
Los factores diferenciadores de Hadoop: escalabilidad de código abierto y tolerancia a fallas
Publicado: 2022-11-18Hadoop es un marco de software de código abierto para el almacenamiento y procesamiento distribuidos de grandes conjuntos de datos en grupos de computadoras. Está diseñado para escalar de un solo servidor a miles de máquinas, cada una de las cuales ofrece computación y almacenamiento local. En lugar de depender del hardware para brindar alta disponibilidad, el marco está diseñado para detectar y manejar fallas en la capa de la aplicación. Hadoop es una base de datos nosql porque utiliza una arquitectura completamente diferente a una base de datos relacional tradicional. Hadoop está diseñado para escalar horizontalmente, lo que significa que puede escalar para acomodar más datos agregando más servidores básicos al clúster. Hadoop también está diseñado para ser tolerante a fallas, lo que significa que si un servidor en el clúster deja de funcionar, el sistema puede continuar funcionando sin ese servidor.
Hadoop no se usa para almacenar datos, ni requiere el uso de almacenamiento relacional; más bien, se utiliza para almacenar grandes cantidades de datos en servidores distribuidos. Una base de datos Hadoop es un tipo de datos en lugar de un sistema de software que permite la computación paralela masiva. Es un tipo de enlace de base de datos NoSQL (como HBase) que permite a los usuarios consultar y buscar bases de datos en una variedad enlazada. RDBMS, en su forma actual, no podría competir con Hadoop porque es capaz de administrar datos relativos y transaccionales. Hadoop tiene la capacidad de manejar cualquier tipo de datos, ya sean estructurados, semiestructurados o no estructurados, y admite una amplia gama de métodos. El análisis de Big Data está brindando a las empresas una ventaja competitiva en el mundo real al proporcionar conocimientos más profundos. Hadoop, como servicio, admite el uso de procesamiento analítico en línea (OLAP) en el procesamiento de datos. Es importante recordar que la velocidad del proceso de datos está determinada por la cantidad de solicitudes de datos. Puede usar Hadoop si no desea transacciones ACID o compatibilidad con OLAP, por ejemplo.
Hadoop y las bases de datos en memoria son dos tecnologías completamente diferentes que se superponen. No son lo mismo, pero sí coinciden en algunas cosas.
Las aplicaciones analíticas que usan SQL-on-Hadoop combinan métodos de consulta de estilo SQL establecidos con elementos más nuevos del marco de datos de Hadoop . SQL-on-Hadoop permite a los desarrolladores empresariales y analistas de negocios colaborar en clústeres de Hadoop con consultas familiares de SQL.
Es una base de datos NoSQL que proporciona un medio para almacenar y recuperar datos. No relacional/no SQL es uno de los términos que se usa comúnmente en este espacio.
Hadoop y SQL administran los datos de varias maneras. SQL es un lenguaje de programación, mientras que Hadoop es un marco de componentes de software. Ambas herramientas son útiles para big data, pero tienen inconvenientes. La plataforma Hadoop puede manejar un conjunto de datos mucho más grande, pero solo escribe datos una vez.
¿Cuál es la diferencia entre Hadoop y Nosql?
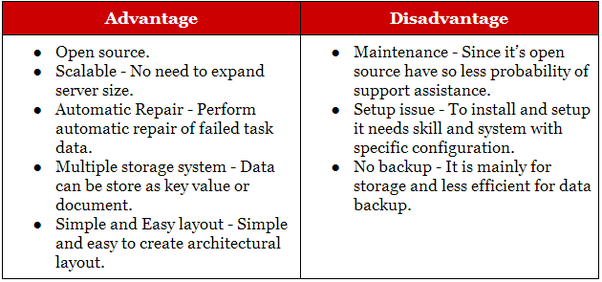
Hadoop es adecuado para aplicaciones de archivado analítico e histórico, mientras que NoSQL es ideal para cargas de trabajo operativas que complementan sus contrapartes relacionales. Las bases de datos NoSQL comenzaron como bases de datos de almacenamiento de valores clave, pero más tarde se les unieron las bases de datos document/json y graph.
El procesamiento en tiempo real, los datos grandes y los datos no estructurados son solo algunos de los escenarios en los que se puede utilizar la tecnología NoSQL. Como resultado, se pueden abordar algunos de estos desafíos, como la escalabilidad y la disponibilidad. La base de datos NoSQL tiene una serie de ventajas sobre la base de datos relacional tradicional. Pueden procesar conjuntos de datos de una manera mucho más rápida y escalable que antes. Los sistemas de administración de bases de datos también utilizan menos conocimientos y experiencia que las bases de datos tradicionales , lo que los hace más fáciles de usar. Una base de datos NoSQL tiene una variedad de ventajas sobre una base de datos relacional tradicional. Lo más importante a considerar es si los necesita para el procesamiento en tiempo real y grandes conjuntos de datos.
Las bases de datos Nosql son la mejor opción para las empresas con grandes cargas de trabajo de datos
Si sus cargas de trabajo de datos se centran más en analizar y procesar grandes cantidades de datos variados y no estructurados, como Big Data, las bases de datos NoSQL son una mejor opción. A diferencia de las bases de datos relacionales , las bases de datos NoSQL no se basan en un modelo de esquema fijo. El RDBMS es más flexible que los RDBMS tradicionales en términos de almacenamiento, procesamiento y administración de datos, lo que lo convierte en una mejor opción para las empresas que requieren la capacidad de acceder rápidamente a grandes cantidades de datos y tienen la necesidad de almacenarlos indefinidamente.
¿Es Big Data Sql o Nosql?

Si sus cargas de trabajo de datos están relacionadas principalmente con el procesamiento y análisis rápidos de grandes cantidades de datos diversos y no estructurados, como Big Data, NoSQL es su mejor opción. El modelo de base de datos NoSQL es único en el sentido de que no se basa en la misma estructura de esquema que una base de datos relacional.
Ya no se trata de si los grandes datos mejorarán la fabricación; es cuestión de cuándo. En big data, hay cantidades vastas, diversas y complejas de datos estructurados y no estructurados disponibles. Los sensores, las cámaras en la planta de producción y los dispositivos de los consumidores se pueden usar para recopilar grandes datos en la fabricación. Debido a que la mayoría de los datos en la fabricación no están estructurados, las arquitecturas NoSQL no pueden competir con enfoques rígidos como SQL. Una base de datos NoSQL no necesita esquemas para almacenar datos en la misma tabla de base de datos, lo que permite a los usuarios almacenar datos en varias estructuras. La línea de separación de una empresa puede determinarse por la cantidad de datos que pretende utilizar. Las transacciones deben cumplir con cuatro principios operativos fundamentales para ser consideradas una transacción de base de datos relacional.
Debido a que los sistemas NoSQL y los sistemas en la nube se pueden integrar, es una buena idea usar marcos de computación en la nube para admitir sistemas NoSQL. La optimización del proceso de fabricación en tiempo real a través de NoSQL se puede lograr mediante la integración con los sistemas de ejecución de fabricación (MES). Este éxito fue posible gracias al uso de análisis de big data para producir respuestas más rápidas a las condiciones cambiantes. MongoDB es una buena base de datos NoSQL porque es fácil de configurar y se puede usar para análisis. El uso de arquitecturas de bases de datos de respuesta más rápida, como NoSQL, permite a la administración realizar mejores simulaciones, lo que les permite tomar mejores decisiones sobre productos en el mundo real. Las bases de datos B2B son vulnerables a ataques entre sitios, así como ataques de inyección y ataques de fuerza bruta. Un ataque de inyección ocurre cuando un atacante agrega datos a los comandos de consulta NoSQL o declaraciones de almacenamiento.

El sector de la fabricación está especialmente preocupado por la seguridad de la arquitectura NoSQL. Si se realiza con éxito un ataque de denegación de servicio o un ataque de inyección, un fabricante puede modificar las especificaciones. Debido a esto, los competidores pueden obtener una ventaja en un mercado altamente competitivo.
Los procesos comerciales que se basan en datos en tiempo real son cada vez más comunes a medida que las empresas buscan formas de mejorar su eficiencia y capacidad de respuesta a las necesidades de los clientes. Las bases de datos NoSQL basadas en la nube, como Cloud Bigtable, brindan una forma rápida y eficiente de almacenar y acceder a grandes conjuntos de datos, lo que las convierte en una excelente solución para este tipo de aplicaciones.
Cloud Bigtable es un servicio de base de datos NoSQL totalmente administrado y ofrece un tiempo de actividad del 99,999 %. Es ideal para cargas de trabajo analíticas y operativas porque tiene altas velocidades de alimentación de datos y es fácil de escalar hacia arriba y hacia abajo. Como resultado, es una excelente opción para el procesamiento de datos en tiempo real en aplicaciones como juegos móviles y análisis minorista.
¿Es Nosql la mejor base de datos para grandes datos?
MongoDB, por ejemplo, es una excelente opción para almacenar grandes cantidades de datos. Permiten una amplia gama de escenarios de procesamiento ágiles y de alto rendimiento. Además, los datos no estructurados se almacenan en bases de datos NoSQL en múltiples nodos de procesamiento y en múltiples servidores. Como resultado, las bases de datos NoSQL han sido la opción predeterminada de algunos de los almacenes de datos más grandes del mundo. ¿Qué base de datos es la mejor para grandes datos? Cuando se trata de esta pregunta, no es posible predecir qué base de datos es la mejor para grandes datos debido a las diferentes necesidades de la organización. Amazon Redshift, Azure Synapse Analytics, Microsoft SQL Server, Oracle Database, MySQL, IBM DB2 y muchas otras bases de datos se encuentran entre las opciones más populares para el almacenamiento de datos de gran tamaño.
¿Es Hadoop una base de datos?
Hadoop es un sistema de archivos distribuidos y un marco para ejecutar aplicaciones en grandes grupos de hardware básico. Hadoop no es una base de datos.
Hadoop, un marco de código abierto, permite el almacenamiento y procesamiento eficientes de conjuntos de datos masivos. Las tablas Hive e Imperative se pueden crear utilizando archivos de texto en HDFS. Admite los tres formatos de archivo principales: archivos de secuencia, archivos de datos Avro y archivos Parquet. Una serie de bytes se representa mediante serialización de datos como una unidad de memoria. Avro, un marco de serialización de datos eficiente, es ampliamente compatible con Hadoop y su ecosistema.
El uso de archivos de texto como formato de almacenamiento para tablas Hive e Implicit simplifica la gestión y manipulación de datos. Como resultado, es una buena opción para el procesamiento por lotes o el almacenamiento de datos en una variedad de formatos. Además, la serialización de datos a través de Avro permite el almacenamiento y la recuperación de datos de manera eficiente y conveniente. Como resultado, es una buena opción para almacenar datos en una variedad de formatos o realizar un procesamiento paralelo.
Hadoop contra Nosql
Hadoop maneja big data para un grupo de hardware básico. Si la funcionalidad no satisface sus necesidades o no es funcional, puede modificarse. Esto se conoce como NoSQL y es un tipo de sistema de gestión de bases de datos que almacena datos estructurados, semiestructurados y no estructurados.
MongoDB, como una base de datos NoSQL (No solo SQL), se creó en 2007 como resultado del desarrollo de C++. Un Hadoop es una colección de programas de software de código abierto que se escriben principalmente en Java para el procesamiento de grandes datos. Esta plataforma también incluye búsqueda de texto completo, herramientas de análisis avanzadas y un lenguaje de consulta fácil de usar. Aunque Hadoop es más conocido por su capacidad para almacenar y procesar grandes cantidades de datos, también lo hace en pequeños lotes. MongoDB proporciona una variedad de herramientas de procesamiento de datos en tiempo real. Los conectores de MongoDB para herramientas externas, como Kafka y Spark, simplifican la ingesta y el procesamiento de datos. Cuando se trata de manejo de datos, Hadoop y MongoDB brindan una amplia gama de ventajas sobre las bases de datos tradicionales. Hadoop es una excelente herramienta para manejar grandes estructuras de datos debido a su sistema de archivos distribuido. MongoDB es la única base de datos que se puede utilizar como reemplazo de las bases de datos tradicionales.
¿Es Spark una base de datos Nosql?
En la documentación, se indica que un DataFrame NoSQL es un DataFrame Spark basado en el formato Spark para almacenar datos. A diferencia de las fuentes de datos anteriores, esta admite la poda y el filtrado de datos (empuje de predicado), lo que permite que las consultas de Spark consulten menos datos y carguen solo los datos requeridos según sea necesario.
Es fundamental mantener la conciencia táctica cuando se utilizan bases de datos Apache Spark y NoSQL ( Apache Cassandra y MongoDB) juntas en una aplicación. Este blog se enfoca en cómo usar Apache Spark en una aplicación NoSQL. CassandraLand y MongoLand en TCP/IP sPark son dos de las atracciones más populares y es un gran lugar para visitar si te gustan los parques temáticos. Mientras buscaba datos del Departamento de Energía, nuestra aplicación Spark comenzó a dar vueltas. Aquí hay una lección rápida sobre cuán importante es la secuencia de teclas de Cassandra cuando se trata de realizar consultas. También está la montaña rusa Partitioner en CassandraLand. Los clientes que disfrutan de las montañas rusas pueden compartir su información con los operadores de las atracciones para que puedan rastrear quién las ha montado a diario.
La primera lección en la Lección 1 de MongoDB es administrar correctamente las conexiones de MongoDB. Cuando necesite actualizar la información sobre el nuevo estado de membresía del parque del Departamento de Energía, los índices de Mongo son extremadamente útiles. Como cliente de MongoDB o Spark, debe mantener una conexión e índices adecuados en caso de actualizaciones del sistema.