
El formato de datos HDF5: una opción atractiva para almacenar y administrar grandes colecciones de datos
Publicado: 2023-02-13HDF5 es un formato de datos diseñado para almacenar y administrar colecciones de datos grandes y complejas. Se utiliza con frecuencia en aplicaciones científicas y de ingeniería, y su popularidad ha ido en aumento en los últimos años. HDF5 no es una base de datos, pero se puede utilizar para almacenar datos en un formato jerárquico similar a un sistema de archivos. Esto convierte a HDF5 en una opción atractiva para aplicaciones que necesitan almacenar y administrar grandes cantidades de datos.
Puede extraer metadatos y datos sin procesar de archivos HDF5 y netCDF4 y utilizar la transmisión de Hadoop para analizar los datos de Hadoop mediante el controlador de archivos virtuales (VFD) del conector HDF5 del sistema de archivos distribuidos de Hadoop (HDFS).
¿HDF5 es una base de datos?
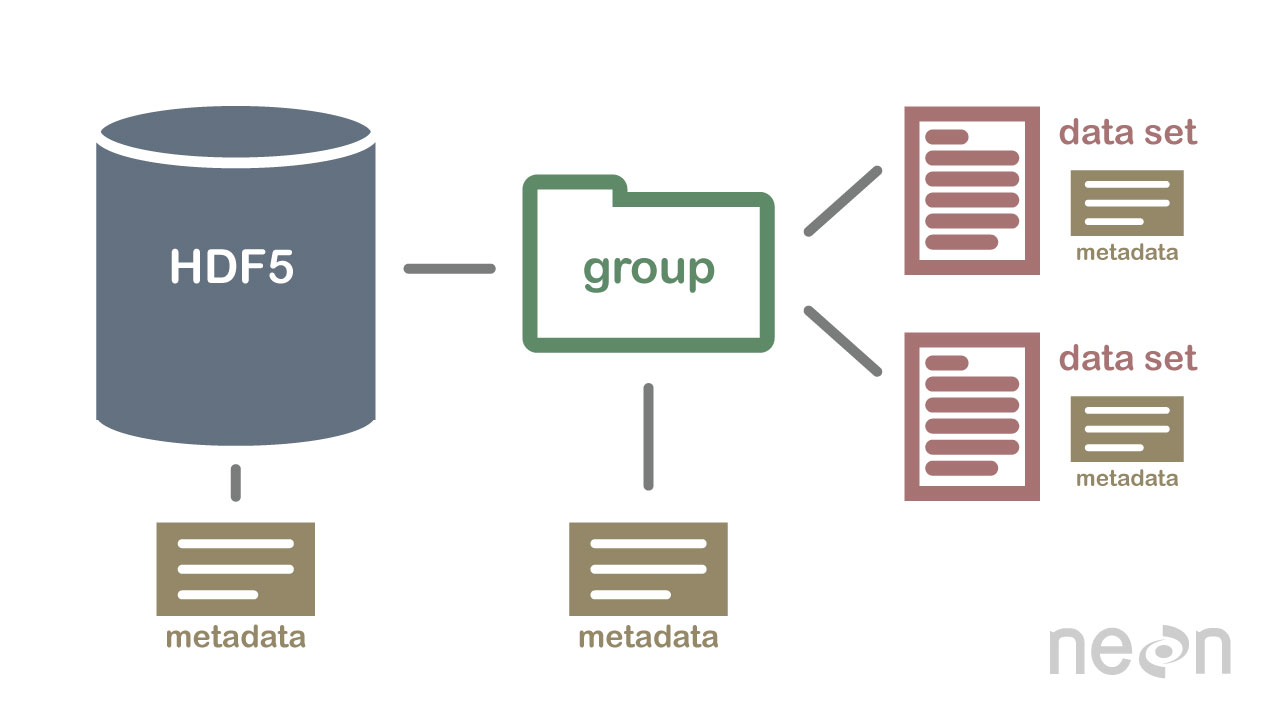
HDF5 no es una base de datos, pero se puede utilizar para almacenar datos en una estructura jerárquica, similar a un sistema de archivos. HDF5 se puede usar para almacenar datos en una variedad de formatos, incluidos texto, imágenes y datos binarios .
Los datos en formato jerárquico (HDF5) son extremadamente útiles en la investigación científica. El sistema de archivos HDF5, ya que es similar a un sistema de archivos en la forma en que es muy eficiente, es un formato excelente. Cuando se trata de datos codificados en este formato, puede ser difícil acceder a ellos. Esta guía lo guiará a través de cómo Apache Drill puede ayudarlo a acceder y consultar fácilmente los conjuntos de datos HDf5. Drill tiene acceso a archivos HDF5 individuales a través de la opción defaultPath. Esto se logra ejecutando directamente la función table() durante el tiempo de consulta o mediante la configuración. Los resultados de esta consulta se pueden encontrar en la siguiente tabla. Drill puede seleccionar las columnas y filtrarlas individualmente, filtradas, agregadas o combinadas con otros datos que puede consultar.
La especificación HDF5 define un formato de archivo para almacenar matrices de datos. Una matriz de datos puede estar formada por cualquier tipo de datos, incluidos datos de cadena, flotantes, complejos y enteros. Una matriz puede contener datos de cualquier tamaño y puede tener cualquier forma. En HDF5, primero se debe crear un archivo de encabezado para crear un conjunto de datos. El archivo de encabezado incluye información sobre el conjunto de datos, así como metadatos. El archivo de encabezado incluye dos piezas importantes de información: el nombre del conjunto de datos y el número de versión del conjunto de datos. Una matriz de datos se utiliza para almacenar los datos de un conjunto de datos. Los bloques se componen de datos en una matriz de datos. En la matriz de datos, cada bloque de datos contiene un conjunto contiguo de datos. El número de bloques de un conjunto de datos está determinado por el número de bytes que contiene. Se puede acceder a los datos a través de varios métodos de acuerdo con la especificación HDF5. Los métodos de indexación se usan más comúnmente para obtener datos en un conjunto de datos. Al usar estos métodos, puede acceder a los datos ingresando el nombre de un bloque en la matriz de datos a la que desea acceder. El método de estructura se puede utilizar para acceder a los datos de un conjunto de datos. Cuando emplea estos métodos, puede acceder a los datos utilizando la estructura de una matriz de datos. En el siguiente ejemplo, puede acceder a los datos en una matriz de datos utilizando los valores de desplazamiento y longitud del método de estructura. Otra forma de obtener datos de un conjunto de datos es mediante el uso de métodos de funciones. Puede obtener datos utilizando uno de los métodos seleccionando la función en el archivo de encabezado para los datos. El método para acceder a una matriz de datos se puede utilizar definiendo el valor en el archivo de encabezado como el elemento de la matriz de datos de la matriz. Finalmente, puede acceder a los datos en un conjunto de datos utilizando el método de acceso. Al emplear estos métodos, puede acceder a los datos utilizando los privilegios de acceso establecidos en el archivo de encabezado. En otras palabras, usar el privilegio de lectura puede acceder a los datos en una matriz de datos a través del método de acceso. Los datos se pueden crear y utilizar de diversas formas utilizando la especificación HDF5. El método de creación es el método más común para crear un conjunto de datos. Con el método de creación, puede crear un conjunto de datos ingresando el nombre del conjunto de datos y el número de versión del conjunto de datos. Además de la especificación HDF5, el uso de conjuntos de datos se puede lograr de varias maneras. El método más utilizado.

¿HDF5 es una base de datos relacional?
HDF5 no es una base de datos relacional.
¿Graphql es Nosql o Sql?
El objetivo principal de GraphQL es utilizar un sistema de tipos para devolver datos de forma más rápida y eficiente. SQL (lenguaje de consulta estructurado) es un lenguaje más antiguo y más utilizado para almacenar datos en sistemas de bases de datos tabulares o relacionales . Si desea que su API se construya sobre una base de datos NoSQL, sería una buena idea trabajar con GraphQL.
Type Mismatch es una base de datos GraphQL y NoSQL creada por Herman Camarena y Roger Cochrane. El uso de GraphQL puede resultar en la introducción de un sistema de tipos en lugar de un sistema NoSQL, eliminando la flexibilidad creada por los sistemas NoSQL. Una colección GraphQL contiene una amplia variedad de documentos que son consistentes en estructura y contienen algunas excepciones. Debido a que GraphQL tiene un conjunto integrado de tipos de datos que coinciden con los tipos de backends, los desarrolladores pueden elegir qué tipos de datos crear. GraphQL debe abordar el problema de las discrepancias de tipos para aprovechar al máximo su potencial. En cuanto a sus características, proporciona una solución de desajuste de nivel inferior debido a sus muchas ventajas. El trabajo está cada vez más automatizado con herramientas como JSON2SDL de StepZen.
Es una herramienta poderosa que se puede usar para crear aplicaciones más resistentes y eficientes, pero SQL no es un sustituto. En términos de mantenimiento, esto puede tener un impacto negativo porque dificulta algunas tareas.
Graphql: un lenguaje de consulta para cualquier base de datos
El lenguaje de consulta GraphQL permite que los clientes y servidores se comuniquen entre sí. Una instancia de GraphQL puede recuperar y persistir cambios desde una fuente de datos o desde un estado persistente. Un resolver es un conjunto de funciones arbitrarias que se utilizan para acceder y manipular datos. La API está disponible en una variedad de bases de datos y GraphQL se puede usar con cualquiera. La base de datos MongoDB es una base de datos de fuente de datos popular que es independiente de varios tipos de datos.
¿Nosql utiliza árboles B?
Las bases de datos NOSQL no utilizan árboles B porque no se basan en el modelo relacional. Las bases de datos NOSQL a menudo se basan en pares clave-valor, almacenes de documentos o bases de datos de gráficos.
Los árboles B son la estructura de indexación predeterminada en MongoDB. En el almacenamiento de datos , un árbol B es un método más eficiente. Los datos se pueden organizar usando números enteros y cadenas si se usan juntos. Como resultado, las bases de datos con un gran volumen de datos deberían considerar su uso. Debido a que los árboles B pueden ocupar mucho espacio, son un modelo eficiente. Esto es beneficioso para las bases de datos que necesitan conservar una gran cantidad de datos. Los árboles B también son una buena opción para las bases de datos que necesitan organizar los datos de una manera específica.
¿Qué base de datos utiliza el árbol B?
Ha existido durante mucho tiempo y se puede utilizar en una amplia gama de bases de datos. Las bases de datos NoSQL se pueden construir sobre motores B-tree, además de motores B-tree. MongoDB, por ejemplo, indexa datos en árboles B. El algoritmo es el mismo para DBMS que para una base de datos relacional, aunque existen algunas excepciones. Se pueden usar cadenas y enteros para organizar datos en el árbol B.
¿Qué base de datos usa B-tree? Mysql, en el artículo que sigue, emplea tanto Btree como B+tree. SQL Server almacena índices basados en datos persistentes basados en claves en forma de BTree. Como resultado, cada nodo de dicho árbol aparece como una sola página.