obsoletos es mayor cuando el nodo más cercano es un nodo secundario. Para que la escritura se propague con éxito en el clúster, deberá incluir opciones para escribir datos en un conjunto de réplicas de MongoDB. Como parte de este proceso, se debe agregar una propiedad de preocupación de escritura para insertar. Cuando se recibe una solicitud de escritura, se solicita al clúster que reconozca que se ha realizado correctamente en la gran mayoría de los nodos que contienen datos. La configuración de un clúster fragmentado también permite configurarlo como un conjunto de réplicas. Un conjunto de réplicas contiene procesos mongod primarios y secundarios. Si el máster falla, se recomienda que el número total de estos procesos sea impar para asegurar que la mayoría se lleve a cabo.
Los clústeres de MongoDB , como su nombre lo indica, son clústeres de nodos que trabajan juntos para almacenar y administrar datos. Al crear un clúster de MongoDB, especifica cuántos nodos incluir y para qué deben configurarse. Puede conectar su aplicación a su clúster MongoDB con Node una vez que se haya creado. MongoDB Compass se puede considerar como un controlador para la biblioteca MongoDB JS o como un controlador PyMongo para MongoDB. La principal ventaja de conectar su aplicación a un clúster es que puede leer y escribir datos en él. Con MongoDB Compass, puede explorar, modificar y visualizar sus datos de diversas maneras. Puede encontrar un ejemplo de cómo puede ver sus datos en una cuadrícula, que le permite observar cómo cambian los datos con el tiempo y quién los distribuye en su clúster.
¿Dónde está el clúster en Mongodb Atlas?
No hay una respuesta definitiva a esta pregunta, ya que la ubicación de un clúster en MongoDB Atlas puede variar según una serie de factores, incluida la región geográfica en la que se encuentra y las necesidades específicas de la aplicación que está impulsando. Sin embargo, en general, un clúster en MongoDB Atlas se puede encontrar en la sección "Clusters" de la consola de MongoDB Atlas.

Un clúster puede ser un conjunto de réplicas o un conjunto fragmentado. El número total de nodos de cada proyecto está limitado por una restricción específica basada en su rango de funciones en todas las regiones. Cada proyecto de Atlas puede implementar hasta 25 bases de datos. Comuníquese con los administradores de la base de datos si tiene alguna pregunta sobre el límite de implementación de la base de datos. La versión 1.2 de TLS es la versión de TLS predeterminada para los clústeres creados después del 1 de julio de 2020.
¿Qué es un clúster en Mongodb?
En MongoDB, un clúster es un grupo de servidores de bases de datos que mantienen copias de los mismos datos. Cada servidor en un clúster se denomina nodo. Un clúster puede tener uno o más nodos.
¿Para qué sirve la agrupación de bases de datos? El proceso de conectar varios servidores o instancias a una única base de datos se denomina conexión SQL. En MongoDB, un clúster es un conjunto de réplicas o un clúster fragmentado, según el tipo de MongoDB. Repasaré cada uno de los distintos aspectos de estos grupos con mayor profundidad en los siguientes párrafos. Debido al equilibrio de carga y la cantidad de máquinas de MongoDB, tiene un alto nivel de disponibilidad. Se puede usar un clúster para automatizar muchos procesos de bases de datos y, al mismo tiempo, permitir la creación de reglas para alertar sobre posibles problemas. Una base de datos MongoDB se puede dividir en dos tipos: conjuntos de réplicas y clústeres de fragmentación.
Los datos se almacenan en varias máquinas en un fragmento. El método de MongoDB para proporcionar escalabilidad de datos se basa en esto. Esto reduce la cantidad de tiempo que lleva administrar grandes cantidades de datos. Debido a la cantidad de datos que proporcionan las réplicas, las aplicaciones distribuidas también pueden beneficiarse de ellas.
Pueden ocurrir problemas de rendimiento y conflictos de datos si se implementan varios proyectos de Atlas en el mismo clúster. Atlas recomienda que solo use un clúster gratuito por proyecto de Atlas. Se requiere una buena herramienta de agrupación de datos en una amplia gama de aplicaciones de análisis y minería de datos. Para evitar posibles problemas de rendimiento y conflictos de datos en los proyectos de Atlas, Atlas recomienda utilizar solo un clúster gratuito por proyecto.
Arquitectura de clúster de Mongodb
Un clúster MongoDB es un grupo de servidores MongoDB que trabajan juntos para almacenar sus datos. Cada servidor en un clúster se denomina nodo. Un clúster puede tener cualquier número de nodos. Un clúster se compone de un conjunto de réplicas, que es un grupo de nodos, cada uno de los cuales tiene una copia de sus datos. Un conjunto de réplicas tiene al menos tres nodos, de modo que si un nodo deja de funcionar, sus datos aún estarán disponibles.
La arquitectura de los conjuntos de réplicas es un factor importante en la capacidad de MongoDB. Los clústeres de MongoDB generalmente se distribuyen en réplicas de tres nodos. La recuperación de la base de datos después de un desastre debe ser constantemente estable, especialmente después. Una de las mejores formas de implementar un clúster fragmentado es usar una estrategia de replicación. Los datos contenidos en las Shard Keys deben distribuirse de la misma manera. Debe escalar la base de datos horizontalmente y reducir la cantidad de operaciones que se pueden realizar en una sola instancia. Con pocos fragmentos, las operaciones de lectura y escritura pueden volverse lentas debido al hecho de que la cantidad de fragmentos limita la cantidad de operaciones.
Cada pieza de datos en un fragmento se compone de un subconjunto de esa pieza en función de un conjunto específico de criterios. Es común que la cantidad mínima de fragmentos requeridos para lograr el significado de fragmentación sea dos. Las consultas de dispersión y recopilación solo se deben usar si se pueden usar simultáneamente entre sí en todos los fragmentos. Al seleccionar un grupo, es fundamental tener al menos siete miembros con derecho a voto para que el proceso de elección sea lo más simple posible. Si solo tiene siete o menos miembros con derecho a voto pero el mismo número de miembros, se debe utilizar el árbitro. Los árbitros no almacenan copias de datos, por lo que se requieren menos recursos para procesar los datos. Se prefiere el uso de un nombre de host DNS lógico en lugar de una dirección IP cuando se configuran miembros del conjunto de réplicas o miembros del clúster fragmentado. Debido a que algunas conexiones de conjuntos de réplicas de grupos de controladores se realizan mediante nombres de conjuntos de réplicas, estos nombres deben usarse por separado para los conjuntos. La distribución geográfica de los nodos del conjunto de réplicas es ideal para abordar la redundancia redundante y garantizar la tolerancia a fallas si uno de los centros de datos está ausente.
Nombre del clúster Mongodb
Un clúster MongoDB es un grupo de servidores MongoDB que funcionan juntos para proporcionar alta disponibilidad y escalabilidad. Un clúster normalmente tiene un servidor primario que actúa como servidor maestro y uno o más servidores secundarios que actúan como esclavos. El servidor principal contiene los datos y los servidores secundarios copian los datos del servidor principal.
Los programas de base de datos orientados a documentos se crean para almacenamiento de gran volumen con la ayuda de MongoDB, un programa multiplataforma. MongoDB, un programa de base de datos NoSQL, se clasifica como tal porque emplea documentos de estilo JSON con esquemas opcionales. Puede mejorar el rendimiento instalando su base de datos en el mismo centro de datos que sus otros recursos de DigitalOcean. La región tiene uno o más centros de datos, y cada uno tiene su propia red de VPC. Se puede seleccionar el tipo de máquina, el número y el tamaño de los nodos de la base de datos. Para decirlo de otra manera, puede agregar hasta dos nodos en espera a su clúster. Agregue un nombre de proyecto, complételo y use las etiquetas que desee usar en él cuando lo cree. Un clúster puede tardar hasta cinco minutos en completarse.
El poder de Mongodb Atlas Clúster
MongoDB Atlas Cluster es una solución de base de datos como servicio NoSQL en la nube pública que se ejecuta en MongoDB. Es una plataforma de datos robusta y escalable que le permite crear e implementar aplicaciones rápidamente. Al utilizar MongoDB Atlas Cluster, puede conectarse de forma segura a MongoDB desde cualquier lugar del mundo.
Cómo crear un clúster en Mongodb
Utilice los siguientes pasos para crear un clúster en MongoDB:
1. Elija una topología de implementación.
2. Seleccione el tipo de conjunto de réplicas que desea implementar.
3. Elija la cantidad de conjuntos de réplicas que desea implementar.
4. Configure los conjuntos de réplicas.
5. Conéctese al enrutador mongos.
6. Configure la clave de fragmento.
7. Agregue fragmentos al clúster.
8. Verifique que el clúster esté operativo.
MongoDB Atlas es un nivel gratuito de MongoDB, que es el servicio de base de datos en la nube completamente administrado de MongoDB. El servicio está diseñado para cargas de trabajo empresariales, así como para clústeres globales . No necesita crear una cuenta con Amazon Web Services (AWS), Google Cloud Platform o Microsoft Azure. Le solicitará que cree una cuenta de administrador para poder acceder al servicio. Para acceder al servicio, un clúster debe estar vinculado a una dirección IP. La configuración de seguridad predeterminada de MongoDB Atlas evita todas las conexiones externas. Su contraseña no debe tener caracteres especiales y solo caracteres alfanuméricos para facilitar la conexión a Studio 3T. Al crear una cadena de conexión para MongoDB, se deben codificar caracteres especiales. En el Paso 1, elija Java de la lista desplegable CONTROLADOR y luego de la lista desplegable VERSIÓN. Si selecciona el controlador y la versión, el servicio actualizará automáticamente la cadena de conexión en el paso 2.
Agrupación en clústeres de Mongodb: una excelente opción para el rendimiento de alta demanda
Con la agrupación en clústeres de MongoDB , puede cumplir con los requisitos de alto rendimiento, disponibilidad y rendimiento para entornos grandes. Los clústeres de MongoDB se pueden configurar para admitir una amplia gama de tipos de conjuntos de réplicas de MongoDB, desde configuraciones simples de un solo nodo hasta configuraciones de múltiples nodos de alta disponibilidad.
Tutorial del clúster de Mongodb
Un clúster MongoDB es un grupo de servidores MongoDB que trabajan juntos para almacenar sus datos. Un clúster de MongoDB puede ser tan pequeño como un solo servidor o tan grande como cientos de servidores. Cuando crea un clúster MongoDB, especifica la cantidad de servidores (nodos) que desea en el clúster. Cada nodo en un clúster de MongoDB almacena un subconjunto de sus datos. Los clústeres de MongoDB están diseñados para ser escalables y proporcionar alta disponibilidad. Puede agregar nodos a un clúster en cualquier momento para aumentar su capacidad o reemplazar un nodo fallido. Cuando elimina un nodo de un clúster, los otros nodos redistribuyen los datos del nodo eliminado para que los datos aún se distribuyan uniformemente en el clúster.
La Guía fácil de MongoDB Clustering de Hevo es el primer paso. Cuando una base de datos es demasiado pequeña o demasiado lenta para ejecutar un sistema, las operaciones de una organización continúan. MongoDB tiene numerosas características avanzadas que fueron diseñadas para la nube, como fragmentación y replicación. MongoDB permite almacenar múltiples copias de los mismos datos, haciéndolos extremadamente accesibles. Si un servidor falla, los datos del otro pueden recuperarse inmediatamente. Puede automatizar, simplificar y enriquecer el proceso de replicación de datos utilizando Hevo Data. La replicación de datos es simple y fácil de usar cuando tiene acceso a nuestra prueba gratuita de 14 días.
Para configurar los clústeres de MongoDB, primero debe instalar los tres componentes necesarios. Con la plataforma automatizada sin código de Hevo, puede realizar un seguimiento de todo lo que necesita hacer para una experiencia de replicación de datos fluida. Para garantizar la máxima disponibilidad, deben estar presentes varios servidores de configuración o enrutadores. Cuando el enrutador determina en qué fragmento se alojan los datos, envía solicitudes al clúster apropiado. En el proceso de establecimiento de clústeres de MongoDB, se requerirán los siguientes pasos para agregarles fragmentos. En una configuración en clúster, el puerto 27018 se usa como predeterminado para los servidores de fragmentos. Significa que es un servidor de fragmentos en lugar de un servidor de configuración.